密云ETL怎么收费,派客动力,公司依托自有产品,整合行业资源,构建先进的数据管理解决方案,解决企业和组织的核心数据问题以及被影响的业务挑战。
这种工具我都使用过,优点有:图形界面,开发简单,数据流向清晰;处理大数据量比较吃力,查错困难,昂贵的费用;ORACLE,那么我觉得所有的ETL,都可以用存储过程来完成了。
ETL,Extraction-Transformation-Loading的缩写,中文名称为数据抽取、转换和加载。ETL贯穿其各个环节。可以理解为是把源数据的数据抽取到ODS或者DW中。文本文件,如用户浏览网站产生的日志文件,业务系统以文件形式提供的数据等;其他外部数据,如手工录入的数据等;也可以根据业务需求每小时甚至每分钟抽取,当然得考虑源数据库系统能否承受;个人感觉这是数据抽取中最重要的部分,可分为全量抽取和增量抽取。全量抽取适用于那些数据量比较小,并且不容易判断其数据发生改变的诸如关系表,维度表,配置表等;增量抽取,一般是由于数据量大,不可能采用全量抽取,或者为了节省抽取时间而采用的抽取策略;通过时间标识字段抽取增量;如createtime,updatetime等;根据上次抽取结束时候记录的自增长ID来抽取增量;下次抽取可根据上次记录的ID来抽取;
密云ETL怎么收费, 转换主要是针对数据仓库建立的模型,通过一系列的转换来实现将数据从业务模型到分析模型,通过ETL工具可视化拖拽操作可以直接使用标准的内置代码片段功能、自定义脚本、函数、存储过程以及其他的扩展方式,实现了各种复杂的转换,并且支持自动分析日志,清楚的监控数据转换的状态并优化分析模型。装载主要是将经过转换的数据装载到数据仓库里面,可以通过直连数据库的方式来进行数据装载,可以充分体现高效性。
还有,ODS会完成一些其他事情,比如,存储一些明细数据以备不时之需等等;数据转换,更多的人把它叫做数据刷新,就是用ODS中的增量或者全量数据来刷新DW中的表。每天都需要把新的数据更新到这些表中。如日期,来运行这些程序即可。还是merge,这个是由业务规则决定的,这些操作也都是嵌入到数据抽取、转换的程序中的。在传统行业的数据仓库项目中,大多会采用一些现成的ETL工具,如Informatica、Datastage、微软SSIS等。
密云ETL怎么收费, 一个存储过程,一个shell/perl脚本,一个java程序等等,都可以作为ETL工具。数据库中的表和字段也没有任何comment,你是不是会骂娘了?你如何知道改这个字段会对哪些程序产生影响?任务每次执行情况等等等等,这些元数据如果都能严格的管控起来,上面的问题肯定不会是问题了。如果觉得本博客对您有帮助,请 赞助作者 。之前的元数据都是用文档的形式所管理,但是个人感觉这种管理还是很落后和难维护的。
在整个过程中可以梳理各个数据集市的元数据。缺点:这个过程对 Teradata 数据量的减少较为缓慢;在迁移改造的过程中需要考虑现有 Teradata数据仓库扩容压力以及维护成本的问题。自下而上:从数据的采集,ETL 层面开始迁移,随后把整个数据仓库层面改造到 Hadoop 系统中,最后再迁移数据集市。优点:首先解决 ETL 迁移的问题,效率较高。 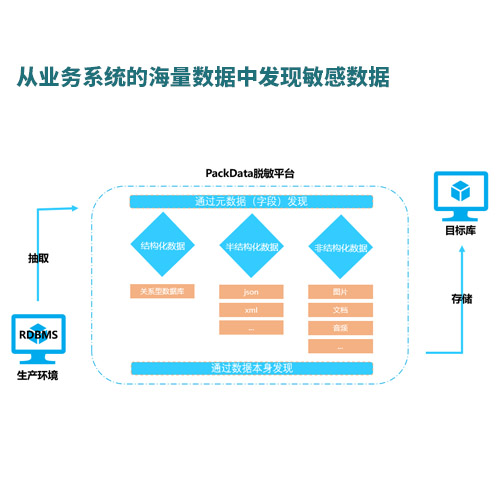
密云ETL怎么收费, 对于系统上线和性能压力非常大。自部分到整体:把一部分核心业务系统数据的全部流程(从 ETL 到数据集市)迁移到 Hadoop 中,然后逐步扩大规模,最后到整个数据仓库。优点:这个方案涉及了两套数据库表和 ETL 系统的维护,而且很多分析的应用需要访问全范围的数据。这个方案在空间缩减方面比较直接。 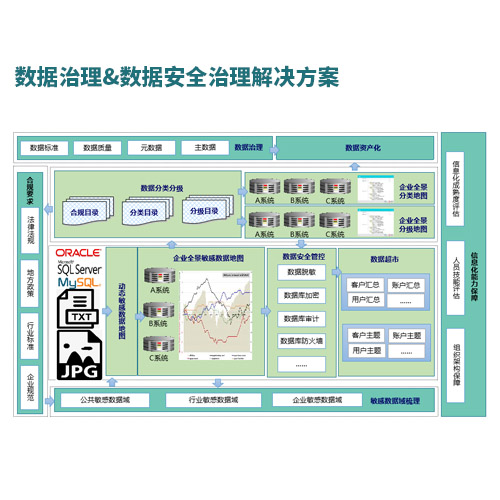




方法查找最大整数)





)







方法及示例)
)