转自:https://www.cnblogs.com/yjd_hycf_space/p/7094005.html
题目: 通过给出的驾驶员行为数据(trip.csv),对驾驶员不同时段的驾驶类型进行聚类,聚成普通驾驶类型,激进类型和超冷静型3类 。 利用Python的scikit-learn包中的Kmeans算法进行聚类算法的应用练习。并利用scikit-learn包中的PCA算法来对聚类后的数据进行降维,然后画图展示出聚类效果。通过调节聚类算法的参数,来观察聚类效果的变化,练习调参。
数据介绍: 选取某一个驾驶员的经过处理的数据集trip.csv,将该驾驶人的各个时间段的特征进行聚类。(注:其中的driver 和trip_no 不参与聚类)
字段介绍: driver :驾驶员编号;trip_no:trip编号;v_avg:平均速度;v_var:速度的方差;a_avg:平均加速度;a_var:加速度的方差;r_avg:平均转速;r_var:转速的方差; v_a:速度level为a时的时间占比(同理v_b , v_c , v_d ); a_a:加速度level为a时的时间占比(同理a_b, a_c); r_a:转速level为a时的时间占比( r_b, r_c)
聚类算法要求:
(1)统计各个类别的数目
(2)找出聚类中心
(3)将每条数据聚成的类别(该列命名为jllable )和原始数据集进行合并,形成新的dataframe,命名为new_df ,并输出到本地,命名为new_df.csv。
降维算法要求:
(1)将用于聚类的数据的特征的维度降至2维,并输出降维后的数据,形成一个dataframe名字new_pca
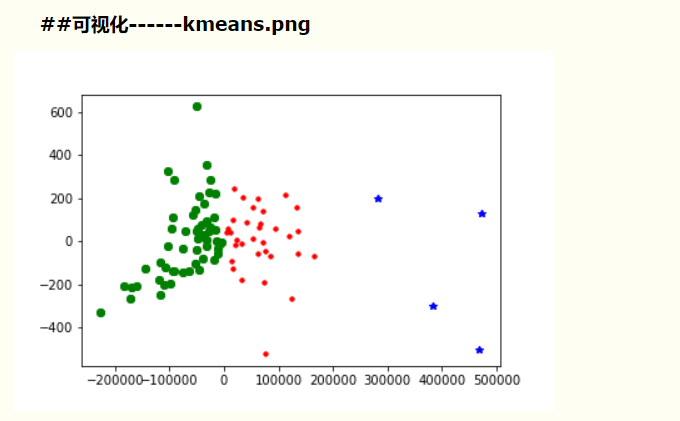
(2)画图来展示聚类效果(可用如下代码):
import matplotlib.pyplot asplt
d = new_pca[new_df['jllable'] == 0]
plt.plot(d[0], d[1], 'r.')
d = new_pca[new_df['jllable'] == 1]
plt.plot(d[0], d[1], 'go')
d = new_pca[new_df['jllable'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.gcf().savefig('D:/workspace/python/Practice/ddsx/kmeans.png')
plt.show()
python实现代码如下:
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltdf=pd.read_csv('trip.csv', header=0, encoding='utf-8')
df1=df.ix[:,2:]
kmeans = KMeans(n_clusters=3, random_state=10).fit(df1)
df1['jllable']=kmeans.labels_
df_count_type=df1.groupby('jllable').apply(np.size)##各个类别的数目
df_count_type
##聚类中心
kmeans.cluster_centers_
##新的dataframe,命名为new_df ,并输出到本地,命名为new_df.csv。
new_df=df1[:]
new_df
new_df.to_csv('new_df.csv')##将用于聚类的数据的特征的维度降至2维,并输出降维后的数据,形成一个dataframe名字new_pca
pca = PCA(n_components=2)
new_pca = pd.DataFrame(pca.fit_transform(new_df))##可视化
d = new_pca[new_df['jllable'] == 0]
plt.plot(d[0], d[1], 'r.')
d = new_pca[new_df['jllable'] == 1]
plt.plot(d[0], d[1], 'go')
d = new_pca[new_df['jllable'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.gcf().savefig('kmeans.png')
plt.show()


和str.length()和str.size()的区别)







...)










