导读:Kubernetes 作为当下最流行的容器自动化运维平台,以声明式实现了灵活的容器编排,本文以 v1.16 版本为基础详细介绍了 K8s 的基本调度框架、流程,以及主要的过滤器、Score 算法实现等,并介绍了两种方式用于实现自定义调度能力。
调度流程
调度流程概览
Kubernetes 作为当下最主流的容器自动化运维平台,作为 K8s 的容器编排的核心组件 kube-scheduler 将是我今天介绍的主角,如下介绍的版本都是以 release-1.16 为基础,下图是 kube-scheduler 的主要几大组件:
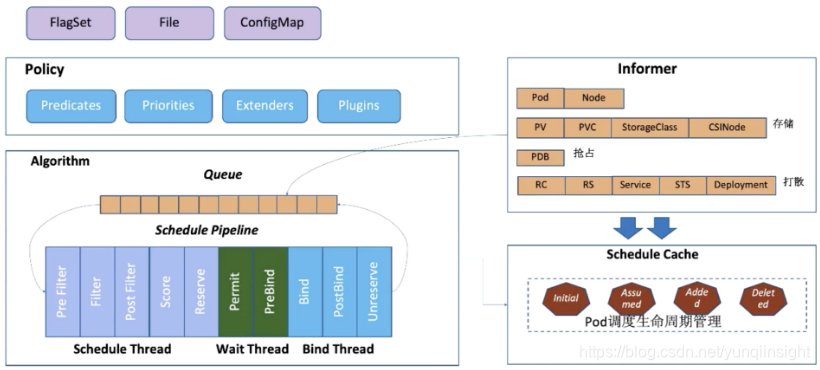
Policy
Scheduler 的调度策略启动配置目前支持三种方式,配置文件 / 命令行参数 / ConfigMap。调度策略可以配置指定调度主流程中要用哪些过滤器 (Predicates)、打分器 (Priorities) 、外部扩展的调度器 (Extenders),以及最新支持的 SchedulerFramwork 的自定义扩展点 (Plugins)。
Informer
Scheduler 在启动的时候通过 K8s 的 informer 机制以 List+Watch 从 kube-apiserver 获取调度需要的数据例如:Pods、Nodes、Persistant Volume(PV), Persistant Volume Claim(PVC) 等等,并将这些数据做一定的预处理作为调度器的的 Cache。
调度流水线
通过 Informer 将需要调度的 Pod 插入 Queue 中,Pipeline 会循环从 Queue Pop 等待调度的 Pod 放入 Pipeline 执行。
调度流水线 (Schedule Pipeline) 主要有三个阶段:Scheduler Thread,Wait Thread,Bind Thread。
- Scheduler Thread 阶段: 从如上的架构图可以看到 Schduler Thread 会经历 Pre Filter -> Filter -> Post Filter-> Score -> Reserve,可以简单理解为 Filter -> Score -> Reserve。
Filter 阶段用于选择符合 Pod Spec 描述的 Nodes;Score 阶段用于从 Filter 过后的 Nodes 进行打分和排序;Reserve 阶段将 Pod 跟排序后的最优 Node 的 NodeCache 中,表示这个 Pod 已经分配到这个 Node 上, 让下一个等待调度的 Pod 对这个 Node 进行 Filter 和 Score 的时候能看到刚才分配的 Pod。
- Wait Thread 阶段: 这个阶段可以用来等待 Pod 关联的资源的 Ready 等待,例如等待 PVC 的 PV 创建成功,或者 Gang 调度中等待关联的 Pod 调度成功等等;
- Bind Thread 阶段: 用于将 Pod 和 Node 的关联持久化 Kube APIServer。
整个调度流水线只有在 Scheduler Thread 阶段是串行的一个 Pod 一个 Pod 的进行调度,在 Wait 和 Bind 阶段 Pod 都是异步并行执行。
调度详细流程
解说完 kube-scheduler 的几大部件的作用和关联关系之后,接下来深入理解下 Scheduler Pipeline 的具体工作原理,如下是 kube-scheduler 的详细流程图,先解说调度队列:
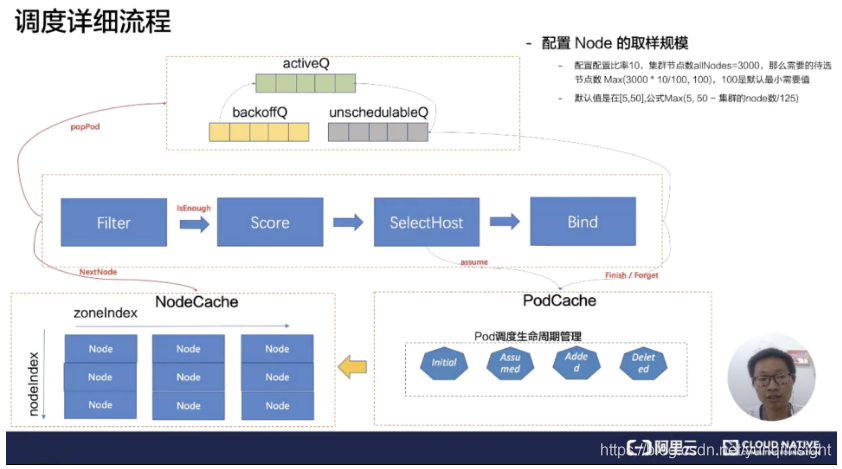
SchedulingQueue 有三个子队列 activeQ、backoffQ、unschedulableQ。
Scheduler 启动的时候所有等待被调度的 Pod 都会进入 activieQ,activeQ 会按照 Pod 的 priority 进行排序,Scheduler Pipepline 会从 activeQ 获取一个 Pod 进行 Pipeline 执行调度流程,当调度失败之后会直接根据情况选择进入 unschedulableQ 或者 backoffQ,如果在当前 Pod 调度期间 Node Cache、Pod Cache 等 Scheduler Cache 有变化就进入 backoffQ,否则进入 unschedulableQ。
unschedulableQ 会定期较长时间(例如 60 秒)刷入 activeQ 或者 backoffQ,或者在 Scheduler Cache 发生变化的时候触发关联的 Pod 刷入 activeQ 或者 backoffQ;backoffQ 会以 backoff 机制相比 unschedulableQ 比较快地让待调度的 Pod 进入 activeQ 进行重新调度。
接着详细介绍 Scheduler Thread 阶段,在 Scheduler Pipeline 拿到一个等待调度的 Pod,会从 NodeCache 里面拿到相关的 Node 执行 Filter 逻辑匹配,这从 NodeCache 遍历 Node 的过程有一个空间算法上的优化,简单可以概括为在避免过滤所有节点的同时考虑了调度的容灾取样调度。
具体的优化算法逻辑(有兴趣的同学可以看 node_tree.go 的 Next 方法):在 NodeCache 中,Node 是按照 zone 进行分堆。在 filter 阶段的时候,为会 NodeCache 维护一个 zondeIndex,每 Pop 一个 Node 进行过滤,zoneIndex 往后挪一个位置,然后从该 zone 的 node 列表中取一个 node 出来。
可以看到上图纵轴有一个 nodeIndex,每次也会自增。如果当前 zone 的节点无数据,那就会从下一个 zone 中拿数据。大概的流程就是 zoneIndex 从左向右,nodeIndex 从上到下,保证拿到的 Node 节点是按照 zone 打散,从而实现避免过滤所有节点的同时考虑了节点的 az 均衡部署。(最新 release-v.1.17 的版本已经取消这种算法,为什么取消应该是没有考虑 Pod 的 prefer 和 node 的 prefer,没有实现 Pod 的 Spec 要求)
取样调度里面的取样规模这里简单介绍一下,默认的取样比率公式 = Max (5, 50 - 集群的 node 数 / 125),取样规模 = Max (100, 集群 Node 数*取样比率)。
这里举个例子:节点规模为 3000 个节点,那么取样比例 = Max (5, 50 - 3000/125) = 26%,那么取样规模 = Max (100, 3000* 0.26) = 780,在调度流水线里面,Filter 只要匹配到 780 个候选节点,就可以停止 Filter 流程,走到 Score 阶段。
Score 阶段依据 Policy 配置的算分插件,进行排序,分数最高的节点作为 SelectHost。接着将这个 Pod 分配到这个 Node 上,这个过程叫做 Reserver 阶段可以称为账本预占。预占的过程修改 Pod 在 PodCache 的状态为 Assumed 的状态(处于内存态)。
调度过程涉及到 Pod 状态机的生命周期,这里简单介绍下 Pod 的几个主要状态: Initial(虚拟状态)->Assumed(Reserver)->Added->Deleted(虚拟状态); 当通过 Informer watch 到 Pod 数据已经确定分配到这个节点的时候,才会把 Pod 的状态变成 Added。选中完节点在 Bind 的时候,有可能会 Bind 失败,在 Bind 失败的时候会做回退,就是把预占用的账本做 Assumed 的数据退回 Initial,也就是把 Assumed 状态擦除,从 Node 里面把 Pod 账本清除。
如果 Bind 失败,会把 Pod 重新丢回到 unschedulableQ 队列里面。在调度队列中,什么情况下 Pod 会到 backoffQ 中呢?这是一个很细节的点。如果在这么一个调度周期里面,Cache 发生了变化,会把 Pod 放到 backoffQ 里面。在 backoffQ 里面等待的时间会比在 unschedulableQ 里面时间更短,backoffQ 里有一个降级策略,是 2 的指数次幂降级。假设重试第一次为 1s,那第二次就是 2s,第三次就是 4s,第四次就是 8s,最大到 10s。
调度算法实现
Predicates (过滤器)
Filter 根据功能用途可以把它们分为四类:
- 存储匹配相关
- Pode 和 Node 匹配相关
- Pod 和 Pod 匹配相关
- Pod 打散相关
存储相关
存储相关的几个过滤器的功能:
- NoVolumeZoneConflict,pvc 关联的 pv 的 label 上设置 zoneaz 限制待匹配的节点要跟 pv;
- MaxCSIVolumeCountPred,是用来校验 pvc 上指定的 Provision 在 CSI plugin 上的单机最大 pv 数限制;
- CheckVolumeBindingPred,在 pvc 和 pv 的 binding 过程中对其进行逻辑校验,里头的逻辑写的比较复杂,主要都是如何复用 pv;
- NoDiskConfict,SCSI 存储不会被重复的 volume。
Pod 和 Node 匹配相关
- CheckNodeCondition:校验节点是否准备好被调度,校验node.condition的condition type :Ready为true和NetworkUnavailable为false以及Node.Spec.Unschedulable为false;
- CheckNodeUnschedulable:在 node 节点上有一个 NodeUnschedulable 的标记,我们可以通过 kube-controller 对这个节点直接标记为不可调度,那这个节点就不会被调度了。在 1.16 的版本里,这个 Unschedulable 已经变成了一个 Taints。也就是说需要校验一下 Pod 上打上的 Tolerates 是不是可以容忍这个 Taints;
- PodToleratesNodeTaints:校验 Node 的 Taints 是否被 Pod Tolerates 包含;
- PodFitsHostPorts:校验 Pod 上的 Container 声明的 Ports 是否正在被 Node 上已经分配的 Pod 使用;
- MatchNodeSelector: 校验 Pod.Spec.Affinity.NodeAffinity 和 Pod.Spec.NodeSelector 是否与 Node 的 Labels 匹配。
Pod 和 Pod 匹配相关
MatchinterPodAffinity:主要是 PodAffinity 和 PodAntiAffinity 的校验逻辑,这里面最大的复杂度是在于 Affinity 里面的 PodAffinityTerm 描述支持的 TopologyKey(可以表示在 node/zone/az 等拓扑结构上),这个其实是一个性能杀手。
Pod 打散相关
- EvenPodsSpread
- CheckServiceAffinity
EvenPodsSpread
这是一个新的功能特性,首先来看一下 EvenPodsSpread 中 Spec 描述:
-- 描述符合条件的一组 Pod 在指定 TopologyKey 上的打散要求。
下面我们来看一下怎么描述一组 Pod,如下图所示:
spec:topologySpreadConstraints:- maxSkew: 1whenUnsatisfiable: DoNotScheduletopologyKey: k8s.io/hostnameselector:matchLabels:app: foomatchExpressions:- key: appoperator: Invalues: ['foo', 'foo2']topologySpreadConstraints: 用于描述 Pod 要在什么拓扑结构上进行均衡打散,多个 topologySpreadConstraint 之间是 and 关系;
selector:用于描述需要满足的拓扑打散的一组 Pod 的列表
topologyKey: 作用在什么拓扑结构上;
maxSkew: 最大允许的不均衡数量;
whenUnsatisfiable: 当不满足 topologySpreadConstraint 的时候的策略,DoNotSchedule:表示作用于 filter 阶段,ScheduleAnyway:作用于 score 阶段。
下面举例描述下:

selector 选择的是所有 lable 符合 app=foo 的 pod,必须在 zone 级别是打散的,允许最大不均衡数为 1。
集群中有三个 zone,上图中 label 的值 app=foo 的 Pod 在 zone1 和 zone2 中都分配了一个 pod。
计算不均衡数量公式为:ActualSkew = count[topo] - min(count[topo])
首先,依据 selector 获取到符合条件的 Pod 列表
其次,会按照 topologyKey 去分组得到 count[topo]
如上图所示:
假设 maxSkew 为 1,如果分配到 zone1/zone2,skew 的值为2,大于前面设置的 maxSkew。这是不匹配的,所以只能分配到 zone3。如果分配到 zone3 的话,min(count[topo]) 为1,count[topo]为 1,那 skew 就等于 0,因此只能分配到 zone2。
假设 maxSkew 为 2,分配到 z1(z2),skew 的值为 2/1/0(1/2/0),最大值为 2,满足 <=maxSkew。那 z1/z2/z3 都是允许被选择的。
通过 EvenPodsSpread 可以实现一组 Pod 在某个 TopologyKey 上的均衡打散需求,如果必须要求每个 topo 上都均衡可以设 maxSkew 为1,当然这个描述缺乏了一些控制,例如必须分配在多少个 topologyValue 上的限制。
Priorities
接下来看一下打分算法,打分算法主要解决的问题就是集群的碎片、容灾、水位、亲和、反亲和等。
按照类别可以分为四大类:
- Node 水位
- Pod 打散 (topp,service,controller)
- Node 亲和&反亲和
- Pod 亲和&反亲和
资源水位
接下来介绍打分器相关的第一个资源水位。

节点打分算法跟资源水位相关的主要有四个,如上图所示。

- 资源水位公式的概念
Request:Node 已经分配的资源;Allocatable:Node 的可调度的资源
- 优先打散
把 Pod 分到资源空闲率最高的节点上,而非空闲资源最大的节点,公式:资源空闲率=(Allocatable - Request) / Allocatable,当这个值越大,表示分数越高,优先分配到高分数的节点。其中(Allocatable - Request)表示为Pod分配到这个节点之后空闲的资源数。
- 优先堆叠
把 Pod 分配到资源使用率最高的节点上,公式:资源使用率 = Request / Allocatable ,资源使用率越高,表示得分越高,会优先分配到高分数的节点。
- 碎片率
是指 Node 上的多种资源之间的资源使用率的差值,目前支持 CPU/Mem/Disk 三类资源, 假如仅考虑 CPU/Mem,那么碎片率的公式 = Abs[CPU(Request / Allocatable) - Mem(Request / Allocatable)] 。举一个例子,当 CPU 的分配率是 99%,内存的分配率是 50%,那么碎片率 = 99% - 50% = 50%,那么这个例子中剩余 1% CPU, 50% Mem,很难有这类规格的容器能用完 Mem。得分 = 1 - 碎片率,碎片率越高得分低。
- 指定比率
可以在 Scheduler 启动的时候,为每一个资源使用率设置得分,从而实现控制集群上 node 资源分配分布曲线。
Pod 打散

Pod 打散为了解决的问题为:支持符合条件的一组 Pod 在不同 topology 上部署的 spread 需求。
- SelectorSpreadPriority
用于实现 Pod 所属的 Controller 下所有的 Pod 在 Node 上打散的要求。实现方式是这样的:它会依据待分配的 Pod 所属的 controller,计算该 controller 下的所有 Pod,假设总数为 T,对这些 Pod 按照所在的 Node 分组统计;假设为 N (表示为某个 Node 上的统计值),那么对 Node上的分数统计为 (T-N)/T 的分数,值越大表示这个节点的 controller 部署的越少,分数越高,从而达到 workload 的 pod 打散需求。
- ServiceSpreadingPriority
官方注释上说大概率会用来替换 SelectorSpreadPriority,为什么呢?我个人理解:Service 代表一组服务,我们只要能做到服务的打散分配就足够了。
- EvenPodsSpreadPriority
用来指定一组符合条件的 Pod 在某个拓扑结构上的打散需求,这样是比较灵活、比较定制化的一种方式,使用起来也是比较复杂的一种方式。
因为这个使用方式可能会一直变化,我们假设这个拓扑结构是这样的:Spec 是要求在 node 上进行分布的,我们就可以按照上图中的计算公式,计算一下在这个 node 上满足 Spec 指定 labelSelector 条件的 pod 数量,然后计算一下最大的差值,接着计算一下 Node 分配的权重,如果说这个值越大,表示这个值越优先。
Node 亲和&反亲和

- NodeAffinityPriority,这个是为了满足 Pod 和 Node 的亲和 & 反亲和;
- ServiceAntiAffinity,是为了支持 Service 下的 Pod 的分布要按照 Node 的某个 label 的值进行均衡。比如:集群的节点有云上也有云下两组节点,我们要求服务在云上云下均衡去分布,假设 Node 上有某个 label,那我们就可以用这个 ServiceAntiAffinity 进行打散分布;
- NodeLabelPrioritizer,主要是为了实现对某些特定 label 的 Node 优先分配,算法很简单,启动时候依据调度策略 (SchedulerPolicy)配置的 label 值,判断 Node 上是否满足这个label条件,如果满足条件的节点优先分配;
- ImageLocalityPriority,节点亲和主要考虑的是镜像下载的速度。如果节点里面存在镜像的话,优先把 Pod 调度到这个节点上,这里还会去考虑镜像的大小,比如这个 Pod 有好几个镜像,镜像越大下载速度越慢,它会按照节点上已经存在的镜像大小优先级亲和。
Pod 亲和&反亲和
InterPodAffinityPriority
先介绍一下使用场景:
- 第一个例子,比如说应用 A 提供数据,应用 B 提供服务,A 和 B 部署在一起可以走本地网络,优化网络传输;
- 第二个例子,如果应用 A 和应用 B 之间都是 CPU 密集型应用,而且证明它们之间是会互相干扰的,那么可以通过这个规则设置尽量让它们不在一个节点上。
NodePreferAvoidPodsPriority
用于实现某些 controller 尽量不分配到某些节点上的能力;通过在 node 上加 annotation 声明哪些 controller 不要分配到 Node 上,如果不满足就优先。
如何配置调度器
配置调度器介绍

怎么启动一个调度器,这里有两种情况:
- 第一种我们可以通过默认配置启动调度器,什么参数都不指定;
- 第二种我们可以通过指定配置的调度文件。
如果我们通过默认的方式启动的话,想知道默认配置启动的参数是哪些?可以用 --write-config-to 可以把默认配置写到一个指定文件里面。
下面来看一下默认配置文件,如下图所示:
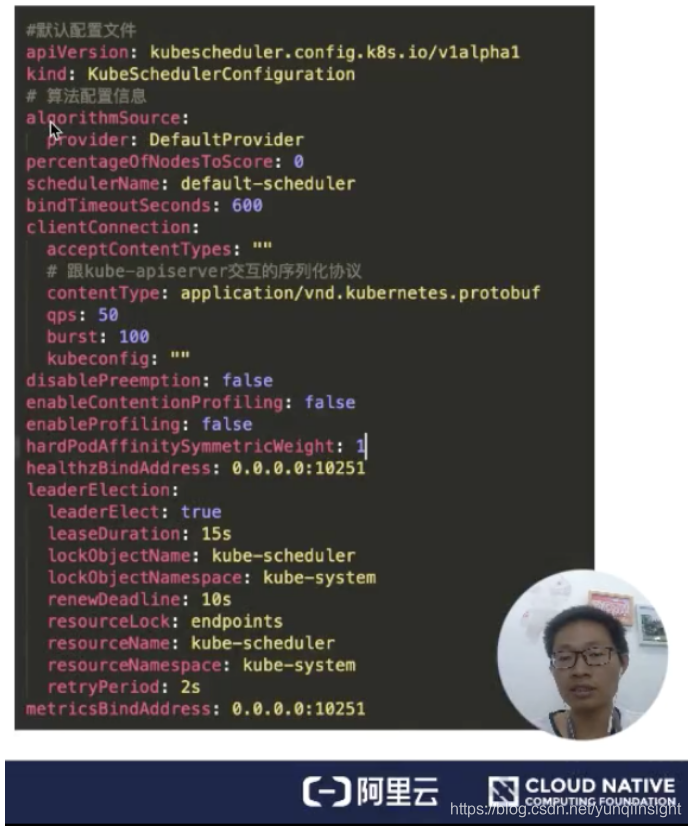
- algorithmSource :算法提供者,目前提供三种方式:Provider、file、configMap,后面会介绍这块;
- percentageOfNodesToscore : 调度器提供的一个扩展能力,能够减少 Node 节点的取样规模;
- schedulerName :用来表示调度器启动的时候,负责哪些 Pod 的调度;如果没有指定的话,默认名称就是 default-scheduler;
- bindTimeoutSeconds :用来指定 bind 阶段的操作时间,单位是秒;
- clientConnection: 用来配置跟 kube-apiserver 交互的一些参数配置。比如 contentType,是用来跟 kube-apiserver 交互的序列化协议,这里指定为 protobuf;
- disablePreemption :关闭抢占调度;
- hardPodAffinitySymnetricweight :配置 PodAffinity 和 NodeAffinity 的权重是多少。
algorithmSource

这里介绍一下过滤器、打分器等一些配置文件的格式,目前提供三种方式:
- Provider
- file
- configMap
如果指定的是 Provider,有两种实现方式:
- 一种是 DefaultPrivider;
- 一种是 ClusterAutoscalerProvider。
ClusterAutoscalerProvider 是优先堆叠的,DefaultPrivider 是优先打散的。关于这个策略,当你的节点开启了自动扩容,尽量使用 ClusterAutoscalerProvider 会比较符合你的需求。
这里看一下策略文件的配置内容,如下图所示:
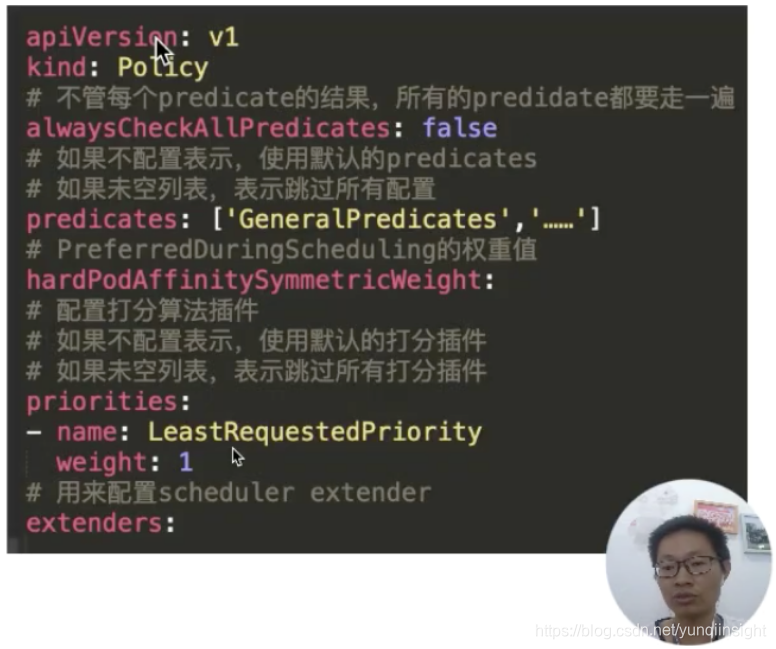
这里可以看到配置的过滤器 predicates,配置的打分器 priorities,以及我们配置的扩展调度器。这里有一个比较有意思的参数就是:alwaysCheckAllPredicates。它是用来控制当过滤列表有个返回 false 时,是否继续往下执行?默认的肯定是 false;如果配置成 true,它会把每个插件都走一遍。
如何扩展调度器
Scheduler Extender

首先来看一下 Schedule Extender 能做什么?在启动官方调度器之后,可以再启动一个扩展调度器。
通过配置文件,如上文提到的 Polic 文件中 extender 的配置,包括 extender 服务的 URL 地址、是否 https 服务,以及服务是否已经有 NodeCache。如果有 NodeCache,那调度器只会传给 nodenames 列表。如果没有开启,那调度器会把所有 nodeinfo 完整结构都传递过来。
ignorable 这个参数表示调度器在网络不可达或者是服务报错,是否可以忽略扩展调度器。managedResources,官方调度器在遇到这个 Resource 时会用扩展调度器,如果不指定表示所有的都会使用扩展调度器。
这里举个 GPU share 的例子。在扩展调度器里面会记录每个卡上分配的内存大小,官方调度器只负责 Node 节点上总的显卡内存是否足够。这里扩展资源叫 example/gpu-men: 200g,假设有个 Pod 要调度,通过 kube-scheduler 会看到我们的扩展资源,这个扩展资源配置要走扩展调度器,在调度阶段就会通过配置的 url 地址来调用扩展调度器,从而能够达到调度器能够实现 gpu-share 的能力。
Scheduler Framework
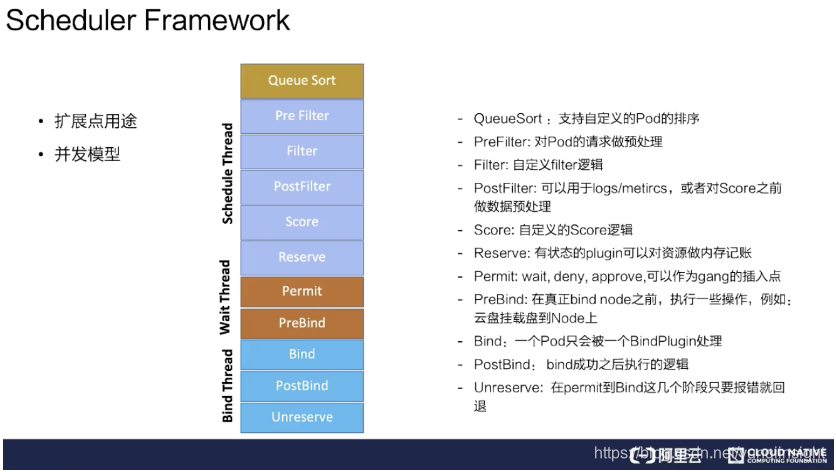
这里分成两点来说,从扩展点用途和并发模型分别介绍。
扩展点的主要用途
扩展点的主要用途主要有以下几个:
- QueueSort:用来支持自定义 Pod 的排序。如果指定 QueueSort 的排序算法,在调度队列里面就会按照指定的排序算法来进行排序;
- Prefilter:对 Pod 的请求做预处理,比如 Pod 的缓存,可以在这个阶段设置;
- Filter:就是对 Filter 做扩展,可以加一些自己想要的 Filter,比如说刚才提到的 gpu-shared 可以在这里面实现;
- PostFilter:可以用于 logs/metircs,或者是对 Score 之前做数据预处理。比如说自定义的缓存插件,可以在这里面做;
- Score:就是打分插件,通过这个接口来实现增强;
- Reserver:对有状态的 plugin 可以对资源做内存记账;
- Permit:wait、deny、approve,可以作为 gang 的插入点。这个可以对每个 pod 做等待,等所有 Pod 都调度成功、都达到可用状态时再去做通行,假如一个 pod 失败了,这里可以 deny 掉;
- PreBind:在真正 bind node 之前,执行一些操作,例如:云盘挂载盘到 Node 上;
- Bind:一个 Pod 只会被一个 BindPlugin 处理;
- PostBind:bind 成功之后执行的逻辑,比如可以用于 logs/metircs;
- Unreserve:在 Permit 到 Bind 这几个阶段只要报错就回退。比如说在前面的阶段 Permit 失败、PreBind 失败, 都会去做资源回退。
并发模型
并发模型意思是主调度流程是在 Pre Filter 到 Reserve,如上图浅蓝色部分所示。从 Queue 拿到一个 Pod 调度完到 Reserve 就结束了,接着会把这个 Pod 异步交给 Wait Thread,Wait Thread 如果等待成功了,就会交给 Bind Thread,就是这样一个线程模型。
自定义 Plugin
如何编写注册自定义 Plugin?
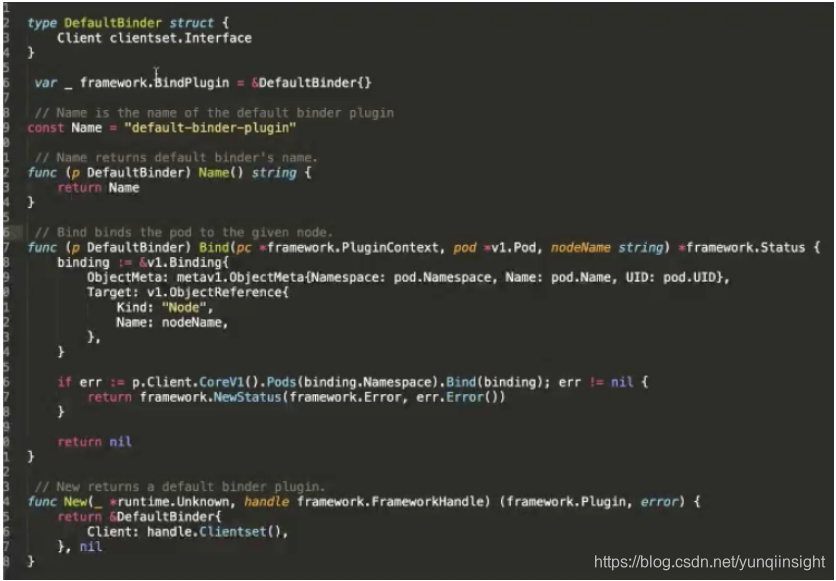
这里是一个官方的例子,在 Bind 阶段,要将 Pod 绑定到某个 Node 上,对 Kube-apiserver 做 Bind。这里可以看到主要有两个接口,bind 的接口是声明调度器的名称,以及 bind 的逻辑是什么。最后还要实现一个构造方法,告诉它的构造方法是怎样的逻辑。
启动自定义 Plugin 的调度器:
- vendor
- fork
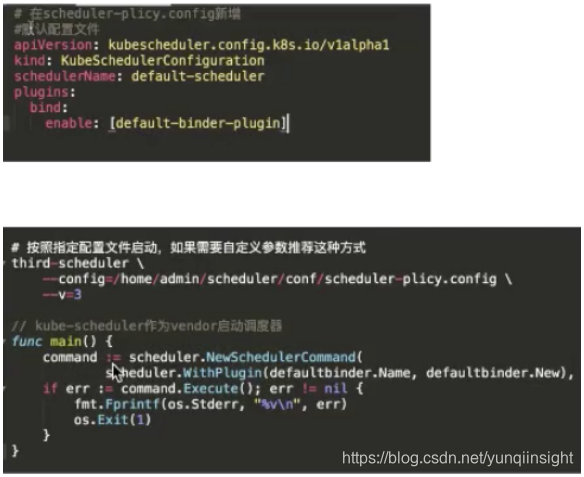
在启动的时候可以通过两种方式去注册:
- 第一种方式是通过自己编写一个脚本,通过 vendor 把调度器的代码 vendor 进来。在启动 scheduler.NewSchedulerCommand 的时候把 defaultbinder 注册进去,这样就可以启动一个调度器;
- 第二种方式是可以 fork kube-scheduler 的源代码,然后把调度器的 defaultbinder 通过 register 插件注册进去。注册完这个插件,去 build 一个脚本、build 一个镜像,然后启动的时候,在配置文件的 plugins.bind.enable 启动起来。
本文总结
本文内容到此就结束了,这里为大家简单总结一下:
- 第一部分跟大家介绍了下调度器的整体工作流程,以及一些计算的算法优化;
- 第二部分详细介绍调度的主要几个工作组件过滤器组件、score 组件的实现,并列举几个 score 的使用场景;
- 第三部分介绍调度器的配置文件的用法说明,让大家可以通过这些配置来实现自己期望的调度行为;
- 第四部分介绍了一些高级用法,怎么通过 extender/framework 扩展调度能力,来满足特殊业务场景的调度需求。
原文链接
本文为阿里云原创内容,未经允许不得转载。



















