模式是 Rust 中特殊的语法,它用来匹配类型中的结构,无论类型是简单还是复杂。结合使用模式和 match 表达式以及其他结构可以提供更多对程序控制流的支配权。模式由如下一些内容组合而成:
- 字面值
- 解构的数组、枚举、结构体或者元组
- 变量
- 通配符
- 占位符
这些部分描述了我们要处理的数据的形状,接着可以用其匹配值来决定程序是否拥有正确的数据来运行特定部分的代码。
我们通过将一些值与模式相比较来使用它。如果模式匹配这些值,我们对值部分进行相应处理。
18.1 所有可能会用到模式的位置
模式出现在 Rust 的很多地方。你已经在不经意间使用了很多模式!本部分是一个所有有效模式位置的参考。
match分支
如第六章所讨论的,一个模式常用的位置是 match 表达式的分支。在形式上 match 表达式由 match 关键字、用于匹配的值和一个或多个分支构成,这些分支包含一个模式和在值匹配分支的模式时运行的表达式:
match VALUE {PATTERN => EXPRESSION,PATTERN => EXPRESSION,PATTERN => EXPRESSION,
}
match 表达式必须是 穷尽(exhaustive)的,意为 match 表达式所有可能的值都必须被考虑到。一个确保覆盖每个可能值的方法是在最后一个分支使用捕获所有的模式:比如,一个匹配任何值的名称永远也不会失败,因此可以覆盖所有匹配剩下的情况。
有一个特定的模式 _ 可以匹配所有情况,不过它从不绑定任何变量。这在例如希望忽略任何未指定值的情况很有用。本章之后的 “忽略模式中的值” 部分会详细介绍 _ 模式的更多细节。
if let条件表达式
第六章讨论过了 if let 表达式,以及它是如何主要用于编写等同于只关心一个情况的 match 语句简写的。if let 可以对应一个可选的带有代码的 else 在 if let 中的模式不匹配时运行。
下面展示了也可以组合并匹配 if let、else if 和 else if let 表达式。这相比 match 表达式一次只能将一个值与模式比较提供了更多灵活性;一系列 if let、else if、else if let 分支并不要求其条件相互关联。
下面的代码展示了一系列针对不同条件的检查来决定背景颜色应该是什么。为了达到这个例子的目的,我们创建了硬编码值的变量,在真实程序中则可能由询问用户获得。
fn main() {let favorite_color: Option<&str> = None;let is_tuesday = false;let age: Result<u8, _> = "34".parse();if let Some(color) = favorite_color {println!("Using your favorite color, {} as the backgroud", color);} else if is_tuesday {println!("Tuesday is green day");} else if let Ok(age) = age {if age > 30 {println!("Using purplr as the backgroud color");} else {println!("Using orange as the backgroud color");}} else {println!("Using blue as the backgroud color");}
}
如果用户指定了中意的颜色,将使用其作为背景颜色。如果今天是星期二,背景颜色将是绿色。如果用户指定了他们的年龄字符串并能够成功将其解析为数字的话,我们将根据这个数字使用紫色或者橙色。最后,如果没有一个条件符合,背景颜色将是蓝色:
这个条件结构允许我们支持复杂的需求。使用这里硬编码的值,例子会打印出 Using purple as the background color。
注意 if let 也可以像 match 分支那样引入覆盖变量:if let Ok(age) = age 引入了一个新的覆盖变量 age,它包含 Ok 成员中的值。这意味着 if age > 30 条件需要位于这个代码块内部;不能将两个条件组合为 if let Ok(age) = age && age > 30,因为我们希望与 30 进行比较的被覆盖的 age 直到大括号开始的新作用域才是有效的。
if let 表达式的缺点在于其穷尽性没有为编译器所检查,而 match 表达式则检查了。如果去掉最后的 else 块而遗漏处理一些情况,编译器也不会警告这类可能的逻辑错误。
while let条件循环
一个与 if let 结构类似的是 while let 条件循环,它允许只要模式匹配就一直进行 while 循环。
fn main() {let mut stack = Vec::new();stack.push(1);stack.push(2);stack.push(3);while let Some(top) = stack.pop() {println!("{}", top);}}
这个例子会打印出 3、2 接着是 1。pop 方法取出 vector 的最后一个元素并返回 Some(value)。如果 vector 是空的,它返回 None。while 循环只要 pop 返回 Some 就会一直运行其块中的代码。一旦其返回 None,while 循环停止。我们可以使用 while let 来弹出栈中的每一个元素。
for循环
如同第三章所讲的,for 循环是 Rust 中最常见的循环结构,不过还没有讲到的是 for 可以获取一个模式。在 for 循环中,模式是 for 关键字直接跟随的值,正如 for x in y 中的 x。
let v = vec!['a', 'b', 'c'];for (index, value) in v.iter().enumerate() {println!("{} is at index {}", value, index);
}结果

这里使用 enumerate 方法适配一个迭代器来产生一个值和其在迭代器中的索引,他们位于一个元组中。第一个 enumerate 调用会产生元组 (0, 'a')。当这个值匹配模式 (index, value),index 将会是 0 而 value 将会是 'a',并打印出第一行输出。
let语句
在本章之前,我们只明确的讨论过通过 match 和 if let 使用模式,不过事实上也在别地地方使用过模式,包括 let 语句。例如,考虑一下这个直白的 let 变量赋值:
let x = 5;
本书进行了不下百次这样的操作,不过你可能没有发觉,这正是在使用模式!let 语句更为正式的样子如下:
let PATTERN = EXPRESSION;
像 let x = 5; 这样的语句中变量名位于 PATTERN 位置,变量名不过是形式特别朴素的模式。我们将表达式与模式比较,并为任何找到的名称赋值。所以例如 let x = 5; 的情况,x 是一个模式代表 “将匹配到的值绑定到变量 x”。同时因为名称 x 是整个模式,这个模式实际上等于 “将任何值绑定到变量 x,不管值是什么”。
为了更清楚的理解 let 的模式匹配方面的内容,考虑下面使用 let 和模式解构一个元组:
let (x, y, z) = (1, 2, 3);
这里将一个元组与模式匹配。Rust 会比较值 (1, 2, 3) 与模式 (x, y, z) 并发现此值匹配这个模式。在这个例子中,将会把 1 绑定到 x,2 绑定到 y 并将 3 绑定到 z。你可以将这个元组模式看作是将三个独立的变量模式结合在一起。
如果模式中元素的数量不匹配元组中元素的数量,则整个类型不匹配,并会得到一个编译时错误。
let (x, y) = (1, 2, 3);
尝试编译这段代码会给出如下类型错误:
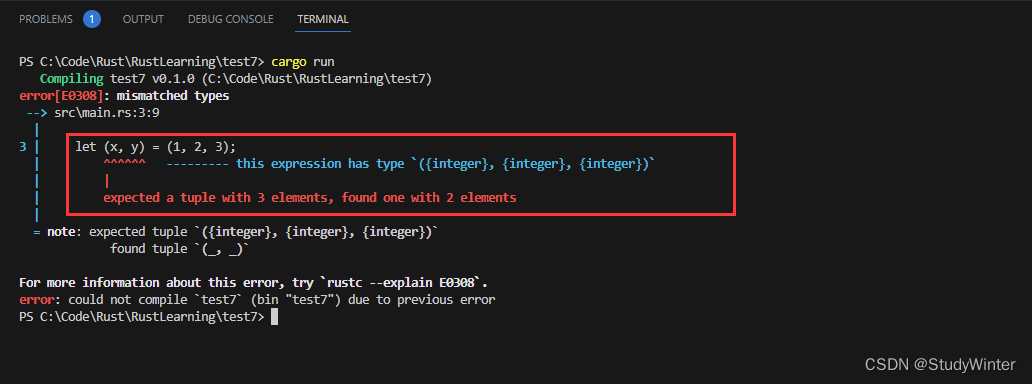
如果希望忽略元组中一个或多个值,也可以使用 _ 或 ..,如 “忽略模式中的值” 部分所示。如果问题是模式中有太多的变量,则解决方法是通过去掉变量使得变量数与元组中元素数相等。
函数参数
函数参数也可以是模式。
fn foo(x: i32) {// 代码
}
x 部分就是一个模式!类似于之前对 let 所做的,可以在函数参数中匹配元组。
fn print_coordinates(&(x, y): &(i32, i32)) {println!("Current location: ({}, {})", x, y);
}fn main() {let point = (3, 5);print_coordinates(&point);
}
这会打印出 Current location: (3, 5)。值 &(3, 5) 会匹配模式 &(x, y),如此 x 得到了值 3,而 y得到了值 5。
18.2 Refutability (可反驳性)︰模式是否会匹配失效
模式有两种形式:refutable(可反驳的)和 irrefutable(不可反驳的)。能匹配任何传递的可能值的模式被称为是 不可反驳的(irrefutable)。一个例子就是 let x = 5; 语句中的 x,因为 x 可以匹配任何值所以不可能会失败。对某些可能的值进行匹配会失败的模式被称为是 可反驳的(refutable)。一个这样的例子便是 if let Some(x) = a_value 表达式中的 Some(x);如果变量 a_value 中的值是 None 而不是 Some,那么 Some(x) 模式不能匹配。
函数参数、 let 语句和 for 循环只能接受不可反驳的模式,因为通过不匹配的值程序无法进行有意义的工作。if let 和 while let 表达式被限制为只能接受可反驳的模式,因为根据定义他们意在处理可能的失败:条件表达式的功能就是根据成功或失败执行不同的操作。
通常我们无需担心可反驳和不可反驳模式的区别,不过确实需要熟悉可反驳性的概念,这样当在错误信息中看到时就知道如何应对。遇到这些情况,根据代码行为的意图,需要修改模式或者使用模式的结构。
让我们看看一个尝试在 Rust 要求不可反驳模式的地方使用可反驳模式以及相反情况的例子。
let Some(x) = some_option_value;
如果 some_option_value 的值是 None,其不会成功匹配模式 Some(x),表明这个模式是可反驳的。然而 let 语句只能接受不可反驳模式因为代码不能通过 None 值进行有效的操作。Rust 会在编译时抱怨我们尝试在要求不可反驳模式的地方使用可反驳模式:
error[E0005]: refutable pattern in local binding: `None` not covered-->|
3 | let Some(x) = some_option_value;| ^^^^^^^ pattern `None` not covered
因为我们没有覆盖(也不可能覆盖!)到模式 Some(x) 的每一个可能的值, 所以 Rust 会合理地抗议。
为了修复在需要不可反驳模式的地方使用可反驳模式的情况,可以修改使用模式的代码:不同于使用 let,可以使用 if let。如此,如果模式不匹配,大括号中的代码将被忽略,其余代码保持有效。
if let Some(x) = some_option_value {println!("{}", x);
}
我们给了代码一个得以继续的出路!这段代码可以完美运行,尽管这意味着我们不能再使用不可反驳模式并免于收到错误。如果为 if let 提供了一个总是会匹配的模式
if let x = 5 {println!("{}", x);
};
Rust 会抱怨将不可反驳模式用于 if let 是没有意义的:
warning: irrefutable if-let pattern--> <anon>:2:5|
2 | / if let x = 5 {
3 | | println!("{}", x);
4 | | };| |_^|= note: #[warn(irrefutable_let_patterns)] on by default
基于此,match匹配分支必须使用可反驳模式,除了最后一个分支需要使用能匹配任何剩余值的不可反驳模式。Rust允许我们在只有一个匹配分支的match中使用不可反驳模式,不过这么做不是特别有用,并可以被更简单的 let 语句替代。
目前我们已经讨论了所有可以使用模式的地方, 以及可反驳模式与不可反驳模式的区别,下面让我们一起去把可以用来创建模式的语法过目一遍吧。
18.3 所有的模式语法
匹配字面值
如第六章所示,可以直接匹配字面值模式。如下代码给出了一些例子:
fn main() {let x = 1;match x {1 => println!("one"),2 => println!("two"),3 => println!("three"),_ => println!("anything"),}
}
这段代码会打印 one 因为 x 的值是 1。如果希望代码获得特定的具体值,则该语法很有用。
匹配命名变量
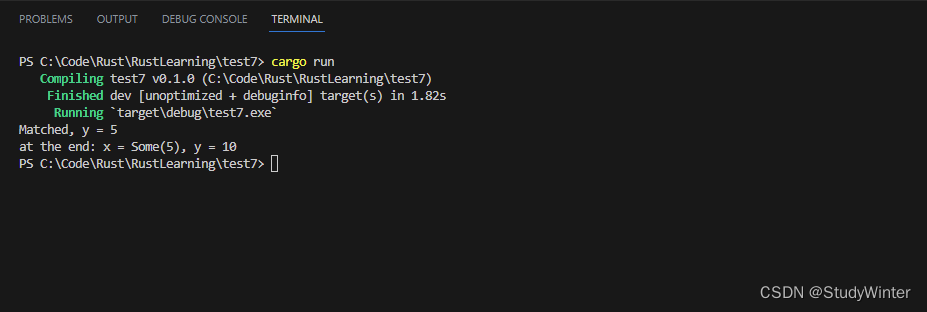
命名变量是匹配任何值的不可反驳模式,这在之前已经使用过数次。然而当其用于 match 表达式时情况会有些复杂。因为 match 会开始一个新作用域,match 表达式中作为模式的一部分声明的变量会覆盖 match 结构之外的同名变量,与所有变量一样。在下面示例中,声明了一个值为 Some(5) 的变量 x 和一个值为 10 的变量 y。接着在值 x 上创建了一个 match 表达式。观察匹配分支中的模式和结尾的 println!,并在运行此代码或进一步阅读之前推断这段代码会打印什么。
fn main() {let x = Some(5);let y = 10;match x {Some(50) => println!("Got 50"),Some(y) => println!("Matched, y = {:?}", y),_ => println!("Default case, x = {:?}", x),}println!("at the end: x = {:?}, y = {:?}", x, y);
}
让我们看看当 match 语句运行的时候发生了什么。第一个匹配分支的模式并不匹配 x 中定义的值,所以代码继续执行。
第二个匹配分支中的模式引入了一个新变量 y,它会匹配任何 Some 中的值。因为我们在 match 表达式的新作用域中,这是一个新变量,而不是开头声明为值 10 的那个 y。这个新的 y 绑定会匹配任何 Some 中的值,在这里是 x 中的值。因此这个 y 绑定了 x 中 Some 内部的值。这个值是 5,所以这个分支的表达式将会执行并打印出 Matched, y = 5。
如果 x 的值是 None 而不是 Some(5),头两个分支的模式不会匹配,所以会匹配下划线。这个分支的模式中没有引入变量 x,所以此时表达式中的 x 会是外部没有被覆盖的 x。在这个假想的例子中,match 将会打印 Default case, x = None。
一旦 match 表达式执行完毕,其作用域也就结束了,同理内部 y 的作用域也结束了。最后的 println! 会打印 at the end: x = Some(5), y = 10。
多个模式
在 match 表达式中,可以使用 | 语法匹配多个模式,它代表 或(or)的意思。例如,如下代码将 x 的值与匹配分支相比较,第一个分支有 或 选项,意味着如果 x 的值匹配此分支的任一个值,它就会运行:
fn main() {let x = 1;match x {1 | 2 => println!("one or two"),3 => println!("three"),_ => println!("anything"),}
}
结果

通过..=匹配值的范围
..= 语法允许你匹配一个闭区间范围内的值。在如下代码中,当模式匹配任何在此范围内的值时,该分支会执行:
fn main() {let x = 5;match x {1..=5 => println!("one through five"),_ => println!("something else"),}
}
结果
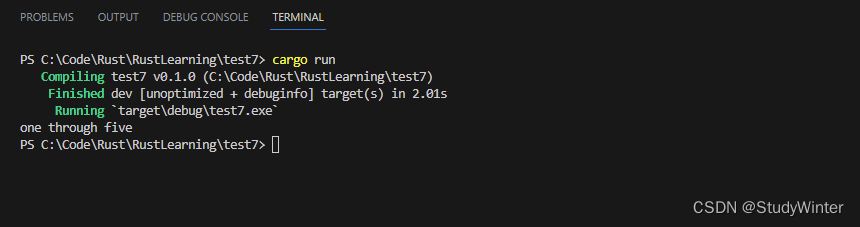
如果 x 是 1、2、3、4 或 5,第一个分支就会匹配。这相比使用 | 运算符表达相同的意思更为方便;相比 1..=5,使用 | 则不得不指定 1 | 2 | 3 | 4 | 5。相反指定范围就简短的多,特别是在希望匹配比如从 1 到 1000 的数字的时候!
范围只允许用于数字或 char 值,因为编译器会在编译时检查范围不为空。char 和 数字值是 Rust 仅有的可以判断范围是否为空的类型。
fn main() {let x = 'c';match x {'a'..='j' => println!("early ASCII letter"),'k'..='z' => println!("late ASCII letter"),_ => println!("something else"),}}
结果

也可以使用模式来解构结构体、枚举、元组和引用,以便使用这些值的不同部分。
解构结构体
下面示例展示带有两个字段 x 和 y 的结构体 Point,可以通过带有模式的 let 语句将其分解:
struct Point {x: i32,y: i32,
}fn main() {let p = Point { x: 0, y: 7 };let Point { x: a, y: b } = p;assert_eq!(0, a);assert_eq!(7, b);
}
这段代码创建了变量 a 和 b 来匹配结构体 p 中的 x 和 y 字段。这个例子展示了模式中的变量名不必与结构体中的字段名一致。不过通常希望变量名与字段名一致以便于理解变量来自于哪些字段。
因为变量名匹配字段名是常见的,同时因为 let Point { x: x, y: y } = p; 包含了很多重复,所以对于匹配结构体字段的模式存在简写:只需列出结构体字段的名称,则模式创建的变量会有相同的名称。
struct Point {x: i32,y: i32,
}fn main() {let p = Point { x: 0, y: 7 };let Point { x, y } = p;assert_eq!(0, x);assert_eq!(7, y);
}
这段代码创建了变量 x 和 y,与变量 p 中的 x 和 y 相匹配。其结果是变量 x 和 y 包含结构体 p 中的值。
也可以使用字面值作为结构体模式的一部分进行进行解构,而不是为所有的字段创建变量。这允许我们测试一些字段为特定值的同时创建其他字段的变量。
下面示例示了一个 match 语句将 Point 值分成了三种情况:直接位于 x 轴上(此时 y = 0 为真)、位于 y 轴上(x = 0)或不在任何轴上的点。
struct Point {x: i32,y: i32,
}fn main() {let p = Point { x: 0, y: 7 };match p {Point { x, y: 0 } => println!("On the x axis at {}", x),Point { x: 0, y } => println!("On the y axis at {}", y),Point { x, y } => println!("On neither axis: ({}, {})", x, y),}
}
第一个分支通过指定字段 y 匹配字面值 0 来匹配任何位于 x 轴上的点。此模式仍然创建了变量 x 以便在分支的代码中使用。
类似的,第二个分支通过指定字段 x 匹配字面值 0 来匹配任何位于 y 轴上的点,并为字段 y 创建了变量 y。第三个分支没有指定任何字面值,所以其会匹配任何其他的 Point 并为 x 和 y 两个字段创建变量。
在这个例子中,值 p 因为其 x 包含 0 而匹配第二个分支,因此会打印出 On the y axis at 7。

解构枚举
编写一个 match 使用模式解构每一个内部值
// 枚举
enum Message {Quit,Move { x: i32, y: i32 },Write(String),ChangeColor(i32, i32, i32),
}fn main() {let msg = Message::ChangeColor(0, 160, 255);match msg {Message::Quit => {println!("The Quit variant has no data to destructure.")}Message::Move { x, y } => {println!("Move in the x direction {} and in the y direction {}",x,y);}Message::Write(text) => println!("Text message: {}", text),Message::ChangeColor(r, g, b) => {println!("Change the color to red {}, green {}, and blue {}",r,g,b)}}
}
这段代码会打印出 Change the color to red 0, green 160, and blue 255。尝试改变 msg 的值来观察其他分支代码的运行。
对于像 Message::Quit 这样没有任何数据的枚举成员,不能进一步解构其值。只能匹配其字面值 Message::Quit,因此模式中没有任何变量。
对于像 Message::Move 这样的类结构体枚举成员,可以采用类似于匹配结构体的模式。在成员名称后,使用大括号并列出字段变量以便将其分解以供此分支的代码使用。
对于像 Message::Write 这样的包含一个元素,以及像 Message::ChangeColor 这样包含三个元素的类元组枚举成员,其模式则类似于用于解构元组的模式。模式中变量的数量必须与成员中元素的数量一致。
解构嵌套的结构体和枚举
目前为止,所有的例子都只匹配了深度为一级的结构体或枚举。当然也可以匹配嵌套的项!
enum Color {Rgb(i32, i32, i32),Hsv(i32, i32, i32),}enum Message {Quit,Move { x: i32, y: i32 },Write(String),ChangeColor(Color),}fn main() {let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));match msg {Message::ChangeColor(Color::Rgb(r, g, b)) => {println!("Change the color to red {}, green {}, and blue {}",r,g,b)}Message::ChangeColor(Color::Hsv(h, s, v)) => {println!("Change the color to hue {}, saturation {}, and value {}",h,s,v)}_ => ()}}match 表达式第一个分支的模式匹配一个包含 Color::Rgb 枚举成员的 Message::ChangeColor 枚举成员,然后模式绑定了 3 个内部的 i32 值。第二个分支的模式也匹配一个 Message::ChangeColor 枚举成员, 但是其内部的枚举会匹配 Color::Hsv 枚举成员。我们可以在一个 match 表达式中指定这些复杂条件,即使会涉及到两个枚举。
解构结构体和元组
甚至可以用复杂的方式来混合、匹配和嵌套解构模式。如下是一个复杂结构体的例子,其中结构体和元组嵌套在元组中,并将所有的原始类型解构出来:
fn main() {struct Point {x: i32,y: i32,}let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
}
这将复杂的类型分解成部分组件以便可以单独使用我们感兴趣的值。
通过模式解构是一个方便利用部分值片段的手段,比如结构体中每个单独字段的值。
有时忽略模式中的一些值是有用的,比如 match 中最后捕获全部情况的分支实际上没有做任何事,但是它确实对所有剩余情况负责。有一些简单的方法可以忽略模式中全部或部分值:使用 _ 模式(我们已经见过了),在另一个模式中使用 _ 模式,使用一个以下划线开始的名称,或者使用 .. 忽略所剩部分的值。让我们来分别探索如何以及为什么要这么做。
使用_忽略整个值
我们已经使用过下划线(_)作为匹配但不绑定任何值的通配符模式了。虽然 _ 模式作为 match 表达式最后的分支特别有用,也可以将其用于任意模式,包括函数参数中
fn foo(_: i32, y: i32) {println!("This code only uses the y parameter: {}", y);
}fn main() {foo(3, 4);
}
这段代码会完全忽略作为第一个参数传递的值 3,并会打印出 This code only uses the y parameter: 4。
大部分情况当你不再需要特定函数参数时,最好修改签名不再包含无用的参数。在一些情况下忽略函数参数会变得特别有用,比如实现 trait 时,当你需要特定类型签名但是函数实现并不需要某个参数时。此时编译器就不会警告说存在未使用的函数参数,就跟使用命名参数一样。
使用嵌套的_忽略部分值
也可以在一个模式内部使用_ 忽略部分值,例如,当只需要测试部分值但在期望运行的代码中没有用到其他部分时。下面示例展示了负责管理设置值的代码。业务需求是用户不允许覆盖现有的自定义设置,但是可以取消设置,也可以在当前未设置时为其提供设置。
fn main() {let mut setting_value = Some(5);let new_setting_value = Some(10);match (setting_value, new_setting_value) {(Some(_), Some(_)) => {println!("Can't overwrite an existing customized value");}_ => {setting_value = new_setting_value;}}println!("setting is {:?}", setting_value);
}
这段代码会打印出 Can't overwrite an existing customized value 接着是 setting is Some(5)。在第一个匹配分支,我们不需要匹配或使用任一个 Some 成员中的值;重要的部分是需要测试 setting_value 和 new_setting_value 都为 Some 成员的情况。在这种情况,我们打印出为何不改变 setting_value,并且不会改变它。
对于所有其他情况(setting_value 或 new_setting_value 任一为 None),这由第二个分支的 _ 模式体现,这时确实希望允许 new_setting_value 变为 setting_value。

也可以在一个模式中的多处使用下划线来忽略特定值。
fn main() {let numbers = (2, 4, 8, 16, 32);match numbers {(first, _, third, _, fifth) => {println!("Some numbers: {}, {}, {}", first, third, fifth)}}
}
这会打印出 Some numbers: 2, 8, 32, 值 4 和 16 会被忽略。

通过在名字前以一个下划线开头来忽略未使用的变量
如果你创建了一个变量却不在任何地方使用它, Rust 通常会给你一个警告,因为这可能会是个 bug。但是有时创建一个还未使用的变量是有用的,比如你正在设计原型或刚刚开始一个项目。这时你希望告诉 Rust 不要警告未使用的变量,为此可以用下划线作为变量名的开头。
fn main() {let _x = 5;let y = 10;
}
这里得到了警告说未使用变量 y,不过没有警告说未使用下划线开头的变量。
注意, 只使用 _ 和使用以下划线开头的名称有些微妙的不同:比如 _x 仍会将值绑定到变量,而 _ 则完全不会绑定。为了展示这个区别的意义,
fn main() {let s = Some(String::from("Hello!"));if let Some(_s) = s {println!("found a string");}println!("{:?}", s);}
我们会得到一个错误,因为 s 的值仍然会移动进 _s,并阻止我们再次使用 s。
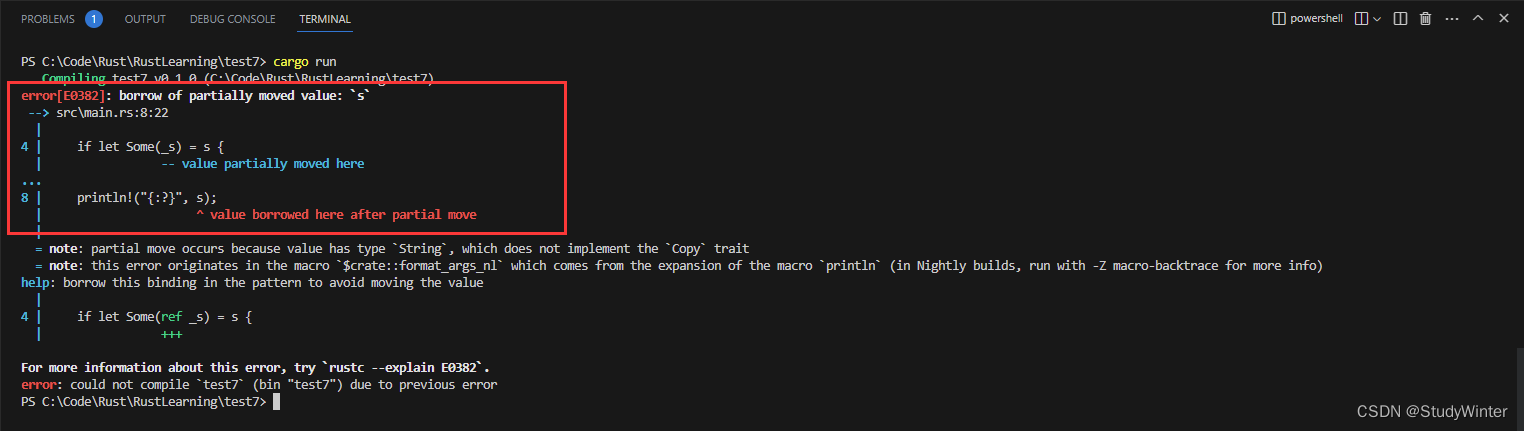
然而只使用下划线本身,并不会绑定值。
fn main() {let s = Some(String::from("Hello!"));if let Some(_) = s {println!("found a string");}println!("{:?}", s);}
上面的代码能很好的运行;因为没有把 s 绑定到任何变量;它没有被移动。
用..忽略剩余值
对于有多个部分的值,可以使用 .. 语法来只使用部分并忽略其它值,同时避免不得不每一个忽略值列出下划线。.. 模式会忽略模式中剩余的任何没有显式匹配的值部分。
fn main() {struct Point {x: i32,y: i32,z: i32,}let origin = Point { x: 0, y: 0, z: 0 };match origin {Point { x, .. } => println!("x is {}", x),}
}
这里列出了 x 值,接着仅仅包含了 .. 模式。这比不得不列出 y: _ 和 z: _ 要来得简单,特别是在处理有很多字段的结构体,但只涉及一到两个字段时的情形。

.. 会扩展为所需要的值的数量。
fn main() {let numbers = (2, 4, 8, 16, 32);match numbers {(first, .., last) => {println!("Some numbers: {}, {}", first, last);},}
}
这里用 first 和 last 来匹配第一个和最后一个值。.. 将匹配并忽略中间的所有值。然而使用 .. 必须是无歧义的。如果期望匹配和忽略的值是不明确的,Rust 会报错。

下面示例展示了一个带有歧义的 .. 例子,因此其不能编译:
fn main() {let numbers = (2, 4, 8, 16, 32);match numbers {(.., second, ..) => {println!("Some numbers: {}", second)},}
}
如果编译上面的例子,会得到下面的错误:

Rust 不可能决定在元组中匹配 second 值之前应该忽略多少个值,以及在之后忽略多少个值。这段代码可能表明我们意在忽略 2,绑定 second 为 4,接着忽略 8、16 和 32;抑或是意在忽略 2 和 4,绑定 second 为 8,接着忽略 16 和 32,以此类推。变量名 second 对于 Rust 来说并没有任何特殊意义,所以会得到编译错误,因为在这两个地方使用 .. 是有歧义的。
匹配守卫提供的额外条件
匹配守卫(match guard)是一个指定于 match 分支模式之后的额外 if 条件,它也必须被满足才能选择此分支。匹配守卫用于表达比单独的模式所能允许的更为复杂的情况。
这个条件可以使用模式中创建的变量。
fn main() {let num = Some(4);match num {Some(x) if x < 5 => println!("less than five: {}", x),Some(x) => println!("{}", x),None => (),}
}
上例会打印出 less than five: 4。当 num 与模式中第一个分支比较时,因为 Some(4) 匹配 Some(x) 所以可以匹配。接着匹配守卫检查 x 值是否小于 5,因为 4 小于 5,所以第一个分支被选择。
相反如果 num 为 Some(10),因为 10 不小于 5 所以第一个分支的匹配守卫为假。接着 Rust 会前往第二个分支,这会匹配因为它没有匹配守卫所以会匹配任何 Some 成员。
无法在模式中表达 if x < 5 的条件,所以匹配守卫提供了表现此逻辑的能力。
案例:
fn main() {let x = Some(5);let y = 10;match x {Some(50) => println!("Got 50"),Some(n) if n == y => println!("Matched, n = {}", n),_ => println!("Default case, x = {:?}", x),}println!("at the end: x = {:?}, y = {}", x, y);
}
现在这会打印出 Default case, x = Some(5)。现在第二个匹配分支中的模式不会引入一个覆盖外部 y 的新变量 y,这意味着可以在匹配守卫中使用外部的 y。相比指定会覆盖外部 y 的模式 Some(y),这里指定为 Some(n)。此新建的变量 n 并没有覆盖任何值,因为 match 外部没有变量 n。
匹配守卫 if n == y 并不是一个模式所以没有引入新变量。这个 y 正是 外部的 y 而不是新的覆盖变量 y,这样就可以通过比较 n 和 y 来表达寻找一个与外部 y 相同的值的概念了。
也可以在匹配守卫中使用 或 运算符 | 来指定多个模式,同时匹配守卫的条件会作用于所有的模式。
fn main() {let x = 4;let y = false;match x {4 | 5 | 6 if y => println!("yes"),_ => println!("no"),}
}
这个匹配条件表明此分支值匹配 x 值为 4、5 或 6 同时 y 为 true 的情况。运行这段代码时会发生的是第一个分支的模式因 x 为 4 而匹配,不过匹配守卫 if y 为假,所以第一个分支不会被选择。代码移动到第二个分支,这会匹配,此程序会打印出 no。这是因为 if 条件作用于整个 4 | 5 | 6 模式,而不仅是最后的值 6。换句话说,匹配守卫与模式的优先级关系看起来像这样:
(4 | 5 | 6) if y => ...
而不是:
4 | 5 | (6 if y) => ...
可以通过运行代码时的情况看出这一点:如果匹配守卫只作用于由 | 运算符指定的值列表的最后一个值,这个分支就会匹配且程序会打印出 yes。
@绑定
at 运算符(@)允许我们在创建一个存放值的变量的同时测试其值是否匹配模式。下面示例展示了一个例子,这里我们希望测试 Message::Hello 的 id 字段是否位于 3...7 范围内,同时也希望能将其值绑定到 id_variable 变量中以便此分支相关联的代码可以使用它。可以将 id_variable 命名为 id,与字段同名,不过出于示例的目的这里选择了不同的名称。
fn main() {enum Message {Hello { id: i32 },}let msg = Message::Hello { id: 5 };match msg {Message::Hello {id: id_variable @ 3..=7,} => {println!("Found an id in range: {}", id_variable)}Message::Hello { id: 10..=12 } => {println!("Found an id in another range")}Message::Hello { id } => {println!("Found some other id: {}", id)}}
}
上例会打印出 Found an id in range: 5。通过在 3...7 之前指定 id_variable @,我们捕获了任何匹配此范围的值并同时测试其值匹配这个范围模式。
第二个分支只在模式中指定了一个范围,分支相关代码代码没有一个包含 id 字段实际值的变量。id 字段的值可以是 10、11 或 12,不过这个模式的代码并不知情也不能使用 id 字段中的值,因为没有将 id 值保存进一个变量。
最后一个分支指定了一个没有范围的变量,此时确实拥有可以用于分支代码的变量 id,因为这里使用了结构体字段简写语法。不过此分支中没有像头两个分支那样对 id 字段的值进行测试:任何值都会匹配此分支。
使用 @ 可以在一个模式中同时测试和保存变量值。
总结
模式是 Rust 中一个很有用的功能,它帮助我们区分不同类型的数据。当用于 match 语句时,Rust 确保模式会包含每一个可能的值,否则程序将不能编译。let 语句和函数参数的模式使得这些结构更强大,可以在将值解构为更小部分的同时为变量赋值。可以创建简单或复杂的模式来满足我们的要求。
参考:模式用来匹配值的结构 - Rust 程序设计语言 简体中文版 (bootcss.com)





)







![[系统] 电脑突然变卡 / 电脑突然** / 各种突发情况解决思路](http://pic.xiahunao.cn/[系统] 电脑突然变卡 / 电脑突然** / 各种突发情况解决思路)
)




