
阿里妹导读:Apache Flink 是公认的新一代开源大数据计算引擎,其流水线运行系统既可以执行批处理程序也可以执行流处理程序。目前,Flink 已成为 Apache 基金会和 GitHub 社区最为活跃的项目之一。在 Flink Forward Asia 2019 上,阿里巴巴资深技术专家,实时计算负责人王峰 (莫问)总结了 2019 年 Flink 在中国的发展和演进,阿里对 Flink 社区的贡献以及未来 Flink 的最新发展方向。
GitHub 地址:https://github.com/apache/flink
Flink:最活跃Apache 项目之一
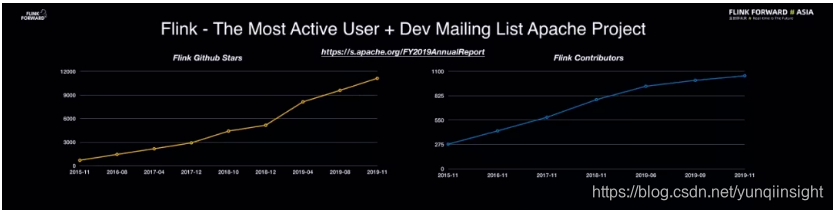
首先,简单总结一下 Flink 社区的发展情况。自 2014 年 Flink 贡献给开源社区之后,其发展非常迅速。目前,Flink 可以称之为 Apache 基金会中最为活跃的项目之一,在 GitHub 上其访问量在 Apache 项目中位居前三。从 Star 数量上看,仅仅是 2019 年一年的时间,Flink 在 GitHub 上的 Star 数量就翻了一倍,Contributor 数量也呈现出持续增长的态势。通过相关数据可以看出,越来越多的企业和开发者正在不断地加入 Flink 社区,并为 Flink 的发展贡献力量。其中,中国开发者也做出了巨大的贡献。
欢迎一起在GitHub上点个Star
Apache Flink 在中国的应用
随着 Flink 社区的快速发展,其技术也逐渐走向成熟。在 2019 年,国内已经有大量的本土互联网公司开始采用 Apache Flink 作为主流的实时计算解决方案。同时,在全球范围内,优步、网飞、微软和亚马逊等国际互联网公司也逐渐开始使用 Apache Flink。

Apache Flink 的未来
如今,Flink 的主要应用场景基本上还是数据分析,尤其是实时数据分析。Flink 本质上是一款流式数据处理引擎,覆盖的场景主要是实时数据分析、实时风控、实时 ETL 处理等。未来,社区希望 Flink 演化成为统一的数据引擎。
- 在离线数据处理方面,希望 Flink 能够在流数据处理的基础之上进一步实现批与流的统一,提供统一的数据处理和分析的解决方案。
- 另一方面,朝着在线数据分析处理的方向演进,即利用 Flink 的核心优势、Event-Driven Function 的能力以及 Flink 自带的状态管理等特性实现在线的函数计算。
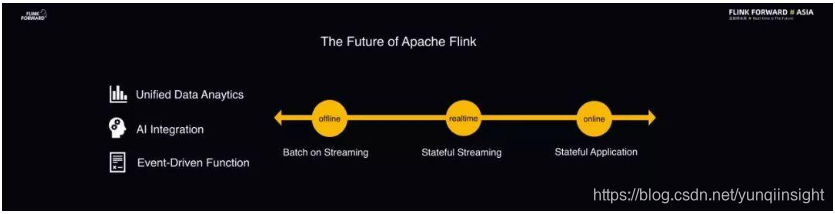
近年来,AI 场景发展得如火如荼并且计算的规模也越来越大。因此,Flink 社区也希望能够主动拥抱 AI 场景,在 Flink 机器学习方面支持 AI 场景,甚至和 AI 原生的深度学习引擎比如 Flink + TensorFlow、Flink + PyTorch 等实现协同,提供大数据+AI 的全链路解决方案。
统一的数据分析解决方案
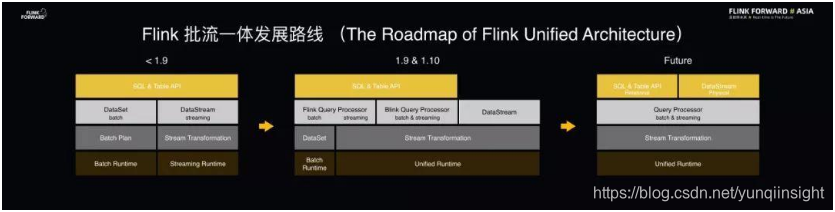
下图为 Apache Flink 批流一体的发展路线图。在 1.9 版本之前,Flink 的批和流还属于两条 Code Path,DataSet 和 DataStream 是两条独立的 API,具有两套不同的运行时环境,尚未实现批流一体的高度融合。所以在 2019 年发布的 Flink 1.9 版本和即将发布的 1.10 版本中,社区投入了大量精力去做 Flink 批流一体架构的整合。经过一年的努力,在 Flink 1.10 版本中已经实现了 Flink Task 的运行时环境、执行引擎层以及 SQL 和 Table 层面的批和流的高度统一。但是目前而言,Flink 在架构上还没有完全实现批流全部统一。未来,社区希望将 DataSet 和 DataStream 两套 API 做到批流高度融合。
统一Flink SQL
SQL 是在大数据处理中当之无愧的“王道”语言,同时也是最通用、最主流的语言。在 Flink 1.9 版本中发布了一部分统一的 SQL 功能,而未来在 1.10 版本中也会发布更多的新功能,比如采用了批流统一的 Query 处理器、支持完整的 DDL 功能。此外,Flink 还通过了 TPC-H 和 TPC-DS 的测试集验证,已达到生产级可用状态。Flink 1.10 版本还增强了对于 Python 的支持,目前 Flink SQL 能够非常方便地使用 Python UDF。除此之外,Flink 也积极地拥抱了 Hive 生态,使得 Flink SQL 能够兼容 Hive,这样用户能够以极低的成本尝试 Flink 的新技术。

统一 SQL 架构
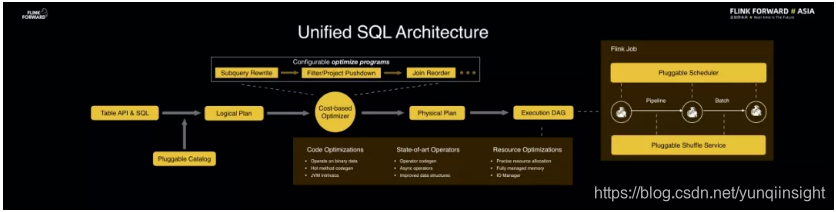
下面将从技术层面分享 Flink Unified SQL 的架构是如何实现批流的融合,进而实现统一处理的。对于用户的一条 SQL 而言,无论是批处理还是流处理,可能读取数据的模式是相同的,只不过输出结果可能是一次性输出或者持续性输出。在 Flink 中,可以对于用户输入的 SQL 采用统一的处理器进行解析、编译、优化等动作,最终产生一个 Flink Job 提交到 Flink 集群中运行。
在查询处理的过程中,新版本的 Flink 增加了非常多的优化技术,比如执行计划策略的优化、执行算子的优化、二进制数据结构的优化、代码自动生成的优化以及 JVM 的优化等,使得 SQL 编译出来的 Job 执行效率更高。在 Runtime 方面,也对 Flink 执行引擎做了重构,对核心底层功能进行抽象,抽象出了可插拔的调度策略以及 Shuffle Service,这样一来 Runtime 非常灵活,能够自由适配流和批的 Job 模式,甚至能够实现同一 Job 中流算子和批算子的自由转换。
Flink 与 Hive 生态系统集成
让大家能够真正将 Flink SQL 用起来,不仅仅需要考虑优秀的内核技术或者完善的功能,也需要考虑到用户的迁移成本。最理想的情况就是让大家既能够享受到 Flink SQL 的新技术成果,同时又不用去修改已有的系统或者数据以及元数据等。因此,Flink SQL 在 2019 年的重大成果之一就是更好地对接了 Hive 生态。

在 Flink 1.10 版本中,批流一体的 SQL 将直接无缝对接 Hive 的 metastore,可以与 Hive 直接共享元数据,Flink Connector 能够直接读取 Hive 的分区表数据,并且不会产生任何影响。同时,Flink 还兼容 Hive 的 UDF,可以直接运行在 Hive 集群环境中,不需要定义额外的集群。整体的效果使得用户仅花费极低的成本就能够在 Hive SQL 和 Flink SQL 之间非常自由地实现切换。Flink SQL 的另外一个先天优势是可以支持流数据,也就是同一套业务逻辑在处理 Hive 数据的同时,也可以对接到 Kafka 等消息队列来处理实时数据。
TPC-DS Benchmark 测试效果
下图为 Flink 在 TPC-DS 的 Benchmark 测试的性能表现。这里的数据集规模为 10TB,数据格式为 Hive ORC,对比版本中,Hive 使用的是 3.0 版本,Flink 使用的 1.10 Pre-Release 版本。
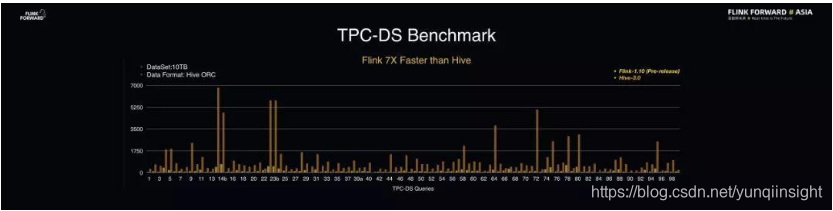
结果表明,Flink 不仅能够跑通 99 个 TPC-DS 的查询,同时其性能还能够达到 Hive 的 7 倍。通过 Benchmark 就可以看到 Flink SQL 无论是在功能完善性、性能还是其他各个方面都已经达到了业界的高标准,达到了生产级可用。
Flink 拥抱 AI
2019 年,整个技术圈里最火的当属 AI 了。而 Flink 除了做数据处理之外,还希望能够更好地拥抱 AI 场景。2019 年,Flink 在 AI 方面首先铺垫了机器学习基础设施,这部分所做的第一件事情就是实现了 Flink ML Lib 的基础 API,称之为 ML Pipeline。
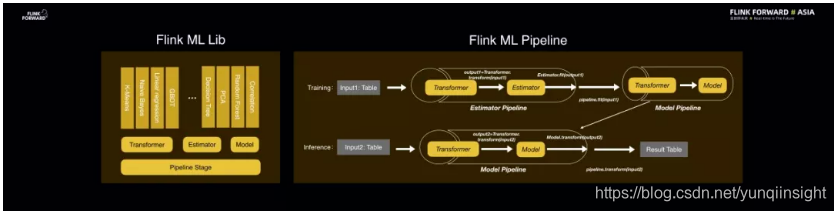
ML Pipeline 的核心是机器学习的流程,其中的核心概念包含 Transformer、Estimator、Model 等。Flink 机器学习算法的开发人员可以使用这套 API 去开发不同的 Transformer、Estimator、Model,去实现各种经典的机器学习算法,非常方便。基于 ML Pipeline 这套 API 还能够自由组合组件来构建机器学习的训练流程和预测流程。
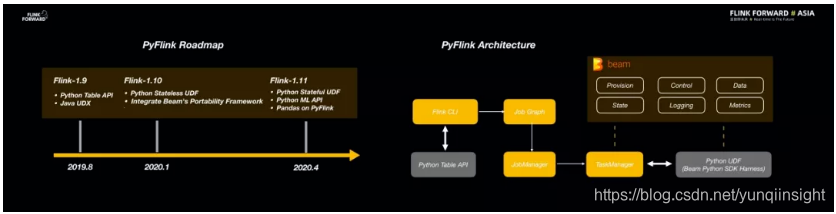
对于 AI 算法的开发人员而言,他们最喜欢的往往并不是 SQL 而是 Python。因此,Flink 对于 Python 的支持也尤为重要。在 2019 年,Flink 社区也投入了大量的资源来完善 Flink 的 Python 生态,诞生了 PyFlink 项目。并且在 Flink 1.9 版本中实现了 Python 对于 Table API 的支持。但这是不够的,在 Flink 1.10 版本中还重点支持了 Python UDF 特性。为了实现这一目标一般有两种技术选择,一种是从无到有地实现从 Java 到 Python 的通信,另一种是直接使用成熟的框架。很幸运的是 Beam 社区在 Python 支持上非常强大,因此 Flink 社区与 Beam 社区之间开展了良好的合作,Flink 使用了 Beam 的 Python 资源,比如 SDK、Framework 以及数据通信格式等。在未来,Flink 会进一步完善对于 Python API 和 UDF 的支持,在 ML Pipeline 上更多地支持 Python,同时也希望引入更多成熟的 Python 库。
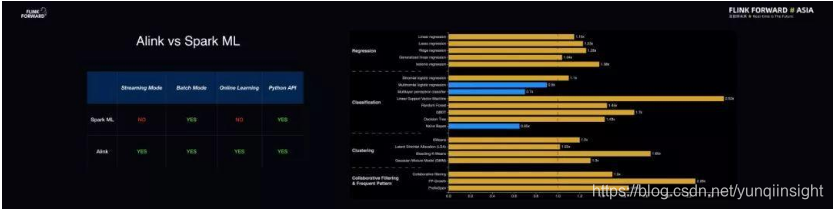
Alibaba Alink
众所周知,阿里巴巴在 2018 年重磅推出了 Blink,也就是阿里内部的 Flink 版本。而 Alink 则是阿里巴巴内部的基于 Flink 的机器学习算法库,由阿里云机器学习 PAI 团队开发。Alink 是一套分布式、批流一体的机器学习算法库,它既非常好地利用了 Flink 批流一体的计算能力以及在机器学习基础设施上的一些优势,还结合了阿里巴巴的业务场景。目前,Alink 的上百个机器学习算法也正在向 Flink 社区贡献,希望能够成为新一代的 Flink ML。为了尽快让大家享受到 Alink 的技术红利,阿里巴巴也决定同时开源 Alink 项目。
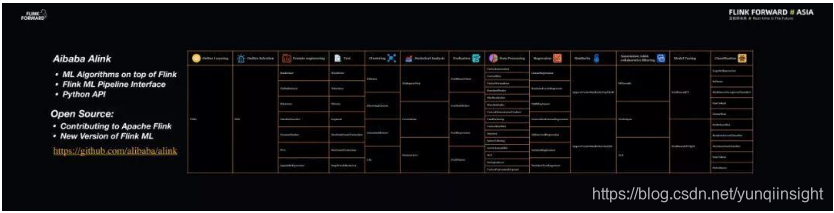
将 Alink 与主流的机器学习算法库进行对比,可以发现其最大的优势就是不仅能够支持批式训练的机器学习场景,也能够支持在线的机器学习场景。Alink 在离线的机器学习场景下与主流的 Spark ML 做了对比,在功能集合上所有算法基本一致,此外还做了性能对比,Alink 和 Spark ML 在离线训练场景下的性能基本在一个水平线上,旗鼓相当。但是 Alink 的优势在于一些算法能够以流式方法进行计算,更好地实现在线机器学习。
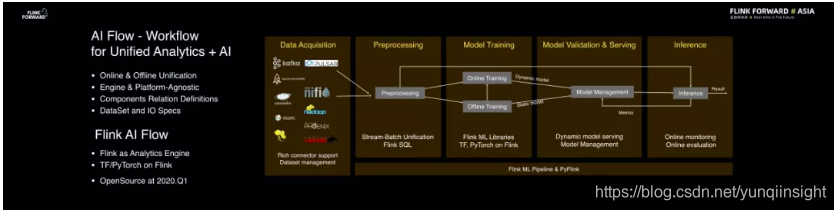
AI Flow
另外,AI 部分的新项目——AI Flow 也值得关注。AI Flow 是大数据及 AI 的处理流程平台,在 AI Flow 中定义不同数据之间的关系以及元数据格式等就能够非常方便地搭建一套大数据及 AI 处理的流程。整个 Workflow 并不绑定某一引擎或者平台,但是用户可以借助 Flink 批流一体的能力去搭建自己的大数据及 AI 解决方案。目前,AI Flow 项目正在准备中,预计将于明年的第一季度以与 Alink 相同的模式进行开源。
云原生 (Cloud Native)
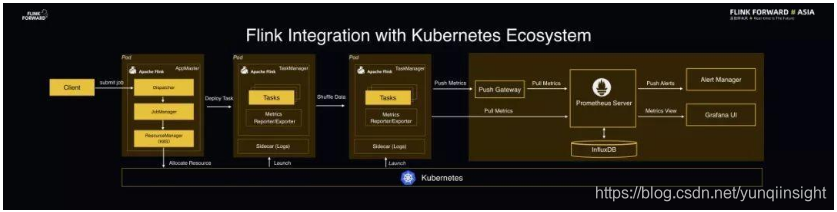
Flink 与 Kubernetes 生态系统集成
Flink 1.10 版本将会发布 Flink 与 Kubernetes 生态系统的集成功能,使得 Flink 能够原生地运行在 Kubernetes 管理平台之上。之所以要将 Flink 放在 Kubernetes 之上,是因为这样做有以下几点优势:
- 第一,Kubernetes 能够在多租户场景下为 Flink 带来更好的体验。
- 第二,目前各大公司都在逐步采用 Kubernetes 做 IT 设施的管理,如果 Flink 能够运行在 Kubernetes 之上,对于用户而言就能够实现更大规模的资源共享和统一管理,降低成本的同时能够提高效率。
- 第三,Kubernetes 云原生生态发展非常迅速,如果 Flink 能够与 Kubernetes 生态实现很好的整合,就能够让 Flink 享受到 Kubernetes 生态的技术红利,使得 Flink 能够在生产环境下提供运维保障。
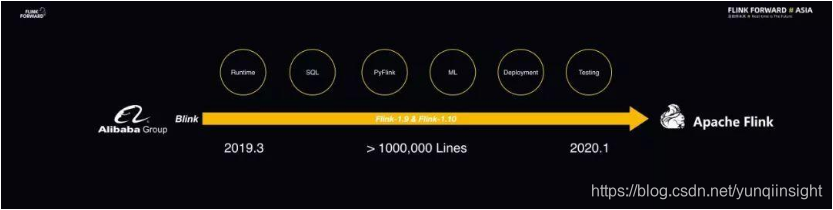
阿里巴巴 Blink 贡献给 Apache Flink 社区
2019 年 3 月,Blink 正式开源。与此同时,阿里巴巴也希望将 Blink 的能力贡献回 Flink,共建一套 Flink 社区。而 Flink 通过 1.9 和即将发布的 1.10 两个大版本的迭代基本完成了这项工作。在这 10 个月的工作中,阿里巴巴向 Flink 社区贡献了超过一百万行代码,将 Blink 中积累的大量架构优化工作都推回给了 Flink 社区,不仅包括 Runtime、SQL、PyFlink,还包括新的 ML 等。
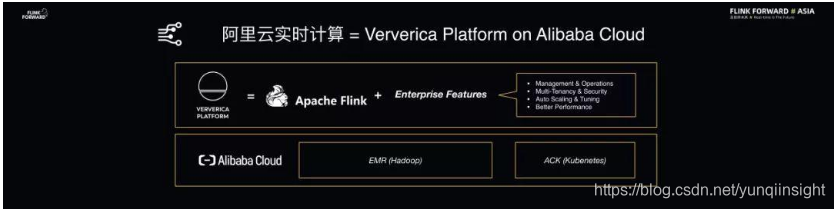
阿里云实时计算-Ververica Platform on Alibaba Cloud
在将 Blink 逐步贡献到 Flink 之后,阿里巴巴决定在 2020 年将两套内核逐渐合并为一套内核,将 Blink 内核合并到 Flink 内核中,全面支持开源社区的发展。未来,阿里云的产品和内部服务都会基于开源的 Flink 内核来实现。此外,阿里巴巴的技术团队和 Flink 创始团队 一起合作,联合打造了 Flink 企业版:Ververica Platform。这套全新的企业版将会支持阿里巴巴内部业务和云上业务。阿里巴巴也将投入更多力量到开源 Flink 的发展和社区的建设当中,也希望和广大业界同仁一起助力 Flink 中文社区的发展。
原文链接
本文为阿里云原创内容,未经允许不得转载。
-之wx.request封装)




-之登录)





-之封装组件)



-之自定义导航栏)


-之获取手机号、用户信息)
)