
阿里妹导读:任何应用系统都离不开对数据的处理,数据也是驱动业务创新以及向智能化发展最核心的东西。数据处理的技术已经是核心竞争力。在一个完备的技术架构中,通常也会由应用系统以及数据系统构成。应用系统负责处理业务逻辑,而数据系统负责处理数据。本篇文章主要面向数据系统的研发工程师和架构师,希望对你有所启发。
前言
传统的数据系统就是所谓的『大数据』技术,这是一个被创造出来的名词,代表着新的技术门槛。近几年得益于产业的发展、业务的创新、数据的爆发式增长以及开源技术的广泛应用,经历多年的磨炼以及在广大开发者的共建下,大数据的核心组件和技术架构日趋成熟。特别是随着云的发展,让『大数据』技术的使用门槛进一步降低,越来越多的业务创新会由数据来驱动完成。
『大数据』技术会逐步向轻量化和智能化方向发展,最终也会成为一个研发工程师的必备技能之一,而这个过程必须是由云计算技术来驱动以及在云平台之上才能完成。应用系统和数据系统也会逐渐融合,数据系统不再隐藏在应用系统之后,而是也会贯穿在整个业务交互逻辑。传统的应用系统,重点在于交互。而现代的应用系统,在与你交互的同时,会慢慢地熟悉你。数据系统的发展驱动了业务系统的发展,从业务化到规模化,再到智能化。
- 业务化:完成最基本的业务交互逻辑。
- 规模化:分布式和大数据技术的应用,满足业务规模增长的需求以及数据的积累。
- 智能化:人工智能技术的应用,挖掘数据的价值,驱动业务的创新。
向规模化和智能化的发展,仍然存在一定的技术门槛。成熟的开源技术的应用能让一个大数据系统的搭建变得简单,同时大数据架构也变得很普遍,例如广为人知的Lambda架构,一定程度上降低了技术的入门门槛。但是对数据系统的后续维护,例如对大数据组件的规模化应用、运维管控和成本优化,需要掌握大数据、分布式技术及复杂环境下定位问题的能力,仍然具备很高的技术门槛。
数据系统的核心组件包含数据管道、分布式存储和分布式计算,数据系统架构的搭建会是使用这些组件的组合拼装。每个组件各司其职,组件与组件之间进行上下游的数据交换,而不同模块的选择和组合是架构师面临的最大的挑战。
本篇文章主要面向数据系统的研发工程师和架构师,我们会首先对数据系统核心组件进行拆解,介绍每个组件下对应的开源组件以及云上产品。之后会深入剖析数据系统中结构化数据的存储技术,介绍阿里云Tablestore选择哪种设计理念来更好的满足数据系统中对结构化数据存储的需求。
数据系统架构
核心组件

上图是一个比较典型的技术架构,包含应用系统和数据系统。这个架构与具体业务无关联,主要用于体现一个数据应用系统中会包含的几大核心组件,以及组件间的数据流关系。应用系统主要实现了应用的主要业务逻辑,处理业务数据或应用元数据等。数据系统主要对业务数据及其他数据进行汇总和处理,对接BI、推荐或风控等系统。整个系统架构中,会包含以下比较常见的几大核心组件:
关系数据库:用于主业务数据存储,提供事务型数据处理,是应用系统的核心数据存储。
高速缓存:对复杂或操作代价昂贵的结果进行缓存,加速访问。
搜索引擎:提供复杂条件查询和全文检索。
队列:用于将数据处理流程异步化,衔接上下游对数据进行实时交换。异构数据存储之间进行上下游对接的核心组件,例如数据库系统与缓存系统或搜索系统间的数据对接。也用于数据的实时提取,在线存储到离线存储的实时归档。
非结构化大数据存储:用于海量图片或视频等非结构化数据的存储,同时支持在线查询或离线计算的数据访问需求。
结构化大数据存储:在线数据库也可作为结构化数据存储,但这里提到的结构化数据存储模块,更偏在线到离线的衔接,特征是能支持高吞吐数据写入以及大规模数据存储,存储和查询性能可线性扩展。可存储面向在线查询的非关系型数据,或者是用于关系数据库的历史数据归档,满足大规模和线性扩展的需求,也可存储面向离线分析的实时写入数据。
批量计算:对非结构化数据和结构化数据进行数据分析,批量计算中又分为交互式分析和离线计算两类,离线计算需要满足对大规模数据集进行复杂分析的能力,交互式分析需要满足对中等规模数据集实时分析的能力。
流计算:对非结构化数据和结构化数据进行流式数据分析,低延迟产出实时视图。
对于数据存储组件我们再进一步分析,当前各类数据存储组件的设计是为满足不同场景下数据存储的需求,提供不同的数据模型抽象,以及面向在线和离线的不同的优化偏向。我们来看下下面这张详细对比表:

派生数据体系
在数据系统架构中,我们可以看到会存在多套存储组件。对于这些存储组件中的数据,有些是来自应用的直写,有些是来自其他存储组件的数据复制。例如业务关系数据库的数据通常是来自业务,而高速缓存和搜索引擎的数据,通常是来自业务数据库的数据同步与复制。不同用途的存储组件有不同类型的上下游数据链路,我们可以大概将其归类为主存储和辅存储两类,这两类存储有不同的设计目标,主要特征为:
- 主存储:数据产生自业务或者是计算,通常为数据首先落地的存储。ACID等事务特性可能是强需求,提供在线应用所需的低延迟业务数据查询。
- 辅存储:数据主要来自主存储的数据同步与复制,辅存储是主存储的某个视图,通常面向数据查询、检索和分析做优化。
为何会有主存储和辅存储的存在?能不能统一存储统一读写,满足所有场景的需求呢?目前看还没有,存储引擎的实现技术有多种,选择行存还是列存,选择B+tree还是LSM-tree,存储的是不可变数据、频繁更新数据还是时间分区数据,是为高速随机查询还是高吞吐扫描设计等等。数据库产品目前也是分两类,TP和AP,虽然在往HTAP方向走,但实现方式仍然是底层存储分为行存和列存。
再来看主辅存储在实际架构中的例子,例如关系数据库中主表和二级索引表也可以看做是主与辅的关系,索引表数据会随着主表数据而变化,强一致同步并且为某些特定条件组合查询而优化。关系数据库与高速缓存和搜索引擎也是主与辅的关系,采用满足最终一致的数据同步方式,提供高速查询和检索。在线数据库与数仓也是主与辅的关系,在线数据库内数据集中复制到数仓来提供高效的BI分析。
这种主与辅的存储组件相辅相成的架构设计,我们称之为『派生数据体系』。在这个体系下,最大的技术挑战是数据如何在主与辅之间进行同步与复制。

上图我们可以看到几个常见的数据复制方式:
- 应用层多写:这是实现最简单、依赖最少的一种实现方式,通常采取的方式是在应用代码中先向主存储写数据,后向辅存储写数据。这种方式不是很严谨,通常用在对数据可靠性要求不是很高的场景。因为存在的问题有很多,一是很难保证主与辅之间的数据一致性,无法处理数据写入失效问题;二是数据写入的消耗堆积在应用层,加重应用层的代码复杂度和计算负担,不是一种解耦很好的架构;三是扩展性较差,数据同步逻辑固化在代码中,比较难灵活添加辅存储。
- 异步队列复制:这是目前被应用比较广的架构,应用层将派生数据的写入通过队列来异步化和解耦。这种架构下可将主存储和辅存储的数据写入都异步化,也可仅将辅存储的数据写入异步化。第一种方式必须接受主存储可异步写入,否则只能采取第二种方式。而如果采用第二种方式的话,也会遇到和上一种『应用层多写』方案类似的问题,应用层也是多写,只不过是写主存储与队列,队列来解决多个辅存储的写入和扩展性问题。
- CDC(Change Data Capture)技术:这种架构下数据写入主存储后会由主存储再向辅存储进行同步,对应用层是最友好的,只需要与主存储打交道。主存储到辅存储的数据同步,则可以再利用异步队列复制技术来做。不过这种方案对主存储的能力有很高的要求,必须要求主存储能支持CDC技术。一个典型的例子就是MySQL+Elasticsearch的组合架构,Elasticsearch的数据通过MySQL的binlog来同步,binlog就是MySQL的CDC技术。
『派生数据体系』是一个比较重要的技术架构设计理念,其中CDC技术是更好的驱动数据流动的关键手段。具备CDC技术的存储组件,才能更好的支撑数据派生体系,从而能让整个数据系统架构更加灵活,降低了数据一致性设计的复杂度,从而来面向高速迭代设计。可惜的是大多数存储组件不具备CDC技术,例如HBase。而阿里云Tablestore具备非常成熟的CDC技术,CDC技术的应用也推动了架构的创新,这个在下面的章节会详细介绍。
一个好的产品,在产品内部会采用派生数据架构来不断扩充产品的能力,能将派生的过程透明化,内部解决数据同步、一致性及资源配比问题。而现实中大多数技术架构采用产品组合的派生架构,需要自己去管理数据同步与复制等问题,例如常见的MySQL+Elasticsearch,或HBase+Solr等。这种组合通常被忽视的最大问题是,在解决CDC技术来实时复制数据后,如何解决数据一致性问题?如何追踪数据同步延迟?如何保证辅存储与主存储具备相同的数据写入能力?
存储组件的选型
架构师在做架构设计时,最大的挑战是如何对计算组件和存储组件进行选型和组合,同类的计算引擎的差异化相对不大,通常会优先选择成熟和生态健全的计算引擎,例如批量计算引擎Spark和流计算引擎Flink。而对于存储组件的选型是一件非常有挑战的事,存储组件包含数据库(又分为SQL和NoSQL两类,NoSQL下又根据各类数据模型细分为多类)、对象存储、文件存储和高速缓存等不同类别。带来存储选型复杂度的主要原因是架构师需要综合考虑数据分层、成本优化以及面向在线和离线的查询优化偏向等各种因素,且当前的技术发展还是多样化的发展趋势,不存在一个存储产品能满足所有场景下的数据写入、存储、查询和分析等需求。有一些经验可以分享给大家:
- 数据模型和查询语言仍然是不同数据库最显著的区别,关系模型和文档模型是相对抽象的模型,而类似时序模型、图模型和键值模型等其他非关系模型是相对具象的抽象,如果场景能匹配到具象模型,那选择范围能缩小点。
- 存储组件通常会划分到不同的数据分层,选择面向规模、成本、查询和分析性能等不同维度的优化偏向,选型时需要考虑清楚对这部分数据存储所要求的核心指标。
- 区分主存储还是辅存储,对数据复制关系要有明确的梳理。(主存储和辅存储是什么在下一节介绍)
- 建立灵活的数据交换通道,满足快速的数据搬迁和存储组件间的切换能力,构建快速迭代能力比应对未知需求的扩展性更重要。
另外关于数据存储架构,我认为最终的趋势是:
- 数据一定需要分层
- 数据最终的归属地一定是OSS
- 会由一个统一的分析引擎来统一分析的入口,并提供统一的查询语言
结构化大数据存储
定位
结构化大数据存储在数据系统中是一个非常关键的组件,它起的一个很大的作用是连接『在线』和『离线』。作为数据中台中的结构化数据汇总存储,用于在线数据库中数据的汇总来对接离线数据分析,也用于离线数据分析的结果集存储来直接支持在线查询或者是数据派生。根据这样的定位,我们总结下对结构化大数据存储的几个关键需求。
关键需求
大规模数据存储:结构化大数据存储的定位是集中式的存储,作为在线数据库的汇总(大宽表模式),或者是离线计算的输入和输出,必须要能支撑PB级规模数据存储。
高吞吐写入能力:数据从在线存储到离线存储的转换,通常是通过ETL工具,T+1式的同步或者是实时同步。结构化大数据存储需要能支撑多个在线数据库内数据的导入,也要能承受大数据计算引擎的海量结果数据集导出。所以必须能支撑高吞吐的数据写入,通常会采用一个为写入而优化的存储引擎。
丰富的数据查询能力:结构化大数据存储作为派生数据体系下的辅存储,需要为支撑高效在线查询做优化。常见的查询优化包括高速缓存、高并发低延迟的随机查询、复杂的任意字段条件组合查询以及数据检索。这些查询优化的技术手段就是缓存和索引,其中索引的支持是多元化的,面向不同的查询场景提供不同类型的索引。例如面向固定组合查询的基于B+tree的二级索引,面向地理位置查询的基于R-tree或BKD-tree的空间索引或者是面向多条件组合查询和全文检索的倒排索引。
存储和计算成本分离:存储计算分离是目前一个比较热的架构实现,对于一般应用来说比较难体会到这个架构的优势。在云上的大数据系统下,存储计算分离才能完全发挥优势。存储计算分离在分布式架构中,最大的优势是能提供更灵活的存储和计算资源管理手段,大大提高了存储和计算的扩展性。对成本管理来说,只有基于存储计算分离架构实现的产品,才能做到存储和计算成本的分离。
存储和计算成本的分离的优势,在大数据系统下会更加明显。举一个简单的例子,结构化大数据存储的存储量会随着数据的积累越来越大,但是数据写入量是相对平稳的。所以存储需要不断的扩大,但是为了支撑数据写入或临时的数据分析而所需的计算资源,则相对来说比较固定,是按需的。
数据派生能力:一个完整的数据系统架构下,需要有多个存储组件并存。并且根据对查询和分析能力的不同要求,需要在数据派生体系下对辅存储进行动态扩展。所以对于结构化大数据存储来说,也需要有能扩展辅存储的派生能力,来扩展数据处理能力。而判断一个存储组件是否具备更好的数据派生能力,就看是否具备成熟的CDC技术。
计算生态:数据的价值需要靠计算来挖掘,目前计算主要划为批量计算和流计算。对于结构化大数据存储的要求,一是需要能够对接主流的计算引擎,例如Spark、Flink等,作为输入或者是输出;二是需要有数据派生的能力,将自身数据转换为面向分析的列存格式存储至数据湖系统;三是自身提供交互式分析能力,更快挖掘数据价值。
满足第一个条件是最基本要求,满足第二和第三个条件才是加分项。
开源产品
目前开源界比较知名的结构化大数据存储是HBase和Cassandra,Cassandra是WideColumn模型NoSQL类别下排名Top-1的产品,在国外应用比较广泛。但这里我们重点提下HBase,因为在国内的话相比Cassandra会更流行一点。
HBase是基于HDFS的存储计算分离架构的WideColumn模型数据库,拥有非常好的扩展性,能支撑大规模数据存储,它的优点为:
- 存储计算分离架构:底层基于HDFS,分离的架构可带来存储和计算各自弹性扩展的优势,与计算引擎例如Spark可共享计算资源,降低成本。
- LSM存储引擎:为写入优化设计,能提供高吞吐的数据写入。
- 开发者生态成熟,接入主流计算引擎:作为发展多年的开源产品,在国内也有比较多的应用,开发者社区很成熟,对接几大主流的计算引擎。
HBase有其突出的优点,但也有几大不可忽视的缺陷:
查询能力弱:提供高效的单行随机查询以及范围扫描,复杂的组合条件查询必须使用Scan+Filter的方式,稍不注意就是全表扫描,效率极低。HBase的Phoenix提供了二级索引来优化查询,但和MySQL的二级索引一样,只有符合最左匹配的查询条件才能做索引优化,可被优化的查询条件非常有限。
数据派生能力弱:前面章节提到CDC技术是支撑数据派生体系的核心技术,HBase不具备CDC技术。HBase Replication具备CDC的能力,但是仅为HBase内部主备间的数据同步机制。有一些开源组件利用其内置Replication能力来尝试扩展HBase的CDC技术,例如用于和Solr同步的Lily Indexer,但是比较可惜的是这类组件从理论和机制上分析就没法做到CDC技术所要求的数据保序、最终一致性保证等核心需求。
成本高:前面提到结构化大数据存储的关键需求之一是存储与计算的成本分离,HBase的成本取决于计算所需CPU核数成本以及磁盘的存储成本,基于固定配比物理资源的部署模式下CPU和存储永远会有一个无法降低的最小比例关系。即随着存储空间的增大,CPU核数成本也会相应变大,而不是按实际所需计算资源来计算成本。要达到完全的存储与计算成本分离,只有云上的Serverless服务模式才能做到。
运维复杂:HBase是标准的Hadoop组件,最核心依赖是Zookeeper和HDFS,没有专业的运维团队几乎无法运维。
热点处理能力差:HBase的表的分区是Range Partition的方式,相比Hash Partition的模式最大的缺陷就是会存在严重的热点问题。HBase提供了大量的最佳实践文档来指引开发者在做表的Rowkey设计的时候避免热点,例如采用hash key,或者是salted-table的方式。但这两种方式下能保证数据的分散均匀,但是无法保证数据访问的热度均匀。访问热度取决于业务,需要一种能根据热度来对Region进行Split或Move等负载均衡的自动化机制。
国内的高级玩家大多会基于HBase做二次开发,基本都是在做各种方案来弥补HBase查询能力弱的问题,根据自身业务查询特色研发自己的索引方案,例如自研二级索引方案、对接Solr做全文索引或者是针对区分度小的数据集的bitmap索引方案等等。总的来说,HBase是一个优秀的开源产品,有很多优秀的设计思路值得借鉴。
Tablestore
Tablestore是阿里云自研的结构化大数据存储产品,具体产品介绍可以参考官网以及权威指南。Tablestore的设计理念很大程度上顾及了数据系统内对结构化大数据存储的需求,并且基于派生数据体系这个设计理念专门设计和实现了一些特色的功能。
| 设计理念
Tablestore的设计理念一方面吸收了优秀开源产品的设计思路,另一方面也是结合实际业务需求演化出了一些特色设计方向,简单概括下Tablestore的技术理念:
- 存储计算分离架构:采用存储计算分离架构,底层基于飞天盘古分布式文件系统,这是实现存储计算成本分离的基础。
- LSM存储引擎:LSM和B+tree是主流的两个存储引擎实现,其中LSM专为高吞吐数据写入优化,也能更好的支持数据冷热分层。
- Serverless产品形态:基于存储计算分离架构来实现成本分离的最关键因素是Serverless服务化,只有Serverless服务才能做到存储计算成本分离。大数据系统下,结构化大数据存储通常会需要定期的大规模数据导入,来自在线数据库或者是来自离线计算引擎,在此时需要有足够的计算能力能接纳高吞吐的写入,而平时可能仅需要比较小的计算能力,计算资源要足够的弹性。另外在派生数据体系下,主存储和辅存储通常是异构引擎,在读写能力上均有差异,有些场景下需要灵活调整主辅存储的配比,此时也需要存储和计算资源弹性可调。
- 多元化索引,提供丰富的查询能力:LSM引擎特性决定了查询能力的短板,需要索引来优化查询。而不同的查询场景需要不同类型的索引,所以Tablestore提供多元化的索引来满足不同类型场景下的数据查询需求。
- CDC技术:Tablestore的CDC技术名为Tunnel Service,支持全量和增量的实时数据订阅,并且能无缝对接Flink流计算引擎来实现表内数据的实时流计算。
- 拥抱开源计算生态:除了比较好的支持阿里云自研计算引擎如MaxCompute和Data Lake Analytics的计算对接,也能支持Flink和Spark这两个主流计算引擎的计算需求,无需数据搬迁。
- 流批计算一体:能支持Spark对表内全量数据进行批计算,也能通过CDC技术对接Flink来对表内新增数据进行流计算,真正实现批流计算结合。
| 特色功能
- 多元化索引
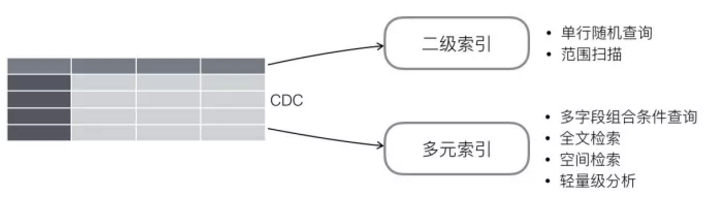
Tablestore提供多种索引类型可选择,包含全局二级索引和多元索引。全局二级索引类似于传统关系数据库的二级索引,能为满足最左匹配原则的条件查询做优化,提供低成本存储和高效的随机查询和范围扫描。多元索引能提供更丰富的查询功能,包含任意列的组合条件查询、全文搜索和空间查询,也能支持轻量级数据分析,提供基本的统计聚合函数,两种索引的对比和选型可参考这篇文章。
- 通道服务

通道服务是Tablestore的CDC技术,是支撑数据派生体系的核心功能,具体能力可参考这篇文章。能够被利用在异构存储间的数据同步、事件驱动编程、表增量数据实时订阅以及流计算场景。目前在云上Tablestore与Blink能无缝对接,也是唯一一个能直接作为Blink的stream source的结构化大数据存储。
大数据处理架构
大数据处理架构是数据系统架构的一部分,其架构发展演进了多年,有一些基本的核心架构设计思路产出,例如影响最深远的Lambda架构。Lambda架构比较基础,有一些缺陷,所以在其基础上又逐渐演进出了Kappa、Kappa+等新架构来部分解决Lambda架构中存在的一些问题,详情介绍可以看下这篇文章的介绍。Tablestore基于CDC技术来与计算引擎相结合,基于Lambda架构设计了一个全新的Lambda plus架构。
Lambda plus架构

Lambda架构的核心思想是将不可变的数据以追加的方式并行写到批和流处理系统内,随后将相同的计算逻辑分别在流和批系统中实现,并且在查询阶段合并流和批的计算视图并展示给用户。基于Tablestore CDC技术我们将Tablestore与Blink进行了完整对接,可作为Blink的stream source、dim和sink,推出了Lambda plus架构:
- Lambda plus架构中数据只需要写入Tablestore,Blink流计算框架通过通道服务API直读表内的实时更新数据,不需要用户双写队列或者自己实现数据同步。
- 存储上,Lambda plus直接使用Tablestore作为master dataset,Tablestore支持用户在线系统低延迟读写更新,同时也提供了索引功能进行高效数据查询和检索,数据利用率高。
- 计算上,Lambda plus利用Blink流批一体计算引擎,统一流批代码。
- 展示层,Tablestore提供了多元化索引,用户可自由组合多类索引来满足不同场景下查询的需求。
总结
本篇文章我们谈了数据系统架构下的核心组件以及关于存储组件的选型,介绍了派生数据体系这一设计理念。在派生数据体系下我们能更好的理清存储组件间的数据流关系,也基于此我们对结构化大数据存储这一组件提了几个关键需求。阿里云Tablestore正是基于这一理念设计,并推出了一些特色功能,希望能通过本篇文章对我们有一个更深刻的了解。
在未来,我们会继续秉承这一理念,为Tablestore内的结构化大数据派生更多的便于分析的能力。会与开源计算生态做更多整合,接入更多主流计算引擎。
原文链接
本文为云栖社区原创内容,未经允许不得转载。










_04)








