OB君:2020年9月25日,OceanBase在外滩大会举办的“数据库,新标杆,新征途”分论坛正式落幕,内容涵盖数据库的趋势探讨、分布式数据库的技术创新与行业应用,及国内数据库的发展与生态。欢迎持续关注本系列内容~
北京奥星贝斯科技有限公司 CTO 兼 OceanBase 数据库创始人阳振坤,在外滩大会上分享了《OceanBase 数据库七亿 tpmC 的关键技术》的主题演讲,以下为演讲实录:
联机事务处理(OLTP)系统
很多人都清楚事务的 ACID 特性,知道事务要满足原子性、一致性、隔离性和持久性,这是从数据库本身的角度来看。但是,如果站在业务的角度,客户对数据库其实有更高的要求,第一个要求是数据不能错,交易数据是企业所有数据的基础,是最核心的数据,这是企业的命脉。

第二个要求是服务不能停,比如最早期的支付宝在后半夜没有业务访问或者业务访问量很少,如今支付宝24小时都有访问,每日高峰的时候峰值甚至比早年的双11还高。所以服务是永远不能停的。
第三个要求是事务高并发处理能力,因为很难预算出有多少用户在同时使用,所以这就需要数据库有高度并发处理的能力。全世界有非常多的数据库厂商,近年来也进入了国产数据库的繁荣时期,但是翻过这座山真正能够把这套系统做到生产中使用的其实少之又少。
TPC-C 基准测试
TPC-C benchmark 诞生于上个世纪80年代,ATM 自动提款机问世以后,数据库厂商都希望推销自家的联机交易处理系统。各个数据库厂商在联机交易处理的 benchmark 上各自为政,没有统一的规范,各自的 benchmark 结果既缺乏足够的说服力,用户也无法在各个系统之间进行参照和对比。
TPC 组织的创始人 Omri Serlin 说服了8家公司成立 TPC 组织,共同制定数据库的系列 benchmark 测试标准并对测试过程和结果进行审计和认证。TPC-C 是其中的联机交易处理的测试标准,也是国际上最重要最权威的测试标准。TPC-C 模型本身看起来似乎很简单,也就是九张表、五种事务。但正是这个看似简单的模型,却很好了抽象了直到今天的各个行业业务系统,包括电子商务、银行、商场、交通、通信、政府、企业等等。
TPC-C 的测试和审计是一个特别严格的过程。TPC-C 审计要求首先做功能的验证,也就是数据库事务的 ACID,功能验证通过了才能跑性能。跑性能则有两个要求:第一,要求8小时稳定运行,没有任何人工干预;第二,性能测试至少进行2小时且期间的性能波动不超过2%。这一定程度上证明了系统的稳定和可靠性。
过去从来没有分布式数据库做过 TPC-C 测试。鉴于 OceanBase 存储架构的特殊性,OceanBase 的性能测试是8小时而不是通常的2小时,因此整个8小时中性能波动不能超过2%。
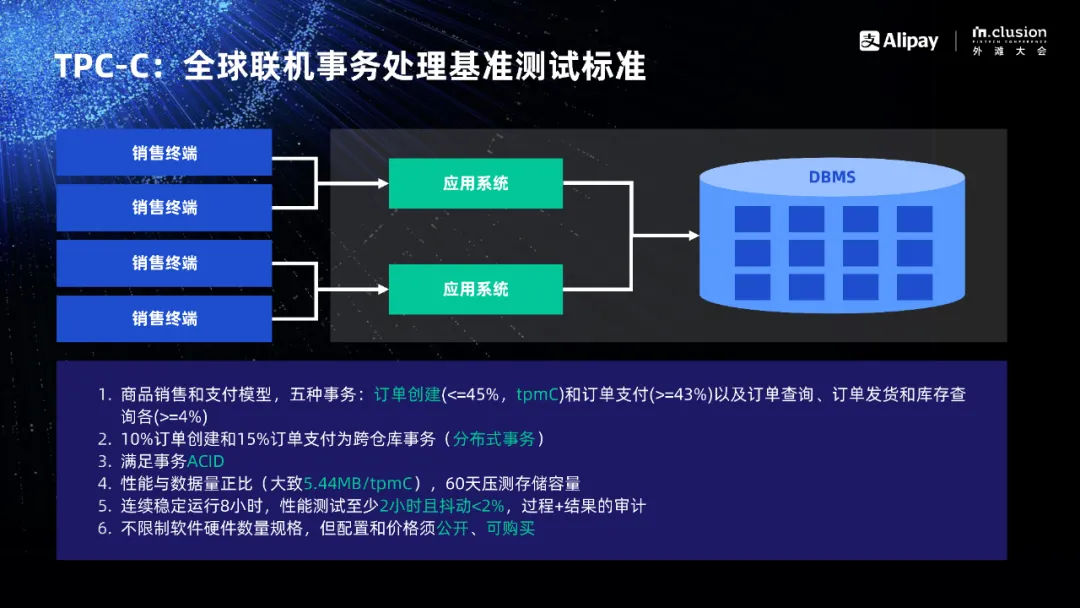
可能有人会说,我可以用很少的数据也能跑出很高的性能,这个数据可以在 CPU 的缓存里,但这是 TPC-C 所不允许的,因为 TPC-C 测试对应的是实际业务场景。在实际业务中,用户数越多,性能越高,数据量也越大。所以,TPC-C 要求性能与数据量成正比。这里我们需要提到 TPC-C 的一个基本概念——仓库,每个仓库最高只允许12.86个tpmC,大致换算一下,相当于一个 tpmC 对应5.44MB的数据。
另外有一个看起来很宽松的要求,不限制测试的软件和硬件的版本和型号,也不限制软件硬件的数量和规格,但配置和价格必须是公开的,且在市场上可购买的。那么有人会问是否只要堆越多的机器,就能达到越高的性能呢?对于交易处理系统,其实并没有这么简单。
为什么没有分布式 OLTP 数据库产品?
很多人大学里学过分布式事务,有人说两阶段提交如果2台机器能够做,3台、4台、5台机器也能做,那么用100台、1000台机器,是否就能跑出更高的性能?
可能很多人没有仔细去想这件事,分布式事务两阶段提交其实是理论上的结果,而且这基于很强的假设——假设硬件不出故障,尤其存储不出故障。
那我们看看下面这个模型,假设 A 给 B 转 100 元钱,原来 A 有 900 元,B 有 500 元,转账后应该 A 有 800 元、B 有 600 元,这是很简单的一个流程:第一阶段做准备工作,检查一下 A 账户是否正常,同时检查 B 帐户是否正常,任何一个不满足转账条件,转账交易就要被取消,如果两个账户都正常,那就通知 A 扣 100 元,通知 B 加 100元。

这个过程看起来一切都很正常,但是如果其中有一个结点比如 A 这个结点坏了,这怎么办?B 这个结点的 100 元加还是不加,仔细分析加也不对,不加也不对。假如 A 彻底坏掉了,就没有人知道它曾经做过这笔交易,如果 B 加了这 100 元,A 这里没减,这个帐就不平了。那反过来如果 A 这个节点过一会儿又正常了,B 这个节点不加这 100 元也不对,因为 A 的 100元减掉了,B 的100元没有加。那么看起来很简单的一件事,其实做起来就变得很困难。所以事务处理不是简简单单靠堆机器就可以堆出来的。
那么,又有人会问如果给这两个结点各建一个备库,出了问题用备库来顶上行不行?答案也是否定的。因为主备镜像无法做到主库与备库完全一致,你要想做到完全一致,意味着每一笔事务都需要从主库同步到备库,这时候整个系统的可用性的链路变长了。对于银行和企业来说,这是一个生死两难的问题,要保证同步,就面临着业务不可用的风险。所以,主备一致性与服务可用性两者不可兼得。
OceanBase 的诞生契机
我们前面讲了,交易型数据库很难做,而且做了市场上很可能没有用户敢用,何况它的各方面投入也会很大。而 OceanBase 的诞生和发展得益于有了千载难逢的天时地利与人和的机遇。

“天时”是互联网的爆发式增长对数据库的高并发、大数据量提出了很高的需求,而传统关系数据库难以满足这个需求;“地利”是阿里巴巴内部从淘宝到支付宝拥有大量使用数据库的场景,OceanBase 可以从不是特别关键的应用场景开始尝试,一步步地将数据库做到关键系统;“人和”是当时单机数据库已经走到了尽头,下一步一定是走向分布式,而当时团队成员恰好具备分布式技术背景。这几个条件一起促成了 OceanBase 的诞生。
OceanBase 的技术架构
多数派(Paxos)协议
分布式数据库一定会面临分布式事务,面临两阶段提交,普通两阶段提交解决不了这个问题,也分析过之所以出问题是因为对节点的可靠性做了假设。可以回想一下,如果刚才两阶段提交中结点都不出问题,那么两阶段提交是可以工作的。
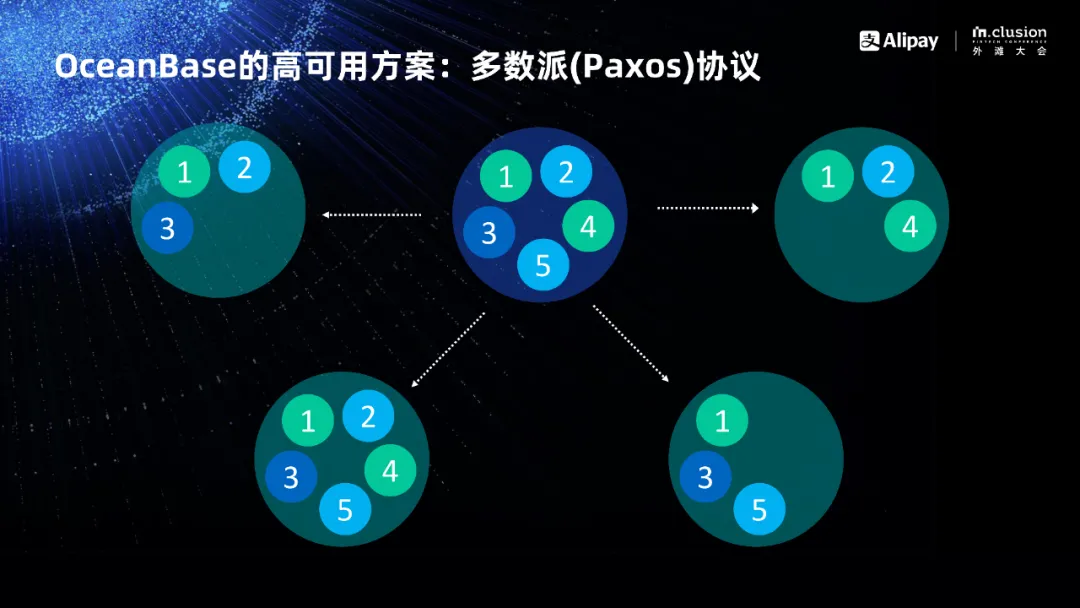
OceanBase 是怎么解决这个问题的呢?OceanBase 的做法是在原有的基础上增加一个备库,主库同步事务到两个备库,只要一个备库收到,加上主库自己至少两个库收到,这样如果两个备库相当于三个结点三个副本,如果四个备库相当于五个结点五个副本。你坏一个甚至两个结点,数据还在,整个系统可以正常完成两阶段的提交工作。
OceanBase 分布式事务实现
我们以三个结点三个副本为例,哪怕坏了一个结点,剩下两个结点每一笔事务至少在其中一个结点上存在,那么可以利用这一点把刚才没有进行完的事务或者进行中的事务恢复出来,只要恢复出来事情就可以做下去,两阶段的提交就可以正常结束。

三代 TPC-C 排行榜榜首
去年 OceanBase 第一次 TPC-C 测试之后,有一些的噪音,大家说你跟九年前的结果比算不了什么,其实是这些人并不了解 OceanBase 登顶背后的真正意义。

OceanBase 的 TPC-C 测试的立项是2018年8月16日,立项前讨论这个事情的时候,大家有一定的担心,因为从人力物力各方面来看都是比较大的投入。讨论之后定了两步走的策略,第一步做小一点的规模,目的是把这条路先走通,因为当时全世界还没有厂商用分布式数据做过 TPC-C 测试。后来用了200多台的数据库服务器,经过半年多的时间,最终通过了这个测试。TPC-C 委员会的人对于传统的集中式数据库很熟悉,但分布式事务处理数据库,他们也没有接触过。
第一次 TPC-C 测试通过之后,第二次测试的准备就开始了。因为有了第一次测试的经验,第二次的测试结果是在意料之中的。或许有人会问集中式数据库是否还能跑出更高的性能?众所周知,数据库的性能,受制于两个瓶颈,一个是 CPU,另一个是 IO。三代 TPC-C 榜首中,第一和第二代的榜首是传统数据库的代表。第三代榜首是 OceanBase,达到了7亿多 tpmC,比二代高了一个数量级。在分布式环境下,OceanBase 的存储是本地盘,这个 IO 能力比共享存储的万兆网卡要更强,最关键是没有数量上的限制,无论是 CPU 还是硬盘数量。
新一代 HTAP 原生分布式关系数据库
讲到这里,可能会有人说,分库分表也可以解决你说到的类似问题。是的,确实会解决一些问题,但有些是很难解决的,比如分库分表后是多个数据库,这多个数据库要保持 ACID 就非常困难。如果原来的数据库是单一数据库,就需要重新设计和规划整个系统。有人混淆分布式数据库的概念,把分库分表也叫分布式,但其实它不是分布式数据库,因为它是多个数据库而不是一个数据库,也不满足 ACID 。
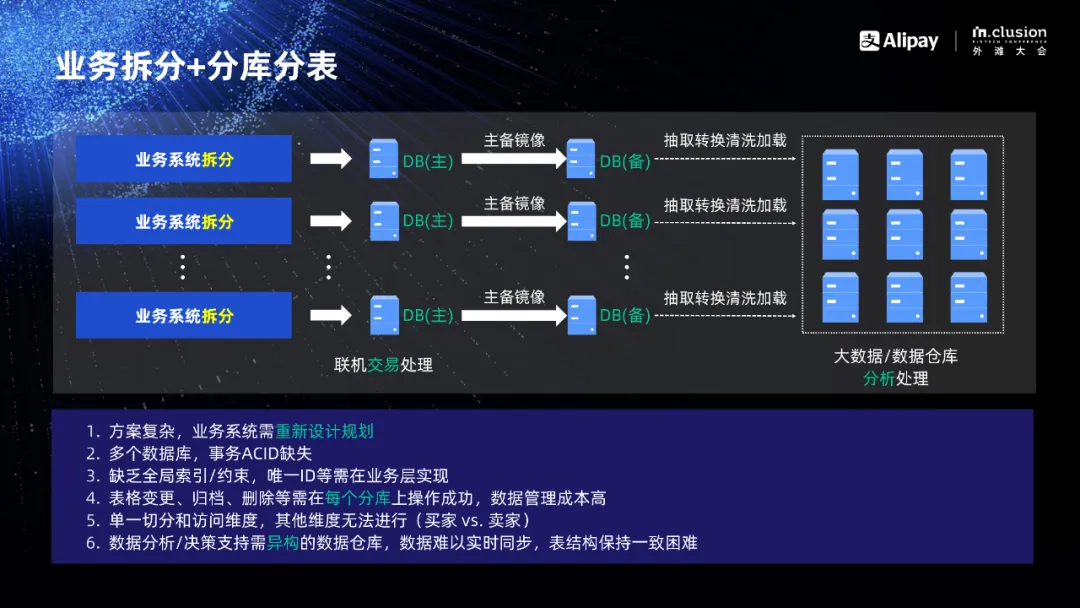
分库分表方案缺乏全局索引和唯一ID,因为它不再是单个数据库。还要对业务做拆分,有个拆分维度,比如买家维度,那么业务上需要对卖家的维度进行处理怎么办?因为卖家的信息会遍布所有分库,如果做简单的统计还可以进行,但如果涉及事务的处理是没有办法进行的。分库分表方案虽然可以解决一些问题,但也带来更多的挑战,更大的复杂性和更高的成本。
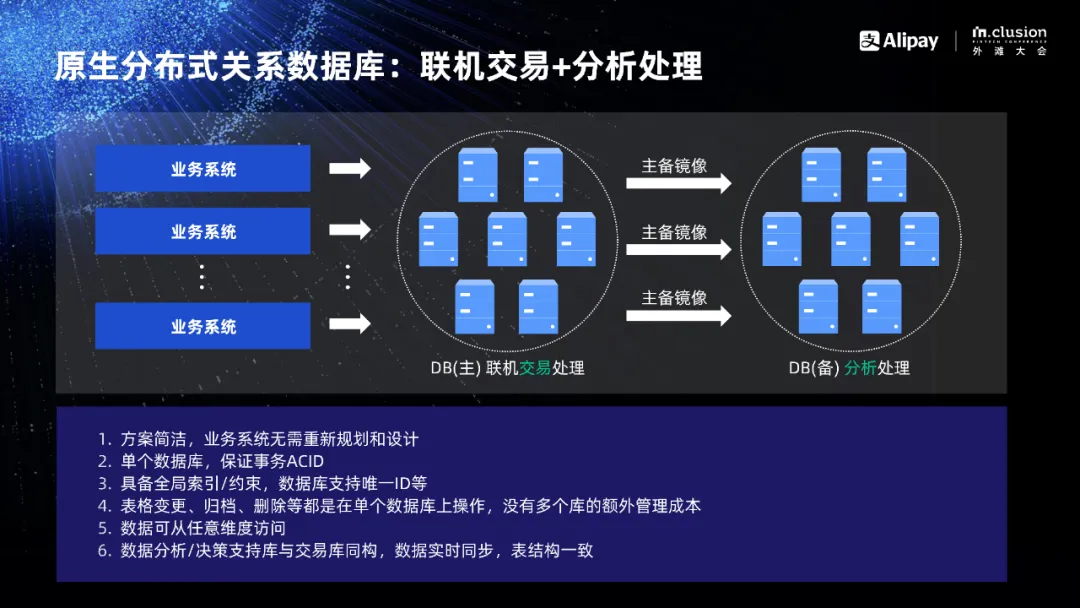
作为一款原生分布式关系数据库,OceanBase 本身可以做到水平扩展,不需要重新拆分业务,我们可以在主库做交易处理,在备库做数据分析处理。甚至在未来可以在主库上同时完成交易和分析的处理。这一技术上的革新很好地克服了分库分表方案的弊端。
原生分布式是数据库的未来
如今的海量数据处理系统,不论是大数据系统还是数据仓库,它们都是分布式——原生分布式。但是我们再看关系数据库尤其是 OLTP 数据库,目前它仍然是单机/集中式的。不是 OLTP 数据库不需要分布式,而是分布式的 OLTP 数据库的研制非常困难。
有很多客户说,分布式是很好,但是今天分布式的生态不够成熟,不如集中式数据库的生态。回想起150年前,汽车刚刚被发明,马车还是最主流的交通工具,当时在马路上优先通行的是马车,汽车也没有生态。而到了2020年的今天,作为主流交通工具的马车已经成为远古的过去,汽车早就成为了不可逆转的主流。
原文链接
本文为阿里云原创内容,未经允许不得转载。




Server 端开启服务过程)














