目标检测最常用的三个模型:Faster R-CNN、SSD和YOLO
Faster R-CNN架构
在Faster RCNN中,候选框是经过RPN产生的,然后再把各个“候选框”映射到特征图上,得到RoIs。
Faster R-CNN步骤:
(1) 由输入图片产生的区域候选
(2) 最后一层卷积输出的所有通道
(3) ROI pooling
注解:ROI Pooling的意义
ROIs Pooling。顾名思义,是Pooling层的一种,而且是针对RoIs的Pooling,他的特点是输入特征图尺寸不固定,但是输出特征图尺寸固定;
ROI pooling总结:
(1)用于目标检测任务;
(2)允许我们对CNN中的feature map进行reuse;
(3)可以显著加速training和testing速度;
(4)允许end-to-end的形式训练目标检测系统。
整个Faster RCNN训练过程可分为4步:
第一步:用在ImageNet数据集上训练好的model初始化模型,训练一个RPN网络;
第二步:用在ImageNet数据集上训练好的model初始化模型,同时用第一步中训练好的RPN网络生成的region proposal作为输入,训练一个Fast RCNN;
第三步:用第二步训练好的Fast RCNN的网络参数初始化RPN网络,但是将RPN与Fast RCNN共享的网络层的learning rate设置为0,仅微调RPN独有的网络层。
第四步:固定共享的网络层,仅微调Fast RCNN所独有的fc层。
网络结构
可以清晰的看到该网络对于一副任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;而Conv layers中包含了13个conv层+13个relu层+4个pooling层;RPN网络首先经过3x3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposals;而Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
复现方式
SSD架构
一 介绍
SSD–single shot multibox detection,是目标识别领域中对 不同类的物体(汽车,人。。。)的识别,识别的表示方式是对被识别的物体画bounding box(包围框)。除此之外还有其他种类的目标识别,比如下图:

SSD网络的特点是:对不同尺度下的 feature map 中每一个点都设置一些 default box, 这些default box有不同的大小和横纵比例,对这些default box进行分类和边框回归的操作。在预测阶段,SSD会对每个default box 生成一个分类标签(属于每一类的概率构成的向量)以及位置坐标的调整
二 SSD网络结构:
SSD网络由两部分组成,前部分是一些经典的特征提取网络,在这里作为base network,使用的是VGG16。后半部分是作者增加的网络,提取成特征的基础之上处理得到不同尺度的feature map,生成许多组default box进行预测分类和位置调整信息。
SSD除了在最终特征图上做目标检测之外,还在之前选取的5个特特征图上进行预测。检测过程不仅在填加特征图(conv8_2, conv9_2, conv_10_2, pool_11)上进行,为了保证网络对小目标有很好检测效果,检测过程也在基础网络特征图(conv4_3, conv_7)上进行
SSD 方法的核心就是 predict object(物体),以及其归属类别的 score(得分);同时,在feature map上使用小的卷积核去 predict 一系列 bounding boxes 的 box offsets,为了得到高精度的检测结果,在不同层次的 feature maps 上去 predict object、box offsets,同时,还得到不同 aspect ratio 的 predictions。
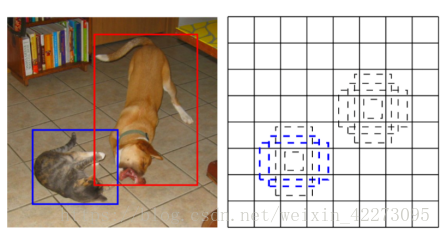
这里简单介绍一下default map cell以及 feature box
1、feature map cell就是将feature map切分成n*n的格子。
2、default box就是每一个格子上,生成一系列固定大小的 box,即图中虚线所形成的一系列 boxes。
算法流程:
首先来看一下SSD的基本步骤:
1、输入一幅图片,让图片经过卷积神经网络(CNN)提取特征,并生成 feature map
2、抽取其中六层的feature map,然后再 feature map 的每个点上生成 default box(各层的个数不同,但每个点都有)
3、将生成的所有 default box 都集合起来,全部丢到 NMS(极大值抑制)中,输出筛选后的 default box,并输出
算法框架
YOLO架构
YOLO(You Only Look Once)是一种基于深度神经网络的对象识别和定位算法,其最大的特点是运行速度很快,可以用于实时系统。
输入一张图片,要求输出其中所包含的对象,以及每个对象的位置(包含该对象的矩形框)。

对象识别和定位,可以看成两个任务:找到图片中某个存在对象的区域,然后识别出该区域中具体是哪个对象。对象识别这件事(一张图片仅包含一个对象,且基本占据图片的整个范围),最近几年基于CNN卷积神经网络的各种方法已经能达到不错的效果了。所以主要需要解决的问题是,对象在哪里。
最简单的想法,就是遍历图片中所有可能的位置,地毯式搜索不同大小,不同宽高比,不同位置的每个区域,逐一检测其中是否存在某个对象,挑选其中概率最大的结果作为输出。显然这种方法效率太低。
RCNN/Fast RCNN/Faster RCNN
RCNN开创性的提出了候选区(Region Proposals)的方法,先从图片中搜索出一些可能存在对象的候选区Selective Search,大概2000个左右,然后对每个候选区进行对象识别。大幅提升了对象识别和定位的效率。不过RCNN的速度依然很慢,其处理一张图片大概需要49秒。因此又有了后续的Fast RCNN 和 Faster RCNN,针对RCNN的神经网络结构和候选区的算法不断改进,Faster RCNN已经可以达到一张图片约0.2秒的处理速度。
YOLO创造性的将候选区和对象识别这两个阶段合二为一,看一眼图片就能知道有哪些对象以及它们的位置。实际上,YOLO并没有真正去掉候选区,而是采用了预定义的候选区(准确说应该是预测区,并不是Faster RCNN所采用的Anchor)。也就是将图片划分为 7*7=49 个网格(grid),每个网格允许预测出2个边框(bounding box,包含某个对象的矩形框),总共 49*2=98 个bounding box。可以理解为98个候选区,它们很粗略的覆盖了图片的整个区域。
YOLO结构
去掉候选区这个步骤以后,YOLO的结构非常简单,就是单纯的卷积、池化最后加了两层全连接。最大的差异是最后输出层用线性函数做激活函数,因为需要预测bounding box的位置(数值型),而不仅仅是对象的概率。YOLO网络结构由24个卷积层与2个全连接层构成,网络入口为448x448(v2为416x416),图片进入网络先经过resize,网络的输出结果为一个张量,维度为:

其中,S为划分网格数,B为每个网格负责的边框个数,C为类别个数。每个小格会对应B个边界框,边界框的宽高范围为全图,表示以该小格为中心寻找物体的边界框位置。每个边界框对应一个分值,代表该处是否有物体及定位准确度:,每个小格会对应C个概率值,找出最大概率对应的类别P(Class|object),并认为小格中包含该物体或者该物体的一部分。
输入和输出的映射关系

输入
输入就是原始图像,唯一的要求是缩放到448*448的大小。主要是因为YOLO的网络中,卷积层最后接了两个全连接层,全连接层是要求固定大小的向量作为输入,所以倒推回去也就要求原始图像有固定的尺寸。那么YOLO设计的尺寸就是448*448。
输出是一个 7*7*30 的张量(tensor)。
输入图像被划分为 7*7 的网格(grid),输出张量中的 7*7 就对应着输入图像的 7*7 网格。或者我们把 7*7*30 的张量看作49个30维的向量,也就是输入图像中的每个网格对应输出一个30维的向量。参考上图,比如输入图像左上角的网格对应到输出张量中左上角的向量。
要注意的是,并不是说仅仅网格内的信息被映射到一个30维向量。经过神经网络对输入图像信息的提取和变换,网格周边的信息也会被识别和整理,最后编码到那个30维向量中。具体来看每个网格对应的30维向量中包含了哪些信息?

网络结构
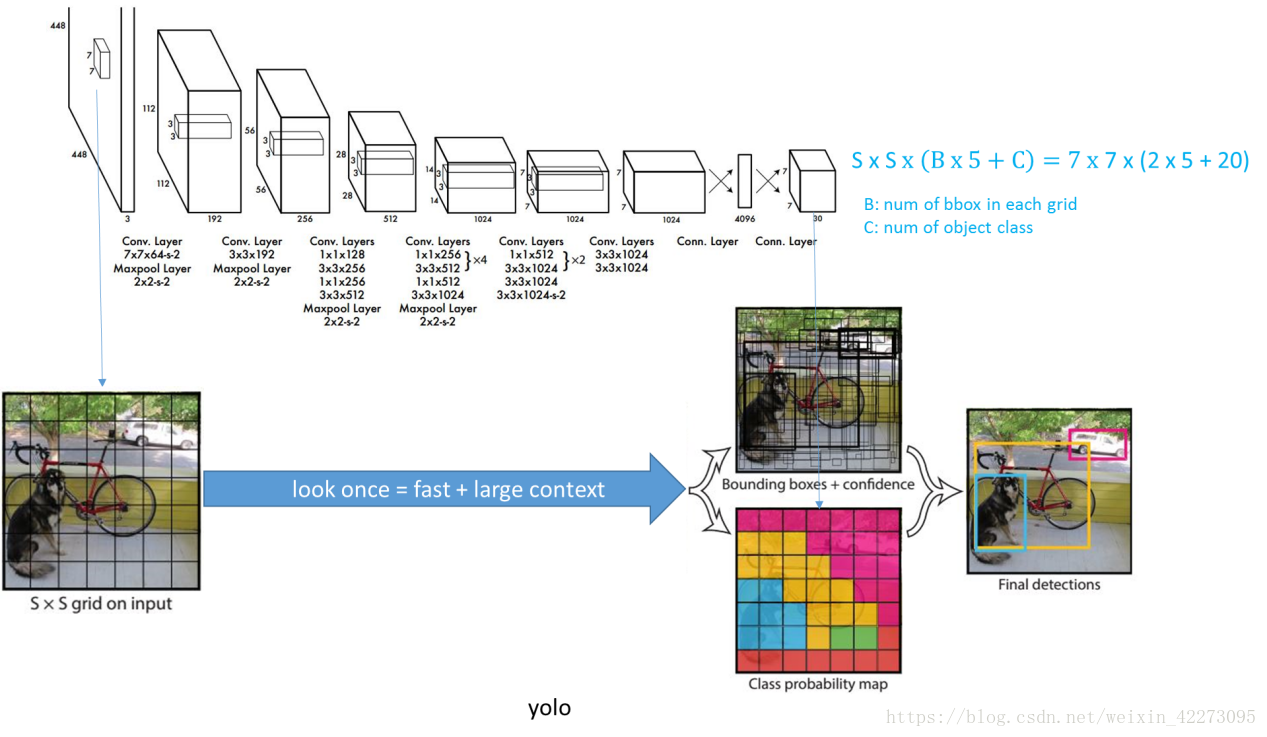
网络方面主要采用GoogLeNet,卷积层主要用来提取特征,全连接层主要用来预测类别概率和坐标。最后的输出是7*7*30,7*7是grid cell的数量。
YOLO存在的优点是:
1.速度快,处理速度可以达到45fps,其快速版本(网络较小)甚至可以达到155fps。这得益于其识别和定位合二为一的网络设计,而且这种统一的设计也使得训练和预测可以端到端的进行,非常简便。
2.泛化能力强 ,可以广泛适用于其他测试集。
3.背景预测错误率低,因为是整张图片放到网络里面进行预测。
YOLO存在的缺点是:
精度低,小目标和邻近目标检测效果差,小对象检测效果不太好(尤其是一些聚集在一起的小对象),对边框的预测准确度不是很高,总体预测精度略低于Fast RCNN。主要是因为网格设置比较稀疏,而且每个网格只预测两个边框,另外Pooling层会丢失一些细节信息,对定位存在影响。
YOLOv2架构
V1 缺陷之处:
1、输入尺寸固定:由于输出层为全连接层,因此在检测时,YOLO 训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成此固定分辨率;
2、占比小的目标检测效果不好:虽然每个格子可以预测 B 个 bounding box,但是最终只选择只选择 IOU 最高的bbox作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。
YOLOv2的结构示意图如下:

YOLOv2 引入了 faster rcnn 中 anchor box 的思想,对网络结构的设计进行了改进,使得模型更易学习。
YOLOv2提出了一种新的分类模型Darknet-19。主要使用3x3卷积并在pooling之后channel数加倍(VGG);global average pooling替代全连接做预测分类,并在3x3卷积之间使用1x1卷积压缩特征表示(Network in Network);使用 batch normalization 来提高稳定性,加速收敛,对模型正则化。Darknet-19的结构如下表:
包含 19 conv + 5 maxpooling.用 1x1 卷积层替代 YOLOv1 的全连接层。1x1 卷积层( 为了跨通道信息整合)如上图的红色矩形框部分。
升级版YOLO v3
YOLO的V1和V2都不如SSD的算法,主要原因是V1的448尺寸和V2版本的416尺寸都不如SSD的300,以上结论都是实验测试的,V3版本的416跟SSD512差不多好,但速度快很多。yolov2有个毛病就是对小物体的检测不敏感,而增加了多尺度预测之后,yolov3在对小物体检测方便有了好转,但是现在的毛病是对中、大size的物体表现的不是那么好。
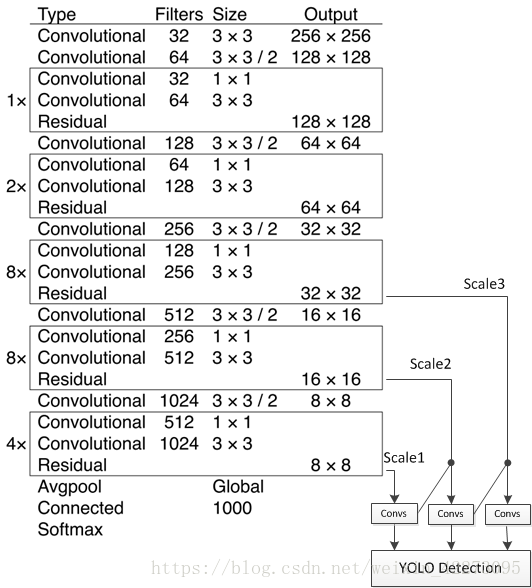
YOLO V2是一个纵向自上而下的网络架构,随着通道数目的不断增加,FLOPS是不断增加的,而V3网络架构是横纵交叉的,看着卷积层多,其实很多通道的卷积层没有继承性,另外,虽然V3增加了anchor centroid,但是对GT的估计变得更加简单,每个GT只匹配一个先验框,而且每个尺度只预测3个框,V2预测5个框,这样的话也降低了复杂度。
Mask R-CNN
Mask R-CNN:像素级目标检测,不仅给出其边界框,并且对边界框内的各个像素是否属于该物体进行标记。
可以看出MaskRCNN在有效检测目标的同时输出高质量的实例分割mask
可以看出MaskRCNN的网络结构,作为FasterRCNN的扩展
1):用RolAlign代替了RoIPooling,RoIPooling使用取整量化,导致特征图RoI映射回原图RoI时空间不对齐明显,造成误差;RolAlign不使用取整量化而是采用双线性插值,完成像素级的对齐;
2):FasterRcnn为每个候选对象ROI提供两个输出,一个类标签,一个边界框偏移量,为此,MaskRCNN并行添加了第三个分割mask的分支,mask分支是应用到每一个ROI上的一个小的FCN(Fully Convolutional Network),以pix2pix的方式预测分割mask。
分割
分割模型一般DeepLabv3+,U-net
U-net

U-net网络非常简单,前半部分作用是特征提取,后半部分是上采样。在一些文献中也把这样的结构叫做编码器-解码器结构。由于此网络整体结构类似于大写的英文字母U,故得名U-net。
1、特征提取部分,每经过一个池化层就一个尺度,包括原图尺度一共有5个尺度。
2、上采样部分,每上采样一次,就和特征提取部分对应的通道数相同尺度融合,但是融合之前要将其crop。这里的融合也是拼接。
U-net与其他常见的分割网络有一点非常不同的地方:U-net采用了完全不同的特征融合方式:拼接,U-net采用将特征在channel维度拼接在一起,形成更厚的特征。
代码复现



)















