摘要: 大数据生态下有着丰富多样的系统:流计算,数据存储,实时分析,离线计算,数据在各个异构系统之间的流转和加工而产生价值,高效的数据传输通道是大数据生态的重要一环。本文描述了阿里HBase团队在数据通道上多年的实践经验,主要讲解在主备容灾,高吞吐低延时等方面的挑战和解决方案。
福利:国际顶级盛会HBaseCon Asia 2018将于8月在北京举行,目前正免费开放申请中,更多详情参考https://yq.aliyun.com/promotion/631
如果你对大数据存储、分布式数据库、HBase等感兴趣,欢迎加入我们,一起做最好的大数据在线存储,职位参考及联系方式:https://maimai.cn/job?webjid=1heZGIyM4&srcu=1aOrffoj1&src=app&fr=my_jobsrecruit_job
摘要:第九届中国数据库技术大会,阿里巴巴技术专家孟庆义对阿里HBase的数据管道设施实践与演进进行了讲解。主要从数据导入场景、 HBase Bulkload功能、HImporter系统、数据导出场景、HExporter系统这些部分进行了讲述。
直播视频请点击
PPT下载请点击
精彩视频整理:
数据导入场景
生意参谋
生意参谋是一种为商家服务,帮助商家进行决策和运营的数据产品。如在淘宝或天猫上开一家店,生意参谋会提供店里每天进入的流量、转化率、客户的画像和同行业进行对比这些数据属于什么位置。商家可以根据流量分析、活动分析和行业分析去进行决策。可以根据平时日志、点击量和访问量,数据库把数据通过实时的流处理写入HBase。有一部分写到离线系统里,定期做一些清洗和计算再写入HBase,然后供业务去查询 HBase。
蚂蚁风控
在蚂蚁上任何一笔交易支付都会调用风控,风控主要是去看这次交易是否属于同一个设备,是否是经常交易的地点,以及交易的店铺信息。它必须在100ms—200ms把风险做完,风控是根据长期的历史信息、近期历史的信息和实时的信息三个方向做综合考量。用户的输入会实时的写入HBase,同时这个实时的信息增量也会导入到离线系统里面,离线系统会定期的对数据进行计算,计算的数据结果会作为历史或近期历史再写回HBase,一个支付可能会调百十次的风控,而且需要在百毫秒内进行返回。
数据导入需要解决的问题
2013年刚刚开始做数据导入的时候面临的更多的是功能需求性的问题,现在需要考虑的是导入的周期性调度、异构数据源多、导入效率高和多集群下的数据一致性的问题。前两个问题更适合由平台化去解决,HBase的数据导入更关注的是导入效率和多集群下的数据的一致性。
什么是Bulkload?Bulkload有什么功能?
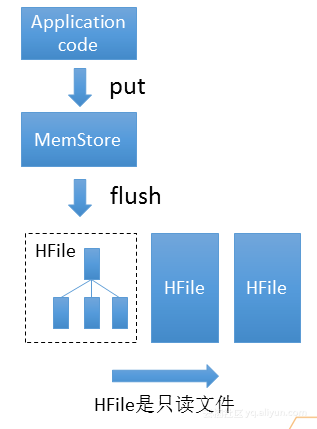
Bulkload使用的是一种新的结构LSM Tree进行写入更新,其结构如上图所示。使用Application code 进行数据写入,数据会被写入到MemStore,MemStore在HBase里是一个跳表,可以把它看成一个有序的列表,并不断往里面插入数据。当数据达到一定量时就会启动flush对数据进行编码和压缩,并写成HFile。HFile是由索引块和数据块组成的文件结构,其特点是只读性,生成HFile之后就不可改了。当用户进行读取数据的时候,就会从三个HFile和一个MemStore进行查找进行读取。这个结构的优化就是就把随机的写变成了有序的写。Bulkload就可以把上千上万条数据在毫秒内加入到HBase里。所以Bulkload的优势如下:
- 高吞吐
- 不需要WAL
- 避免small compaction
- 支持离线构建
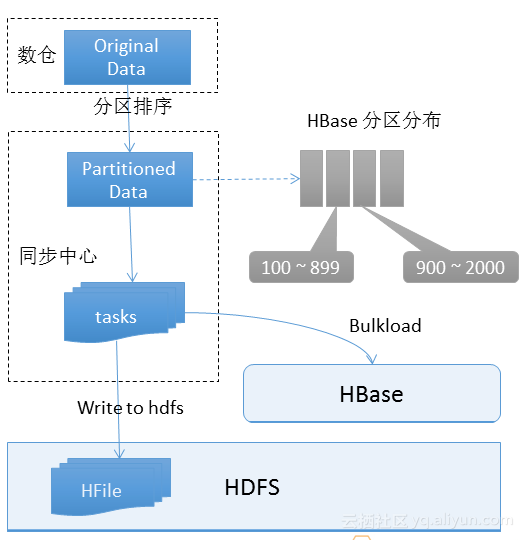
Bulkload的导入结构如上图所示,数据来源于数仓,首先根据HBase的分区规则对数据进行分区和排序。然后会生成Partition Data,需要写一个HBase插进去。同步中心就会调动一个作业,作业内部会有很多的tasks,每个task独立的执行把文件读出,写到HDFS上,形成一个HFile文件。当把所有文件写完,同步中心就会调Bulkload指令到HBase,把所有的HFile一次性的load进去。
以前采用的是多集群导入的方法,但是多集群导入有很多缺点如下:
- 很难保证多个任务同时完成,导致一定时间窗口内数据不一致
- 调度后的运行环境不一致
- 网络延迟不一致
- 失败重试
集群部署对业务不透明的缺点: - 需要配置多个任务
- 集群迁移需要重新配置任务
为了保证数据的一致性,采用了逻辑集群导入法。
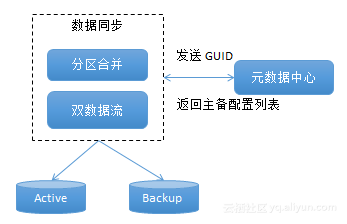
逻辑集群的流程如上图所示,首先进行分区合并,然后进行双数据流处理,把流分别写到Active和Backup里,当Active和Backup的HFile文件写完后执行Bulkload。因为Bulkload是毫秒级别的,所以能实现一致性。
多任务和逻辑集群的差别比较如下:
- 多任务模式:需要重复配置,是不透明的,很难保证一致性,分区排序
需要执行两次,编码压缩两次。 - 逻辑集群模式:配置一次,迁移无感知,在一致性上达到毫秒级,分区排序是执行一次,但分区数量变多,编码压缩一次。
随着业务做得越来越大,这种导入就会遇到新的线上问题,如扩展性、资源利用率、研发效率、监控等。
什么是HImporter系统?
HImporter是用于辅助数据同步的中间层,他会把所有HFile的构建,加载逻辑下沉到HImporter层。
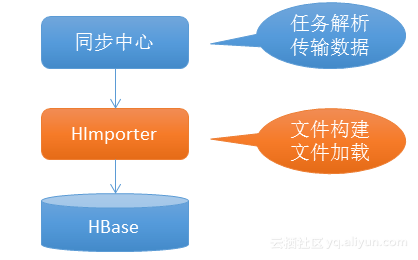
HImporter所处的位置如上图所示。
HImporter的优势
- 分布式水平扩展,同一个作业的不同任务可以调度到HImporter的不同worker节点
- 提高资源利用率,将压缩等CPU密集操作下降到HImporter
- 快速迭代,HImporter的运维和迭代与同步中心独立
- 独立监控,HImporter可按照自己的需求实现监控
HImporter 功能迭代
功能迭代主要包括表属性感知、保证本地化率、支持轻量计算和安全隔离。其中表属性感知就是感知特性,并保证特征不会变,主要包括、混合存储、新压缩编码、表级别副本数;保证本地化率是将Hfile写入到分区所在服务器,保证本地化率和存储特性,对一些rt敏感的业务效果明显;支持轻量计算就是支持MD5,字符串拼接等函数;安全隔离是避免对外暴露HDFS地址、支持Task级别重试。
数据导出场景
菜鸟联盟
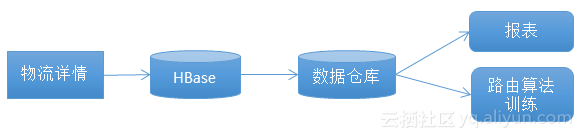
菜鸟联盟的场景如上图所示。一个物流详情会传到HBase,HBase会传到数据仓库,数据仓会产生报表,然后去训练路由算法。
淘宝客服
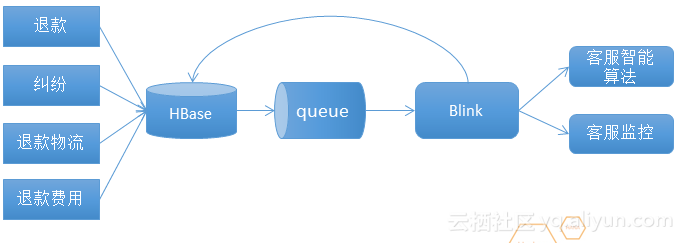
淘宝客服的一个退款应用场景如上图。这是一个逆向链接,把退款、纠纷、退款物流、退款费用等实时的写入到HBase里,HBase会实时的写入queue里,blink流系统会消费queue产生一些数据会返回到HBase,blink输出会支撑智能服务、客户监控等。
增量数据导出需要解决的问题
增量数据导出需要解决的问题主要是离线数据的T+1处理特点、吞吐量 、实时性、主备流量切换等。
早期的方案是会周期性的从HDFS里把所有的日志罗列出来,然后对日志进行排序会产生一个有序的时间流。取work里同步时间最短的作为最终的同步时间。这种方案具有对NN节点造成很大压力、无法应对主备切换、日志热点处理能力低等问题。
HExporter系统
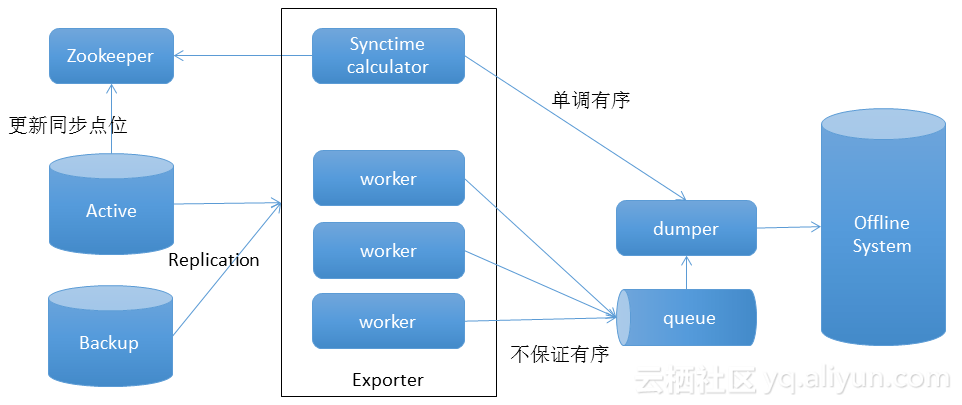
HExporter1.0如上图所示,HExporter1.0优势主要有主备流量切换不影响数据导出,能够识别数据来源,过滤非原始数据;独立的同步时间流,能够保障数据按有序时间分区Dump到数据仓库;复用HBase replication框架,能够降低开发工作量,复用HBase的监控,运维体系。
HExporter1.0 优化主要包括以下五点:
- 减少拓扑网络中的数据发送,备库避免向Exporter发送重复数据;
- 远程辅助消化器,空闲的机器帮助消化热点;
- 避免发送小包,HExporter在接收到小包后,等待一段时间再处理;
- 同步通道配置隔离,实时消费链路和离线消费链路可以采用不同的配置;
- 数据发送前压缩。
HExporter1.0的问题是业务写入流量产生高峰,离线出现同步延迟;HBase升级速度慢。然后我们就有了以下解决思路,离线同步的资源可以和在线资源隔离,利用离线大池子可以削峰填谷;Exporter的worker是无状态的,如果把所有逻辑都放在Exporter,那么升级、扩容会简单快速。然后就产生了HExporter2.0。
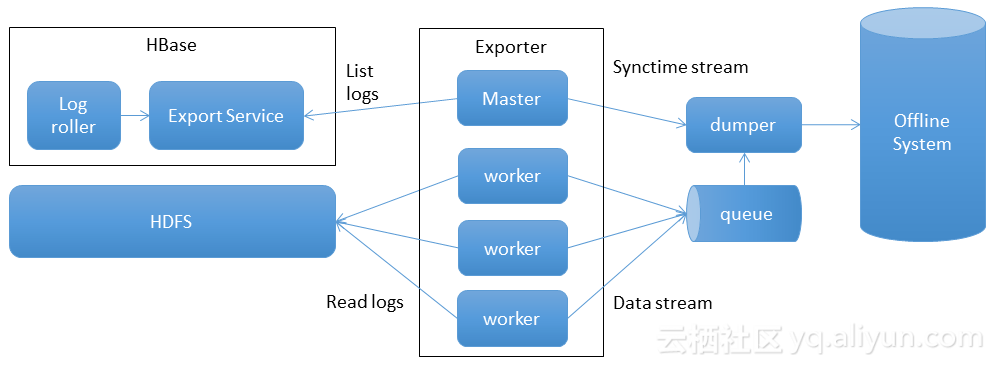
HExporter2.0如上图所示
总结
ALiHBase数据通道的导入和导出都是添加了中间层,中间层的核心价值易扩展、可靠性高、迭代快和稳定。因为采用分布式水平扩展更易扩展;采用自主识别主备切换,封装对HBase访问更可靠;采用架构解耦,快速迭代使迭代速度更快;因为无状态,节点对等所以更加稳定。
原文链接
本文为云栖社区原创内容,未经允许不得转载。

)




)
)



;oracle sql语句大全)

...)





