
2006年项目成立的一开始,“Hadoop”这个单词只代表了两个组件——HDFS和MapReduce。到现在的13个年头,这个单词代表的是“核心”,今天我们就来看看关于Hadoop的精华问答。
 1
1Q:Hadoop是什么?
A:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
2Q:Hadoop框架最核心的设计是?
A:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
3Q:Hadoop的主要优点?
A:Hadoop的主要优点有以下几个:
(a) 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
(b)高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
(c)高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
(d)高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
(e)低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,Hadoop是开源的,项目的软件成本因此会大大降低。
4Q:HDFS是什么?
A:Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.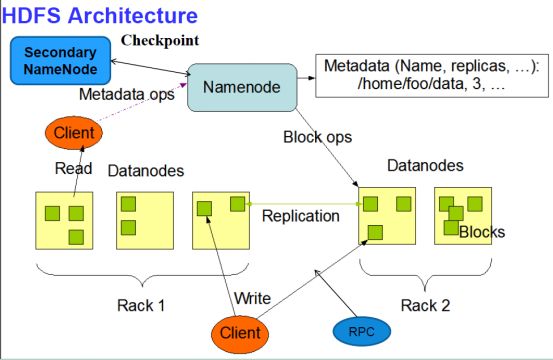
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的。
这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。由于仅存在一个 NameNode,因此这是 HDFS 的一个缺点(单点失败)。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
5Q:HDFS有何特性?
A:HDFS的部分特性:
1. 一致性,高可用性,分区容错性
2. 存储超大文件
3. 一次写入,多次读取(流式数据访问)
4. 运行在普通廉价的服务器上
5. 以高延迟为代价
6. 不适合存储大量小容量的文件
7. 会在多个datanode上存储多份副本,默认3份,三份副本一般会保存在两个或者两个以上的服务器中
8. namenode 负责管理文件目录,文件和block的对应关系以及block和datanode的对应关系
9. datanode负责存储,大部分的容错机制都是在datanode上实现

小伙伴们冲鸭,后台留言区等着你!
关于Hadoop,今天你学到了什么?还有哪些不懂的?除此还对哪些话题感兴趣?快来留言区打卡啦!留言方式:打开第XX天,答:……
同时欢迎大家搜集更多问题,投稿给我们!风里雨里留言区里等你~
福利
1、扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

2、公众号后台回复:白皮书,获取IDC最新数据白皮书整理资料!
推荐阅读:
轻松了解面试官心理!ElasticSearch写入数据的工作原理是什么? | 技术头条
专访图灵奖得主John Hopcroft:中国必须提升本科教育水平,才能在AI领域赶上美国
程序员与程序媛的神仙爱情 | 程序员有话说
他曾主导世界上第一台安卓智能机, 如今能否靠区块链手机找回昔日的光荣?|人物志
移动开发或将被颠覆?
如何将TensorFlow Serving的性能提高超过70%?
 喜欢就点击“在看”吧
喜欢就点击“在看”吧



















