
阿里妹导读:在现实世界中,信息通常以不同的模态同时出现。这里提到的模态主要指信息的来源或者形式。例如在淘宝场景中,每个商品通常包含标题、商品短视频、主图、附图、各种商品属性(类目,价格,销量,评价信息等)、详情描述等,这里的每一个维度的信息就代表了一个模态。如何将所有模态的信息进行融合,进而获得一个综合的特征表示,这就是多模态表征要解决的问题。今天,我们就来探索多模态表征感知网络,了解这项拿过冠军的技术。
作者 | 越丰、箫疯、裕宏、华棠
摘要
近些年,深度学习飞速发展,在很多领域(图像、语音、自然语言处理、推荐搜素等)展现出了巨大的优势。多模态表征研究也进行入深度学习时代,各种模态融合策略层出不穷。
在这里,我们主要对图像和文本这两个最常见的模型融合进行探索,并在2个多模态融合场景中取得了目前最好的效果。
- 在文本编辑图像场景中,我们提出了双线性残差层 ( Bilinear Residual Layer ),对图像和文本两个模态的特征进行双线性表示 ( Bilinear Representation),用来自动学习图像特征和文本特征间更优的融合方式。
- 在时尚图像生成场景中(给定文本直接生成对应的图像),我们采用了跨模态注意力机制(Cross Attention)对生成的图像和文本特征进行融合,再生成高清晰度且符合文本描述的时尚图像。最后,在客观评分和主观评分上取得了最好的成绩。
文本编辑图像
图像编辑是指对模拟图像内容的改动或者修饰,使之满足我们的需要,常见的图像处理软件有Photoshop、ImageReady等。随着人们对于图像编辑需求的日益提升,越来越多的图像要经过类似的后处理。但是图像处理软件使用复杂且需要经过专业的培训,这导致图像编辑流程消耗了大量人力以及时间成本,为解决该问题,一种基于文本的图像编辑手段被提出。基于文本的图像编辑方法通过一段文本描述,自动地编辑源图像使其符合给出的文本描述,从而简化图像编辑流程。例如图1所示,通过基于文本的图像编辑技术可以通过文字命令改变模特衣服的颜色,纹理甚至款式。

图1 基于文本的图像编辑技术示例
然而,基于文本的图像编辑技术目前仍然难以实现,原因是文本和图像是跨模态的,要实现一个智能的图像编辑系统则需要同时提取文本和源图像中的关键语义。这使得我们的模型需要很强的表示学习能力。
现有方法
目前已有一些针对基于文本的图像编辑所提出的方法。他们都采用了强大的图像生成模型GAN(Generative adversarial network)作为基本框架。Hao[1]训练了一个conditional GAN,它将提取出来的text embeddings作为conditional vector和图像特征连接在一起,作为两个模态信息的混合表示,然后通过反卷积操作生成目标图像 (如图2)。
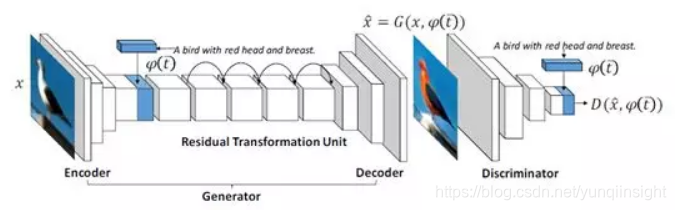
图2 使用传统conditional GAN实现的基于文本的图像编辑方案
Mehmet[2]对以上方法做了改进,他认为特征连接并不是一种好的模态信息融合方式,并用一种可学习参数的特征线性调制方法3去学习图像和文本的联合特征。FiLM减少了模型的参数,同时使得联合特征是可学习的,提高了模型的表示学习能力 (如图3)。

图3 使用FiLM+conditional GAN实现的基于文本的图像编辑方案
我们的工作
我们的工作从理论角度分析了连接操作和特征线性调制操作间特征表示能力的优劣,并将这两种方法推广到更一般的形式:双线性 (Bilinear representation)。据此,我们提出表示学习能力更加优越的双线性残差层 (Bilinear Residual Layer),用来自动学习图像特征和文本特征间更优的融合方式。
Conditioning的原始形式
首先,本文将介绍conditional GAN中的连接操作和它的形式化表达,假设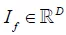 和
和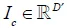 分别为前一层的输出和conditional vector,其中D和
分别为前一层的输出和conditional vector,其中D和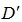 为特征维度,连接的表示为
为特征维度,连接的表示为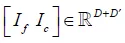 ,后一层的权重
,后一层的权重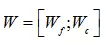 ,其中
,其中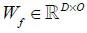 和
和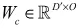 分别为
分别为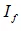 和
和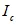 对应的权重,O为输出维度,我们可得到如下变换:
对应的权重,O为输出维度,我们可得到如下变换:
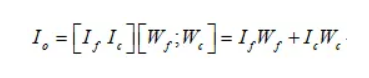
其中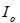 为输出张量。
为输出张量。
FiLM形式
FiLM源自于将特征乘以0-1之间的向量来模拟注意力机制的想法,FiLM进行特征维度上的仿射变换,即:
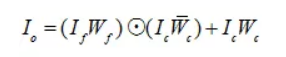
其中,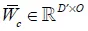 是缩放系数
是缩放系数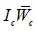 的权重。显而易见,当为全1矩阵时,FiLM退化成Conditioning的原始形式,由此,可以得出FiLM是连接操作的更一般情况。
的权重。显而易见,当为全1矩阵时,FiLM退化成Conditioning的原始形式,由此,可以得出FiLM是连接操作的更一般情况。
Bilinear形式
以上的方法都只是线性变换,我们的工作在此基础上,提出了双线性的形式,即输出张量第i维的值由权重矩阵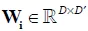 控制:
控制: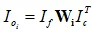 。
。
经过证明,Bilinear形式可以看做FiLM的进一步推广,它具有更加强大的表示学习能力。证明如下:
为了证明FiLM可以由Bilinear的形式表示,首先要将FiLM变换写成单个特征值的情况,假设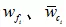 和
和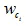 分别对应和中第个i输出值对应的权值,FiLM可以写成:
分别对应和中第个i输出值对应的权值,FiLM可以写成:

以上形式等同于:
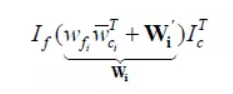
其中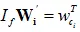 ,而
,而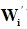 可以通过随机选择
可以通过随机选择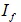 中的一个非零元素
中的一个非零元素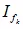 来构造,从而构造如下:
来构造,从而构造如下:

中除了第k行其他位置的元素全为0。显而易见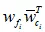 和的秩均为1,由此可得出
和的秩均为1,由此可得出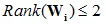 ,也就是说,当Bilinear变换矩阵
,也就是说,当Bilinear变换矩阵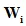 是稀疏的并且有不大于2的秩时,Bilinear形式等同于FiLM。这间接说明Bilinear形式是FiLM的推广。
是稀疏的并且有不大于2的秩时,Bilinear形式等同于FiLM。这间接说明Bilinear形式是FiLM的推广。
Bilinear的Low-rank简化形式
虽然Bilinear有更强的表示能力,但它的参数实在是太多了,为了降低模型复杂度,实际中常常采用一种低秩的方法[4]简化计算,通过将分解为两个低秩阵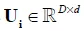 和
和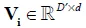 ,其中d为指定的秩。由此,Bilinear的Low-rank简化形式可写为:
,其中d为指定的秩。由此,Bilinear的Low-rank简化形式可写为:
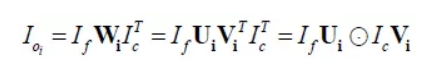
然后通过矩阵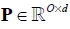 将输出张量投影到输出维度上:
将输出张量投影到输出维度上:
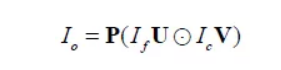
我们将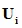 、
、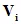 和P作为网络内部可学习的层,并结合短路结构,提出双线性残差层 (Bilinear Residual Layer, BRL),具体可见图4。
和P作为网络内部可学习的层,并结合短路结构,提出双线性残差层 (Bilinear Residual Layer, BRL),具体可见图4。
算法的整体框架如图4,网络由生成器和判别器构成,生成器有三个模块:编码模块,融合模块,解码模块。编码模块由预训练好的文本编码器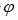 和图像特征提取器
和图像特征提取器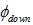 构成,图像特征提取器直接使用VGG16模型conv1-4层权值。融合模块由4个双线性残差层 (Bilinear Residual Layer, BRL)构成,解码模块则是将处理好的特征上采样成图像。
构成,图像特征提取器直接使用VGG16模型conv1-4层权值。融合模块由4个双线性残差层 (Bilinear Residual Layer, BRL)构成,解码模块则是将处理好的特征上采样成图像。

图4 方法的整体框架
训练时,模型得到图像-文本对的输入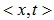 ,t为匹配图像x的对应描述,假设用于编辑图像的文本为
,t为匹配图像x的对应描述,假设用于编辑图像的文本为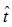
,生成器接收和x作为输入得到:
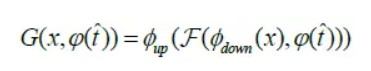
其中,F表示融合模块。对抗训练过程中,判别器被训练以区分语义不相关的图像文本对,因此我们需要从文本库中选择不匹配的文本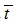 作为负样本,判别器的损失函数如下:
作为负样本,判别器的损失函数如下:
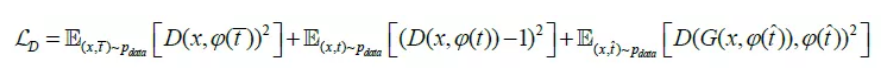
其中前两项为了区分正负样本对,第三项为了尽可能识别生成图像和文本的不匹配。同时生成器G被训练以生成和文本匹配的图像:

整体目标函数即由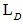 和
和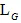 所构成。
所构成。
实验结果
我们的方法在Caltech-200 bird[5]、Oxford-102 flower[6]以及Fashion Synthesis[7]三个数据集上进行了验证。定性结果如图5所示,第一列为原图,第二列表示Conditional GAN原始形式的方法,第三列表示基于FiLM的方法,最后一列是论文提出的方法。很明显前两者对于复杂图像的编辑会失败,而论文提出的方法得到的图像质量都较高。

图5 生成样本定性结果
除此之外,实验还进行了定量分析,尽管对于图像生成任务还很难定量评估,但是本工作采用了近期提出的近似评价指标Inception Score (IS)[8]作为度量标准。由表6可见,我们的方法获得了更高的IS得分,同时在矩阵秩设定为256时,IS得分最高。
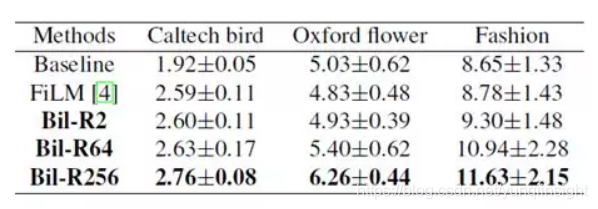
表6 生成样本定量结果
时尚图像生成
在调研多模态融合技术的时候,有一个难点就是文本的描述其实对应到图像上局部区域的特性。例如图7,Long sleeve对应了图像中衣服袖子的区域,并且是长袖。另外,整个文本描述的特性对应的是整个图像的区域。基于这个考虑,我们认为图像和文本需要全局和局部特征描述,图像全局特征描述对应到整个图像的特征,局部特征对应图像每个区域的特征。文本的全局特征对应整个句子的特征,文本的局部特征对应每个单词的特征。然后文本和图像的全局和局部区域进行特征融合。
针对这种融合策略,我们在时尚图像生成任务上进行了实验。时尚图像生成(FashionGEN)是第一届Workshop On Computer VisionFor Fashion, Art And Design中一个比赛,这个比赛的任务是通过文本的描述生成高清晰度且符合文本描述的商品图像。我们在这个比赛中客观评分和人工评分上均获得的第一,并取得了这个比赛的冠军。
我们的方法
我们方法基于细粒度的跨模态注意力,主要思路是将不同模态的数据(文本、图像)映射到同一特征空间中计算相似度,从而学习文本中每个单词语义和图像局部区域特征的对应关系,辅助生成符合文本描述的细粒度时尚图像,如图7所示。
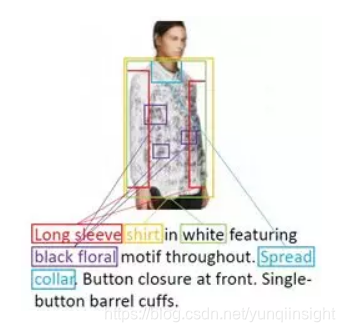
图7 不同单词描述图像不同区域示例
传统的基于文本的图像生成方法通常只学习句子和图像整体的语义关联,缺乏对服装细节纹理或设计的建模。为了改进这一问题,我们引入了跨模态注意力机制。如图8左边区域,已知图像的局部特征,可以计算句子中不同单词对区域特征的重要性,而句子语义可以视为基于重要性权重的动态表示。跨模态注意力可以将图片与文字的语义关联在更加精细的局部特征层级上建模,有益于细粒度时尚图像的生成。

图8 跨模态注意力机制,左图表示通过图像局部特征计算不同单词的重要性,右图表示通过词向量计算不同图像局部特征的重要性
我们用bi-LSTM作为文本编码器,GAN作为对抗生成模型,并将生成过程分为由粗到精,逐步增加分辨率的两个阶段:
- 第一阶段利用句子的整体语义和随机输入学习图像在大尺度上的整体结构。
- 第二阶段利用单词层级的语义在第一阶段低分辨率输出上做局部细节的修正和渲染,得到细粒度的高分辨率时尚图像输出。

图9 整体框架概览,顶部分支利用文本整体语义学习低分辨率的图像大致结构,底部分支在上一阶段的输出上做图像细节的修正,生成更加细粒度的时尚设计或纹理。
对抗生成网络
传统的生成式对抗网络由判别器和生成器两部分组成,判别器的目标是判别生成图像是否在真实数据集的分布中,而生成器的目标是尽可能的骗过判别器生成逼近真实数据集的图像,通过两者的迭代更新,最终达到理论上的纳什均衡点。这个过程被称为对抗训练,对抗训练的提出为建立图像等复杂数据分布建立了可能性。
对于文本生成图像的任务,需要更改生成器的输入以及目标函数,我们将两个阶段的生成器分别设为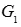 和
和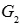 ,整个流程可被形式化为:
,整个流程可被形式化为:
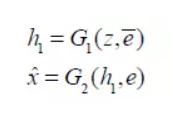
其中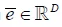 是句子向量,D为双向LSTM两个方向上输出的维度和,
是句子向量,D为双向LSTM两个方向上输出的维度和,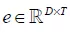 是词向量矩阵,T指代单词的个数,
是词向量矩阵,T指代单词的个数,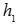 表示第一阶段激活值输出,
表示第一阶段激活值输出,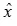 表示生成的图像。我们需要优化的目标函数定义为:
表示生成的图像。我们需要优化的目标函数定义为:
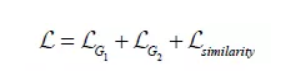
其中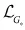 是对抗损失,
是对抗损失,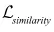 是生成图像和对应描述的相似性损失,
是生成图像和对应描述的相似性损失,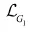 由两部分组成:
由两部分组成:
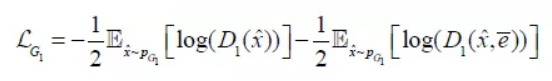
其中第一项非条件损失表示图像本身的真伪,第二项条件损失表示图像和句子语义是否匹配。对 也同理。
也同理。
判别器 ,同时也被训练以最小化交叉熵损失:
,同时也被训练以最小化交叉熵损失:
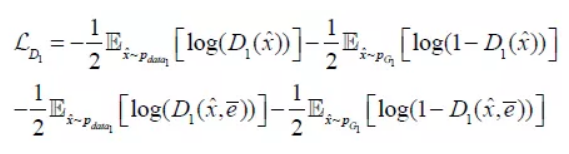
该项对也同理。
基于跨模态注意力的相似性
本节将详细介绍在我们的方法中用到的跨模态注意力机制,给出图像-文本对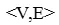 ,我们取Inceptionv3中mixed-6e层的输出768×17×17作为图像区域特征,我们将空间维度展平得到768×289,averagepooling层的输出2048作为图像全局特征,对这些特征使用投影矩阵
,我们取Inceptionv3中mixed-6e层的输出768×17×17作为图像区域特征,我们将空间维度展平得到768×289,averagepooling层的输出2048作为图像全局特征,对这些特征使用投影矩阵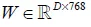 和
和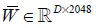 变换到
变换到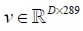 和
和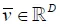 。由此,可以得到相似度矩阵:
。由此,可以得到相似度矩阵:
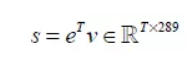
其中元素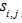 代表了第i个单词和第j个子区域的点积相似性。
代表了第i个单词和第j个子区域的点积相似性。
图像-文本相似性
对于第i个单词,我们最终可以建立不同区域特征的加权和(越相似赋予越大的权重):
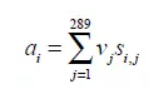
其中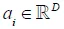 是对应于第i个单词,图像特征的动态表述。
是对应于第i个单词,图像特征的动态表述。
对第i个单词,求得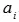 和
和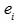 的余弦相似度:
的余弦相似度:

综合可得图片对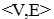 的相似度为:
的相似度为:
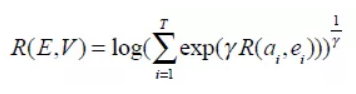
其中超参数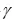 表示最相关的单词-图像区域对对最终相似度得分的影响程度。在一个batch的图像-文本对中,我们最大化正确对的相似度,最小化错误对的相似度:
表示最相关的单词-图像区域对对最终相似度得分的影响程度。在一个batch的图像-文本对中,我们最大化正确对的相似度,最小化错误对的相似度:
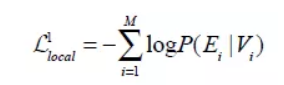
其中,
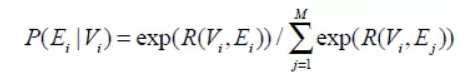
M为batchsize的大小。
文本-图像相似性
同理的,文本-图像的相似性可以形式化为:
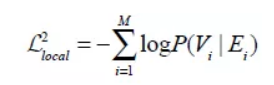
全局相似性
以上我们计算了局部特征上的相似性得分,在全局区域,我们可以利用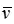 和
和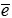 的余弦距离作为全局相似度:
的余弦距离作为全局相似度:

综上,有:
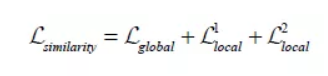
通过优化以上损失函数,我们最终得到的生成的服装图片的效果图如下所示:
附上算法效果图:

总结
我们主要对图像和文本这两个最常见的模型融合进行探索,在文本编辑图像任务上,我们提出基于双线性残差层 (Bilinear Residual Layer)的图文融合策略,并取得了最好的效果,相关工作已经发表在ICASSP 2019上,点击文末“阅读原文”即可查看论文。在时尚图像生成任务上,我们使用了细粒度的跨模态融合策略,并在FashionGen竞赛中取得第一。
关于我们
阿里安全图灵实验室专注于AI在安全和平台治理领域的应用,涵盖风控、知识产权、智能云服务和新零售等商业场景,以及医疗、教育、出行等数亿用户相关的生活场景,已申请专利上百项。2018年12月,阿里安全图灵实验室正式对外推出“安全AI”,并总结其在知识产权保护、新零售、内容安全等领域进行深度应用的成果:2018年全年,内容安全AI调用量达到1.5万亿次;知识产权AI正在为上千个原创商家的3000多个原创商品提供电子“出生证”——线上与全平台商品图片对比,智能化完成原创性校验,作为原创商家电子备案及后续维权的重要依据;新零售场景的防盗损对小偷等识别精准度达到100%。
原文链接
本文为云栖社区原创内容,未经允许不得转载。





慢的问题)










)


