简介: 阿里云AHAS Chaos:应用及业务高可用提升工具平台之故障演练
应用高可用服务AHAS及故障演练AHAS Chaos
应用高可用服务(Application High Availability Service)是阿里云一款专注于提高应用及业务高可用的工具平台,目前主要提供应用架构探测感知、故障注入式高可用能力评测和流控降级高可用防护三大核心能力,通过各自的工具模块可以快速低成本地在营销活动场景、业务核心场景全面提升业务稳定性和韧性。

图1:AHAS服务体系
故障演练AHAS Chaos是一款遵循混沌工程实验原理并融合了阿里巴巴内部实践的产品,提供丰富的故障场景实现,能够帮助分布式系统提升容错性和可恢复性。故障演练建立了一套标准的演练流程,包含准备阶段、执行阶段、检查阶段和恢复阶段。通过四阶段的流程,覆盖用户从计划到还原的完整演练过程,并通过可视化的方式清晰地呈现给用户。
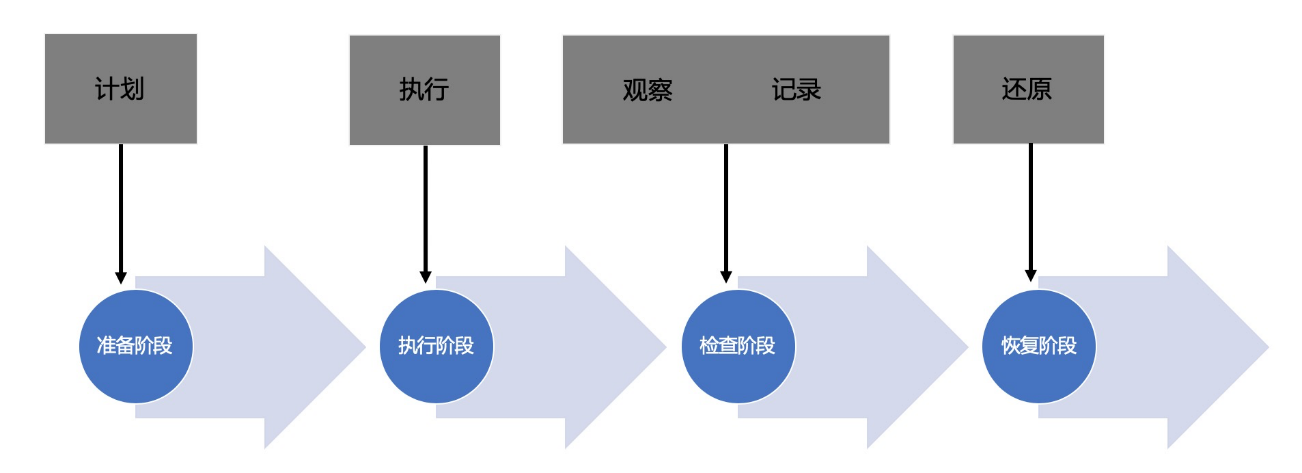
图2:故障演练流程
AHAS Chaos的适用场景
衡量微服务的容错能力
通过模拟调用延迟、服务不可用、机器资源满载等,查看发生故障的节点或实例是否被自动隔离、下线,流量调度是否正确,预案是否有效,同时观察系统整体的QPS或RT是否受影响。在此基础上可以缓慢增加故障节点范围,验证上游服务限流降级、熔断等是否有效。最终故障节点增加到请求服务超时,估算系统容错红线,衡量系统容错能力。
验证容器编排配置是否合理
通过模拟杀服务Pod、杀节点、增大Pod资源负载,观察系统服务可用性,验证副本配置、资源限制配置以及Pod下部署的容器是否合理。
测试PaaS层是否健壮
通过模拟上层资源负载,验证调度系统的有效性;模拟依赖的分布式存储不可用,验证系统的容错能力;模拟调度节点不可用,测试调度任务是否自动迁移到可用节点;模拟主备节点故障,测试主备切换是否正常。
验证监控告警的时效性
通过对系统注入故障,验证监控指标是否准确,监控维度是否完善,告警阈值是否合理,告警是否快速,告警接收人是否正确,通知渠道是否可用等,提升监控告警的准确性和时效性。
定位与解决问题的应急能力
通过故障突袭,随机对系统注入故障,考察相关人员对问题的应急能力,以及问题上报、处理流程是否合理,达到以战养战,锻炼人定位与解决问题的能力。
AHAS Chaos的功能优势
灵活的流程编排
AHAS Chaos将故障演练的环节分为了准备、注入、检查以及恢复四个阶段,每个阶段除了系统初始化完成的必要节点之外,用户也可以根据需要添加自己的流程节点。
AHAS Chaos支持一次演练定义包含多个故障场景,同时用户可以定制这些场景的运行方式,选择依次进行故障注入或同时注入多个场景,通过不同的策略配置来达到不同的故障注入效果。
丰富的故障场景
丰富的故障场景也是AHAS Chaos的一大特色,包括以下场景:
- 常见的基础设施资源例如CPU、内存、磁盘等。
- 应用级别的故障注入,目前支持Java应用,后续将陆续推出对于NodeJs和C++的应用故障注入。
- 云原生领域的演练场景。
无论用户是需要设置集群级别的大规模故障还是应用级别的请求级别细粒度故障,都可以在AHAS Chaos找到适合的场景,下图是AHAS Chaos提供的部分故障场景。
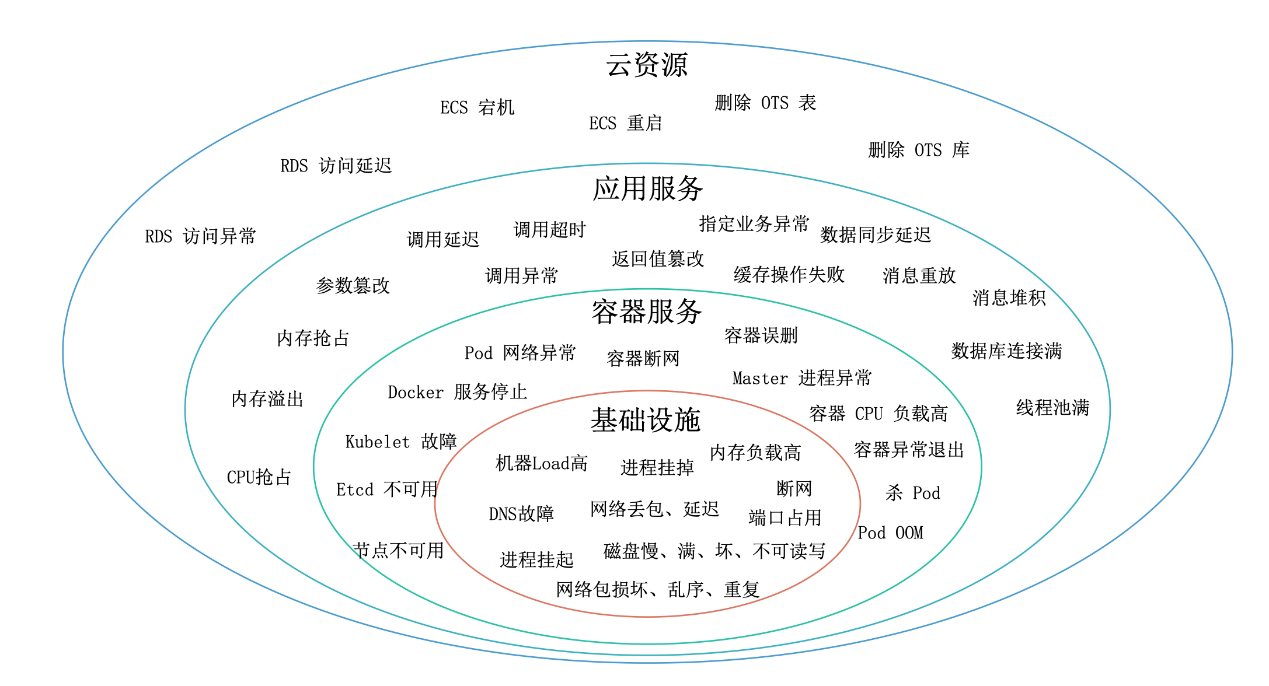
图3:AHAS Chaos提供的部分故障场景
多样的专家经验
AHAS Chaos将阿里内部多年的故障演练经验浓缩成了专家经验,专家经验具有以下优点:
- 专家经验都来自于阿里内部经常演练的场景,保证了演练场景的真实性以及实用性。
- 专家经验不但包括了可执行的演练流程,还描述了专家经验试图解决的问题以及针对的系统架构弱点。
- 专家经验极大地提升了演练创建的效率,用户可以基于专家经验配置好的流程一键生成自己的演练。
安全的演练防护
在保护用户的演练安全性上AHAS Chaos也做了非常多的防护措施:
- 在演练的任意一个环节,用户都可以随时终止演练,每一个终止操作都会自动恢复注入的场景。
- 用户可以一键终止所有正在运行当中的演练。
- 用户可以配置演练的自动恢复时间,防止因演练时间过长而忘记恢复演练引发不必要的问题。
- 用户可以通过全局恢复功能来配置自动恢复的策略,当某个指标符合某个要求时自动恢复演练。
深度集成的阿里云产品
AHAS Chaos和阿里云的许多产品如ARMS、SLS、EDAS、OTS以及架构感知服务等做了深度集成,通过授权用户可以实现以下功能:
- 对依赖的阿里云组件进行故障注入。
- 基于接入的阿里云监控系统数据如ARMS来丰富演练检查和恢复的手段。
- 通过RAM服务来授权不同账号的演练权限,提升演练的安全性。
演练实践
网络不稳定对业务系统的影响
经验描述:通过注入多种网络故障,来检测网络不稳定对系统造成的影响,以及系统的应对情况。
背景:网络环境不好,可能会对业务造成比较大的影响,特别是系统依赖较多的外部服务,比如缓存Redis、消息中间件等,因此需要通过网络层面的故障注入来考察系统的超时处理能力。
架构弱点:1.对第三方系统的调用超时设置不合理;2.缺乏对依赖超时时候的重试能力;3.缺乏对依赖超时问题的兜底策略,比如异常处理、功能降级等措施。
评测:1.系统设置了合理的超时时间,不会因为依赖系统的网络不稳定导致请求超时;2.针对第三方调用超时或者失败的情况,系统配置了监控,并且具备一定的重试能力。
java应用发生oom异常
经验描述:1.通过填满jvm的内存空间,来触发fullgc和oom异常,使得应用的响应时间变长,甚至无响应,来观察业务的处理效率以及监控的发现情况;2.oom存在一定风险无法自动恢复,需要重启应用。
背景:新生代是jvm内部一块重要的内存区域,由于新建对象过多等因素导致该区域内存被占用到一定额度,会触发MiniGc操作进行回收,但是如果新建的对象一直被引用,那么会导致MiniGc无法回收,进而上升到老年代,如果老年代也被占用满,那么就会触发fullgc,频繁的gc操作会导致应用的cpu以及请求响应都变得很高,对业务应用造成比较大的影响。
架构弱点:1.监控缺失,当应用发生fullgc之后,无法及时定位问题,特别是现在很多的jvm监控系统都采用了metric的规范,通过应用提供的http接口来获取监控数据,一旦应用无响应,那么会导致监控数据无法及时获取,进而不能触发报警;2.不能及时下线问题机器,由于频繁的gc,应用已经无法响应业务请求,因此需要及时下线掉问题机器。
评测:1.当应用发生了fullgc,问题机器迅速被隔离掉,不再接受业务请求。2.当应用发生了fullgc,监控系统可以迅速报警并且定位问题。
总结
故障演练AHAS Chaos作为AHAS的一部分,在其中承担了问题发现、问题验证、高可用经验沉淀的作用,并与AHAS其他功能组成了一套完善的高可用保障服务,可以帮助用户实现包括架构、业务、人员的全面高可用提升。
作者:SRE团队技术小编-小兰
原文链接
本文为阿里云原创内容,未经允许不得转载














)




