SERVER-17397: Dropping a Database or Collection in a Sharded Cluster may not fully succeed 是 MongoDB 里老大难的问题,库或集合删除操作如果没有完全执行成功,再新建相同名字的集合,可能导致读到老版本数据的问题。

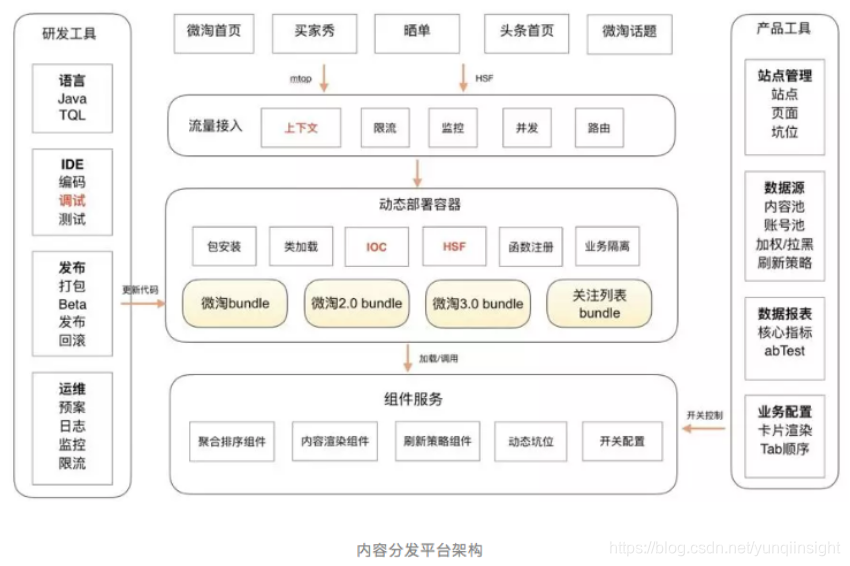
集合分片原理
MongoDB sharding 分片原理参考 MongoDB Sharded cluster架构原理
总的来说,当用户对集合执行开启分片之后,集合分片的元数据会保存在 config server 的 config 集合里
config.collections记录集合分片的元数据,根据哪个 shardKey 分片,集合是否已经被删除等元数据config.chunks,记录各个 chunk(shardKey的某一段范围)对应的 shard 信息,用于路由请求- 各个 shard 里存储集合实际的数据
删除分片集合流程
- 删除所有 shard 里的对应的数据
- 删除 config.chunks 这个集合相关的chunk信息
- 修改 config.collections,标记集合已经删除
注:3.2+都是按上述流程操作,删除 Database 过程类似,还需要再额外操作 config.databases 集合,但本质上存在的问题类似
上述动作需要操作 config server 以及 所有的 shard,如果中间有步骤失败(一些很老的版本,并不是按照上述步骤执行,而且执行过程中可能没有严格检查返回的错误码,即使返回成功实际上内部可能执行失败),最终导致集合的部分数据仍然残留,没有完全清理干净。
如果这个集合名字重新被使用,再次调用 shardCollection 产生新的分片元数据,可能导致
- 在 shard 上的一些残留数据可能被读取到,而这些数据实际上应该被删除了
- mongos 没有成功更新路由信息,最终可能出现多个 mongos 看到的数据视图也不一致,有的 mongos 能读到数据,有的读不到(通过 `flushRouterConfig 命令可以强制刷新路由信息可解决)
解决方案
MongoDB sharding 删除集合/数据库涉及到多个节点进行操作,这些动作无法做到原子性,可能导致一个集合最终处于某种中间状态;复用该集合可能导致一写数据一致性问题。
- 使用 MongoDB 3.2+ 以上版本,大部分case,只要没有异常,删除集合动作都能正常完成的,复用集合名字问题一般问题也不大,但无法完全避免问题。
- 建议 Sharding 环境下,namespace 名字一旦被删除,不要再次复用
- 在需要复用 Namespace 的情况下,如果要确保不会有数据问题,每次可以按 drop collection workaround 确保相关数据被正确清理,并且路由信息被更新。
抢阿里云新用户专属优惠权益,致电95187-1 !
原文链接
本文为云栖社区原创内容,未经允许不得转载。