简介: 本文介绍了微服务治理下金丝雀发布的能力,解决了发布期间少量流量验证新功能的问题。
前言
本文,我们继续聊聊《揭秘大流量场景下发布如丝般顺滑背后的原因》中的另外一环,灰度发布,也叫金丝雀发布。
很多互联网公司在半夜发布的另外一个重要原因是不具备可灰度能力,新版本存在 bug 或者其它原因会影响线上的客户,无奈之下只能选择在半夜进行发布来减少影响面。
我们知道默认情况下,无论是 Kubernetes 还是 ECS,新老版本都存在的情况下会根据特定的负载均衡算法随机地路由到不同的实例上,随机意味着出问题也会随机出现。我们需要一套动态路由来完成灰度发布的解决方案。
在 RPC 领域,我们称灰度发布为动态路由,动态路由的意思是指流量可以动态地路由到指定的实例上。
动态路由场景
动态路由是微服务里非常核心的功能,流量动态路由意味着可以做非常多的事情。由此衍生出各个场景:
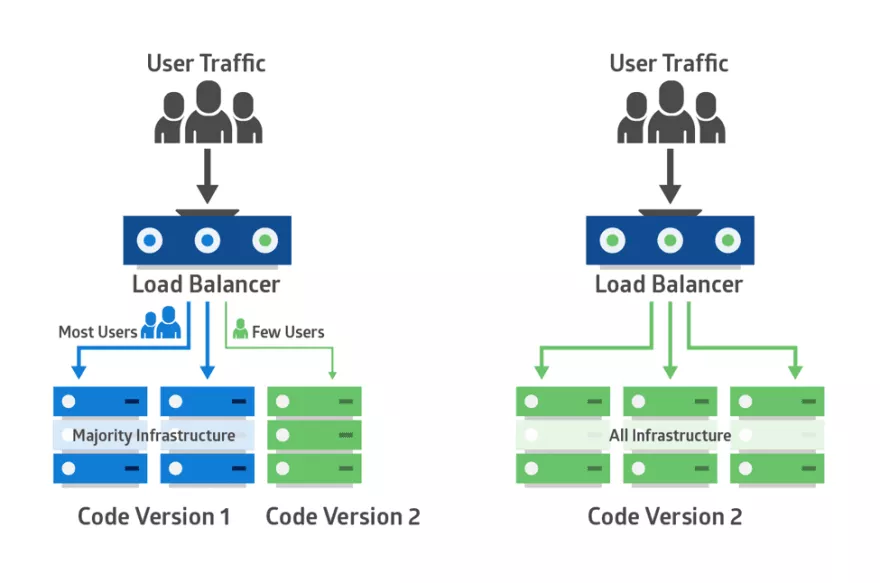
- 金丝雀发布:只有满足特定规则(比如 Query Parameter、HEADER、COOKIE 中某些 KEY 满足一些条件)或者是固定流量比例的流量才会进入新版本,其它流量都路由到老版本上。
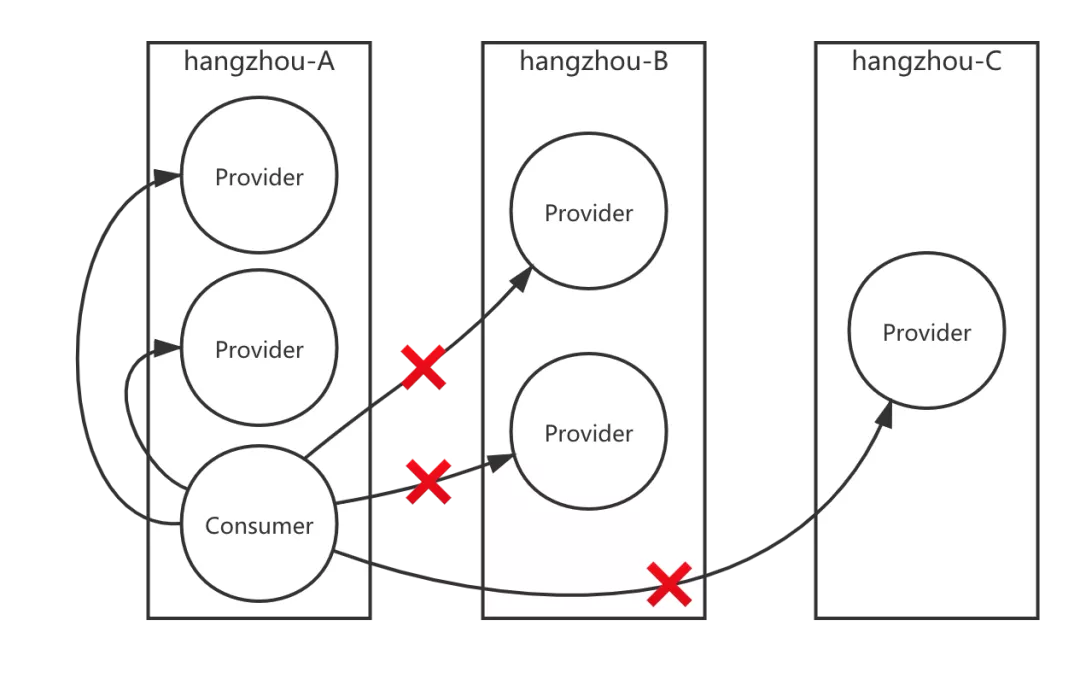
- 同机房优先路由:当公司规模扩大之后,应用会跨机房部署来达到高可用的目的。由于异地跨机房调用出现的网络延迟问题,需要确保服务消费方能优先调用相同机房的服务消费方,这就需要同机房优先路由的能力。
-
标签路由:金丝雀发布的新场景。金丝雀发布一般只有新和老两个版本,标签路由可以在线上部署多个版本,每个版本都对于一个标签。
-
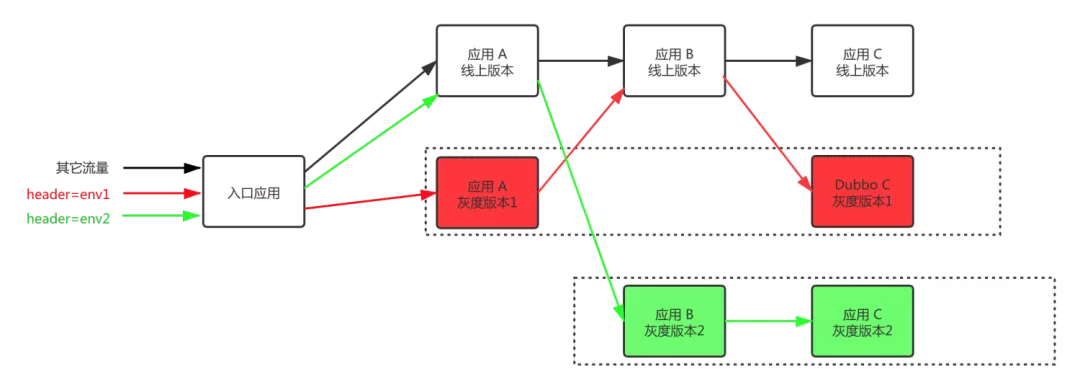
全链路灰度:在业务比较复杂,服务调用链路较长的场景下,每个应用都需要设置路由规则会显得非常繁琐,全链路灰度在金丝雀/标签路由的基础上加上了 "标签透传" 的能力,让灰度流量只在灰度版本之间路由。
接下来我会分几篇文章详细讲一下这几个场景,今天我们先来聊聊金丝雀发布。金丝雀发布可以让我们在白天流量高峰喝着茶吃着瓜子进行线上发布,不需要在半夜为发布的事情而苦恼。
大流量下的应用部署现状
应用 Demo
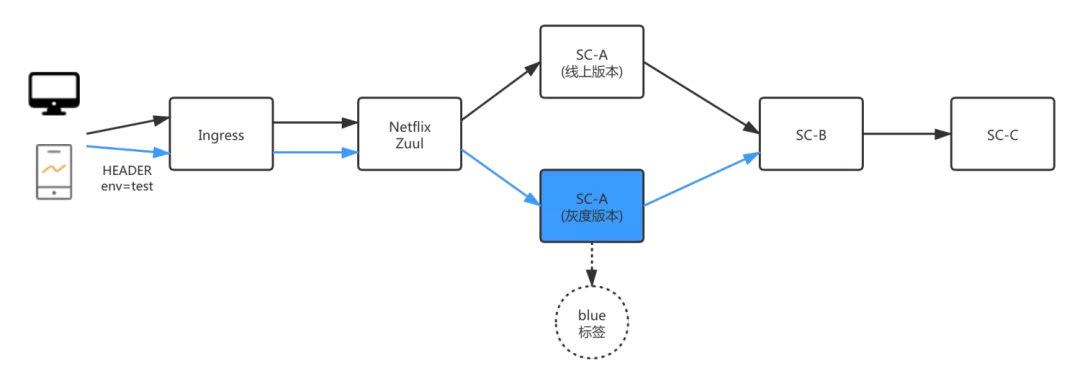
Demo 以 Spring Cloud 为例,服务调用链路如下图所示:
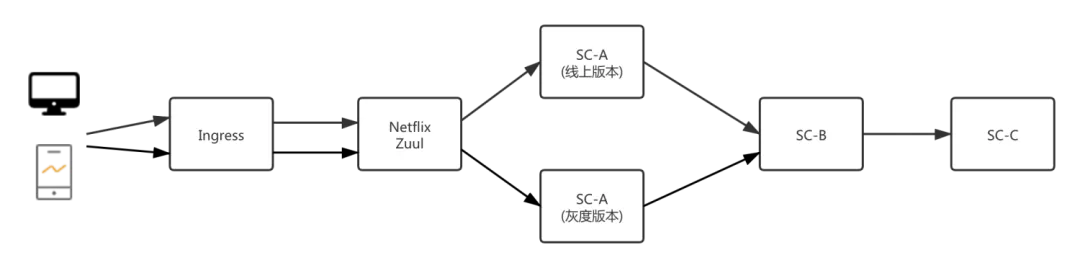
流量从 Netflix Zuul 对应的 Ingress 进来,会调用 SC-A 应用对应的服务,SC-A 应用内部调用 SC-B 应用的服务,SC-B 应用内部调用 SC-C 应用的服务。SC-A 有线上版本和灰度版本这两个版本。
Helm 部署 Demo
Demo 为纯开源 Spring Cloud 架构,项目地址:https://github.com/aliyun/alibabacloud-microservice-demo/tree/master/microservice-doc-demo/traffic-management。
部署完毕后,阿里云容器服务上的工作负载情况如下:
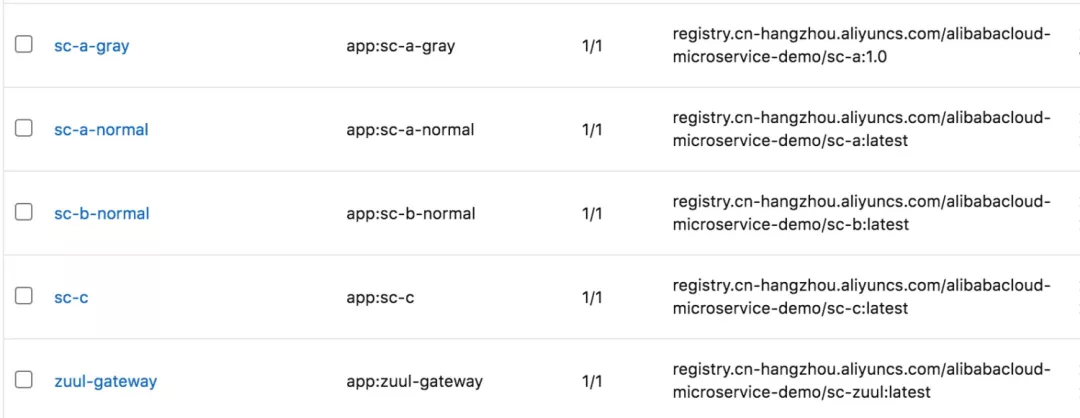
我们通过 "while true; do curl http://{ip:port}/A/a;echo;done" shell 命令不断地去访问 Spring Cloud 服务,各个服务的作用仅仅是打印当前服务的IP,这样我们可以看到整体调用链路:
while true; do curl http://{ip:port}/A/a;echo;done
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
...从这个过程我们明显可以看出 Netflix Zuul -> SC-A 这条链路是随机访问的,由于 SC-A 的线上版本和灰度版本各只有 1 个 Pod,所以随机打印了这两个 POD 的 IP。
开源金丝雀的实现
动态路由的本质就是寻址过程中去找符合条件的实例地址。
Apache Dubbo 提供了 RouterChain 的能力去过滤 Invoker 列表,RouterChain 内部维护着 Router 列表,每个 Router 都会做过滤 Invoker 的逻辑,最后将 Invoker 列表交付给 LoadBalance 做负载均衡获取最后的 Invoker。
ScriptRouter,ConditionRouter 和 TagRouter 这些内置的 Router 内部都是 Dubbo 自带的动态路由能力。
Spring Cloud 的路由能力由 Ribbon 实现。Ribbon 设计了 ILoadBalancer 接口用于获取 Server 列表,最后将这个列表交付给 IRule 做负载均衡策略获取最后的 Server。这块在设计上跟 Dubbo 相比是有缺陷的。
Spring Cloud Ribbon 里的 ILoadBalancer 相当于是 Dubbo RouterChain 里的一个 Router,IRule 相当于是 Dubbo LoadBalance。
最新版本的 Spring Cloud 新增了 Spring Cloud LoadBalancer 组件代替 Ribbon 用于做负载均衡,Spring Cloud LoadBalancer 里的 ServiceInstanceListSupplier 用于获取实例列表信息,ReactiveLoadBalancer 使用负载均衡策略获取最后的实例。
这是 3 者对应组件的说明:

Apache Dubbo 虽然内置了各种 Router,但实际使用下来却有非常多的问题。比如 TagRouter 跟 IP 绑定,在 Kubernetes 下无法工作;ScriptRouter 用了 ScriptEngine 去做脚本的处理,会有性能问题;Dubbo Admin 的使用体验非常糟糕等等。
Spring Cloud 官方并没有提供动态路由的能力,只有社区上的一些开发者自己去扩展了这个能力,社区上也没有任何的 UI 交互界面。
这时候 MSE 告诉你,MSE 的微服务解决方案提供了动态路由的能力,不需要做任何的代码和配置的修改,就能使用 OPEN API 或者 UI 交互去完成金丝雀发布。只需将您的应用接入 MSE 服务治理,您就能享受到金丝雀能力。
只要你的应用是基于 Spring Cloud 或 Dubbo 最近五年内的版本开发,就能直接使用完整的 MSE 微服务治理能力,不需要修改任何代码和配置。
无需任何代码修改就可以做到动态路由的能力,这不香吗?
MSE 金丝雀能力
应用接入 MSE 即可享受 MSE 提供的动态路由能力,无需任何代码修改。
引入标签概念
MSE 引入了标签的概念,可以针对每个标签设置路由规则,满足该路由规则的流量会路由到这个标签对应的实例下。我们将 Spring Cloud Demo 进行一点改造,给 SC-A 的灰度版本打上 "blue" 标签( Helm 已经完成了这个步骤)。
接入 MSE 后,MSE 默认会给应用分配一个 100% 路由到未打标实例的路由规则。此时,我们继续通过 "while true; do curl http://{ip:port}/A/a;echo;done" shell 命令去执行,这个时候调用 SC-A 全部返回线上版本的 IP:
while true; do curl http://{ip:port}/A/a;echo;done
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
A[10.0.0.73] -> B[10.0.0.180] -> C[10.0.0.72]
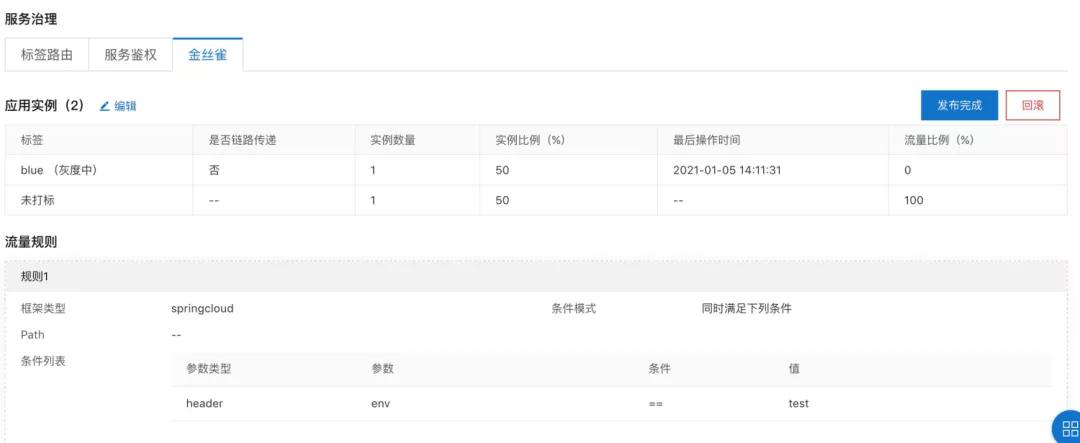
...设置金丝雀路由规则
我们在 MSE 上的应用详情页里的金丝雀 Tab 页里设置 HEADER 里 env 这个 KEY 的值为 test 的金丝雀路由条件:
传入 HEADER 继续使用 shell 执行:
while true; do curl -H "env:test" http://139.196.200.40/A/a;echo;done
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
A1[10.0.0.20] -> B[10.0.0.180] -> C[10.0.0.72]
...这个时候我们发现满足金丝雀规则的流量都去了 SC-A 的灰度版本。
金丝雀路由规则解析
大家看到金丝雀路由规则界面上有两种分别,分别是流量比例和流量规则:
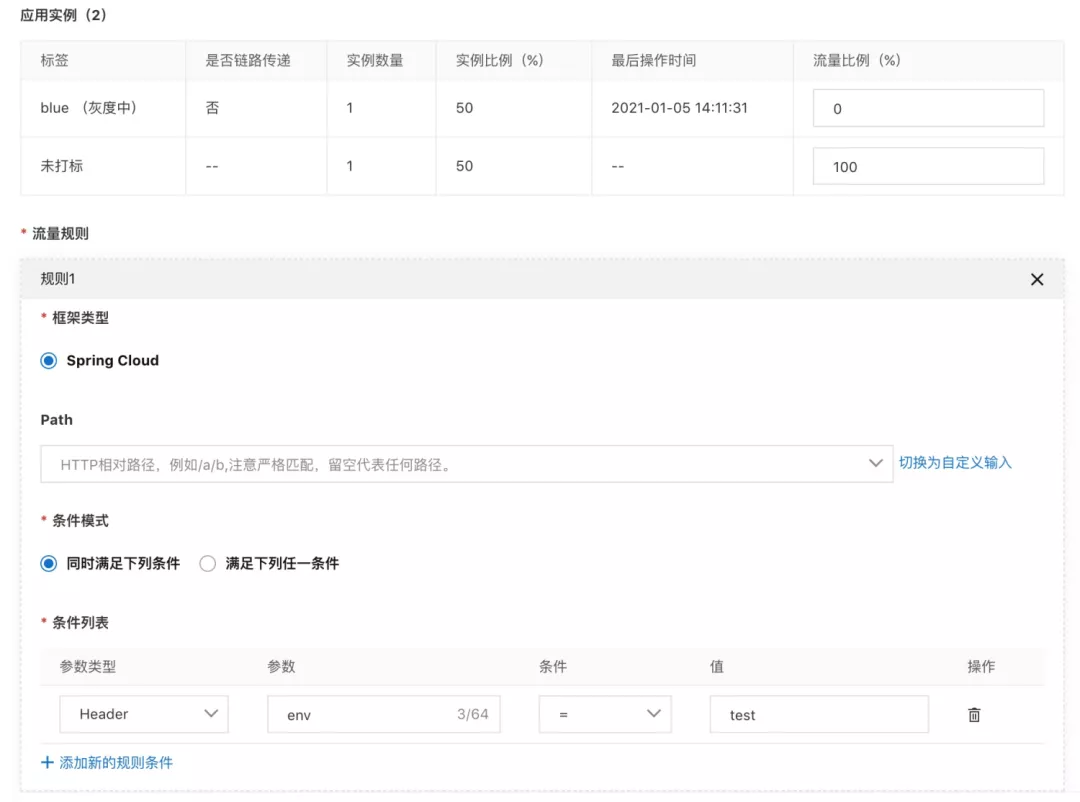
流量规则:表示满足该规则的流量会路由到对应标签(本文使用 blue 作为灰度标签)实例上。比如本文例子中 HEADER 里 env=test 的流量一定会去 blue 标签对应的实例。
流量比例:不满足任何流量规则的流量会按照流量百分比进行路由。比如本文例子中不满足 HEADER 里 env=test 的流量会以 100% 的规则路由到未打标的实例上,由于是 100%,所以那些不满足规则的流量全部都去了未打标实例上(本文未打标表示线上版本)。
MSE 提供的流量规则里的条件支持 HEADER、Query Parameter、COOKIE 以及 Request BODY。
Query Parameter、HEADER、COOKIE 和 Request Body 除了支持常规的运算符外,还支持 in(白名单),对 100 取模和百分比。这里的百分比并不是比例规则中的总流量百分比,而是指对应参数的 hash 值取模,这样就可以让固定的值永远满足路由条件(如果按照流量比例,用户 A 这次访问的是线上版本,下次可能会访问灰度版本)。举个例子,如果 HEADER 中带有用户 ID,我让想部分用户永远能够访问灰度实例,这个时候可以对用户 ID 的 hash 值取模去完成(当然,这个也可以通过白名单去操作,白名单的缺点并不随机,需要输入各个名单)。
Request Body 目前支持解析 json 字符串,比如如下字符串:
{ "a": "aa","b": [1,2,3],"c": [{"d": "dd"}],"e": {"f": "ff"}
}JSON 访问表达式 .a 的值为 aa。
JSON 访问表达式 .b[0] 的值为 1。
JSON 访问表达式 .c[0].d 的值为 dd。
JSON 访问表达式 .e.f 的值为 ff。
总结
本文介绍了微服务治理下金丝雀发布的能力,解决了发布期间少量流量验证新功能的问题。您的应用只需接入 MSE 服务治理,无需任何操作即可享受到动态路由的能力。除了 MSE(微服务引擎),金丝雀发布还被 EDAS、SAE 等云产品集成。
原文链接
本文为阿里云原创内容,未经允许不得转载。

)



)








)




