摘要: 迁移学习正在各个领域大展拳脚,NLP领域正在受到冲击!
在我们之前的文章中,我们展示了如何使用CNN与迁移学习为我们自己创建图片构建分类器。今天,我们介绍NLP中迁移学习的最新趋势,并尝试进行分类任务:将亚马逊评论的数据集分类为正面或负面。
NLP中的迁移学习理念在fast.ai课程中得到了很好的体现,我们鼓励你查看论坛。我们这里的参考文件是 Howard,Ruder,“用于文本分类的通用语言模型微调”。
什么是迁移学习?
计算机视觉是一个使用迁移学习而取得巨大进步的领域。它具有数百万参数的高度非线性模型需要大量数据集进行训练,并且通常需要数天或数周才能进行训练,只是为了能够将图像分类为包含狗或猫!

随着ImageNet的挑战,团队每年都参与竞争,以设计出最佳的图像分类器。已经观察到这些模型的隐藏层能够捕获图像中的一般知识(边缘、某些形式、样式......)。因此,每次我们想要改变任务时,没有必要从头开始重新训练模型。
让我们以VGG-16模型为例(Simonyan、Karen和Zisserman·“用于大规模图像识别的非常深的卷积网络。”(2014))
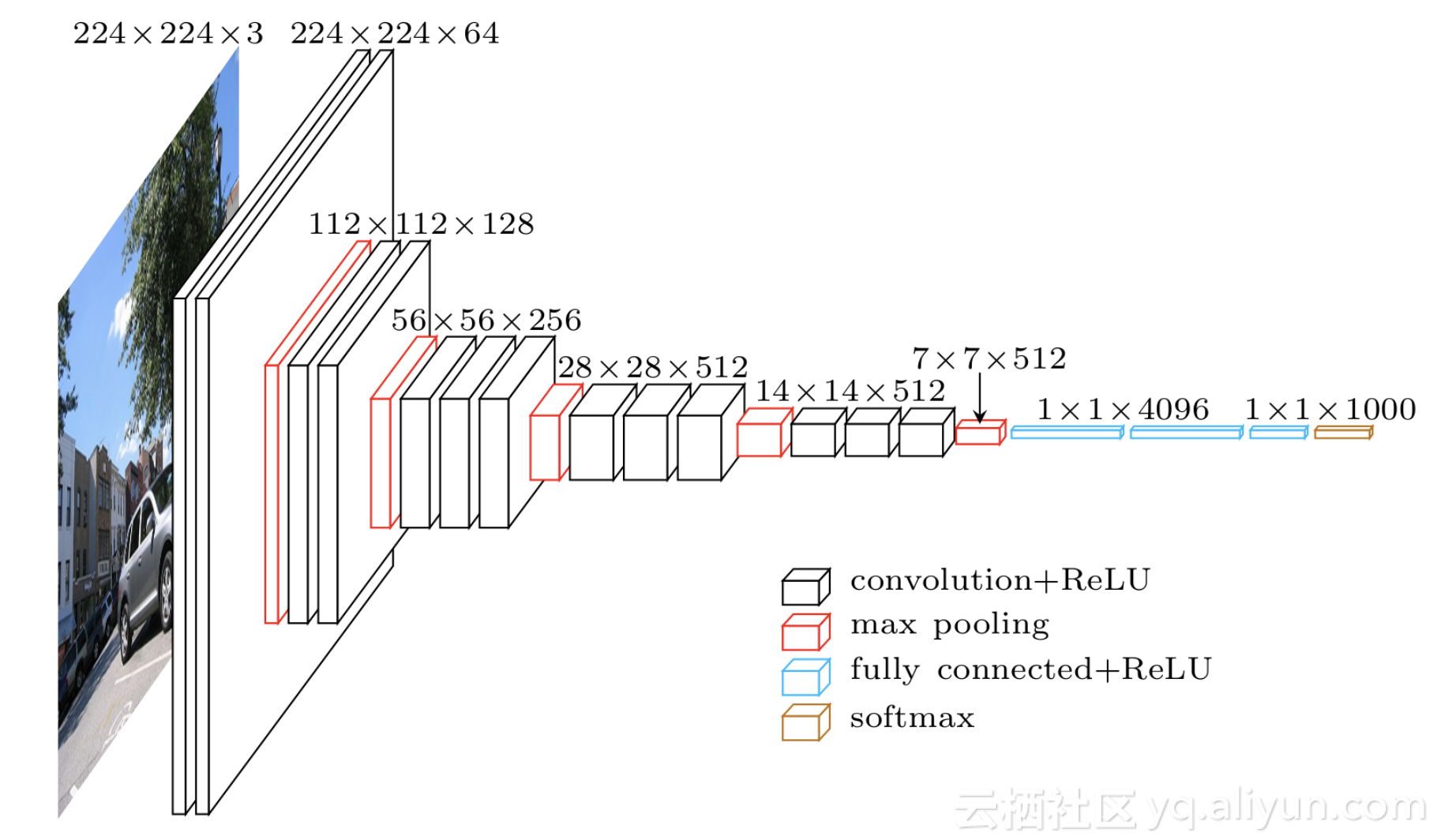
这种架构比较复杂、层数多、参数数量多。作者声称使用4个强大的GPU训练了为3周时间。
迁移学习的想法是,由于中间层被认为是学习图像的一般知识,我们可以将它们用作当成比较全面的特征!我们将下载一个预先训练好的模型(在ImageNet任务上训练数周),删除网络的最后一层(完全连接的层,在ImageNet挑战的1000个类上投射功能),添加put而不是我们选择的分类器,适合我们的任务(如果我们有兴趣对猫和狗进行分类,则为二元分类器),最后仅训练我们的分类层。并且因为我们使用的数据可能与之前训练过的模型数据不同,我们也可以进行微调步骤,这样我们就能在相当短的时间内训练所有层。
除了更快地进行训练之外,迁移学习特别有趣,因为仅在最后一层进行训练使我们仅使用较少的标记数据即可,而端对端训练整个模型则需要庞大的数据集。标记数据很昂贵,并且非常需要建立高质量模型而不需要大数据集。
那么NLP中的迁移学习呢?
NLP深度学习的进展不像计算机视觉那样成熟。虽然可以想象机器能够学习边缘、圆形、正方形等形状,然后使用这些知识做其他事情,但对于文本数据来说这些并不简单。
最初流行的在NLP中迁移学习是由嵌入模型这个词(由word2vec和GloVe广泛推广)带来的。这些单词矢量表示利用单词的上下文,将它们表示为向量,其中相似的单词应具有相似的单词表示。
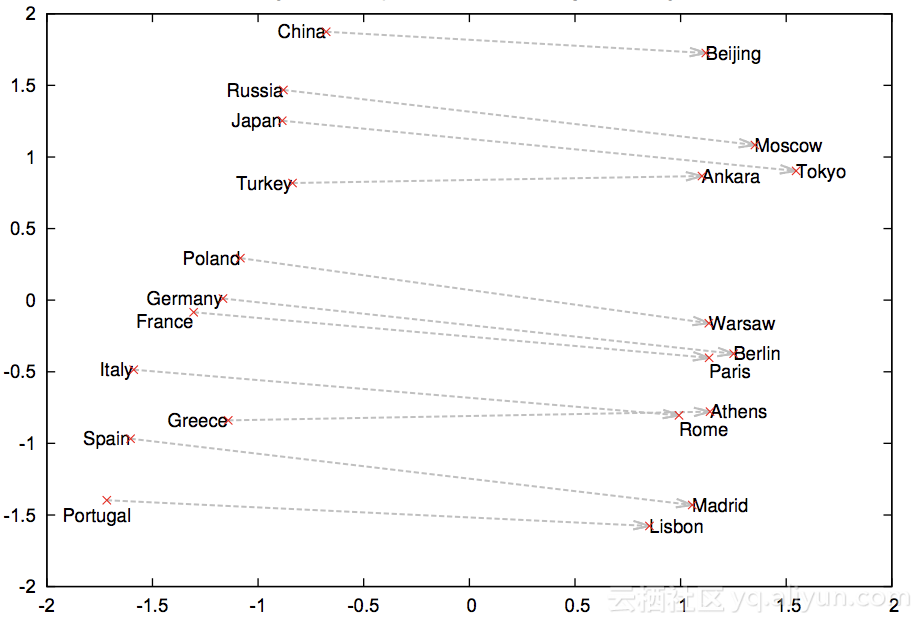
在这个图中,来自word2vec论文,我们看到该模型能够学习国家与其首都城市之间的关系。
包括预先训练的单词向量已经显示出在大多数NLP任务中改进度量,因此已经被NLP社区广泛采用,被用来寻找甚至更好的单词/字符/文档表示。与计算机视觉一样,预训练的单词向量可以被视为特征化函数,转换一组特征中的每个单词。
但是,单词嵌入仅代表大多数NLP模型的第一层。之后,我们仍然需要从头开始训练所有RNN / CNN /自定义层。
用于文本分类的语言模型微调
今年早些时候霍华德和罗德提出了ULMFit模型,以此来进一步提升了迁移学习在NLP的应用。
他们正在探索的想法是基于语言模型。语言模型是一种能够根据已经看到的单词预测下一个单词的模型(想想你的智能手机在你发短信时为你猜测下一个单词)。就像图像分类器通过对图像分类来获得图像的内在知识一样,如果NLP模型能够准确地预测下一个单词,那么说明它已经学到了很多关于自然语言结构。这些知识应提供良好的初始化,然后可以在自定义任务上进行训练!
ULMFit建议在非常大的文本语料库(例如维基百科)上训练语言模型,并将其用作任何分类器的主干!由于你的文本数据可能与维基百科的编写方式不同,因此你需要微调语言模型的参数以将这些差异考虑在内。然后,我们将在此语言模型的顶部添加分类器层,并仅训练此层!
ULMfit paper
让人惊讶的结果是,使用这种预训练的语言模型使我们能够在更少标记的数据上训练分类器!虽然未标记的数据在网络上几乎是无限的,但标记数据非常昂贵且耗时。
以下是他们从IMDb情绪分析任务中报告的结果:
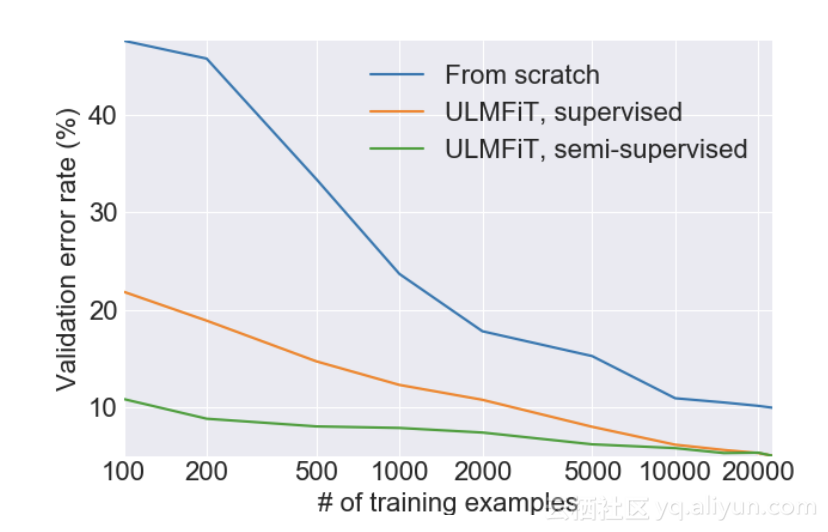
虽然只有100个示例,它们能够达到与使用20k示例从头开始训练时模型达到的相同错误率!
此外,他们还提供了代码,以你选择的语言预先训练语言模型。由于维基百科存在很多的语言中,因此我们可以使用维基百科数据快速从一种语言迁移到另一种语言。众所周知,公共标签数据集更难以使用英语以外的语言进行访问。在这里,你可以对未标记数据上的语言模型进行微调,花几个小时手动注释几百/千个数据点,并使分类器头部适应你预先训练的语言模型来执行你的任务!
游乐场与亚马逊评论
为了改变这种方法的不足之处,我们使用为其论文中的公共数据集上进行了尝试。我们在Kaggle上找到了这个数据集:它包含4百万条关于亚马逊产品的评论,并用积极或消极的情绪标记它们。我们将针对ULMfit的fast.ai课程调整将亚马逊评论分类为正面或负面。我们发现只需要1000个数据点,该模型就能够匹配通过在完整数据集上从头开始训练FastText模型获得的准确度分数。仅使用100个标记示例,该模型仍然能够获得良好的性能。
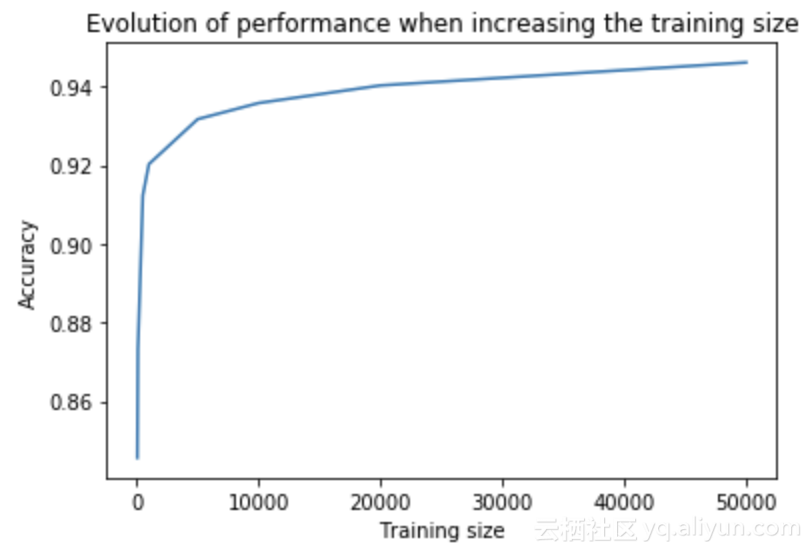
要重现此实验,你可以使用此笔记本,建议使用GPU来运行微调和分类部分。
NLP中的无监督与监督学习,围绕意义进行讨论
使用ULMFit,我们使用了无监督和监督学习。训练无监督的语言模型是“便宜的”,因为你可以在线访问几乎无限的文本数据。但是,使用监督模型很昂贵,因为你需要对数据进行标记。
虽然语言模型能够从自然语言的结构中捕获大量相关信息,但尚不清楚它是否能够捕获文本的含义,即“发送者打算传达的信息或概念”。
你可能已经关注了NLP中非常有趣的Twitter主题。在这个帖子中,艾米莉·本德利用“泰国房间实验”对她进行了反对意义捕获的论证:想象一下,你在一个巨大的图书馆里得到了所有泰国文学的总和。假设你还不懂泰语,你就不会从中学到任何东西。
所以我们可以认为语言模型学到的更多是语法而不是意义。然而,语言模型比仅仅预测语法相关的句子更好。例如,“我要吃来这台电脑”和“我讨厌这台电脑”两者在语法上都是正确的,但一个好的语言模型应该能够知道“我讨厌这台电脑”应该比另外一句更“准确”。所以,即使我看过整个泰语维基百科,我也无法用泰语写作,但很容易看出语言模型确实超越了简单的语法/结构理解。
我们不会在这里进一步探讨意义的概念(这是一个无穷无尽且引人入胜的话题/辩论),如果你有兴趣,我们建议你看下Yejin Choi在ACL 2018的演讲中是如何探讨这一主题的。
NLP中迁移学习的未来
ULMFit取得的进展推动了NLP迁移学习的研究。对于NLP来说,这是一个激动人心的时刻,因为其他微调语言模型也开始出现,特别是FineTune Transformer LM。我们还注意到,随着更好的语言模型的出现,我们甚至可以改善这种知识迁移。
原文链接
本文为云栖社区原创内容,未经允许不得转载。






![python解析excel公式_[python][openpyxl]读取excel中公式的结果值](http://pic.xiahunao.cn/python解析excel公式_[python][openpyxl]读取excel中公式的结果值)



)








