万字长文 | 详解优酷视频质量评价体系
分享嘉宾|李静博士,阿里巴巴文娱集团资深算法专家,阿里巴巴大文娱摩酷实验室视频体验与质量团队负责人
整理出品|AICUG人工智能社区本文地址:https://www.6aiq.com/article/1617926511225
本文版权归作者和AIQ共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出
导读:随着近年来用户在社交媒体/短视频分享平台的重度参与,视频多媒体内容的消费主导从原来的OGC向UPGC转变。因此UPGC图像/视频的质量评价成为了目前学术界重点关注的研究热点。由于其没有无损的参考图片/视频,研究课题本身即属于质量评价领域最具挑战的无参考质量评价。除此外,社交媒体/短视频分享平台等的视频来源十分复杂且多样,导致质量问题的根源可以追溯到整个视频从拍摄到传输到播放的整个pipeline,由此带来的图像/视频降质的因素为多种失真的叠加。这种对于失真类型的不可控(从失真类型到失真程度两个维度)导致UPGC图像/视频的质量评价更具挑战性。因此如何准确评价新型视觉信息的质量从而极大化用户体验是目前质量评价领域和多媒体视觉领域的热点和难点。
本演讲将围绕5G时代移动社交场景中视频观看体验的评价问题,基于视频内容的生产到应用的pipeline,讲述优酷如何针对不同业务场景打造视频质量评价体系,助力移动端多媒体视频行业的体验标准化工作。
目录
1、优酷主观测评平台
2、算法模型
3、业务应用

对于优酷以及各家视频平台来说,我们会面临着很多质量评价的需求,这个质量是包括各种各样视频或者是图像的。
比如说封面图,它的生产方式有很多种,可以从视频里面去截帧,也可以做一些合成类的封面。但生成的这个封面需要去有一个评价机制去判断它是否满足观众的喜爱度。在其他维度不变的情况下,画面质量越好当然观众越喜爱,它的点击率也会越高,进而形成这样一个良性循环。因此,作为打开视频网站的第一眼,封面图是极其重要的一环。
针对UPGC 的这个视频场景,我们同样也需要这样一个评价的工作。随着抖音、快手近年来在国内外特别的火热,以及我们生活和工作节奏的加快,我们观看视频的习惯也渐渐从长视频向短视频、小视频迁移。除此外,用户也会更多的参与到短小视频的制作中。
在视频制作环节,在采集侧,大家的手机性能拍照设备不尽相同。在传输侧以及后处理,大家会用不同的软件去修图,去做一些美化和滤镜的操作。算法侧在自动生产的时候,也会有字幕擦除,增强超分等操作。这些操作都会导致UPGC 这种视频比传统的长视频在质量评价上更加复杂。
哪种后处理方式会比较好?哪种增强方式或超分方式会对于UPGC 视频产生好的观看效果?这里质量评价算法也是非常重要的环节。特别是对于那些低质量的视频,我们需要在用户上传的第一时间,就对他提出一些建议。比如说你这个视频分辨率太低或者主观感知的清晰度不太好,在分发的时候,有可能不能产生好的分发效果。
在长视频领域,一个比较典型的应用就是老片修复。比如过去的黑白电视,或者早年的一些片子,它的清晰度较差,分辨率也比较低。现在随着4k、8k的普及,当一个低分辨率的视频放到了高分辨率的显示器上时,这个视觉感知效果就更加的明显。因此,我们会经常用一些修复和增强手段以及超分去进行一个后处理操作。随着机器学习、深度学习的发展,增强算法也从传统的一些手工特征进行修复,变成了利用大数据,利用deep learning去做这样的一些修复。因此我们不能再利用传统的质量评价方法去对它进行评判,是因为深度学习带来了增强后的一些不可控的artifacts(失真)。一方面可能会表现为视觉上的增强,但另一方面可能引入的是一些视觉不友好的artifacts。所以我们的质量评价在这一环也是尤其重要的。可以正向的去优化,告诉我们怎么样去进行增强,人才会感觉到这是真的画质增强,而不是将噪声/失真增强。
在视频业务场景中,视觉体验评估还有个比较有意思的应用就是广告特效。我们希望广告能带来收入提升的同时,又不去打扰用户的观看体验。所以我们会生成一些比较有意思的广告特效。那在这种情况下,对于广告特效的视觉注意或者视觉体验的这么一个由主观感知到客观评价的模型是非常重要的。首先是它能指导我们进行广告生产的优化。其次也可以量化这样的广告有多大程度用户是喜欢的,多大程度用户是能够感受到这个广告存在,以及感受不到等等这样一个视觉注意量化结果。
最后一个给大家分享的就是我们今年在街舞3上首次运用的一个to C端的产品化体验,就是自由视点视频(Free-Viewpoint Video, FVV)。用户打开优酷APP,根据大家手机型号的不同,看到的角度范围可能也不太一样。那么在高端机上,我们通常可以给到150度到180度这样一个旋转视角,用户可以任意滑动屏幕去看想看的视角。在这个过程中,里面涉及到的算法迭代也是需要质量评价算法介入去进行一步步优化,以达到用户的流畅性的观看体验。
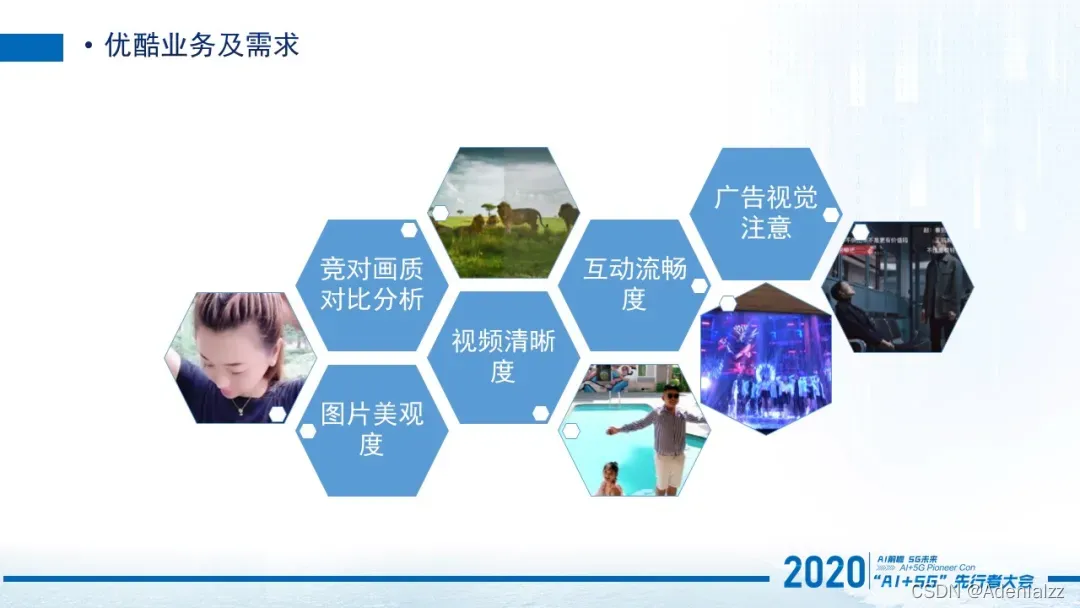
对针业务上的场景,抽象到质量评价这块,我们需要做的是一个体系。这个体系可以针对于图片的美观度进行评价,或者对于画质进行一个对比分析,以及对于UPGC的视频进行清晰度的判断。还有包括刚刚说的自由视点视频这种互动的流畅度,以及广告视觉上的注意力的情况。
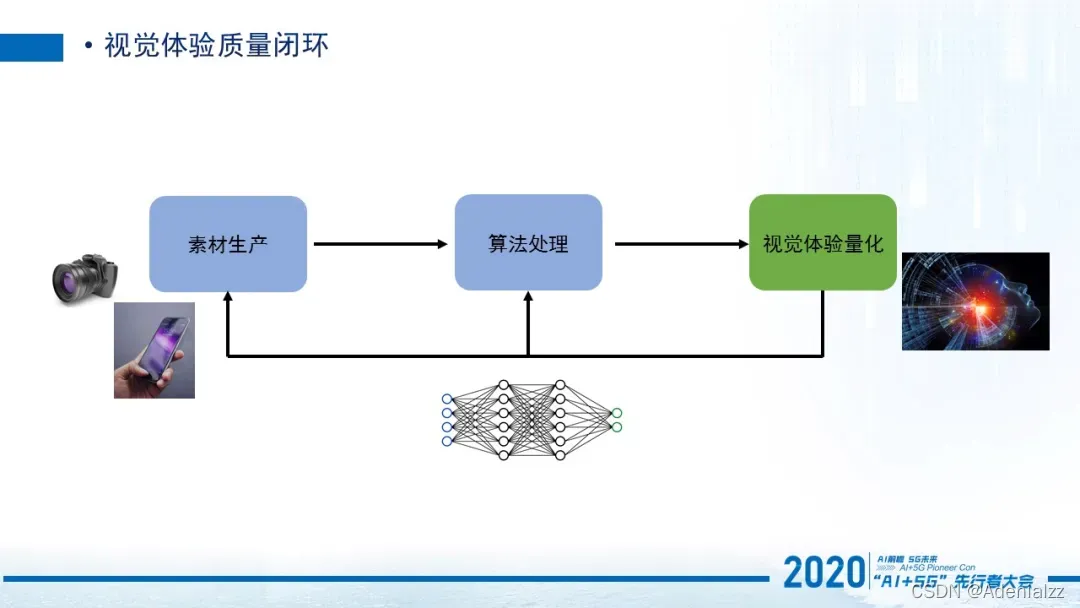
上述讲的业务和技术问题,综合到一个框架下,就形成了这个生产和质量体验量化闭环系统。一旦体验可以量化的话,那么在视频从生产到处理到播放的生命周期中,算法可以进行有效迭代。比如说可以提效,或者是帮助我们提质,它是一个帮助我们优化的过程,这是非常必要的。
当然视觉体验的量化往往也是最难的,因为视觉体验它是一个非常主观的感受。像在传统的CV领域,对于一些物体的检测和识别等任务是非常明确的。比如猫就是猫,狗就是狗。但是在视觉体验中,对于同一个视频,由于每个人的感受都不一样,我认为好,你可能认为不好,这里没有一个对错的标准。所以在这种情况下怎么样去标准化视觉体验是一个非常重要的问题,我们也一直在致力于把体验能够真正的量化起来,标准化下来。
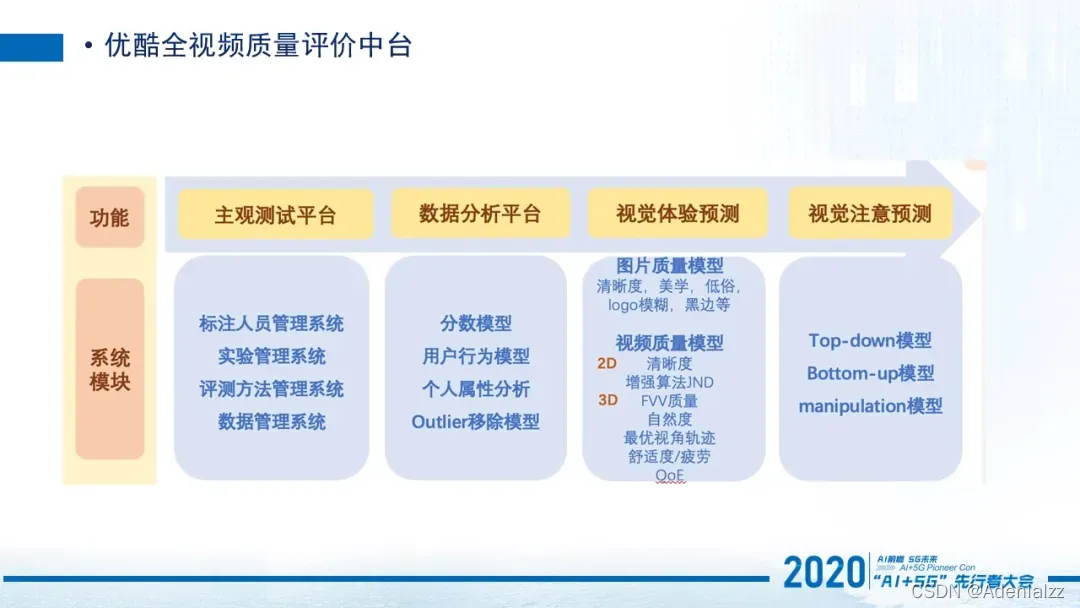
优酷的全视频质量评价中台包含以下4个功能:第一是主观的测试平台,也就是最开始直接通过人去做这样的主观评价去获取数据,然后通过拿到的数据,针对视觉感受进行一个分析。然后我们拿到这个数据之后,就可以进行一些客观模型的研发,比如视觉体验(视觉体验包括各种类型的图片和视频),以及视觉注意的一个预测的工作。
接下来我分三部分去讲下评价体系。第一的话就是最重要的一个是优酷的主观评测平台,这个是基于一切算法模型的一个基本数据,数据是最重要的部分。第二个是算法模型,第三个是我们的业务应用。
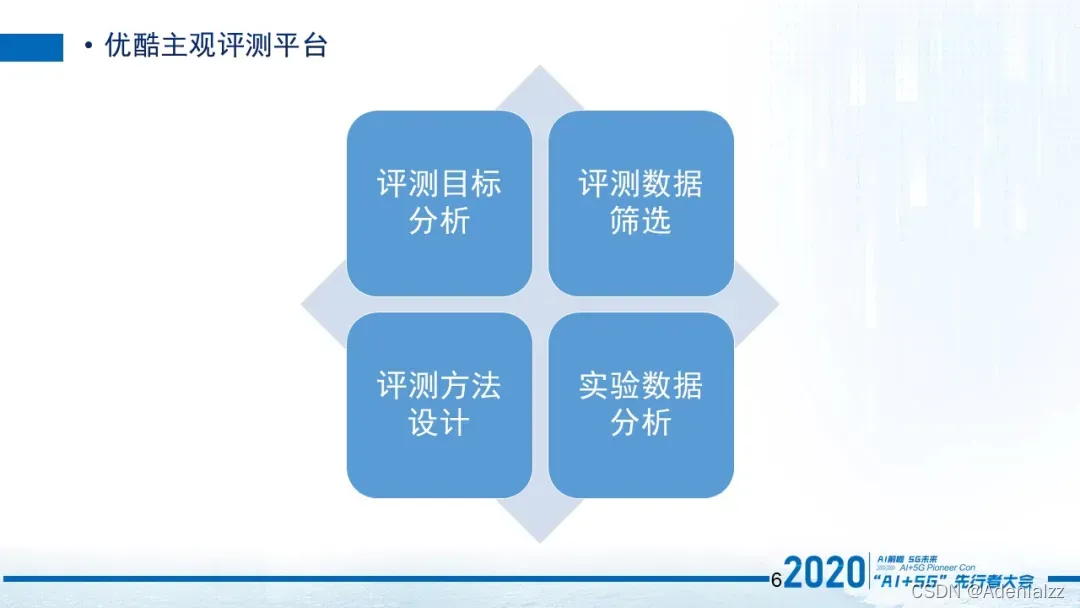
主观评测平台它主要包含四个模块。首先是目标分析模块,然后是数据筛选模块,第三个是评测方法设计,第四是实验数据的分析。接下来会针对这四个模块进行逐一讲解。
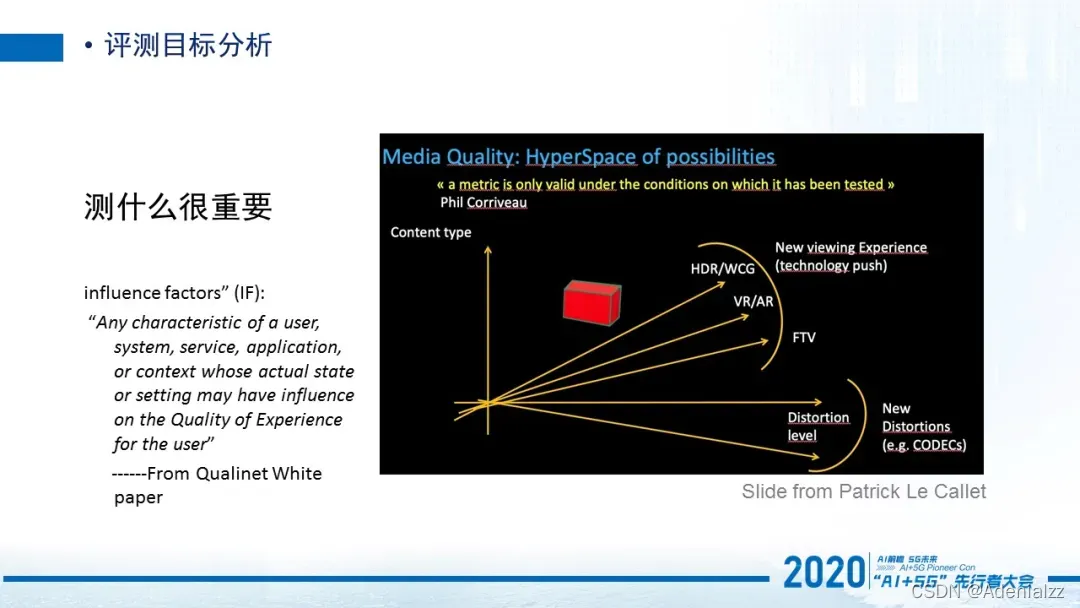
第一个是评测的目标分析。这个通常会被人忽视,当提到质量评价,大家第一反应就是质量评价就是给人看一个东西,然后1到5打分,1就是非常差,5是非常好,用户打分,这个分数就是一个主观分数。那在这个描述中它其实简化了整个过程。我们需要知道的第一点就是你到底想测什么,比如说我们在最开始提到的是针对于封面图,还是针对于UPGC的视频,针对于OGC长视频,还是比如竞品分析的这一块(各家都是在播同一个剧,那么对于各家的编码方式,以及相同带宽情况下所呈现的质量差异),以及包括最新的一些视频技术3D领域的,比如AR、VR或者是自由试点视频。
那这些不同的视频领域或者视频应用场景,到底要测什么,就不再是我们之前所说的1到5的这么一个简单打分的问题了,而是想在业务上达到什么样的目的。所以在Qualinet White paper提到测什么是非常重要的,因为有大量的influence factors在这里边。
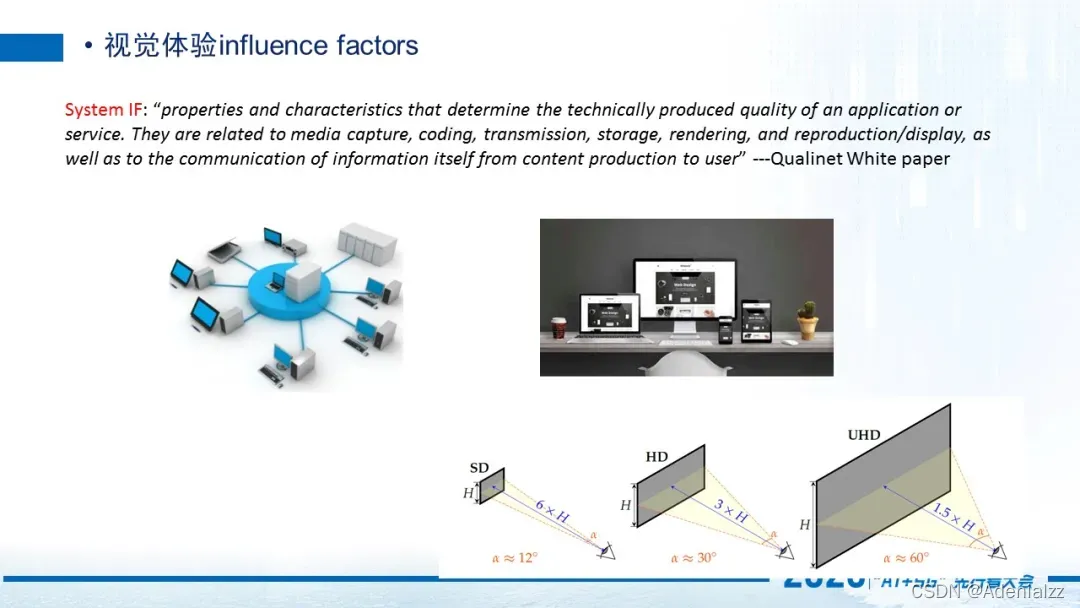
我先讲第一个关于视觉体验有哪些影响因素,第一个影响因素就是系统性的影响因素influence factor。那这里的话主要包括capture,coding,transmission,storage,rendering,以及最后display 的时候。所有的这些环节每个系统的模块都会对视频质量产生一些影响。
长视频领域,因为capture 这一部分大家拿到的视频源是一样。所以最关键的部分,大多数都是在coding和transmission 的阶段。对于终端用户来说,比较重要的是rendering 和display 阶段,也就是用户拿什么样的设备去看。

第二个比较重要的影响因素叫做context influence factor 。这个factor是跟用户的environment相关,包括了它的physical,temporal,social等等。是跟用户当前环境比较相关的一个influence factor。但这个也是经常是被人忽略的。
比如说当观看者,他是在一个非常放松的家庭环境,还是在一个比较嘈杂的咖啡厅,还是我们通常在做主观实验的时候在一个规定的小黑屋标准的环境。那在不同环境下,他所感知到的视频质量是不一样的。

第三个非常关键的因素就是人。每一个人都有自己不同的感受。如果我们把人划分为一些group 的话,比如说性别因素,职业背景等因素以及年龄因素等等,这些也会对于每个人的观看体验产生不一样的影响。举个例子,我们之前做的实验,就会发现女性对于视觉的观看体验相对来说是一个比较positive 的状态,容忍度非常高,大家对于质量好像没有那么高的要求。但是对于男同志来说,一般他们对于观看的清晰度的体验要求就特别高。还有比如年纪较大一点的人群,他们对于质量体验的要求就没有那么高,但对于年轻的同学他们对这质量体验相对就非常高。当然你可以认为这个跟他的背景相关。对于一些年纪比较大的同志来说,在过去的时代中,其实并没有经历太多的这种高质量体验的过程。他们最开始看到的视频甚至从黑白视频开始,过渡到了彩电,从CRT 到HD,再到UHD 这么一个状态。那么到现在的UHD这种极高清体验,甚至VR或者3D电视的时候,其实他们没有更多的参与感在里边。所以过去观看的经验会极大程度影响他对于一个视频的体验判断过程。

知道了这几个非常重要的影响因素以后,我开始讲一下,一旦确定了你要测什么,那接下来就需要进行主观实验了。在进行主观实验的时候,需要测哪些视频,就需要把这些视频都拿过来。
那在这里我们有两个目标,第一,你所选的视频数据必须要满足你的实验目的,就是我刚刚问的那个问题,你要到底测什么,这个非常重要。比如测长视频的竞品分析,那如果把UPGC 的视频放在这里就很不合适,因为它一定不能够满足最终的实验目的。
第二,因为主观实验非常耗时,它需要很多人来参与,花一定的时间去做这样的实验。那么在这种情况下,我们希望可以用最少的数据来满足算法的精度。所以这块就跟传统的CV标签那些领域有极大的差别,传统的CV标签猫就是猫,狗就是狗,所以一个人打标签基本是没有问题的。但是在视觉体验这个评价上,我们一定要用很多的人去做这样的实验。而且需要大量的视频或图像去做实验。但是又不能太大,因为整个实验的时间成本和费用成本非常高,要进行控制。
我们所要做的就是首先分析在所确定的实验目的的前提下,有哪些因子会对实验有影响,然后把这些影响因子有针对性的放在数据筛选过程中。
第二是你知道了这些因素受影响,但是怎么去把这些影响因子可以客观的从数据上获得,也就是你需要有一个数据维度的客观测量。
第三就是采样的策略。比如在早期,你可能会拿到万级或者10万级甚至更高的这样一个视频的数量。但是不可能把这么多的视频全部分发出去去做主观实验。在这里面一定有一个采样策略,需要有针对性的在这些视频里选出最有代表性的一些视频。而这些代表性的视频是由前面的数据维度测量的指标,和前面的影响因子分析来共同决定的。

讲完实验数据的确定之后,我们就进入了主观方法设计阶段,也就是用什么方法去测。这个一定是跟你实验目的挂钩的。那这里先介绍几个经典的主观评测方法,是ITU他们几十年前就已经制定了的一些标准方法。
比如说最传统的ACR(Absolute Categorical Rating) 方法。从1到5打分, 1代表非常糟糕,5代表非常好。在ITU最近的一个标准中,针对于3D的情况下, ACR其实也可以用在视觉舒适度的评测上。比如1分就代表非常不舒适,那5就代表非常舒适。当然在这个维度下,我们其实是有一些争议的。就是当我们去测量一个画质的清晰度的时候,这对于用户来说其实是一个相对简单的视觉任务,因为我们基本是从小到现在每天都在看视频,知道什么样的视频是质量好的,什么是不好的。但对于3D或者VR,并不是所有的人每天都在看这个东西。所以他曾经看到的3D内容,决定了他对于这个维度上的评判标准。比如他过去看的VR,是一段极其精彩的,非常美妙的官方发布的一个demo,那这种视频在很大程度上是避免了视觉疲劳等等一系列不好的体验。那用户看过这个之后,他就会觉这个是非常沉浸式的,非常棒的,没有视觉不舒适这种问题。但是如果一个人过去没有看过好的,只看过一些比较糟糕的,清晰度极低的,戴上了以后转一圈头就开始晕的这种视觉体验的话,那这个标准跟刚刚说的第一个人标准就是完全不同。
在这种情况下,如果让不同的人去给一个要评测的3D的一个视频进行视觉舒适度打分,这个时候就会有极大的差距在。因为大家的评判标准极其不一样,但是所有人又都是对的。甚至还有一些用户之前都没看过VR,你第一次给他看VR让他进行打分,他可能根本无法用5个刻度对视觉舒适度进行划分。
所以在某些评测任务中,这种1到5的简单打分是不能够代表用户的视觉感知的,这个ACR 的评测方法通常被认为是在复杂任务下是不具有这个精度辨别能力。当然在大家经常看的这种已经有足够经验的,比如画质这个问题上,其实ACR就已经足够好了,它的精度基本满足要求。

另外一个评价方法就是如果ACR不是那么的准确的话,那么比较法会相对更加准确。比较法是执行起来极其简单,但是整个过程会非常耗时的一个方法。比较法其实也分为两种:一种就是配对比较法,就是我给你两个激励,比如两个视频或者两个图片,然后每次随机的左右排序,顺序是不一样的。然后分发给观测者问大家,你觉得哪个质量好,或者是针对于3D的任务,你觉得哪个视觉的不舒适度会更高一些。那么这种情况下,即便用户过去没有什么体验,但是在针对这种左右类似于binary 的结果来说,判断起来也会相对容易一些,不同的人给出来的结论基本是一致的。
那另外一种方法叫DSIS,每一次我把参考视频都放在左边,是固定的。并且告诉用户这是一个参考视频,它就是完美的、无瑕的,就是我要的视频。那么右边放一个待测的视频,这个视频可能是经过各种算法处理过的,压缩增强或者超分过的等等。在这种情况下,去让用户给这个待测的视频进行打分。那打分的维度就是跟据左边的完美的参考来比,你觉得它们俩之间是什么样子,可以要用1到5打分。所以这样其实左和右给到的测量维度是不太一样的。一个是Pair comparison,它是单纯的从你的视觉感受上来说左和右哪个好。但是DSIS这是我已经有基准的是最好的,我需要测量的是跟它的差别有多少。Pair comparison 方法的应用场景非常多。比如像facebook 的早期,face mash 这个产品其实用的就是Pair comparison 的方法。

第三个介绍的方法是AccAnn (Acceptability Annoyance Method),它是一种用于测量用户对于视觉感知接受度和容忍度的方法。这个可以用在哪儿?在一些业务场景中,我们有不同的用户人群,例如非会员用户和会员用户;其次针对于用户可能有不同的观看设备,比如说用户可以用手机来看,或者用ipad 来看,或者PC来看。在这个时候我们希望针对不同的用户人群,不同的观看设备,测量他对于视觉感知的容忍度和接受度是怎么样的。
对于一个视频,如果5分是满分的话,我们不太关注这个视频是1.5分还是1.2分,或者4.6分还是4.8分,就是对于这种精细度评判,我们在某些场景其实没有那么高要求。但是我们希望知道的是低于哪个阈值的时候,用户就无法容忍会离开,或者是高于某个阈值的时候,用户对于质量提升就没有感知了,再增加带宽用户也没有明显的差异感受。所以找到这两个阈值是极其重要的。
那这个方法其实就是找到这两个阈值,最终可以帮助我们去知道针对于不同的用户人群和不同的观看设备下,什么样的质量体验是必须的,并且尽可能避免低于这个质量。
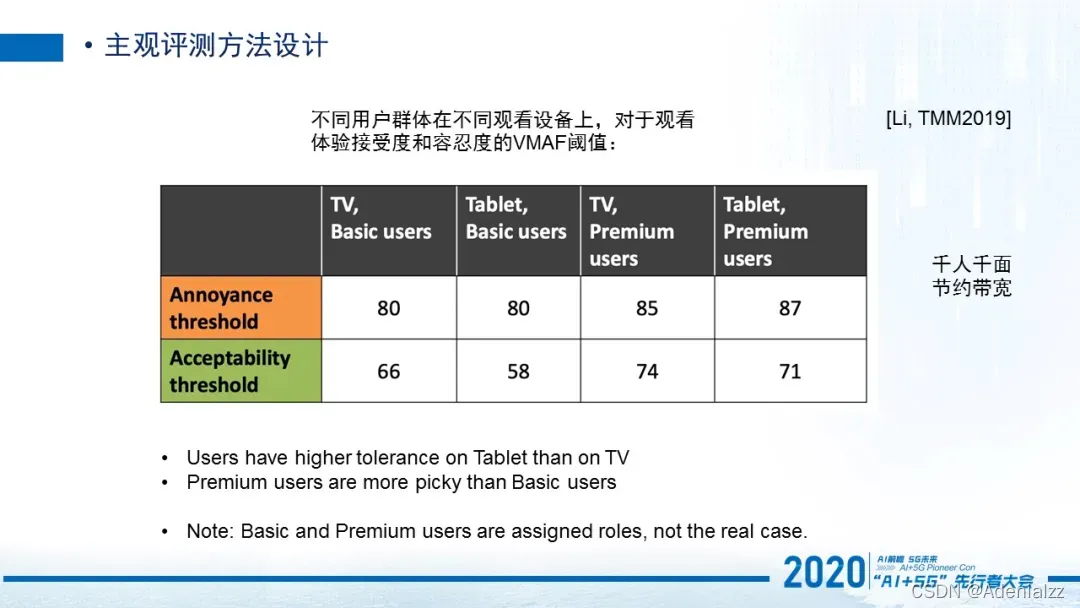
我们曾经在实验室环境测试过,在TV上和Tablet上,我们实验虚拟出来一些假设的普通用户和premium 用户,最终他们的VMAF 的质量分所对应的这两个阈值确实是不一样的。如这个图所示,我们就知道在今后的视频质量评价中,如果用VMAF的话,在用TV观看视频时,高于80分,其实就觉得非常满意了。那低于66分的时候的用户就会觉得不能接受,就可能要离开这个视频平台。当然这是一个我们实验的数据,并不是真实的业务数据,这里只是提供一个参考。
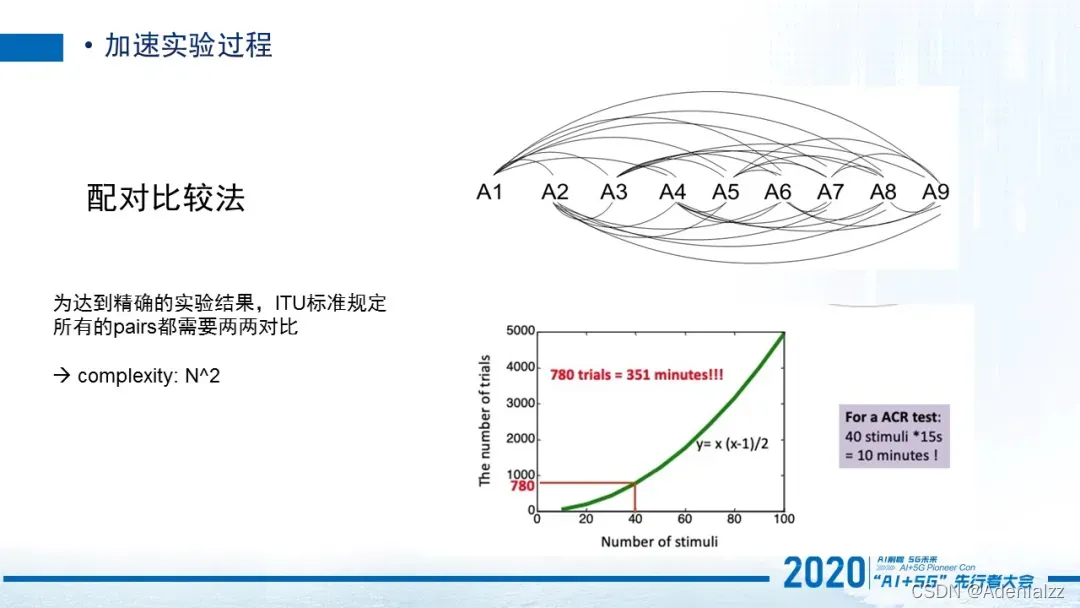
除此以外有一些实验过程其实是可以加速的。刚刚讲的配对比较法,它非常的快而且非常的准确。但是它非常耗时。因为ITU规定了如果你想达到精确的结果,就必须对于所有的视频对都要进行两两比较,那这个量级就非常的大了。针对于同样的一个视频质量评价的实验,比如说有40个视频需要去测试它们的质量。如果使用ACR的方法(1到5打分的方法),对于每一个观测者来说,他10分钟就能完成这个任务了。但是如果用这种配对比较法,就需要耗掉351分钟,所以这基本是一个不可能实现的任务。
所以针对配对比较法,学术界提出了很多加速方法。比如最简单的就是随机采样,就是我们可以随机的去选择比较一些对,再随机的选择另外一些对不比较。当然这里可以有一些random 采样的一些策略,这是一种最简单最直接的方法。
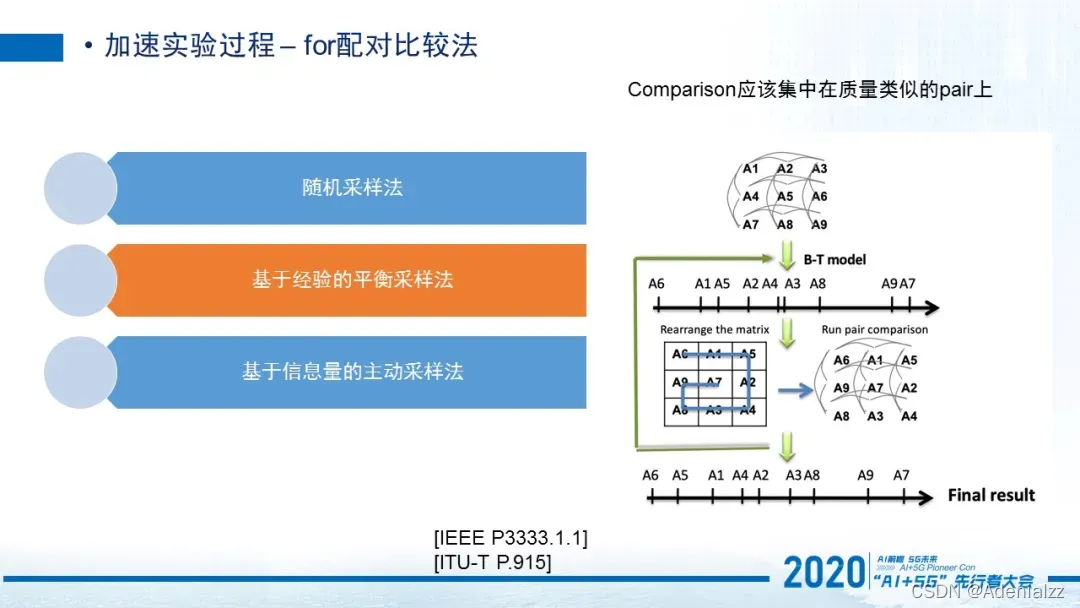
第二是基于经验的平衡采样法, 是我在博士期间提出来的一个方法,被ITU和IEEE标准收录。它是指每一个视频它出现在用户的评测过程中的概率是一致的,不会出现某些视频永远被呈现出来,让用户看,而有些视频就永远不被呈现。我们尽量避免这样的问题,所以这是一个平衡采样法。
这里有个经验,就是我们尽量集中在质量相似的对比实验上,那对于一些质量差异非常大的视频,我们其实没有必要花那么多精力在上面。比如一个270p的一个视频和一个4k视频,那是显而易见4K视频会质量好很多,或者针对于比特率我们也可以有类似的判断。所以我们应该把budget放在这样质量相似的pair上。基于这样的经验,再基于这样一个平衡性的假设,我们最后可以做到这样的平衡采样法。
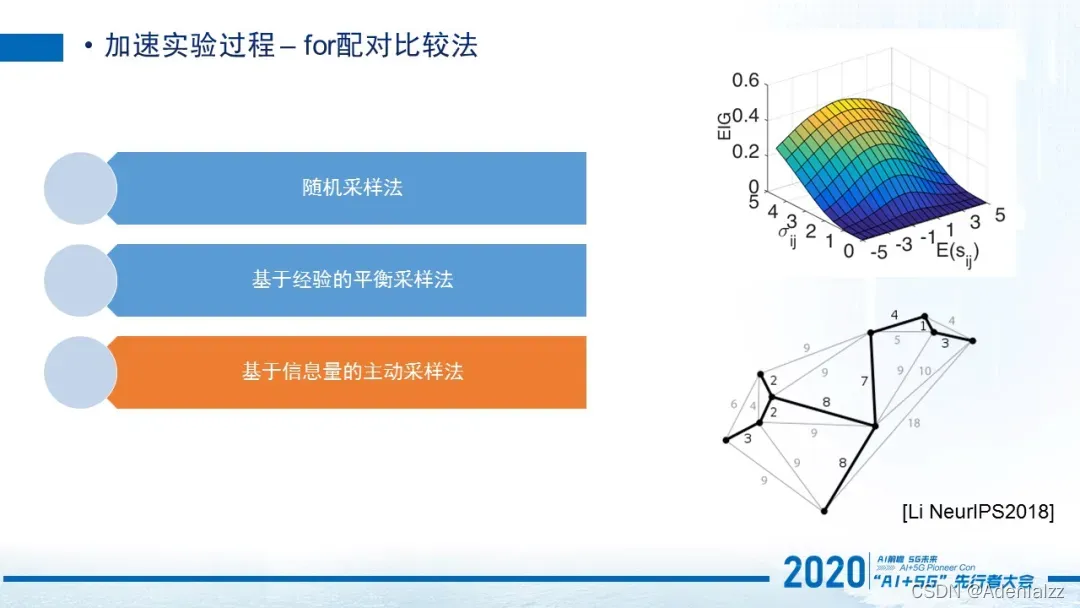
第三个,从数学理论上来讲,是接近于最优化的一个方法,就是基于信息量的主动采样法。这个是我2018年发表在NeurIPS上的工作。上面这个图EIG(Expected Information Gain)就是每个视频对期望的信息增益,横坐标代表的是两个视频之间分数差,y坐标代表是两个视频之间它的分数差的方差。那这里我们给大家一个概念,就是对于两个视频,如果质量越相近,那在我们给它打分的过程中,这两个视频结果产生的信息增益是最多的。那我们其实就是需要把这些能够产生最大信息增益的pair挑出来去进行质量评价,最终可以达到最优化budget的目的。

所以,现在主观实验方法设计好了,主观的实验的流程也加速了。当我们拿到这些实验数据的时候,接下来需要思考的是,如何滤除outlier,如何recover ground truth的问题。非常常见的是在实验过程中,一定会有人不小心按错按钮。比如说在配对比较的时候,他本来想选左边,结果他按了个右,或者是把问题理解错了,把1分和5分他搞反了,以为1是最好5是最差。也有一些人在打分的时候可能会特别的宽容,觉得每一个视频质量都非常好,所以打分比较偏向于永远打4分或者是5分。但有一些人相反,他觉得你给我的这些视频太差了,他跟我过去比看到的那些4k、8k视频简直没有办法比,所有的都在他接受的阈值之下,所以他都是打1分或者2分。每个人都有自己的判断标准,而每个人在打分过程中又可能会有不同的情况发生。那我们应该怎么样去处理这个数据,得到一个相对准确的,接近于我们假设的一个视觉感知ground truth的情况呢?最直接的方法就是增大观测数据量,通过堆人的方式。但是本来视频质量的主观实验已经是一个耗时的过程,又通过增加人的方式它就更加耗时。所以就会又耗时,又耗钱,又耗精力,为了完成这么一个滤除outlier的过程。这对于大部分人来说都会比较困难。那怎么办?
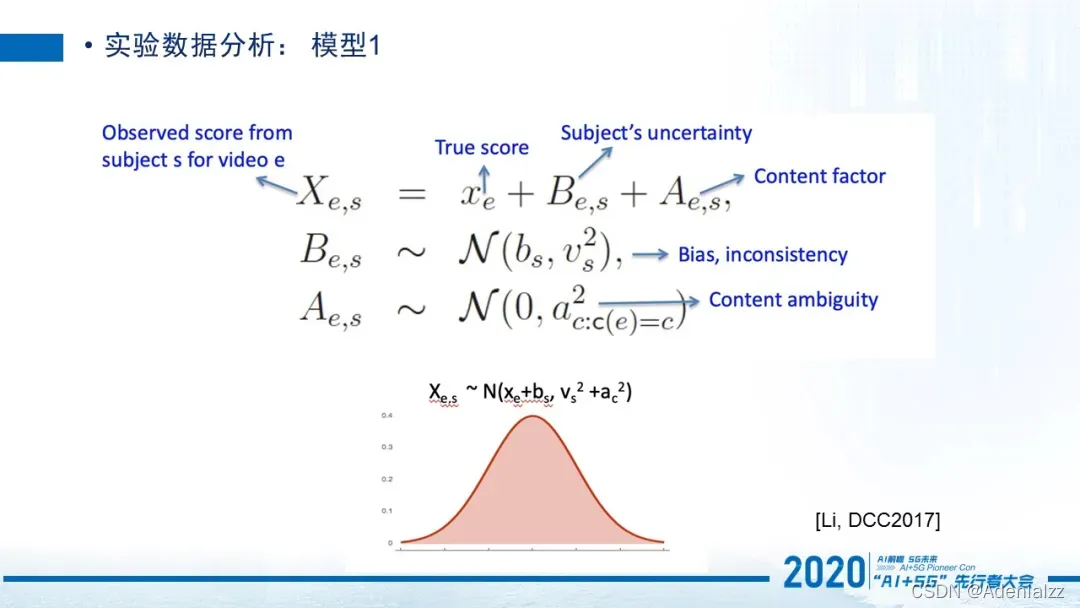
我们会采用一些数据分析模型。比如假设所有用户针对于某一个视频进行打分之后,可以看到这个分数类似于一个高斯分布。它的均值其实是由一个ground truth和这个当前用户他自己的bias来决定的。这个方差其实是由当前用户他在打分过程中的不确定性,以及这个视频本身内容的ambiguity共同来决定的。
什么是用户的bias?可以理解成有的用户总是打分偏高,或者是有些用户打分总是偏低,那么他会在这个针对于ground truth的分数上会有上下偏差,所以每个人都有他自己的偏差。那稳定性是什么?就是有些用户,你给他多少次相同的视频,他给出来的分基本是一致的。但有些用户就很不稳定,就是即便无数次的重复同一个视频,在不同的情况下给他重复同一个视频,让他去进行评判,他都很可能给出非常不同的分数,那么他的这个inconsistency 值相对来说要高一些。
对于视频内容来说,它只影响分数的方差,但不影响ground truth的分数。有些内容它对所有人来说,都是非常容易打分的,比如如果我给你一个纯黑色的界面,让你说它的目前清晰度如何,那它清晰度基本是完美的。所以这个内容是没有ambiguity的。
但是如果是比较奇怪的一些内容,有的人就会说这个内容,我觉得它质量非常好,但有些人会觉得这种质量非常糟。所以这种内容,它就会引起极大的用户意见不统一。所以它的ambiguity就会非常高。
针对于这样的假设,我们会提出这样高斯模型,然后再利用一些算法,把这个参数预估出来,就可以最终恢复或者recover我们想要的ground truth和每一个用户不同的parameter ,以及我们视频内容的parameter 。
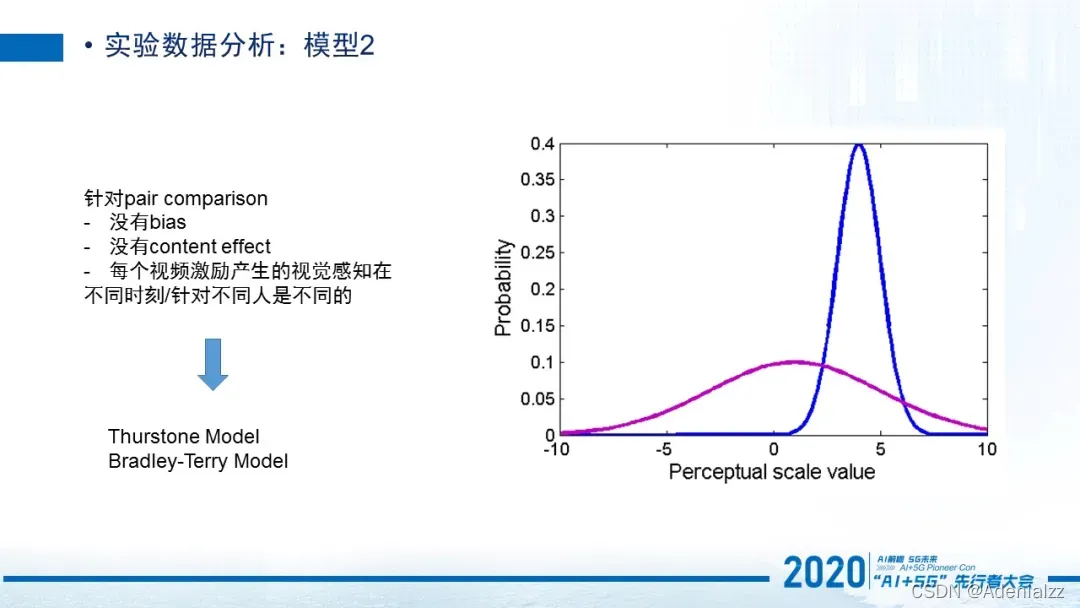
第二个模型是针对于pair comparison的。它还有一个特点就是每一个视频分数它依旧是服从高斯分布的。但是在pair comparison过程当中,每一个人他的bias和content effect不存在了,所以会减少一些特征。那最终我们可以使用一些模型,比如Thurstone模型或者Bradley-Terry模型,针对于这个分布最终可以获得一些参数,而这个参数最终可以帮我们去估计出基于所有视频对儿结果的情况下,每一个视频其实它真实的一个质量是什么样的。
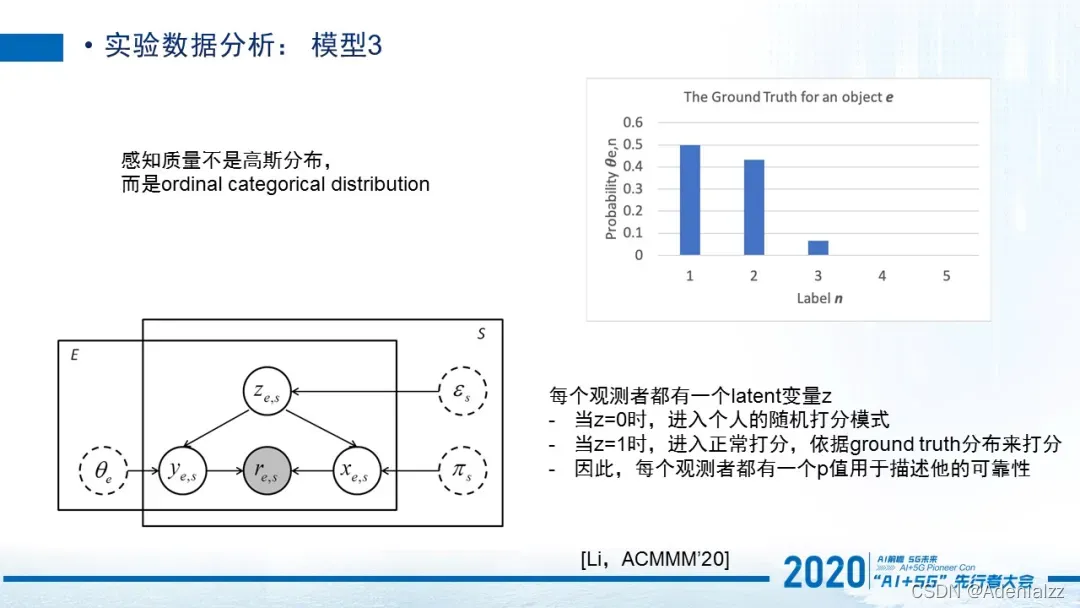
第三个模型相对来说会不太一样,它认为感知质量不是一个高斯分布。是我发表在2020年ACM MM上的一个工作。因为我们平时打分12345,它是一个离散的值,并不呈现一个高斯态,而且它是个截断的状态。所以我们认为它呈现的是一个ordinal categorical distribution。那在这种ground truth的假想下,我们认为每个观测者他都含有一个隐变量,就是他有时候会进入一个正常打分模式,但有时候会进入一个随机打分模式。然后用一个p 值去描述他的可靠性,也就是他从0和1之间转变的一个概率,最终获得这样一个模型去最终预测ground truth应该是什么样,以及每一个人他的p值应该是什么样的,那这是一个区别于之前的一个比较特别的模型。
最后给大家看一下我们的主观评测平台,这里展示的只是一个非常简单的1到5打分的测试平台,你可以看到它显示的视频内容。我们要求播放器是不可以改变视频它本身的resolution的。测试视频的resolution是由实验设计者来决定的。比如说你就是想保持它原视频的分辨率去进行观测,那你就按照原视频去播。但如果你要是想测不同分辨率视频他们在1080p的情况下是什么样的感知质量,那你就需要把不同分辨率的视频全部rescale到1080p,然后统一再在测试平台给用户进行评测。这个就是我们1到5打分的ACR平台。

最后给大家快速过一下我们的客观模型和业务的应用场景。一共有三个场景。

第一个要给大家介绍的就是图像和视频清晰度的评价模型。这是一个基于深度学习的无参考质量评价模型。比如说在这里我们评价了增强版的《还珠格格》视频,以及士兵突击的视频和大江大河的视频,它们的客观质量分预测出来的是符合人眼的主观感受的,所以这个质量分也应用在我们的业务场景中,帮助算法,排序、分发,进行前期的一些处理、筛选。
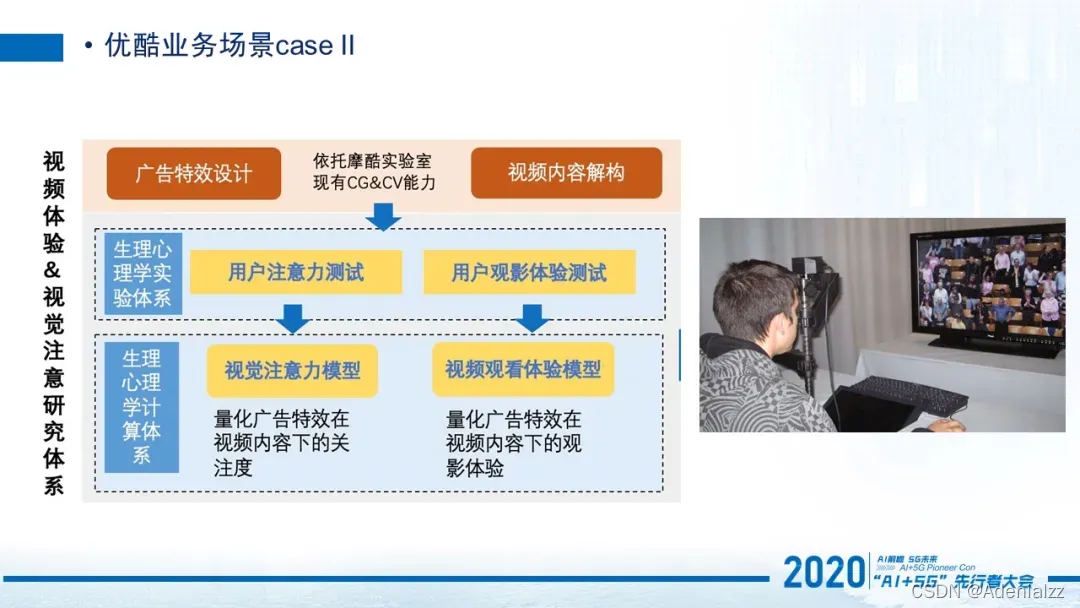
那第二个场景就是广告场景。在这个场景中,我们用了两个模型,一个是视觉注意模型,一个是观看体验模型。它最终呈现的效果是能让广告受人关注,但又不打扰观看体验。

像上面这两个是不好的广告例子,比如左边这个有硬生生的一个压屏条广告,而右边的植入广告是在用户看不到的地方。

我们会进行一些优化的动作,比如增加一些光影特效,这样可以增加一些用户的注意力,但同时并不打扰整个内容观看。右边是通过一点点的光影特效,会把这个区域,从之前的非视觉注意区域,变成一个注意区。

第三个业务场景,就是《这!就是街舞3》的这次自由视点视频算法迭代升级。比如最开始,算法在重建的时候是有一些问题的。对于某些遮挡情况,当我们生成了虚拟视角的时候,它是有一些黑洞存在的,所以在这种情况下,质量分会相对偏低。但是经过一些算法的迭代和优化,我们就会把由遮挡引起的重建的问题给解决掉,那么之前存在黑洞的水面就会变得非常平滑。用户在左右观看的时候就不会出现那种黑洞闪烁的问题,这个质量分也会高一些,告诉我们这个重建算法是比之前的版本要好的。
嘉宾介绍
李静,博士,阿里巴巴文娱集团资深算法专家,阿里巴巴大文娱摩酷实验室视频体验与质量团队负责人。2013年获法国南特大学计算机博士学位,2014年新加坡南洋理工大学访问学者,2014-2016任法国南特大学助理教授,2014-2019任法国国家科学院IPI/LS2N实验室研究员。2019年加入阿里巴巴。研究方向包括生理心理学实验方法论,多媒体视觉体验质量评价,3D视觉,机器学习等。国际质量专家组VQEG成员,国际标准组织IEEE P3333.1成员,欧盟Qualinet成员,AVS视频标准质量评价组成员。ACMMM 2020 QoEVMA workshop组织者。参与制定多个IEEE以及ITU国际标准,担任多个国际期刊与会议评审。








)






![docker gpu报错Error response from daemon: could not select device driver ““ with capabilities: [[gpu]]](http://pic.xiahunao.cn/docker gpu报错Error response from daemon: could not select device driver ““ with capabilities: [[gpu]])



