简介: 在异地多活的实现上,数据能够在三个及以上中心间进行双向同步,才是解决真正异地多活的核心技术所在。本文基于三中心且跨海外的场景,分享一种多中心容灾架构及实现方式,介绍几种分布式ID生成算法,以及在数据同步上最终一致性的实现过程。

一 背景
为什么称之为真正的异地多活?异地多活已经不是什么新鲜词,但似乎一直都没有实现真正意义上的异地多活。一般有两种形式:一种是应用部署在同城两地或多地,数据库一写多读(主要是为了保证数据一致性),当主写库挂掉,再切换到备库上;另一种是单元化服务,各个单元的数据并不是全量数据,一个单元挂掉,并不能切换到其他单元。目前还能看到双中心的形式,两个中心都是全量数据,但双跟多还是有很大差距的,这里其实主要受限于数据同步能力,数据能够在3个及以上中心间进行双向同步,才是解决真正异地多活的核心技术所在。
提到数据同步,这里不得不提一下DTS(Data Transmission Service),最初阿里的DTS并没有双向同步的能力,后来有了云上版本后,也只限于两个数据库之间的双向同步,做不到A<->B<->C这种形式,所以我们自研了数据同步组件,虽然不想重复造轮子,但也是没办法,后面会介绍一些实现细节。
再谈谈为什么要做多中心容灾,以我所在的CDN&视频云团队为例,首先是海外业务的需要,为了能够让海外用户就近访问我们的服务,我们需要提供一个海外中心。但大多数业务还都是以国内为主的,所以国内要建双中心,防止核心库挂掉整个管控就都挂掉了。同时海外的环境比较复杂,一旦海外中心挂掉了,还可以用国内中心顶上。国内的双中心还有个非常大的好处是可以通过一些路由策略,分散单中心系统的压力。这种三个中心且跨海外的场景,应该是目前异地多活最难实现的了。
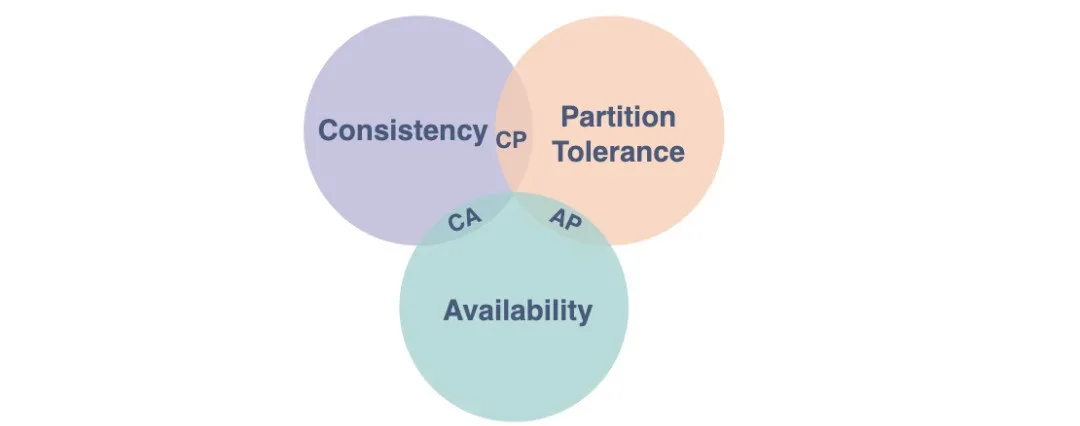
二 系统CAP
面对这种全球性跨地域的分布式系统,我们不得不谈到CAP理论,为了能够多中心全量数据提供服务,Partition tolerance(分区容错性)是必须要解决的,但是根据CAP的理论,Consistency(一致性)和Availability(可用性)就只能满足一个。对于线上应用,可用性自不用说了,那面对这样一个问题,最终一致性是最好的选择。
三 设计原则
1 数据分区
选择一个数据维度来做数据切片,进而实现业务可以分开部署在不同的数据中心。主键需要设计成分布式ID形式,这样当进行数据同步时,不会造成主键冲突。
下面介绍几个分布式ID生成算法。
SnowFlake算法
1)算法说明
+--------------------------------------------------------------------------+
| 1 Bit Unused | 41 Bit Timestamp | 10 Bit NodeId | 12 Bit Sequence Id |
+--------------------------------------------------------------------------+- 最高位是符号位,始终为0,不可用。
- 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
- 10位的机器标识,10位的长度最多支持部署1024个节点。
- 12位的计数序列号,序列号即一系列的自增ID,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
2)算法总结
优点:
- 完全是一个无状态机,无网络调用,高效可靠。
缺点:
- 依赖机器时钟,如果时钟错误比如时钟回拨,可能会产生重复Id。
- 容量存在局限性,41位的长度可以使用69年,一般够用。
- 并发局限性,每毫秒单机最大产生4096个Id。
- 只适用于int64类型的Id分配,int32位Id无法使用。
3)适用场景
一般的非Web应用程序的int64类型的Id都可以使用。
为什么说非Web应用,Web应用为什么不可以用呢,因为JavaScript支持的最大整型就是53位,超过这个位数,JavaScript将丢失精度。
RainDrop算法
1)算法说明
为了解决JavaScript丢失精度问题,由Snowflake算法改造而来的53位的分布式Id生成算法。
+--------------------------------------------------------------------------+
| 11 Bit Unused | 32 Bit Timestamp | 7 Bit NodeId | 14 Bit Sequence Id |
+--------------------------------------------------------------------------+- 最高11位是符号位,始终为0,不可用,解决JavaScript的精度丢失。
- 32位的时间序列,精确到秒级,32位的长度可以使用136年。
- 7位的机器标识,7位的长度最多支持部署128个节点。
- 14位的计数序列号,序列号即一系列的自增Id,可以支持同一节点同一秒生成多个Id,14位的计数序列号支持每个节点每秒单机产生16384个Id。
2)算法总结
优点:
- 完全是一个无状态机,无网络调用,高效可靠。
缺点:
- 依赖机器时钟,如果时钟错误比如时钟不同步、时钟回拨,会产生重复Id。
- 容量存在局限性,32位的长度可以使用136年,一般够用。
- 并发局限性,低于snowflake。
- 只适用于int64类型的Id分配,int32位Id无法使用。
3)适用场景
一般的Web应用程序的int64类型的Id都基本够用。
分区独立分配算法
1)算法说明
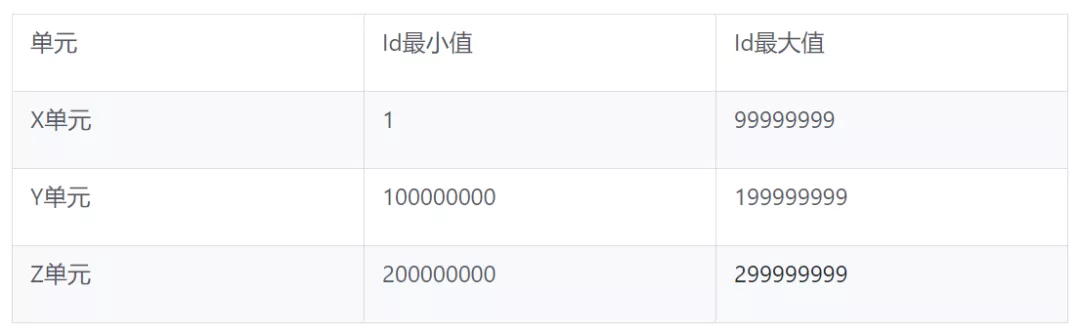
通过将Id分段分配给不同单元独立管理。同一个单元的不同机器再通过共享redis进行单元内的集中分配。
相当于每个单元预先分配了一批Id,然后再由各个单元内进行集中式分配。
比如int32的范围从-2147483648到2147483647,Id使用范围1,2100000000),前两位表示region,则每个region支持100000000(一亿)个资源,即Id组成格式可以表示为[0-20。
即int32位可以支持20个单元,每个单元支持一亿个Id。
2)算法总结
优点:
- 区域之间无状态,无网络调用,具备可靠唯一性
缺点:
- 分区容量存在局限性,需要预先评估业务容量。
- 从Id中无法判断生成的先后顺序。
3)适用场景
适用于int32类型的Id分配,单个区域内容量上限可评估的业务使用。
集中式分配算法
1)算法说明
集中式可以是Redis,也可以是ZooKeeper,也可以利用数据库的自增Id集中分配。
2)算法总结
优点:
- 全局递增
- 可靠的唯一性Id
- 无容量和并发量限制
缺点:
- 增加了系统复杂性,需要强依赖中心服务。
3)适用场景
具备可靠的中心服务的场景可以选用,其他int32类型无法使用分区独立分配的业务场景。
总结
每一种分配算法都有各自的适用场景,需要根据业务需求选择合适的分配算法。主要需要考虑几个因素:
- Id类型是int64还是int32。
- 业务容量以及并发量需求。
- 是否需要与JavaScript交互。
2 中心封闭
尽量让调用发生在本中心,尽量避免跨数据中心的调用,一方面为了用户体验,本地调用RT更短,另一方面防止同一个数据在两个中心同时写入造成数据冲突覆盖。一般可以选择一种或多种路由方式,如ADNS根据地域路由,通过Tengine根据用户属性路由,或者通过sidecar方式进行路由,具体实现方式这里就不展开说了。
3 最终一致性
前面两种其实就是为了最终一致性做铺垫,因为数据同步是牺牲了一部分实时的性能,所以我们需要做数据分区,做中心封闭,这样才能保证用户请求的及时响应和数据的实时准确性。
前面提到了由于DTS支持的并不是很完善,所以我基于DRC(一个阿里内部数据订阅组件,类似canal)自己实现了数据同步的能力,下面介绍一下实现一致性的过程,中间也走了一些弯路。
顺序接收DRC消息
为了保证对于DRC消息顺序的接收,首先想到的是采用单机消费的方式,而单机带来的问题是数据传输效率慢。针对这个问题,涉及到并发的能力。大家可能会想到基于表级别的并发,但是如果单表数据变更大,同样有性能瓶颈。这里我们实现了主键级别的并发能力,也就是说在同一主键上,我们严格保序,不同主键之间可以并发同步,将并发能力又提高了N个数量级。
同时单机消费的第二个问题就是单点。所以我们要实现Failover。这里我们采用Raft协议进行多机选主以及对主的请求。当单机挂掉之后,其余的机器会自动选出新的Leader执行同步任务。
消息跨单元传输
为了很好的支持跨单元数据同步,我们采用了MNS(阿里云消息服务),MNS本身是个分布式的组件,无法满足消息的顺序性。起初为了保证强一致性,我采用消息染色与还原的方式,具体实现见下图:
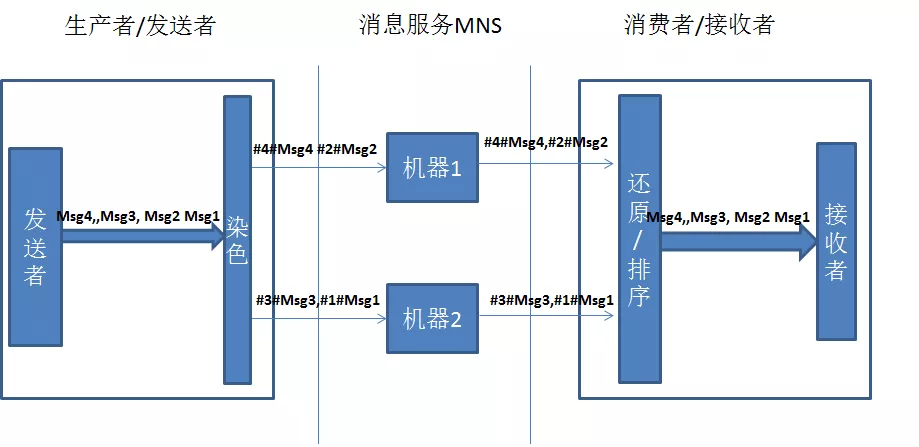
通过实践我们发现,这种客户端排序并不可靠,我们的系统不可能无限去等待一个消息的,这里涉及到最终一致性的问题,在第3点中继续探讨。其实对于顺序消息,RocketMQ是有顺序消息的,但是RocketMQ目前还没有实现跨单元的能力,而单纯的就数据同步而言,我们只要保证最终一致性就可以了,没有必要为了保证强一致性而牺牲性能。同时MNS消息如果没有消费成功,消息是不会丢掉的,只有我们去显示的删除消息,消息才会丢,所以最终这个消息一定会到来。
最终一致性
既然MNS无法保证强顺序,而我们做的是数据同步,只要能够保证最终一致性就可以了。2012年CAP理论提出者Eric Brewer撰文回顾CAP时也提到,C和A并不是完全互斥,建议大家使用CRDT来保障一致性。CRDT(Conflict-Free Replicated Data Type)是各种基础数据结构最终一致算法的理论总结,能根据一定的规则自动合并,解决冲突,达到强最终一致的效果。通过查阅相关资料,我们了解到CRDT要求我们在数据同步的时候要满足交换律、结合律和幂等律。如果操作本身满足以上三律,merge操作仅需要对update操作进行回放即可,这种形式称为op-based CRDT,如果操作本身不满足,而通过附带额外元信息能够让操作满足以上三律,这种形式称为state-based CRDT。
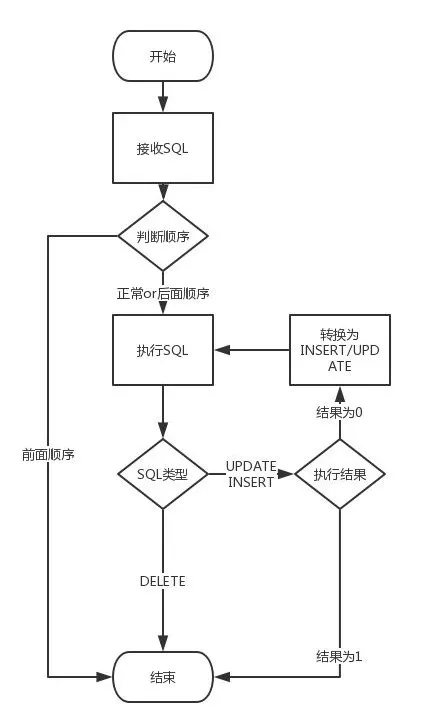
通过DRC的拆解,数据库操作有三种:insert、update、delete,这三种操作不管哪两种操作都是不能满足交换律的,会产生冲突,所以我们在并发级别(主键)加上额外信息,这里我们采用序号,也就是2中提到的染色的过程,这个过程是保留的。而主键之间是并发的,没有顺序而言。当接收消息的时候我们并不保证强顺序,采用LWW(Last Write Wins)的方式,也就是说我们执行当前的SQL而放弃前面的SQL,这样我们就不用考虑交换的问题。同时我们会根据消息的唯一性(实例+单元+数据库+MD5(SQL))对每个消息做幂等,保证每个SQL都不会重复执行。而对于结合律,我们需要对每个操作单独分析。
1)insert
insert是不满足结合律的,可能会有主键冲突,我们把insert语句变更insert ignore,而收到insert操作说明之前并不存在这样一条记录,或者前面有delete操作。而delete操作可能还没有到。这时insert ignore操作返回结果是0,但这次的insert数据可能跟已有的记录内容并不一致,所以这里我们将这个insert操作转换为update 操作再执行一次。
2)update
update操作天然满足结合律。但是这里又要考虑一种特殊情况,那就是执行结果为0。这说明此语句之前一定存在一个insert语句,但这个语句我们还没有收到。这时我们需要利用这条语句中的数据将update语句转成insert再重新执行一次。
3)delete
delete也是天然满足结合律的,而无论之前都有什么操作,只要执行就好了。
在insert和update操作里面,都有一个转换的过程,而这里有个前提,那就是从DRC拿到的变更数据每一条都是全字段的。可能有人会说这里的转换可以用replace into替换,为什么没有使用replace into呢,首先由于顺序错乱的情况毕竟是少数,而且我们并不单纯复制数据,同时也是在复制操作,而对于DRC来说,replace into操作会被解析为update或insert。这样无法保证消息唯一性,也无法做到防循环广播,所以并不推荐。我们看看下面的流程图也许会更清晰些:
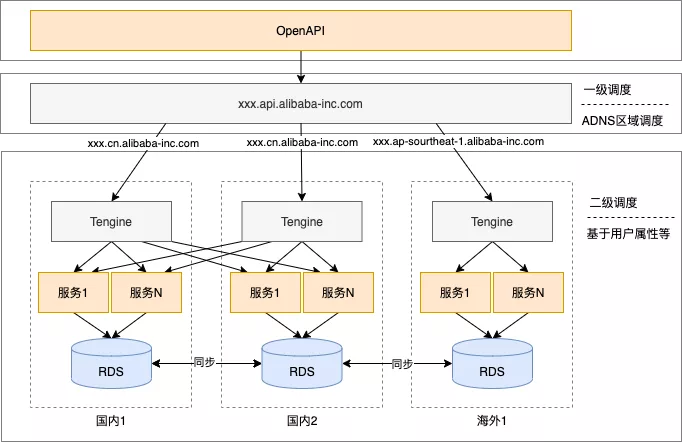
四 容灾架构
根据上面的介绍,我们来看下多中心容灾架构的形态,这里用了两级调度来保证中心封闭,同时利用自研的同步组件进行多中心双向同步。我们还可以制定一些快恢策略,例如快速摘掉一个中心。同时还有一些细节需要考虑,例如在摘掉一个中心的过程中,在摘掉的中心数据还没有同步到其他中心的过程中,应该禁掉写操作,防止短时间出现双写的情况,由于我们同步的时间都是毫秒级的,所以影响很小。
五 结束语
架构需要不断的演进,到底哪种更适合你还需要具体来看,上述的多中心架构及实现方式欢迎大家来讨论。
我们的数据同步组件hera-dts已在BU内部进行使用,数据同步的逻辑还是比较复杂的,尤其是实现双向同步,其中涉及到断点续传、Failover、防丢数据、防消息重发、双向同步中防循环复制等非常多的细节问题。我们的同步组件也是经历了一段时间的优化才达到稳定的版本。
作者:开发者小助手_LS
原文链接
本文为阿里云原创内容,未经允许不得转载

:CGI编程、MySQL数据库)







)







招募开始了!)

