
导读:商汤研究院和浙江大学CAD&CG国家重点实验室合作研发了一个手机端实时单目三维重建系统Mobile3DRecon。与现有的基于RGBD的在线三维重建或离线生成表面网格的系统不同,该系统结合前端位姿跟踪结果,允许用户使用单目摄像头在线重建场景表面网格。
在深度估计方面,提出结合多视图半全局匹配算法和深度神经网络优化后处理过程鲁棒地估计场景深度。在表面网格生成过程,本文提出的在线网格生成算法可以实时增量地融合关键帧深度到稠密网格中,从而重建场景表面。通过定性和定量的实验验证,所研制的单目三维重建系统能够正确处理虚拟物体与真实场景之间的遮挡和碰撞,在手机端实现逼真的AR效果和交互。
论文名称: Mobile3DRecon: Real-time Monocular 3D Reconstruction on a Mobile Phone
论文地址:
Mobile3DRecon: Real-time Monocular 3D Reconstruction on a Mobile Phoneieeexplore.ieee.orgOral slides:
https://www.youtube.com/watch?v=W95Vs4REUGMwww.youtube.com问题和挑战
遮挡和碰撞检测一直是AR行业面对的一大难题,其技术难点在于需要实时获取场景的三维表面信息,从而使虚拟物体和真实环境能融为一体。
当前已有的实时场景重建系统通常需要RGB-D或Lidar摄像头的支持(如KinectFusion, InfiniTAM, ElasticFusion, BundleFusion等),然而受硬件的限制目前市面上大部分的手机无法使用该功能;
另一类重建系统虽然可以根据单目RGB摄像头计算深度,从而重建场景表面(如MonoFusion, MobileFusion, CHISEL等),但是需要较大的计算时间和内存开销,大多仅能在PC或高端的移动平台上实时运行。
针对上述问题,本文提出了一个手机端实时单目三维重建系统Mobile3Drecon,该工作的主要贡献在于:
- 提出一种基于多视图关键帧的深度估计方法,能够在手机端高效获取较高精度的场景深度,同时能够一定程度上容忍SLAM位姿偏差和弱纹理场景的影响;
- 提出一种快速有效的增量式网格生成方法,该方法可以融合关键帧深度从而实时增量地重建场景表面网格,同时支持场景动态物体的移除,在中端的手机平台上实时运行;
- 搭建了一套完整的基于单目RGB的实时三维重建系统,该系统在中端手机平台上可以达到125ms每关键帧,获取的表面网格精度可以达到厘米级,基于该系统可以在手机端实现逼真的AR效果和交互,如图1所示。

方法介绍
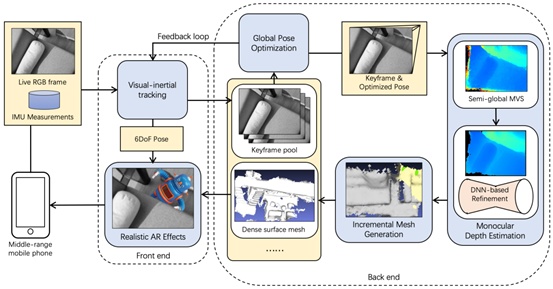
本系统框架如图2所示。移动设备获取的RGB图像和IMU信息经过前端视觉惯性SLAM系统后可以实时得到关键帧的6自由度位姿,该位姿经过后端全局优化后进入深度估计模块,对于新增的每个关键帧,首先基于多视图半全局匹配方法计算关键帧初始深度图,然后采用置信度和深度神经网络优化深度图噪声,优化后的深度图输入增量式网格生成模块后实时构建场景表面稠密网格。
通过实时6自由度位姿估计和场景表面网格构建,Mobile3DRecon系统支持用户在手机端实现真实的AR遮挡和碰撞效果。下面分别介绍系统的单目深度估计和增量式网格构建两个主要功能模块。
1. 单目深度估计
动机:
传统基于多视图立体匹配的深度估计算法通常需要较强的GPU算力来满足实时计算的要求,而轻量的算法又难以获得精确完整的深度图结果。尽管一些基于深度神经网络的深度估计算法在公开数据集上表现出了较好的效果,然而在实际应用过程中受场景弱纹理和SLAM位姿偏差的影响较大,手机平台算力的影响也使其难以在移动端部署。
鉴于此,本文期望结合轻量化的深度神经网络和快速的多视图半全局匹配算法实现场景深度计算,考虑到手机平台算力、SLAM位姿偏差和弱纹理场景的影响,本文希望多视图半全局匹配方法在保证深度估计泛化能力的同时,能够融合多帧信息提升对位姿偏差和弱纹理区域的容忍度,通过结合深度神经网络能够有效改善位姿偏差和弱纹理产生的深度噪声,从而得到精确、完整的深度图结果。
方法:
本文提出的单目深度估计算法主要包含三个部分:
- 多视图立体匹配算法,用于计算初始深度图
- 置信度去噪算法,用于去除初始深度图噪声
- 基于深度神经网络的深度图优化算法,用于改善深度图质量
具体方式如下:
① 步骤:多视图深度估计


② 步骤:置信度噪声剔除


③ 步骤:基于深度神经网络的深度图优化
去除深度图噪声后,本文使用一个轻量的深度神经网络优化深度图,网络结构如图4所示,包含了多任务网络和深度优化网络两个部分。
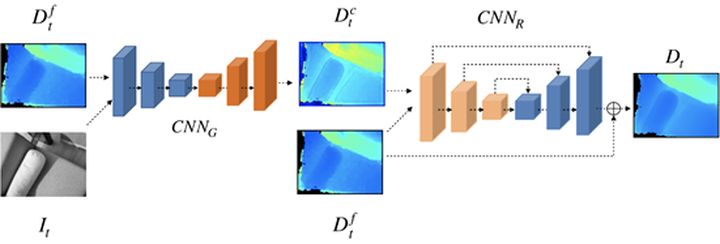

网络第二个阶段的输入为原始深度图和一阶段的深度图噪声预测结果,使用U-Net残差深度优化网络优化原始输入的深度,得到更高质量的深度输出。本文使用Demon数据集[2]训练上述网络,然后使用手机采集的带TOF深度的3700组序列影像微调该网络。图5所示为带有一定位姿偏差的图像,第二列为置信度剔除噪声后的深度图,最后一列为经过深度优化网络后的深度图结果,可以看出深度图仅存在少量的空间噪声。

2. 增量式网格生成
动机:
在线网格重建的难点在于如何在保证较好重建效果和重建规模的前提下,能够实时在线地重建场景三维表面信息。传统基于TSDF融合的方法虽然能够在线融合深度图,TSDF的更新通常需要在GPU平台上才能达到实时,受平台算力的影响该过程很难在一些中低端的手机上实时应用。
此外,现有的表面网格生成的算法(如Marching Cubes[4])是离线的,难以实现在线增量式表面网格生成和更新。鉴于此,本文希望能够实现一种适合手机端AR应用的实时增量式在线网格生成算法,通过构建一种快速的基于空间索引的voxel hash机制,并对传统的Marching Cubes算法进行改进,使其能够在线增量地扩展场景网格表面,从而重建场景三维信息。同时,考虑到空间中的动态物体可能会对AR遮挡和碰撞效果产生影响,因此本文希望增量式网格生成算法能够快速有效地剔除空间动态物体。
方法:
本文的增量式网格生成方法主要包含三个部分:
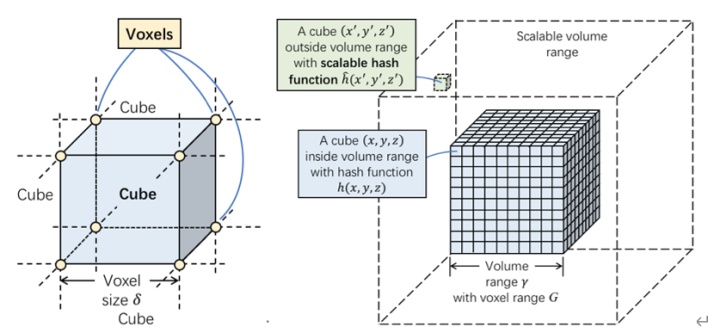
- 可扩展的哈希函数,用于建立空间体素的索引机制
- 体素融合与动态物体移除,用于将计算的深度图融合到体素中,同时移除不在当前场景的动态物体
- 增量式网格更新用于快速提取体素块的网格面片,从而重建场景三维信息
具体方式如下:
① 可扩展的哈希函数

② 体素的融合与动态物体移除
对于输入的每个关键帧深度图,通过将深度值投影到三维的体素块中,从而判断是否需要分配新的体素块,如果需要则将体素块的TSDF和权值信息插入到索引表中,否则按照下式(7)更新当前体素块体素的TSDF值和权重。
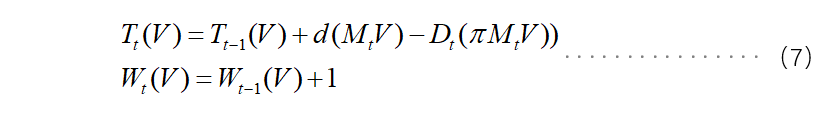
为了处理动态物体产生的网格,本文将可见的体素投影到当前帧深度上进行可视性检查,如果发现与当前深度存在差异,则更改体素的TSDF值。通过这种方式可以使移出场景的动态物体产生的网格被逐渐消除。如图7展示了增量式网格构建过程中动态物体移除的过程。

③ 增量式网格更新


实验结果
本文使用OPPO R17 Pro手机采集带有真实场景深度的5组数据,用于从定性和定量两个方面对比Mobile3DRecon与一些SOTA方法的效果, 其中ground truth为OPPO R17 Pro获取的与单目相机对齐的TOF深度。图9和图10所示为室外楼梯场景分别使用REMODE、DPSNet、MVDepthNet以及本文方法生成深度图和mesh网格,可以看出本文方法生成的深度图细节更加明显,在此基础上生成的网格质量优于其它几种方法。


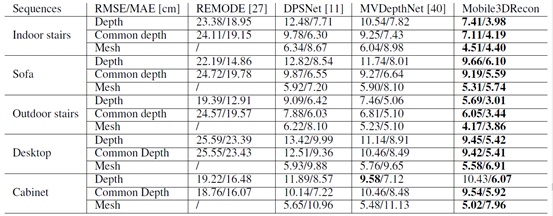
为了定量评价本文方法和REMODE、DPSNet、MVDepthNet生成的深度图和网格的精度,本文对比了5个场景下几种方法的实验结果,如表1所示。
分别统计了几种方法的深度和网格与真值深度(ToF)和真值网格在公共有效区域的RMSE和MAE精度,可以看出Mobile3DRecon方法不论是在深度图还是网格质量上都要优于其它的一些SOTA方法,深度图和网格精度可以达到厘米级。其余4个场景重建的网格结果如图11所示。
表1:Mobile3DRecon系统重建五个由OPPO R17 Pro采集的实验场景的精度评估,每个场景给出了本文的方法和其他方法的深度和网格的RMSE和MAE误差,以ToF深度作为真值。

本文在OPPO R17 Pro和小米8两个中端手机平台上测试了Mobile3DRecon各个过程的耗时,如下表所示。Mobile3DRecon在小米8(高通骁龙845)平台上基本可以达到OPPO R17 Pro(高通骁龙710)两倍的运行速度,然而即使是在性能较弱的OPPO R17 Pro手机上,本系统基于关键帧深度估计和增量式网格构建的过程仍然可以满足每秒5关键帧的运行帧率,从而达到实时的效果。
表2:Mobile3DRecon系统每个关键帧各步骤的详细耗时情况,分别在OPPO R17 Pro和小米8两个手机平台上统计。

图12展示了Mobile3DRecon系统集成到移动端Unity的运行效果,可以看出在OPPO R17 Pro和小米8手机上该系统能够通过精确重建场景表面网格使得虚拟物体的放置不局限于平面结构,同时室内楼梯和打印机场景的示例也展示了虚拟球与真实场景产生的正确遮挡和碰撞交互效果。

结语
本文提出了一个实时的单目三维重建系统,该系统允许用户在一些中端的手机平台上使用单目摄像头提供在线网格生成功能。与现有的基于点云或TSDF的在线重建方法不同,Mobile3DRecon系统可以根据单目摄像头图像鲁棒地估计场景深度,同时将估计的关键帧深度实时增量地融合到稠密网格表面。
本文在两个中端手机平台上验证了Mobile3DRecon系统的重建结果,通过定量和定性的实验验证了所提出的实时单目三维重建系统的有效性。
Mobile3DRecon系统能够正确处理虚拟物体与真实场景之间的遮挡和碰撞,从而达到逼真的AR效果。
References
[1] A. Drory, C, et al. Semi-global matching: A principled derivation in terms of message passing. In German Conference on Pattern Recognition, pp. 43–53. Springer, 2014.
[2] Ummenhofer B, Zhou H, Uhrig J, et al. Demon: Depth and Motion Network for Learning Monocular Stereo. In CVPR, 2017.
[3] Matthias Nießner, Michael Zollhöfer, Izadi S , et al. Real-time 3D Reconstruction at Scale using Voxel Hashing. ACM Transactions on Graphics (TOG), 2013.
[4] W. E. Lorensen and H. E. Cline. Marching cubes: A high resolution 3D surface construction algorithm. ACM SIGGRAPH Computer Graphics, 21(4):163–169, 1987.
[5] P. Ondruska, P. Kohli, and S. Izadi. MobileFusion: Real-time volumetric surface reconstruction and dense tracking on mobile phones. IEEE Transactions on Visualization and Computer Graphics, 21(11):1–1.
[6] Y. Yao, Z. Luo, S. Li, T. Fang, and L. Quan. MVSNet: Depth inference for unstructured multi-view stereo. In ECCV, pp. 767–783, 2018.
[7] S. Im, H.-G. Jeon, S. Lin, and I. S. Kweon. Dpsnet: End-to-end deep plane sweep stereo. In International Conference on Learning Representations, 2019.
论文作者
杨幸彬、周立阳、姜翰青、唐中樑、王元博、鲍虎军、章国锋









)

Timer定时应用实验)







