简介: DataWorks提供任务搬站功能,支持将开源调度引擎Oozie、Azkaban、Airflow的任务快速迁移至DataWorks。本文主要介绍如何将开源Airflow工作流调度引擎中的作业迁移至DataWorks上
DataWorks提供任务搬站功能,支持将开源调度引擎Oozie、Azkaban、Airflow的任务快速迁移至DataWorks。本文主要介绍如何将开源Airflow工作流调度引擎中的作业迁移至DataWorks上。
支持迁移的Airflow版本
Airflow支持迁移的版本:python >= 3.6.x airfow >=1.10.x
整体迁移流程
迁移助手支持开源工作流调度引擎到DataWorks体系的大数据开发任务迁移的基本流程如下图示。

针对不同的开源调度引擎,DataWorks迁移助手会出一个相关的任务导出方案。
整体迁移流程为:通过迁移助手调度引擎作业导出能力,将开源调度引擎中的作业导出;再将作业导出包上传至迁移助手中,通过任务类型映射,将映射后的作业导入至DataWorks中。作业导入时可设置将任务转换为MaxCompute类型作业、EMR类型作业、CDH类型作业等。
Airflow作业导出
导出原理介绍:在用户的Airflow的执行环境里面,利用Airflow的Python库加载用户在Ariflow上调度的dag folder(用户自己的dag python文件所在目录)。导出工具在内存中通过Airflow的Python库去读取dag的内部任务信息及其依赖关系,将生成的dag信息通过写入json文件导出。
具体的执行命令可进入迁移助手->任务上云->调度引擎作业导出->Airflow页面中查看。
Airflow作业导入
拿到了开源调度引擎的导出任务包后,用户可以拿这个zip包到迁移助手的迁移助手->任务上云->调度引擎作业导入页面上传导入包进行包分析。
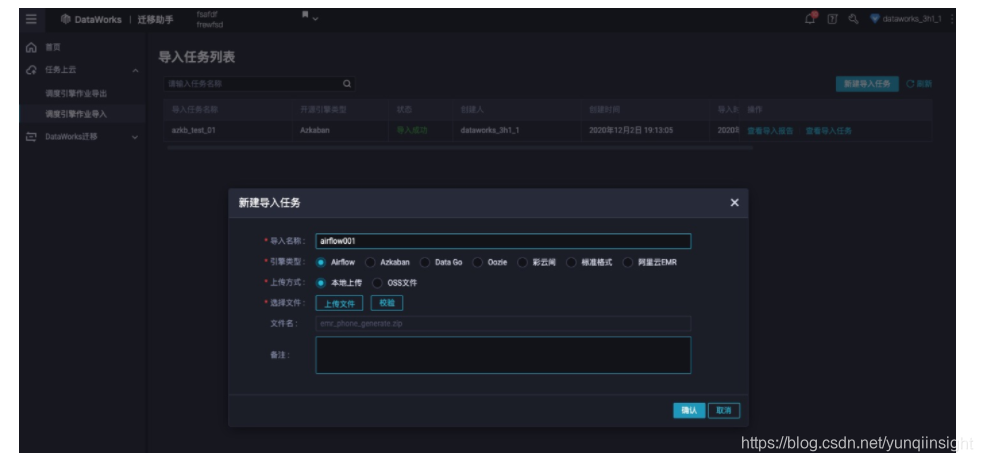
导入包分析成功后点击确认,进入导入任务设置页面,页面中会展示分析出来的调度任务信息。

开源调度导入设置
用户可以点击高级设置,设置Airflow任务与DataWorks任务的转换关系。不同的开源调度引擎,在高级设置里面的设置界面基本一致如下。

高级设置项介绍:
- sparkt-submit转换为:导入过程会去分析用户的任务是不是sparkt-submit任务,如果是的话,会将spark-submit任务转换为对应的DataWorks任务类型,比如说:ODPS_SPARK/EMR_SPARK/CDH_SPARK等
- 命令行 SQL任务转换为:开源引擎很多任务类型是命令行运行SQL,比如说hive -e, beeline -e, impala-shell等等,迁移助手会根据用户选择的目标类型做对应的转换。比如可以转换成ODPS_SQL, EMR_HIVE, EMR_IMPALA, EMR_PRESTO, CDH_HIVE, CDH_PRESTO, CDH_IMPALA等等
- 目标计算引擎类型:这个主要是影响的是Sqoop同步的目的端的数据写入配置。我们会默认将sqoop命令转换为数据集成任务。计算引擎类型决定了数据集成任务的目的端数据源使用哪个计算引擎的project。
- Shell类型转换为:SHELL类型的节点在Dataworks根据不同计算引擎会有很多种,比如EMR_SHELL,CDH_SHELL,DataWorks自己的Shell节点等等。
- 未知任务转换为:对目前迁移助手无法处理的任务,我们默认用一个任务类型去对应,用户可以选择SHELL或者虚节点VIRTUAL
- SQL节点转换为:DataWorks上的SQL节点类型也因为绑定的计算引擎的不同也有很多种。比如 EMR_HIVE,EMR_IMPALA、EMR_PRESTO,CDH_HIVE,CDH_IMPALA,CDH_PRESTO,ODPS_SQL,EMR_SPARK_SQL,CDH_SPARK_SQL等,用户可以选择转换为哪种任务类型。
注意:这些导入映射的转换值是动态变化的,和当前项目空间绑定的计算引擎有关,转换关系如下。
导入至DataWorks + MaxCompute
| 设置项 | 可选值 |
| sparkt-submit转换为 | ODPS_SPARK |
| 命令行 SQL任务转换为 | ODPS_SQL、ODPS_SPARK_SQL |
| 目标计算引擎类型 | ODPS |
| Shell类型转换为 | DIDE_SHELL |
| 未知任务转换为 | DIDE_SHELL、VIRTUAL |
| SQL节点转换为 | ODPS_SQL、ODPS_SPARK_SQL |
导入至DataWorks + EMR
| 设置项 | 可选值 |
| sparkt-submit转换为 | EMR_SPARK |
| 命令行 SQL任务转换为 | EMR_HIVE, EMR_IMPALA, EMR_PRESTO, EMR_SPARK_SQL |
| 目标计算引擎类型 | EMR |
| Shell类型转换为 | DIDE_SHELL, EMR_SHELL |
| 未知任务转换为 | DIDE_SHELL、VIRTUAL |
| SQL节点转换为 | EMR_HIVE, EMR_IMPALA, EMR_PRESTO, EMR_SPARK_SQL |
导入至DataWorks + CDH
| 设置项 | 可选值 |
| sparkt-submit转换为 | CDH_SPARK |
| 命令行 SQL任务转换为 | CDH_HIVE, CDH_IMPALA, CDH_PRESTO, CDH_SPARK_SQL |
| 目标计算引擎类型 | CDH |
| Shell类型转换为 | DIDE_SHELL |
| 未知任务转换为 | DIDE_SHELL、VIRTUAL |
| SQL节点转换为 | CDH_HIVE, CDH_IMPALA, CDH_PRESTO, CDH_SPARK_SQL |
执行导入
设置完映射关系后,点击开始导入即可。导入完成后,请进入数据开发中查看导入结果。
数据迁移
大数据集群上的数据迁移,可参考:DataWorks数据集成或MMA。
原文链接
本文为阿里云原创内容,未经允许不得转载。

、备份与恢复)

















