一、业务背景
在电商运营工作中,营销活动是非常重要的部分,对用户增长和GMV都有很大帮助。对电商运营来说,如何从庞大的商品库中筛选出卖家优质商品并推送给有需要的买家购买是每时每刻都要思索的问题,而且这个过程需要尽可能快和实时。保证快和实时就可以提升买卖双方的用户体验,提高用户粘性。
二、实时选品
为了解决上面提到的问题,闲鱼研发了马赫系统。马赫是一个实时高性能的商品选品系统,解决在亿级别商品中通过规则筛选优质商品并进行投放的场景。有了马赫系统之后,闲鱼的运营同学可以在马赫系统上创建筛选规则,比如商品标题包含“小猪佩奇”、类目为“玩具”、价格不超过100元且商品状态为未卖出。在运营创建规则后,马赫系统会同时进行两步操作,第一步是从存量商品数据筛选符合条件的商品进行打标;第二步是对商品实时变更进行规则计算,实时同步规则命中结果。
马赫系统最大的特点是快而实时,体现在命中规模为100w的规则可以在10分钟之内完成打标;商品本身变更导致的规则命中结果同步时间为1秒钟。运营可以通过马赫系统快速筛选商品向用户投放,闲鱼的流量也可以精准投给符合条件的商品并且将流量利用到最大化。
那么马赫系统是如何解决这一典型的电商问题的呢,马赫系统和流计算有什么关系呢,这是下面要详细说明的部分。
三、流计算
流计算是持续、低延迟、事件触发的数据处理模型。流计算模型是使用实时数据集成工具,将数据实时变化传输到流式数据存储,此时数据的传输变成实时化,将长时间累积大量的数据平摊到每个时间点不停地小批量实时传输;流计算会将计算逻辑封装为常驻计算服务,一旦启动就一直处于等待事件触发状态,当有数据流入后会触发计算迅速得到结果;当流计算得到计算结果后可以立刻将数据输出,无需等待整体数据的计算结果。

闲鱼实时选品系统使用的流计算框架是Blink,Blink是阿里巴巴基于开源流计算框架Flink定制研发的企业级流计算框架,可以认为是Flink的加强版,现在已经开源。Flink是一个高吞吐、低延迟的计算引擎,同时还提供很多高级功能。比如它提供有状态的计算,支持状态管理,支持强一致性的数据语义以及支持Event Time,WaterMark对消息乱序的处理等特性,为闲鱼实时选品系统的超低延时选品提供了有力支持。

3.1、Blink之State
State是指流计算过程中计算节点的中间计算结果或元数据属性,比如在aggregation过程中要在state中记录中间聚合结果,比如Apache Kafka作为数据源时候,我们也要记录已经读取记录的offset,这些State数据在计算过程中会进行持久化(插入或更新)。所以Blink中的State就是与时间相关的,Blink任务的内部数据(计算数据和元数据属性)的快照。
马赫系统会在State中保存商品合并之后的全部数据和规则运行结果数据。当商品发生变更后,马赫系统会将商品变更信息与State保存的商品信息进行合并,并将合并的信息作为入参运行所有规则,最后将规则运行结果与State保存的规则运行结果进行Diff后得到最终有效的运行结果。所以Blink的State特性是马赫系统依赖的关键特性。
3.2、Blink之Window
Blink的Window特性特指流计算系统特有的数据分组方式,Window的创建是数据驱动的,也就是说,窗口是在属于此窗口的第一个元素到达时创建。当窗口结束时候删除窗口及状态数据。Blink的Window主要包括两种,分别为滚动窗口(Tumble)和滑动窗口(Hop)。
滚动窗口有固定大小,在每个窗口结束时进行一次数据计算,也就是说滚动窗口任务每经过一次固定周期就会进行一次数据计算,例如每分钟计算一次总量。

滑动窗口与滚动窗口类似,窗口有固定的size,与滚动窗口不同的是滑动窗口可以通过slide参数控制滑动窗口的新建频率。因此当slide值小于窗口size的值的时候多个滑动窗口会重叠,此时数据会被分配给多个窗口,如下图所示:

Blink的Window特性在数据计算统计方面有很多使用场景,马赫系统主要使用窗口计算系统处理数据的实时速度和延时,用来进行数据统计和监控告警。
3.3、Blink之UDX
UDX是Blink中用户自定义函数,可以在任务中调用以实现一些定制逻辑。Blink的UDX包括三种,分别为:
- UDF - User-Defined Scalar Function
UDF是最简单的自定义函数,输入是一行数据的任意字段,输出是一个字段,可以实现数据比较、数据转换等操作。 - UDTF - User-Defined Table-Valued Function
UDTF 是表值函数,每个输入(单column或多column)返回N(N>=0)Row数据,Blink框架提供了少量的UDTF,比如:STRING_SPLIT,JSON_TUPLE和GENERATE_SERIES3个built-in的UDTF。 - UDAF - User-Defined Aggregate Function
UDAF是聚合函数,输入是多行数据,输出是一个字段。Blink框架Built-in的UDAF包括MAX,MIN,AVG,SUM,COUNT等,基本满足了80%常用的集合场景,但仍有一定比例的复杂业务场景,需要定制自己的聚合函数。
马赫系统中使用了大量的UDX进行逻辑定制,包括消息解析、数据处理等。而马赫系统最核心的商品数据合并、规则运行和结果Diff等流程就是通过UDAF实现的。
四、秒级选品方案
选品系统在项目立项后也设计有多套技术方案。经过多轮讨论后,最终决定对两套方案实施验证后决定最终实现方案。
第一套方案是基于PostgreSQL的方案,PostgreSQL可以很便捷的定义Function进行数据合并操作,在PostgreSQL的trigger上定义执行规则逻辑。基于PostgreSQL的技术实现较复杂,但能满足功能需求。不过性能测试结果显示PostgreSQL处理小数据量(百万级)性能较好;当trigger数量多、trigger逻辑复杂或处理亿级别数据时,PostgreSQL的性能会有较大下滑,不能满足秒级选品的性能指标。因此基于PostgreSQL的方案被否决(在闲鱼小商品池场景中仍在使用)。
第二套方案是基于Blink流计算方案,通过验证发现Blink SQL很适合用来表达数据处理逻辑而且Blink性能很好,综合对比之后最终选择Blink流计算方案作为实际实施的技术方案。
为了配合使用流计算方案,马赫系统经过设计和解耦,无缝对接Blink计算引擎。其中数据处理模块是马赫系统核心功能模块,负责接入商品相关各类数据、校验数据、合并数据、执行规则和处理执行结果并输出等步骤,所以数据处理模块的处理速度和延时在很大程度上能代表马赫系统数据处理速度和延时。接下来我们看下数据处理模块如何与Blink深度结合将数据处理延迟降到秒级。

数据处理模块结构如上图,包含数据接入层、数据合并层、规则运行层和规则运行结果处理层。每层都针对流计算处理模式进行了单独设计。
4.1、数据接入层

数据接入层是数据处理模块前置,负责对接多渠道各种类型的业务数据,主要逻辑如下:
- 数据接入层对接多个渠道多种类型的业务数据;
- 解析业务数据并做简单校验;
- 统计各渠道业务数据量级并进行监控,包括总量和同比变化量;
- 通过元数据中心获取字段级别的Metadata配置。元数据中心是用来保存和管理所有字段的MetaData配置信息组件。Metadata配置代表字段元数据配置,包括字段值类型,值范围和值格式等基础信息;
- 根据Metadata配置进行字段级别数据校验;
- 按照马赫定义的标准数据范式组装数据。
这样设计的考虑是因为业务数据是多种多样的,比如商品信息包括数据库的商品表记录、商品变更的MQ消息和算法产生的离线数据,如果直接通过Blink对接这些业务数据源的话,需要创建多个Blink任务来对接不同类型业务数据源,这种处理方式太重,而且数据接入逻辑与Blink紧耦合,不够灵活。
数据接入层可以很好的解决上述问题,数据接入层可以灵活接入多种业务数据,并且将数据接入与Blink解耦,最终通过同一个Topic发出消息。而Blink任务只要监听对应的Topic就可以连续不断的收到业务数据流,触发接下来的数据处理流程。
4.2、数据合并层

数据合并是数据处理流程的重要步骤,数据合并的主要作用是将商品的最新信息与内存中保存的商品信息合并供后续规则运行使用。数据合并主要逻辑是:
- 监听指定消息队列Topic,获取业务数据消息;
- 解析消息,并将消息内容按照字段重新组装数据,格式为
{key:[timestamp, value]},key是字段名称,value是字段值,timestamp为字段数据产生时间戳; - 将组装后的数据和内存中保存的历史数据根据timestamp进行字段级别数据合并,合并算法为比较timestamp大小取最新字段值,具体逻辑见下图。

数据合并有几个前提:
- 内存可以保存存量数据;
这个是Blink提供的特性,Blink可以将任务运行过程中产生的存量数据保存在内存中,在下一次运行时从内存中取出继续处理。 - 合并后的数据能代表商品的最新状态;
这点需要一个巧妙设计:商品信息有很多字段,每个字段的值是数组,不仅要记录实际值,还要记录当前值的修改时间戳。在合并商品信息时,按照字段进行合并,合并规则是取时间戳最大的值为准。
举例来说,内存中保存的商品ID=1的信息是{"desc": [1, "描述1"], "price": [4, 100.5]},数据流中商品ID=1的信息是{"desc": [2, "描述2"], "price": [3, 99.5]},那么合并结果就是{"desc": [2, "描述2"], "price": [4, 100.5]},每个字段的值都是最新的,代表商品当前最新信息。
当商品信息发生变化后,最新数据由数据接入层流入,通过数据合并层将数据合并到内存,Blink内存中保存的是商品当前最新的全部数据。
4.3、规则运行层

规则运行层是数据处理流程核心模块,通过规则运算得出商品对各规则命中结果,逻辑如下:
- 规则运行层接受输入为经过数据合并后的数据;
- 通过元数据中心获取字段级别Metadata配置;
- 根据字段Metadata配置解析数据;
- 通过规则中心获取有效规则列表,规则中心是指创建和管理规则生命周期的组件;
- 循环规则列表,运行单项规则,将规则命中结果保存在内存;
- 记录运行规则抛出异常的数据,并进行监控告警。
这里的规则指的是运营创建的业务规则,比如商品价格大于50且状态为在线。规则的输入是经过数据合并后的商品数据,输出是true或false,即是否命中规则条件。规则代表的是业务投放场景,马赫系统的业务价值就是在商品发生变更后尽快判断是否命中之前未命中的规则或是不命中之前已经命中的规则,并将命中和不命中结果尽快体现到投放场景中。
规则运行需利用Blink强大算力来保证快速执行,马赫系统当前有将近300条规则,而且还在快速增长。这意味着每个商品发生变更后要在Blink上运行成百上千条规则,闲鱼每天有上亿商品发生变更,这背后需要的运算量是非常惊人的。
4.4、运行结果处理层
读者读到这里可能会奇怪,明明经过规则运行之后直接把运行结果输出到投放场景就可以了,不需要运行结果处理层。实际上运行结果处理层是数据处理模块最重要的部分。
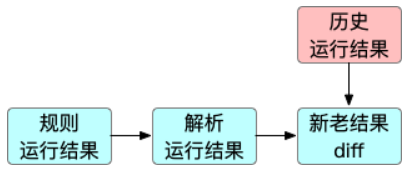
因为在实际场景中,商品的变更在大部分情况只会命中很少一部分规则,而且命中结果也很少会变化。也就是说商品对很多规则的命中结果是没有意义的,如果将这些命中结果也输出的话,只会增加操作TPS,对实际结果没有任何帮助。而筛选出有效的运行结果,这就是运行结果处理层的作用。运行结果处理层逻辑如下:
- 获取商品数据的规则运行结果;
- 按照是否命中规则解析运行结果;
将运行结果与内存中保存的历史运行结果进行diff,diff作用是排除新老结果中相同的命中子项,逻辑见下图。

运行结果处理层利用Blink内存保存商品上一次变更后规则运行结果,并将当前变更后规则运行结果与内存中结果进行比较,计算出有效运行结果。举例来说,商品A上一次变更后规则命中结果为{"rule1":true, "rule2":true, "rule3":false, "rule4":false},当前变更后规则命中结果为{"rule1":true, "rule2":false, "rule3":false, "rule4":true}。因为商品A变更后对rule1和rule3的命中结果没有变化,所以实际有效的命中结果是{"rule2":false, "rule4":true},通过运行结果处理层处理后输出的是有效结果的最小集,可以极大减小无效结果输出,提高数据处理的整体性能和效率。
4.5、难点解析
虽然闲鱼实时选品系统在立项之初经过预研和论证,但因为使用很多新技术框架和流计算思路,在开发过程中遇到一些难题,包括设计和功能实现方面的,很多是设计流计算系统的典型问题。我们就其中一个问题与各位读者探讨-规则公式转换。
4.5.1、规则公式转换
这个问题的业务场景是:运营同学在马赫系统页面上筛选商品字段后保存规则,服务端是已有的老系统,逻辑是根据规则生成一段SQL,SQL的where条件和运营筛选条件相同。SQL有两方面的作用,一方面是作为离线规则,在离线数据库中执行SQL筛选符合规则的离线商品数据;另一方面是转换成在线规则,在Blink任务中对实时商品变更数据执行规则以判断是否命中。
因为实时规则运行使用的是MVEL表达式引擎,MVEL表达式是类Java语法的,所以问题就是将离线规则的SQL转换成在线规则的Java表达式,两者逻辑需一致,并且需兼顾性能和效率。问题的解决方案很明确,解析SQL后将SQL操作符转换成Java操作符,并将SQL特有语法转成Java语法,例如A like '%test%'转成A.contains('test')。
这个问题的难点是如何解析SQL和将解析后的语义转成Java语句。经过调研之后给出了简单而优雅的解决方案,主要步骤如下:
- 使用Druid框架解析SQL语句,转成一个二叉树,单独取出其中的where条件子树;
-
通过后序遍历算法遍历where条件子树;
- 将SQL操作符换成对应的Java操作符;
目前支持且、或、等于、不等于、大于、大于等于、小于、小于等于、like、not like和in等操作。 - 将SQL语法格式转成Java语法;
将in语法改成Java的或语法,例如A in ('hello', 'world')转成(A == 'hello') || (A == 'world')。
- 将SQL操作符换成对应的Java操作符;
实际运行结果如下:
代码逻辑如下(主要是二叉树后续遍历和操作符转换,不再详细解释):

五、结论
马赫系统上线以来,已经支持近400场活动和投放场景,每天处理近1.4亿条消息,峰值TPS达到50000。马赫系统已经成为闲鱼选品投放的重要支撑。
本文主要阐述马赫系统中数据处理的具体设计方案,说明整体设计的来龙去脉。虽然闲鱼实时选品系统针对的是商品选品,但数据处理流计算技术方案的输入是MQ消息,输出也是MQ消息,不与具体业务绑定,所以数据处理流计算技术方案不只适用于商品选品,也适合其他类似实时筛选业务场景。希望我们的技术方案和设计思路能给你带来一些想法和思考,也欢迎和我们留言讨论,谢谢。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
关于引用传递仍是值传递...)


















