背景
在MaxCompute查询中,Join是很常见的场景。例如以下Query,就是一个简单的Inner Join把t1表和t2表通过id连接起来:
SELECT t1.a, t2.b FROM t1 JOIN t2 ON t1.id = t2.id;
Join在MaxCompute内部主要有三种实现方法:
Broadcast Hash Join - 当Join存在一个很小的表时,我们会采用这种方式,即把小表广播传递到所有的Join Task Instance上面,然后直接和大表做Hash Join。
Shuffle Hash Join - 如果Join表比较大,我们就不能直接广播了。这时候,我么可以把两个表按照Join Key做Hash Shuffle,由于相同的键值Hash结果也是一样的,这就保证了相同的Key的记录会收集到同一个Join Task Instance上面。然后,每个Instance对数据量小的一路建Hash表,数据量大的顺序读取Join。
Sort Merge Join - 如果Join的表更大一些,#2的方法也用不了,因为内存已经不足以容纳建立一个Hash Table。这时我们的实现方法是,先按照Join Key做Hash Shuffle,然后再按照Join Key做排序,最后我们对Join双方做一个归并,具体流程如下图所示:
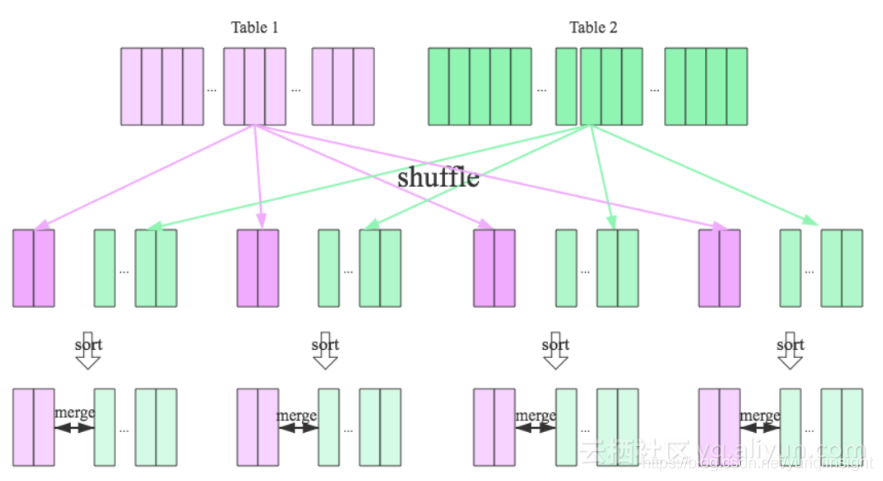
实际上对于MaxCompute今天的数据量和规模,我们绝大多数情况下都是使用的Sort Merge Join,但这其实是非常昂贵的操作。从上图可以看到,Shuffle的时候需要一次计算,并且中间结果需要落盘,后续Reducer读取的时候,又需要读取和排序的过程。对于M个Mapper和R个Reducer的场景,我们将产生M x R次的IO读取。对应的Fuxi物理执行计划如下所示,需要两个Mapper Stage,一个Join Stage,其中红色部分为Shuffle和Sort操作: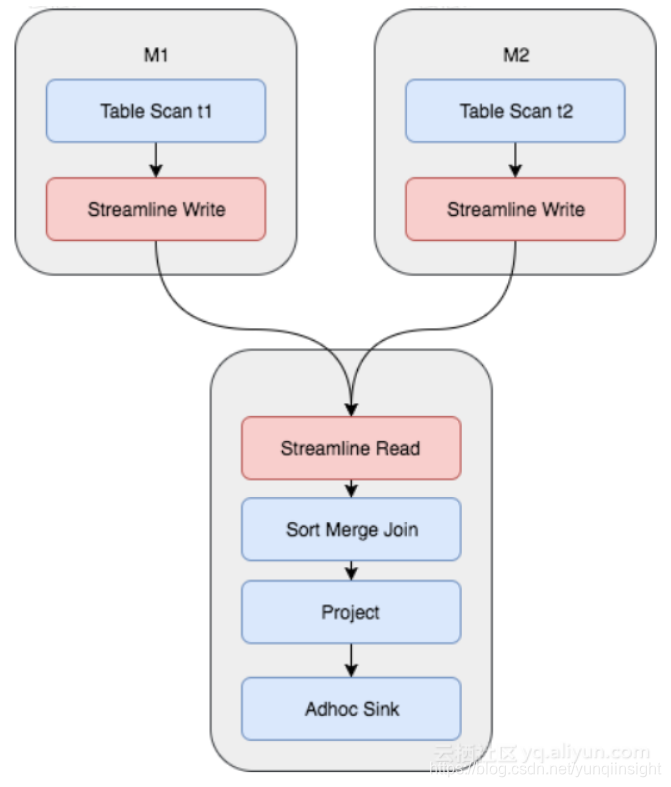
与此同时,我们观察到,有些Join是可能反复发生的,比如上面的Query改成了:SELECT t1.c, t2.d FROM t1 JOIN t2 ON t1.id = t2.id;
虽然,我们选择的列不一样了,但是底下的Join是完全一样的,整个Shuffle和Sort的过程也是完全一样的。
又或者:SELECT t1.c, t3.d FROM t1 JOIN t3 ON t1.id = t3.id;
这个时候是t1和t3来Join,但实际上对于t1而言,整个Shuffle和Sort过程还是完全一样。
于是,我们考虑,如果我们初始表数据生成时,按照Hash Shuffle和Sort的方式存储,那么后续查询中将避免对数据的再次Shuffle和Sort。这样做的好处是,虽然建表时付出了一次性的代价,却节省了将来可能产生的反复的Shuffle和Join。这时Join的Fuxi物理执行计划变成了如下所示,不仅节省了Shuffle和Sort的操作,并且查询从3个Stage变成了1个Stage完成:
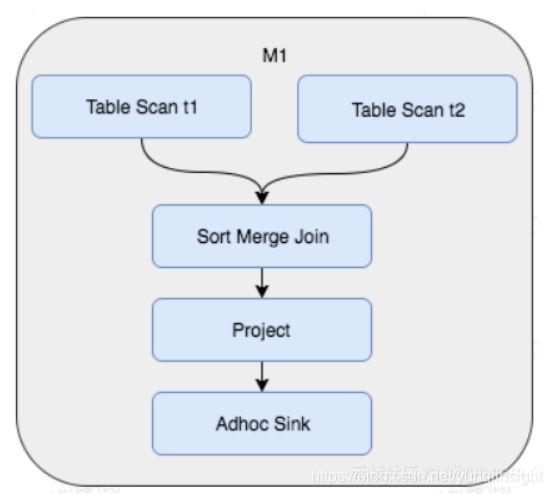
所以,总结来说,Hash Clustering通过允许用户在建表时设置表的Shuffle和Sort属性,进而MaxCompute根据数据已有的存储特性,优化执行计划,提高效率,节省资源消耗。
功能描述
目前Hash Clustering功能已经上线,缺省条件下即打开支持。
- 创建Hash Clustering Table
用户可以使用以下语句创建Hash Clustering表。用户需要指定Cluster Key(即Hash Key),以及Hash分片(我们称之为Bucket)的数目。Sort是可以选项,但在大多数情况下,建议和Cluster Key一致,以便取得最佳的优化效果。
CREATE TABLE [IF NOT EXISTS] table_name
[(col_name data_type [comment col_comment], ...)][comment table_comment][PARTITIONED BY (col_name data_type [comment col_comment], ...)]
[CLUSTERED BY (col_name [, col_name, ...]) [SORTED BY (col_name [ASC | DESC] [, col_name [ASC | DESC] ...])] INTO number_of_buckets BUCKETS]
[AS select_statement]
举个例子如下:
CREATE TABLE T1 (a string, b string, c bigint) CLUSTERED BY (c) SORTED by (c) INTO 1024 BUCKETS;
如果是分区表,则可以用这样的语句创建:CREATE TABLE T1 (a string, b string, c bigint) PARTITIONED BY (dt string) CLUSTERED BY (c) SORTED by (c) INTO 1024 BUCKETS;
CLUSTERED BY
CLUSTERED BY指定Hash Key,MaxCompute将对指定列进行Hash运算,按照Hash值分散到各个Bucket里面。为避免数据倾斜,避免热点,取得较好的并行执行效果,CLUSTERED BY列适宜选择取值范围大,重复键值少的列。此外,为了达到Join优化的目的,也应该考虑选取常用的Join/Aggregation Key,即类似于传统数据库中的主键。
SORTED BY
SORTED BY子句用于指定在Bucket内字段的排序方式,建议Sorted By和Clustered By一致,以取得较好的性能。此外,当SORTED BY子句指定之后,MaxCompute将自动生成索引,并且在查询的时候利用索引来加快执行。
INTO number_of_buckets BUCKETS
INTO ... BUCKETS 指定了哈希桶的数目,这个数字必须提供,但用户应该由数据量大小来决定。Bucket越多并发度越大,Job整体运行时间越短,但同时如果Bucket太多的话,可能导致小文件太多,另外并发度过高也会造成CPU时间的增加。目前推荐设置让每个Bucket数据大小在500MB - 1GB之间,如果是特别大的表,这个数值可以再大点。
目前,MaxCompute只能在Bucket Number完全一致的情况下去掉Shuffle步骤,我们下一个发布,会支持Bucket的对齐,也就是说存在Bucket倍数关系的表,也可以做Shuffle Remove。为了将来可以较好的利用这个功能,我们建议Bucket Number选用2的N次方,如512,1024,2048,最大不超过4096,否则影响性能以及资源使用。
对于Join优化的场景,两个表的Join要去掉Shuffle和Sort步骤,要求哈希桶数目一致。如果按照上述原则计算两个表的哈希桶数不一致,怎么办呢?这时候建议统一使用数字大的Bucket Number,这样可以保证合理的并发度和执行效率。如果表的大小实在是相差太远,那么Bucket Number设置,可以采用倍数关系,比如1024和256,这样将来我们进一步支持哈希桶的自动分裂和合并时,也可以利用数据特性进行优化。
- 更改表属性
对于分区表,我们支持通过ALTER TABLE语句,来增加或者去除Hash Clustering属性:
ALTER TABLE table_name
[CLUSTERED BY (col_name [, col_name, ...]) [SORTED BY (col_name [ASC | DESC] [, col_name [ASC | DESC] ...])] INTO number_of_buckets BUCKETS
ALTER TABLE table_name NOT CLUSTERED;
关于ALTER TABLE,有几点需要注意:
alter table改变聚集属性,只对于分区表有效,非分区表一旦聚集属性建立就无法改变。
alter table只会影响分区表的新建分区(包括insert overwrite生成的),新分区将按新的聚集属性存储,老的数据分区保持不变。
由于alter table只影响新分区,所以该语句不可以再指定PARTITION
ALTER TABLE语句适用于存量表,在增加了新的聚集属性之后,新的分区将做hash cluster存储。
- 表属性显示验证
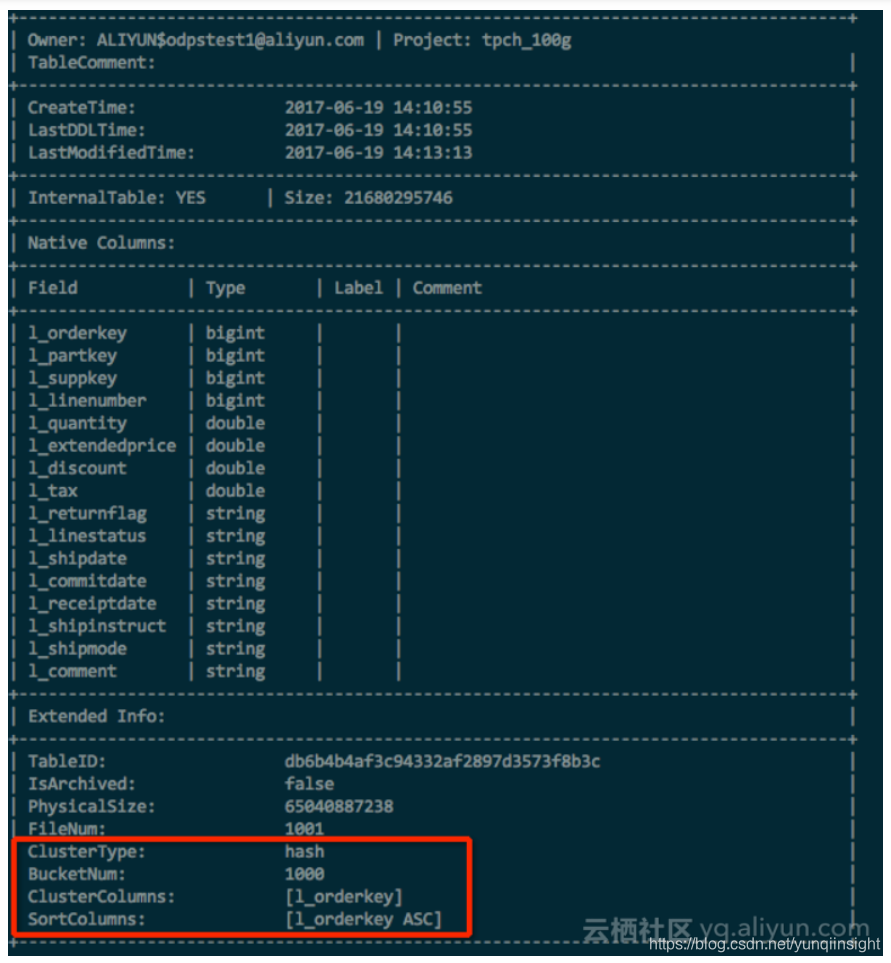
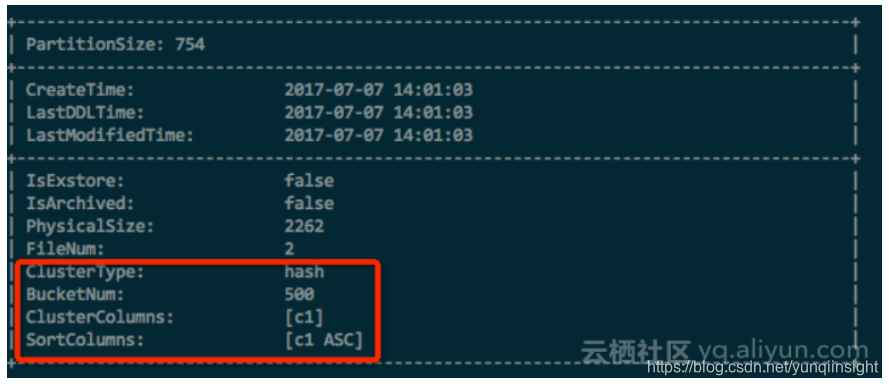
在创建Hash Clustering Table之后,可以通过:
DESC EXTENDED table_name;
来查看表属性,Clustering属性将显示在Extended Info里面,如下图所示:
对于分区表,除了可以使用以上命令查看Table属性之后,于是需要通过以下命令查看分区的属性:
DESC EXTENDED table_name partition(pt_spec);
例如:
Hash Clustering的其他优点
- Bucket Pruning优化
考虑以下查询:
CREATE TABLE t1 (id bigint, a string, b string) CLUSTERED BY (id) SORTED BY (id) into 1000 BUCKETS;
...
SELECT t1.a, t1.b, t1.c FROM t1 WHERE t1.id=12345;
对于普通表,这个通常意味着全表扫描操作,如果表非常大的情况下,资源消耗量是非常可观的。但是,因为我们已经对id做Hash Shuffle,并且对id做排序,我们的查询可以大大简化:
通过查询值"12345"找到对应的Hash Bucket,这时候我们只需要在1个Bucket里面扫描,而不是全部1000个。我们称之为“Bucket Pruning”。
以下是安全部基于User ID查询场景的一个例子。下面这个logview是普通的表的查询操作,可以看到,由于数据量很大,一共起了1111个Mapper,读取了427亿条记录,最后找符合条件记录26条,总共耗时1分48秒: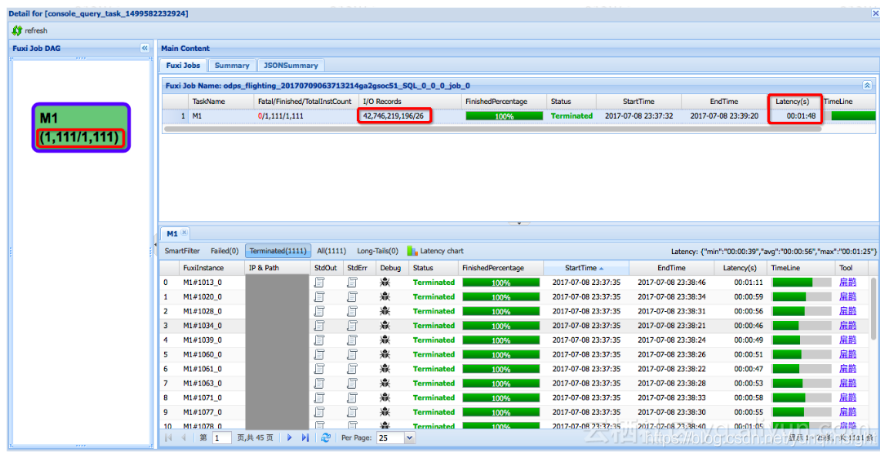
同样的数据,同样的查询,用Hash Clustering表来做,我们可以直接定位到单个Bucket,并利用Index只读取包含查询数据的Page,可以看到这里只用了4个Mapper,读取了10000条记录,总共耗时只需要6秒,如果用service mode这个时间还会更短:
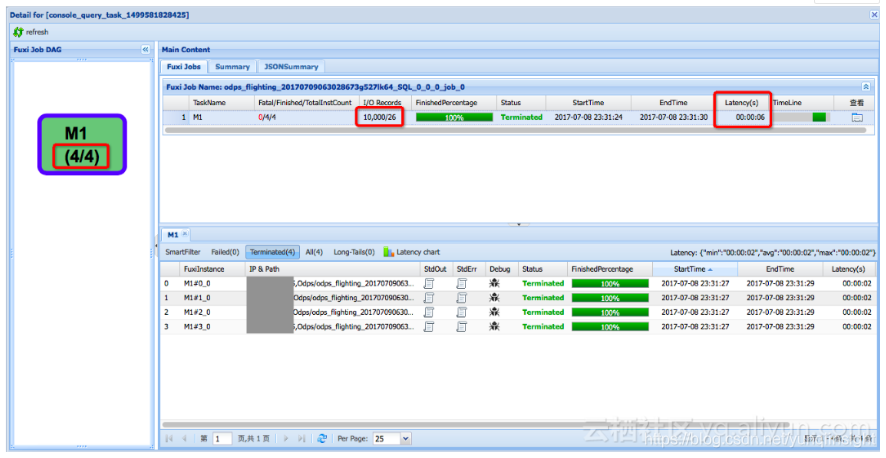
- Aggregation优化
例如,对于以下查询:SELECT department, SUM(salary) FROM employee GROUP BY (department);
在通常情况下,我们会对department进行Shuffle和Sort,然后做Stream Aggregate,统计每一个department group。但是如果表数据已经CLUSTERED BY (department) SORTED BY (department),那么这个Shuffle和Sort的操作,也就相应节省掉了。
- 存储优化
即便我们不考虑以上所述的各种计算上的优化,单单是把表Shuffle并排序存储,都会对于存储空间节省上有很大帮助。因为MaxCompute底层使用列存储,通过排序,键值相同或相近的记录存放到一起,对于压缩,编码都会更加友好,从而使得压缩效率更高。在实际测试中,某些极端情况下,排序存储的表可以比无序表的存储空间节省50%。对于生命周期很长的表,使用Hash Clustering存储,是一个很值得考虑的优化。
以下是一个简单的实验,使用100G TPC-H lineitem表,包含了int,double,string等多种数据类型,在数据和压缩方式等完全一样的情况下,hash clustering的表空间节省了~10%。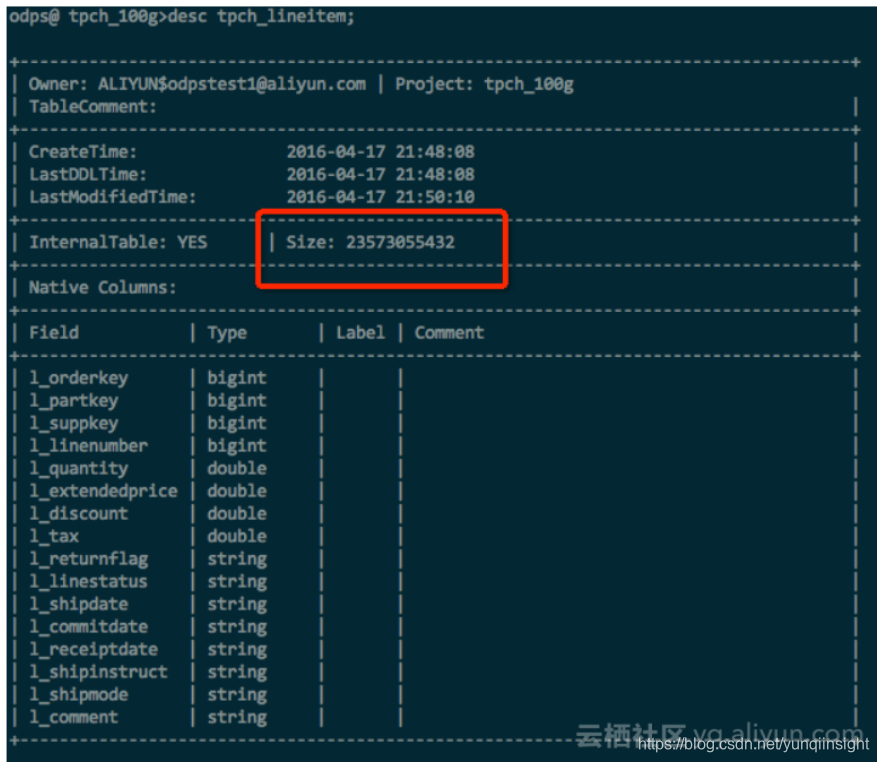
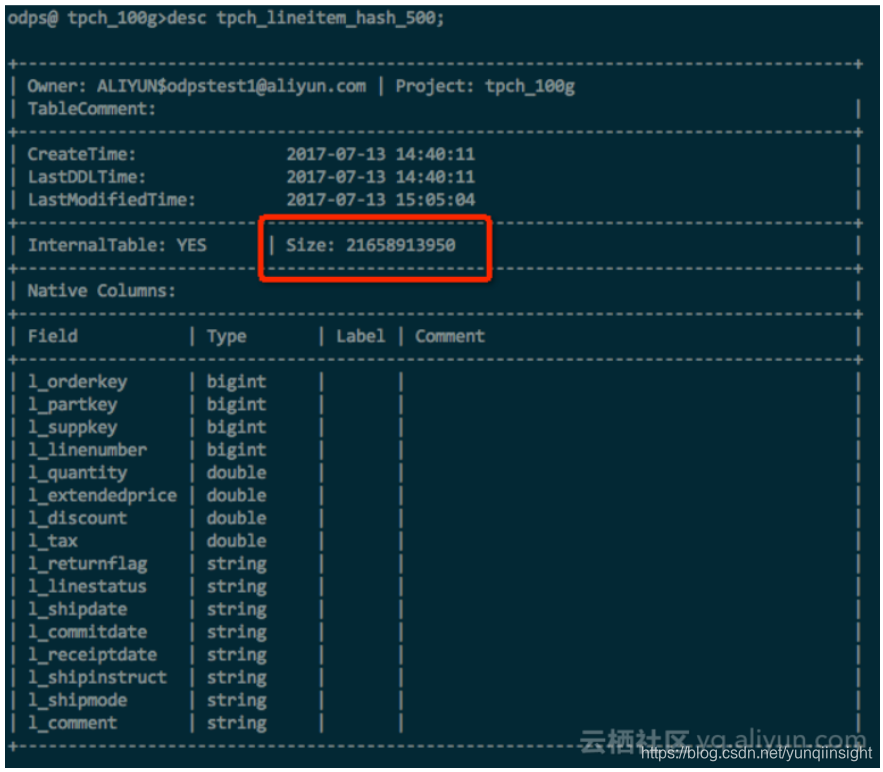
测试数据及分析
对于Hash Clustering整体带来的性能收益,我们通过标准的TPC-H测试集进行衡量。测试使用1T数据,统一使用500 Buckets,除了nation和region两个极小的表以外,其余所有表均按照第一个列作为Cluster和Sort Key。
整体测试结果表明,在使用了Hash Clustering之后,总CPU时间减少17.3%,总的Job运行时间减少12.8%。
具体各个Query CPU时间对比如下: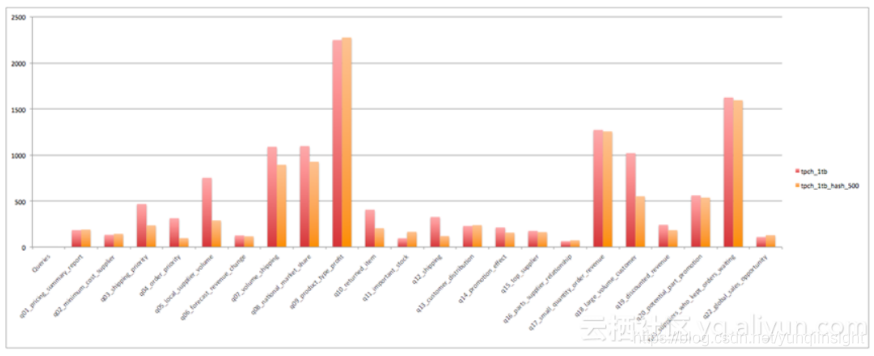
Job运行时间对比如下: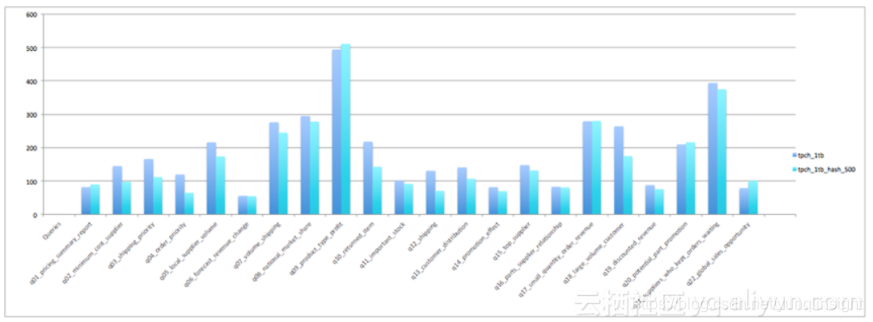
需要注意到是TPC-H里并不是所有的Query都可以利用到Clustering属性,特别是两个耗时最长的Query没有办法利用上,所以从总体上的效率提升并不是非常惊人。但如果单看可以利用上Clustering属性的Query,收益还是非常明显的,比如Q4快了68%,Q12快了62%,Q10快了47%,等等。
以下是TPC-H Q4在普通表的Fuxi执行计划: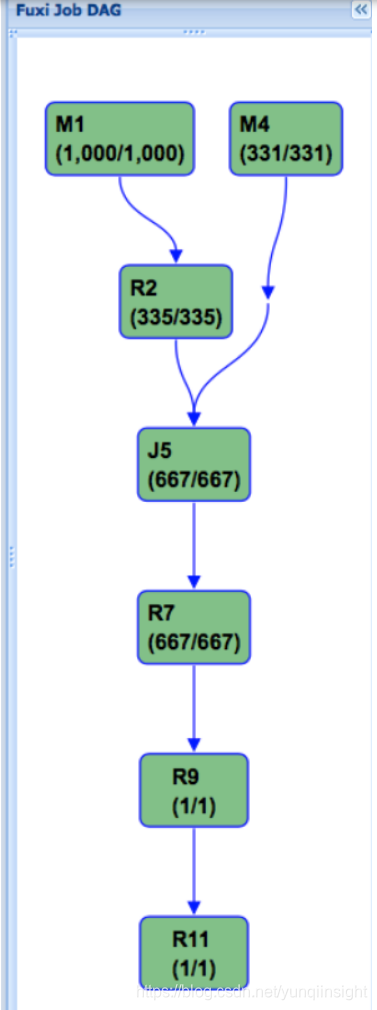
而下面则是使用Hash Clustering之后的执行计划,可以看到,这个DAG被大大的简化,这也是性能得到大幅提升的关键原因: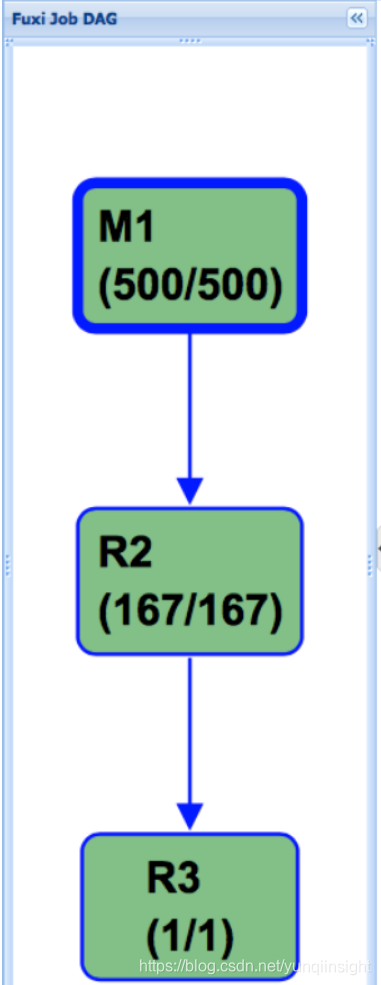
功能限制及将来计划
目前Hash Clustering的第一阶段开发工作完成,但还存在以下限制和不足:
- 不支持insert into,只能通过insert overwrite来添加数据。
- 不支持tunnel直接upload到range cluster表,因为tunnel上传数据是无序的。
原文链接
本文为云栖社区原创内容,未经允许不得转载。










与简单访问权限管理...)








