
阿里妹导读:信息流作为手淘的一大流量入口,对手淘的浏览效率转化和流量分发起到至关重要的作用。在探索如何给用户推荐其喜欢的商品这条路上,我们首次将端计算大规模应用在手淘客户端,通过端侧丰富的用户特征数据和触发点,利用机器学习和深度神经网络,在端侧持续感知用户意图,抓住用户转瞬即逝的兴趣点,并给予用户及时的结果反馈。通过大半年的不断改进,手淘信息流端上智能推荐在9月中旬全量,并在双十一当天对信息流的点击量和GMV都带来了大幅的提升。下文将给大家分享我们在探索过程中发现的问题,对其的思考和解决方案。
背景
现状与解决方案
手淘上以列表推荐形式为主的业务场景有不少,以手淘信息流为例,进入猜你喜欢场景的用户,兴趣点常常是不明确的,用户浏览时往往没有明确的商品需求,而是在逛的过程中逐渐去发现想买的商品。而推荐系统在用户逛到买的过程中,往往会下发并呈现不同类型商品让用户从中挑选,推荐系统这个过程中会去捕捉用户的兴趣变化,从而推荐出更符合用户兴趣的商品。然而推荐系统能不能做到用户兴趣变化时立刻给出响应呢?推荐系统以往的做法都是通过客户端请求后触发云端商品排序,然后将排序好的商品下发给用户,端侧再依次做商品呈现。这样存在下面两个问题:
- 云端推荐系统对终端用户推荐内容调整机会少,往往都在分页请求时,而简单请求并不能灵活做内容的增删改。
- 云端推荐系统不能及时获取到用户当前时刻的偏好意图,快速给出反馈。
我们总结发现,目前推荐系统的弊端是,用户偏好的变化与推荐系统对用户感知和对内容的调整时机并不能匹配,会出现推荐的内容并非用户当前时刻想要的,用户浏览和点击意愿都会下降。那么怎样能够让推荐系统及时感知到用户偏好并及时的给出用户想要的内容呢?
我们先透过现象看本质,以上问题的本质在于推荐系统和用户交互过程中的实时性差,以及决策系统可调整性差。实时性差体现在两个方面,推荐系统对终端用户的感知实时性差以及对用户的干预实时性差。而决策系统可调整性差,体现在决策系统对用户内容的调整时机依赖端侧的固定规则请求,可调整的内容局限于当前次下发的内容。如果我们能够解决实时性问题,推荐系统能够实时感知用户偏好,并在任何时机实时调整用户所见内容,推荐的内容可以更符合用户当前的偏好;如果我们能够解决决策系统可调整性差问题,推荐系统可以决定合适的时机去调整用户内容,可以决定用更优的方式去调整具体的内容。那么解决的方案是什么呢?

我们在手淘信息流中引入机器学习和深度神经网络模型,结合端侧用户特征,在端侧持续感知用户意图,实时决策并实时反馈结果给用户,这样解决了实时性差以及决策系统可调整性差的问题。我们把这个解决方案称之为端智能。
端智能带来的改变
端智能的本质是“端”+“智能”。首先“智能”不是一个新鲜的东西,“智能”不管是在云端或终端,解决的问题是通过机器学习数据的内在机制并推理出最终结论;“端”解决的问题是将”智能“工程化并落地到具体的应用场景,“端”有机的整合端侧数据以及云端下发内容,决定何时触发“智能”做决策,最终决定怎样给用户以反馈。
端智能带来的改变,则是让端上具备了“独立思考”的能力,这让部分决策和计算不再依赖于云端,端侧可以更实时、更有策略的给出结果。说到实时性,5G时代的到来,其低时延特性极大的降低了端和云的交互时间,但这并不影响我们利用端智能实现更低成本的决策和快速响应,反而对于端智能来说,好处是能和云端结合的更紧密。另外由于在端侧能够秒级感知用户意图做出决策,产品和用户贴的更近了,这催生了更多实时性的玩法,产品将不再局限于要到固定的时机如分页请求让云端去给到新的内容反馈,而是思考,当用户表达出来特定的用户意图时,产品应该如何提供与意图相匹配的内容。
端智能与传统差异比较
尽管端智能带来了很多好的改变,但这里依然需要强调一点,并不是说有了端智能就不再需要云智能,怎样做到云&端协同智能才是未来。
端智能的优势在于:
- 端侧有着丰富的用户特征和触点,有着更多的机会和条件去做决策
- 实时性高,在端侧处理可节省数据的网络传输时间,节省的时间可用于更快的反馈结果
- 节省资源,在端侧处理,利用端侧算力和存储空间,可以节省大量的云端计算和存储资源
- 隐私性好,从产生数据到消费数据都在端侧完成,避免传输到云端引起隐私泄露风险
端智能的不足在于:
- 设备资源有限,端侧的算力、电力、存储是有限的,不能做大规模高强度的持续计算。
- 算法规模小,端侧算力小,而且单用户的数据,在算法上并不能做到最优
- 用户数据有限,端侧数据并不适合长期大量存储,端侧可用数据有限
云智能的优势在于:
- 大数据,云端可以通过长期大量的来自不同人群的数据进行计算
- 设备资源充足,云计算的算力、电力、存储都可以根据需求进行配置
- 算法规模大,可以通过足够的大规模模型,计算出最优解
云智能不足在于:
- 响应速度慢,受传输带宽影响,不能稳定提供较高的响应速度
- 用户感知弱,端侧产生的数据同步到云端,数据量限制和传输时间的约束都会削弱云端对用户的感知
从以上云智能和端智能的对比可以看出,端智能适合于依赖端侧用户触点的小规模低时延的计算,而云智能更适合中长期数据大规模计算。同时,端智能往往需要云端提供的长期特征及内容,而云智能也往往需要端上的特征和丰富的触发点,两者优势互补,才能发挥出更好的效果。
端智能基础设施建设
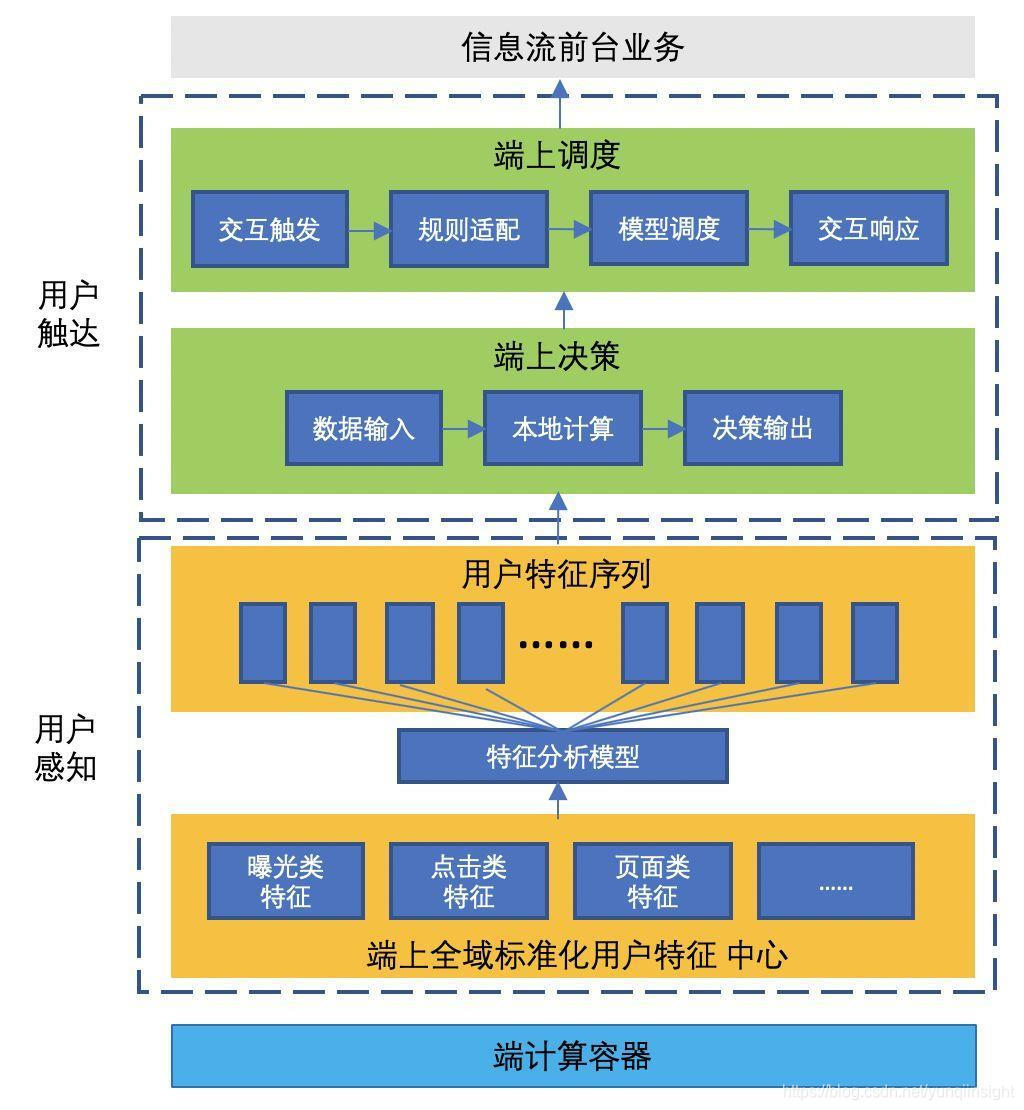
高楼起于平地,打造端智能这幢摩天大楼需要很多基础设施,剥除各种各样边角料和锦上添花的东西后,我们认为构成支撑起端智能体系的骨架组成部分主要有数据、端计算、端计算引擎、端智能决策框架、算法研发平台。其中,端侧数据 、端计算、端计算引擎这三块的作用是实时感知用户,计算出贴合用户的结果;端智能决策框架是触达用户的通道,通过端上实时智能决策衔接用户意图和端计算,最后通过一定的干预手段展现到用户眼前;算法研发平台是开发过程主要接触的平台,能有效提升研发效率。通过一个简单的示意图也许能更好的理解这五大块:

数据-BehaviX
无论计算是发生在云端还是终端,数据始终是执行所有计算的基本要素之一,端计算的本质也是计算,数据当然也是他的要素之一。在淘宝或者其他阿里系App里我们已经有很多数据沉淀,这些数据包括但不限于商品、商品特征、用户特征等。这些数据同样可以作为端计算的输入来源,但如果只有这些,端计算和云计算相比在数据上似乎没有什么明显优势了,所以我们需要回过头看下端计算作为端智能的重要部分,他的在数据上的核心优势是什么?端计算运行在端上,天然能获取端上的数据,而且是实时获取。我们希望这部分数据是和已有数据是互补的、对端计算是有价值的,端计算的目的之一是千人千面,端上丰富的用户特征,能体现当前用户的实时意图。所以我们在构建了端侧用户特征数据中心BehaviX。
BehaviX作为整个端智能的数据基础,提供给算法特征数据作为模型数据输入源,支持了特征实时同步云端,让云端能够秒级感知到端侧用户特征,提供了算法基于端侧用户特征数据做意图分析的能力。
端智能决策框架-BehaviR
从用户角度来看,用户感知到的不是一堆数据和计算而是能够被感知到的结果,因此,即使计算出来的结果无比贴合用户意图,如果无法及时触达用户也是无用功。触达用户方式多种多样,我们需要基于实际场景放开手大胆探索,合理的产品设计会让用户觉得是在和一个“智能”的App交流,反之,不合理的产品设计会打扰用户、对用户造成困扰。从技术角度来说,我们要设计和做的其实是一条触达通道,通过感知用户触点,我们能根据运营规则配置或者本地模型决策出此时要给用户什么类型的反馈,然后通过下面要讲述的端计算能力计算出贴合用户的结果并展示给用户,以此将端计算和用户连接在一起。
端智能决策框架能简化业务方接入端智能流程,帮助业务方真正做到实时感知、及时干预。
端计算-EdgeRec
端计算简单理解起来可以认为是跑在端上的一段逻辑,这段逻辑可以是一个预置的Native任务,也可以是一个脚本,当然,在最终我们希望他是一个算法模型。算法模型是目前做到千人千面的有效手段之一,其他优势不再累述了,详见下面的友情链接。
回到这里的主角EdgeRec-边缘计算算法,他在在端上实时建模了用户的异构特征序列,为端上决策提供通用的用户状态表达。通过多任务学习,共享通用的用户状态表达,在端上建模多种决策模型。另外,边缘计算算法SDK也提供端上深度学习算法开发的通用解决方案,如:端上深度学习模型库、端上模型拆分部署、端上模型版本控制、端上样本生成等。
端计算引擎-Walle&MNN
端计算引擎是端智能体系中重要的一环,是算法模型的基础环境。无论是iOS还是Android目前都提供了一套环境,但两端差异性比较大,限制也比较多。构建一套端计算引擎的成本是非常高的,但长远来看统一两端引擎、抹平差异是有非常有必要的。Walle和MNN作为当前我们端计算引擎很好地做到了这一点。
Walle是端上整体的Runtime,他为算法的Python脚本、深度模型以及Jarvis的EFC、ESC等特征样本计算库提供运行环境,另外也为BehaviX管理的基础数据提供存储服务。
MNN 是一个轻量级的深度学习端侧推理引擎,核心解决深度神经网络模型在端侧推理运行问题,涵盖深度神经网络模型的优化、转换和推理,其前身为 AliNN。
算法研发平台:Jarvis
算法模型的研发并不是简单地在本地IDE写一份代码那么简单,我们通常需要理论调研、算法开发、模型训练、参数调优、线上验证等等步骤,本地环境是远远不够的,所以算法研发平台的存在能帮助算法同学更高效、更专注地进行研发工作。另外,端智能要出结果,一定是多团队通力合作的结果,多团队合作仅靠口头沟通是远远不够的,我们需要一套合理的流程去简化和规范各项工作,因此,在算法研发平台的基础之上我们仍旧需要一个一站式平台。
Jarvis提供一站式的开发、调试、验证、AB测试、发布、监控平台,与算法同学共建一起打造了端上的特征计算、样本计算等基础库。
整体流程图
我们构建了端智能的五个基础设施,通过端上调度系统,将整个端智能技术体系串联起来,总体来说分为用户触达和用户感知部分。用户触达部分包括端上调度和端上决策,端上调度提供和业务的直接对接,端上决策由端上调度系统在合适的时候拉起本地算法计算;用户感知部分则对用户特征进行标准化端上用户特征,提供端侧计算的数据输入。
数据效果
从年初信息流端智能立项以来,我们经过最开始的小流量实验,效果逐渐优化,大半年的不断探索试错,信息流端智能于9月中旬在首页猜你喜欢场景全量。双十一当天也取得了不错的业务效果,对商品推荐的准确度提升,信息流GMV和点击量都大幅提升。其实这只是信息流在端智能的开始,相信后面更深入的优化探索,我们将会取到更好的效果。
总结
从我们以往的经验来看,端侧做的更多的是将云端内容以具体的形式呈现给用户。当端侧也具备了感知用户意图并智能做出决策时,端侧的能力就不再局限于“呈现”,端侧也可以”思考“。业务可以利用端侧”思考“能力,将以往在云端解决起来比较困难的问题放到端上去解决,如云端决策实时性问题、大数据量上报云端分析的资源消耗问题;可以结合端侧本身的特性,如传感器、相机、UI呈现等,去思考如何去整合用户特征、数据、端侧算法去大胆尝试找到新的突破口。
原文链接
本文为阿里云原创内容,未经允许不得转载。




 您的 k8s 集群资源)













