2019独角兽企业重金招聘Python工程师标准>>> 
一、Elasticsearch的聚合
ES的聚合相当于关系型数据库里面的group by,例如查找在性别字段男女人数的多少并且按照人数的多少进行排序,在使用MySQL的时候,可以使用如下的句子
- select sex,count(*) from table_name group by sex order by count(*)
在ES里面想要实现这种的语句,就叫做聚合,比如这种的聚合使用DSL语句的话如下所示:
- GET /index/type/_search
- {
- "size" : 0,
- "aggs" : {
- "agg_sex" : {
- "terms" : {
- "field" : "sex"
- }
- }
- }
- }
这样就可以实现最以上例子中的group by的功能,当然这只是最简单的聚合的使用,在ES里面的聚合有多重多样的,比如说有度量聚合,可以用来计算某一个字段的平均值最大值等,在此给出一个简单的度量聚合的例子
- GET /index/type/_search
- {
- "size" : 0,
- "aggs": {
- "agg_sex": {
- "terms": {
- "field": "sex"
- },
- "agg_age": {
- "avg_age": {
- "avg": {
- "field": "age"
- }
- }
- }
- }
- }
- }
这个DSL语句就是将先按照性别进行聚合,并且对不同的性别给出一个平均的年龄,使用之后ES的给出结果如下所示:
- {
- ...
- "aggregations": {
- "agg_sex": {
- "buckets": [
- {
- "key": "male",
- "doc_count": 4,
- "avg_age": {
- "value": 25
- }
- },
- {
- "key": "female",
- "doc_count": 2,
- "avg_age": {
- "value": 23
- }
- }
- ]
- }
- }
- ...
- }
在度量聚合里面有min,max,sum,avg聚合等,还有stats,extern_stats等聚合,其中stats的聚合给出的信息会包括min,max,count等基本的信息,更多详细的细节请参考ES官网给出的指导https://www.elastic.co/guide/en/elasticsearch/guide/current/aggregations.html
以上只是给出的度量聚合,但是在实际中我们经常使用的是桶聚合,什么是桶聚合呢,个人理解就是将符合某一类条件的文档选出来,所有的某一类的聚合就称为桶,例如你可以按照某一个分类将所有的商品聚合起来,这种情况下就可以认为某一个分类的商品称为一个桶,下面将详细介绍几个常用的桶聚合,并且会给出Java使用时候的代码
二、桶聚合
桶聚合是在实际使用时候用处比较多的一种聚合,简单的桶聚合包括term聚合,range聚合,date聚合,IPV4聚合等聚合,因为自己使用的仅仅是其中的三个,在此就简单的介绍三个,分别是term聚合,range聚合,以及date聚合
1、term聚合
term聚合就是第一部分给出的简单的例子,按照不同的字段进行聚合
2、range聚合
range聚合为按照自定义的范围来创造桶,将每一个范围的数据进行聚合,并且这个聚合一般适用于字段类型为long或者int,double的字段,可以进行直接的聚合,例如,我们想统计不同年龄段的人的个数,DSL如下所示:
- GET /index/type/_search
- {
- "aggs" : {
- "agg_age" : {
- "field":"age"
- "ranges" : [
- { "to" : 18},
- { "from" : 19,"to" : 50},
- {"from" : 51}
- ]
- }
- }
- }
3、daterange聚合
date range聚合和range聚合类似,但是所使用的类型是datetime这种类型,使用的时候与range有些区别,给出一个简单的使用date range聚合的DSL例子,如下所示:
- GET /index/type/_search
- {
- "aggs" : {
- "agg_year" : {
- "field":"date"
- "ranges" : [
- { "to" : "2008-08-08"},
- { "from" : "2008-08-09","to" : "2012-09-01"},
- {"from" : "2012-09-02"}
- ]
- }
- }
- }
上面的DSL是简单的按照时间格式进行区间的聚合,但是有些时候我们可能想要一些按照年份聚合或者月份聚合的情况,这个时候应该怎么办呢?在date range里面可以指定日期的格式,例如下面给出一个按照年份进行聚合的例子:
- GET /index/type/_search
- {
- "aggs" : {
- "agg_year" : {
- "field":"date"
- "format":"YYYY",
- "ranges" : [
- { "to" : "1970"},
- { "from" : "1971","to" : "2012"},
- {"from" : "2013"}
- ]
- }
- }
- }
我们可以指定格式来进行聚合
三、对于上述三种聚合java的实现
首先先给出一个具体的使用ES java api实现搜索并且聚合的完整例子,例子中使用的是terms聚合,按照分类id,将所有的分类进行聚合
- public void aggsearch() {
- init();
- SearchResponse response = null;
- SearchRequestBuilder responsebuilder = client.prepareSearch("iktest")
- .setTypes("iktest").setFrom(0).setSize(250);
- AggregationBuilder aggregation = AggregationBuilders
- .terms("agg")
- .field("category_id")
- .subAggregation(
- AggregationBuilders.topHits("top").setFrom(0)
- .setSize(10)).size(100);
- response = responsebuilder.setQuery(QueryBuilders.boolQuery()
- .must(QueryBuilders.matchPhraseQuery("name", "中学历史")))
- .addSort("category_id", SortOrder.ASC)
- .addAggregation(aggregation)// .setSearchType(SearchType.DFS_QUERY_THEN_FETCH)
- .setExplain(true).execute().actionGet();
- SearchHits hits = response.getHits();
- Terms agg = response.getAggregations().get("agg");
- System.out.println(agg.getBuckets().size());
- for (Terms.Bucket entry : agg.getBuckets()) {
- String key = (String) entry.getKey(); // bucket key
- long docCount = entry.getDocCount(); // Doc count
- System.out.println("key " + key + " doc_count " + docCount);
- // We ask for top_hits for each bucket
- TopHits topHits = entry.getAggregations().get("top");
- for (SearchHit hit : topHits.getHits().getHits()) {
- System.out.println(" -> id " + hit.getId() + " _source [{}]"
- + hit.getSource().get("category_name"));
- ;
- }
- }
- System.out.println(hits.getTotalHits());
- int temp = 0;
- for (int i = 0; i < hits.getHits().length; i++) {
- // System.out.println(hits.getHits()[i].getSourceAsString());
- System.out.print(hits.getHits()[i].getSource().get("product_id"));
- // if(orderfield!=null&&(!orderfield.isEmpty()))
- // System.out.print("\t"+hits.getHits()[i].getSource().get(orderfield));
- System.out.print("\t"
- + hits.getHits()[i].getSource().get("category_id"));
- System.out.print("\t"
- + hits.getHits()[i].getSource().get("category_name"));
- System.out.println("\t"
- + hits.getHits()[i].getSource().get("name"));
- }
- }
- }
以上的例子实现的是按照category_id字段进行分类的聚合,并且将在name字段查找包含“中学历史”的这个词,并且按照category_id进行排序,在此给出的只是一个搜索实现的函数,里面的字段名字,以及index,type等很多字段均为自己定义的index里面的名字,上面给出的是terms聚合时候的代码,如果使用的是range聚合或者date range聚合,只需要改变aggregation就可以
使用range聚合的时候:
- aggregation = AggregationBuilders.range("agg")
- .field("price").addUnboundedTo(50)
- .addRange(51, 100).addRange(101, 1000)
- .addUnboundedFrom(1001);
使用date range聚合的时候:
- aggregation = AggregationBuilders.dateRange("agg")
- .field("date").format("yyyy")
- .addUnboundedTo("1970").addRange("1970", "2000")
- .addRange("2000", "2010").addUnboundedFrom("2009");
以上所有的聚合均是先过滤搜索,然后对于召回得到的结果进行一个聚合,例如我们在name字段搜索中学历史这个词,最终得到四个分类分别为1,2,3,4那么聚合的时候就是这四个分类,但是有时候我们可能会需要对于搜索的结果进行一个过滤,但是我们不想对聚合的结果进行过滤,那么我们就要使用一下的部分了
四、先聚合再过滤
以上将的简单的聚合都是先过滤或者搜索,然后对结果进行聚合,但是有时候我们需要先进行聚合,然后再对结果进行一次过滤,但是我们不希望这个时候聚合会发生变化,什么时候会遇到这种情况呢,我们以美团为例做一个说明,在主页我们直接点解美食,得到如下所示的图
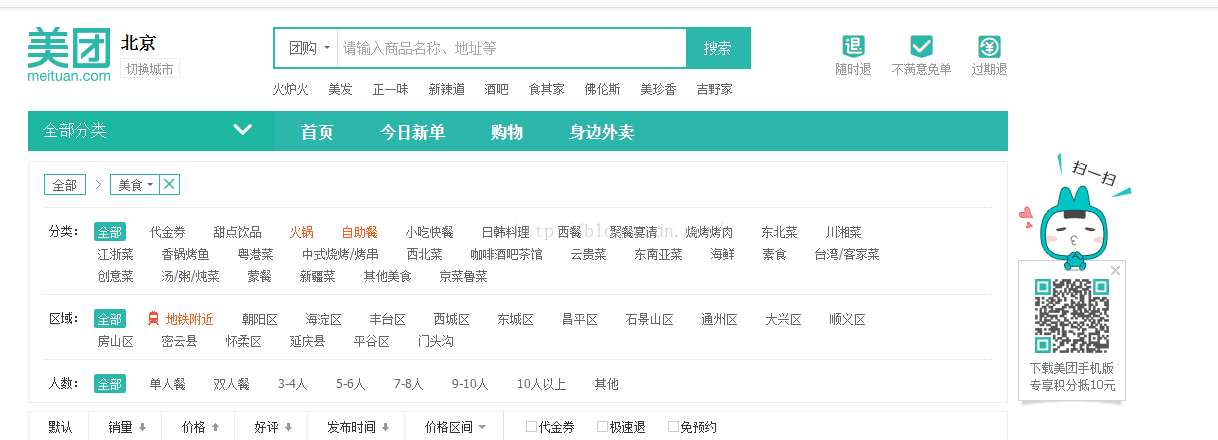
点美食之后出现全部的分类,包括各种的菜系,下面我们点一个具体的菜系
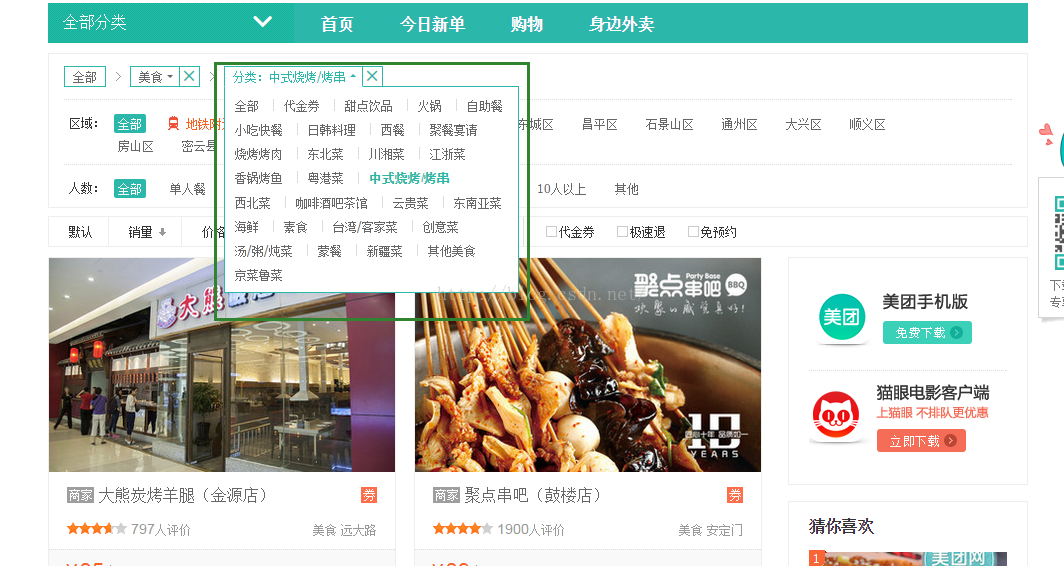
从程序上来说,我们点第二次菜系的时候,出现的所有的菜品均是烤串之类的菜品了,但是在分类里面还是所有的分类都会有,如果按照之前的ES的聚合,会将所有搜索出来的品的分类进行一个聚合,但是点完烤串之后,所有的分类都是烤串了,那么就应该所有的分类只有一个烤串了,不应该有其他的,这样的话肯定是不可以的,那么如何才能实现这种聚合的,这个时候我们就需要先聚合,然后进行再次的过滤,但是过滤的时候并不影响之前的聚合结果,这就是先聚合再过滤,在ES里面也有这种情况的考虑,这个时候使用的是postfilter
postfilter解决了仅仅过滤搜索结果,但是并不影响聚合结果,下面给出一个java使用时候的例子以及比较
函数一为第三部分给出的完整的搜索函数,按照分类聚合
函数二的改变只是对于一的
- response = responsebuilder.setQuery(QueryBuilders.boolQuery()
- .must(QueryBuilders.matchPhraseQuery("name", "中学历史")))
- .addSort("category_id", SortOrder.ASC)
- .addAggregation(aggregation)
- .setPostFilter(QueryBuilders.rangeQuery("price").gt(1000).lt(5000))
- .setExplain(true).execute().actionGet();
添加了按照price进行过滤,最后结果显示,聚合的结果两次完全一样,但是函数二召回的结果为函数一结果的子集。
五、后续学习
如何多次的过滤以及召回,比如先过滤后聚合再过滤再次聚合然后再次过滤这种的应该如何实现,需要学习。