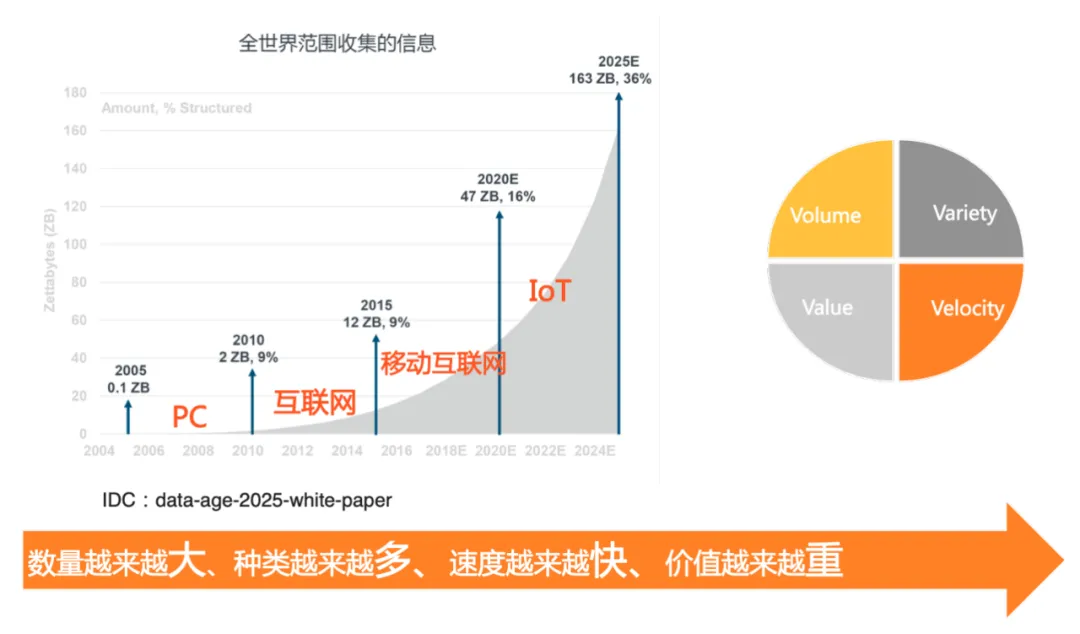
简介: 随着 IoT 技术的快速发展,物联网设备产生的数据呈爆炸式增长,数据的总量(Volume)、数据类型越来越多(Variety)、访问速度要求越来越快(Velocity)、对数据价值(Value)的挖掘越来越重视。物联网产生的数据通常都具备时间序列特征,时序数据库是当前针对物联网 IoT、工业互联网 IIoT、应用性能监控 APM 场景等垂直领域定制的数据库解决方案,本文主要分析物联网场景海量时序数据存储与处理的关键技术挑战及解决方案。

作者 | 林青
来源 | 阿里技术公众号
随着 IoT 技术的快速发展,物联网设备产生的数据呈爆炸式增长,数据的总量(Volume)、数据类型越来越多(Variety)、访问速度要求越来越快(Velocity)、对数据价值(Value)的挖掘越来越重视。物联网产生的数据通常都具备时间序列特征,时序数据库是当前针对物联网 IoT、工业互联网 IIoT、应用性能监控 APM 场景等垂直领域定制的数据库解决方案,本文主要分析物联网场景海量时序数据存储与处理的关键技术挑战及解决方案。
一 时序数据存储挑战
1 典型时序应用场景
随着 5G/IoT 技术的发展,数据呈爆炸式增长,其中物联网 (IoT) 与应用性能监控 (APM) 等是时序数据最典型的应用领域,覆盖物联网、车联网、智能家居、工业互联网、应用性能监控等常见的应用场景,海量的设备持续产生运行时指标数据,对数据的读写、存储管理都提出了很大的挑战。

2 时序数据的特征
在典型的物联网、APM 时序数据场景里,数据的产生、访问都有比较明显的规律,有很多共同的特征,相比当前互联网典型的应用特征有比较大的区别。
- 数据按时间顺序产生,一定带有时间戳,海量的物联网设备或者被监控到应用程序,按固定的周期或特定条件触发,持续不断的产生新的时序数据。
- 数据是相对结构化的,一个设备或应用,产生的指标一般以数值类型(绝大部分)、字符类型为主,并且在运行过程中,指标的数量相对固定,只有模型变更、业务升级时才会新增/减少/变更指标。
- 写多读少,极少有更新操作,无需事务能力支持,在互联网应用场景里,数据写入后,往往会被多次访问,比如典型的社交、电商场景都是如此;而在物联网、APM 场景,数据产生存储后,往往在需要做数据运营分析、监控报表、问题排查时才会去读取访问。
- 按时间段批量访问数据,用户主要关注同一个或同一类类设备在一段时间内的访问趋势,比如某个智能空调在过去1小时的平均温度,某个集群所有实例总的访问 QPS 等,需要支持对连续的时间段数据进行常用的计算,比如求和、计数、最大值、最小值、平均值等其他数学函数计算。
- 近期数据的访问远高于历史数据,访问规律明显,历史数据的价值随时间不断降低,为节省成本,通常只需要保存最近一段时间如三个月、半年的数据,需要支持高效的数据 TTL 机制,能自动批量删除历史数据,最小化对正常写入的影响。
- 数据存储量大,冷热特征明显,因此对存储成本要求比较高,需要有针对性的存储解决方案。
结合时序的特征,要满足大规模时序数据存储需求,至少面临如下的几个核心挑战:
- 高并发的写入吞吐:在一些大规模的应用性能监控、物联网场景,海量的设备持续产生时序数据,例如某省域电网用电测量数据,9000万的电表设备,原来每个月采集一次,后续业务升级后15分钟采集一次,每秒的时序数据点数达到数百万甚至千万时间点,需要数十到上百台机器的集群规模来支撑全量的业务写入;时序数据存储需要解决大规模集群的横向扩展,高性能平稳写入的需求。
- 高效的时序数据查询分析:在典型的监控场景,通常需要对长周期的数据进行查询分析,比如针对某些指标最近1天、3天、7天、1个月的趋势分析、报表等;而在物联网场景,有一类比较典型的断面查询需求,例如查询某个省指定时间所有电表的用电量量明细数据,查询某个品牌空调的某个时间的平均运行温度;这些查询都需要扫描大量的集群数据才能拿到结果,同时查询的结果集也可能非常大;时序数据存储需要支持多维时间线检索、并具备流式处理、预计算等能力,才能满足大规模 APM、IoT 业务场景的典型查询需求,并且针对时序大查询要最小化对写入的影响。
- 低成本的时序数据存储:某典型的车联网场景,仅20000辆车每小时就产生近百GB的车辆指标数据,如果要保存一年的运行数据就需要PB级的数据存储规模;由于数据规模巨大,对存储的低成本要求很高,另外时序数据的冷热特征明显。时序数据存储需要充分利用好时序数据量大、冷热访问特征明显、做好计算、存储资源的解耦,通过低成本存储介质、压缩编码、冷热分离、高效 TTL、Servereless 等技术将数据存储成本降低到极致。
- 简单便捷的生态协同:在物联网、工业互联网等场景,时序数据通常有进一步做运营分析处理的需求,在很多情况下时序数据只是业务数据的一部分,需要与其他类型的数据组合来完成查询分析;时序数据存储需要能与生态 BI 分析工具、大数据处理、流式分析系统等做好对接,与周边生态形成协同来创造业务价值。
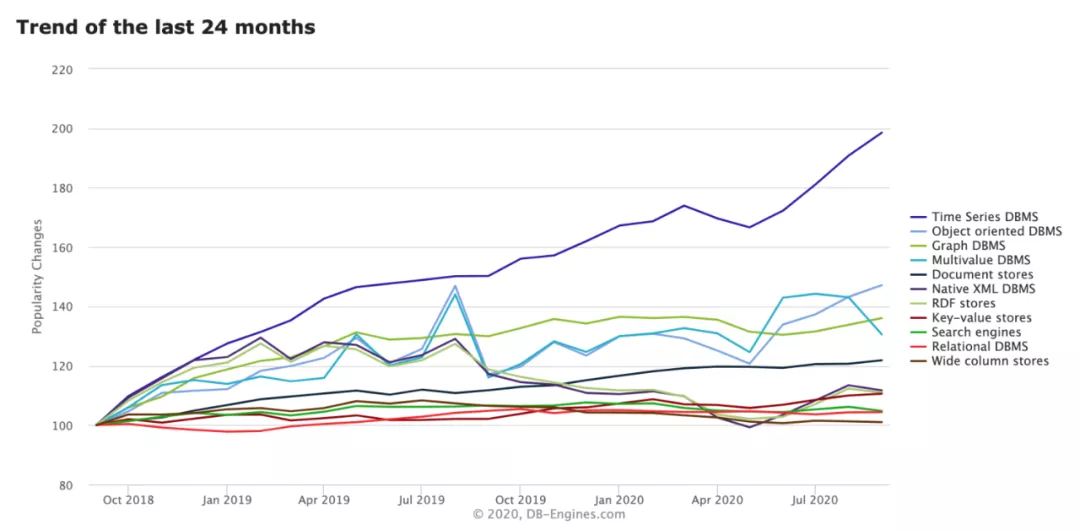
为了应对海量时序数据的存储与处理的挑战,从2014年开始,陆续有针对时序数据存储设计的数据库诞生,并且时序数据库的增长趋势持续领先,时序数据库结合时序数据的特征,尝试解决时序数据存储在高写入吞吐、横向扩展、低成本存储、数据批量过期、高效检索、简单访问与时序数据计算等方面面临的挑战。
3 业界时序数据库发展
时序数据库经过近些年的发展,大致经历了几个阶段:
- 第一阶段,以解决监控类业务需求为主,采用时间顺序组织数据,方便对数据按时间周期存储及检索,解决关系型数据库存储时序数据的部分痛点,典型的代表包括 RDDTool、Wishper(Graphite)等,这类系统处理的数据模型比较单一,单机容量受限,并且通常内嵌于监控告警解决方案。
- 第二阶段,伴随大数据和Hadoop生态的发展,时序数据量开始迅速增长,业务对于时序数据存储处理扩展性方面提出更高的要求。基于通用可扩展的分布式存储专门构建的时间序列数据库开始出现,典型的代表包括 OpenTSDB(底层使用 HBase)、KairosDB(底层使用 Cassandra)等,利用底层分布式存储可扩展的优势,在 KV 模型上构建定制的时序模型,支持海量时序的倒排检索与存储能力。这类数据库的数据存储本质仍然是通用的 KV 存储,在时序数据的检索、存储压缩效率上都无法做到极致,在时序数据的处理支持上也相对较弱。
- 第三阶段,随着 Docker、Kubernetes、微服务、IoT 等技术的发展,时间序列数据成为增长最快的数据类型之一,针对时序数据高性能、低成本的存储需求日益旺盛,针对时序数据定制存储的数据库开始出现,典型的以InfluxDB 为代表,InfluxDB 的 TSM 存储引擎针对时序数据定制,支持海量时间线的检索能力,同时针对时序数据进行压缩降低存储成本,并支持大量面向时序的窗口计算函数,InfluxDB 目前也是 DB Engine Rank 排名第一的时序数据库。InfluxDB 仅开源了单机版本,高可用集群版仅在企业版和云服务的版本里提供。
- 第四阶段,随着云计算的高速发展,云上时序数据库服务逐步诞生,阿里云早在2017年就推出了 TSDB 云服务,随后 Amazon、Azure 推出 Amazon TimeStream、Azure Timeseires Insight 服务,InfluxData 也逐步往云上转型,推出 InfluxDB 云服务;时序数据库云服务可以与云上其他的基础设施形成更好的协同,云数据库已是不可逆的发展趋势。
二 Lindorm TSDB 背后的技术思考
1 Lindorm 云原生多模数据库
为了迎接 5g/IoT 时代的数据存储挑战,阿里云推出云原生多模数据库 Lindorm ,致力于解决海量多类型低成本存储与处理问题,让海量数据存得起、看得见。

Lindorm 支持宽表、时序、搜索、文件等多种模型,满足多类型数据统一存储需求,广泛应用于物联网、车联网、广告、社交、应用监控、游戏、风控等场景。其中 Lindorm TSDB 时序引擎提供高效读写性能、低成本数据存储、时序数据聚合、插值、预测等计算能力,主要应用于物联网(IoT)、工业互联网(IIoT)、应用性能监控(APM)等场景。
2 Lindorm TSDB 核心设计理念
Lindorm TSDB 做为下一代时序数据库,在架构升级过程中,我们认为时序数据库的发展会有如下趋势:
- 多模融合:未来时序数据库与通用KV数据库、关系型数据库等的配合联系会越来越紧密,例如在物联网场景,设备元数据的存储、运行时数据的存储、业务类数据的存储通常会使用不同的数据模型来存储。
- 云原生:随着云计算的发展,未来时序数据库的存储要基于云原生技术,充分利用云上的基础设施,形成相互依赖或协同,进一步构建出时序存储的竞争力。
- 时序原生:未来时序数据库的存储引擎是针对时序数据高度定制化的,保证高效的时序多维检索能力,高写入吞吐及高压缩率,支持冷热数据自动化管理。
- 分布式弹性:未来时序数据库要具备分布式扩展的能力,应对大规模的时序数据库存储,在时序的典型应用场景,例如物联网、工业电网、监控、都有海量设备数据写入和存储的需求,必须要做到弹性扩展,通过分布式、Serverless 等技术实现规模从小到大的弹性伸缩。
- 时序 SQL:未来时序数据库的访问要支持标准 SQL(or SQL Like 表达方式),一方面使用上更加便捷,降低数据库的使用门槛,同时也能基于 SQL 提供更加强大并有时序特色的计算能力。
- 云边一体:未来时序数据库在边缘设备端不再是孤立的数据存储,边缘侧会不断加深与云端协同,形成一体化的时序存储解决方案。
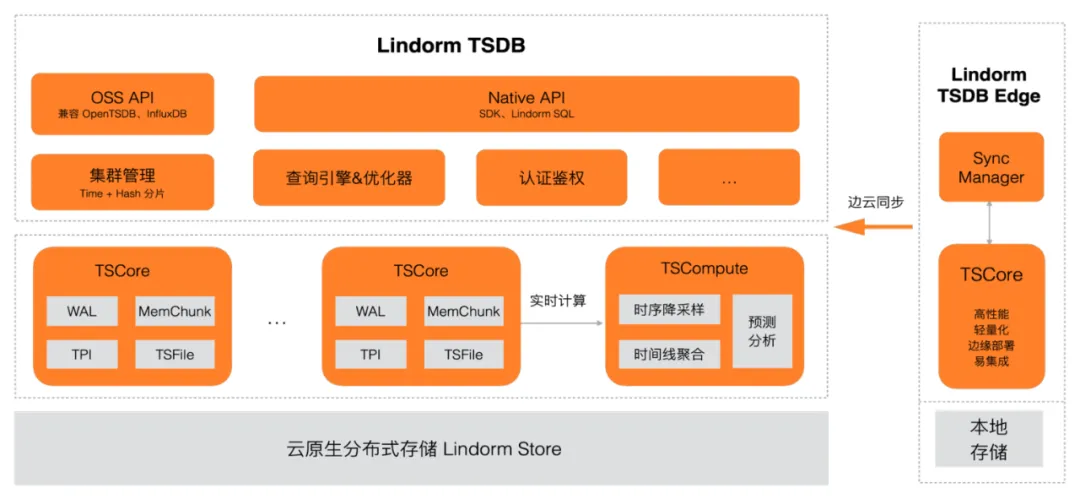
基于以上判断,我们构建了云原生多模数据库 Lindorm,支持宽表、时序、搜索、文件等多种常用模型,解决物联网/互联网海量数据存储的常见需求,其中 Lindorm TSDB 采用计算存储分离的架构,充分利用云原生存储基础设施,定制时序存储引擎,相比业界的解决方案更具竞争力。
- 多模融合、统一存储:Lindorm TSDB 引擎与宽表、搜索、文件等形成配合,解决用户多类型数据的统一存储处理需求。
- 云原生低成本存储,计算存储分离:Lindorm TSDB 引擎基于云原生分布式存储平 LindormStore,提供高可靠的数据存储,并支持弹性扩展,提供标准型、性能型、容量型等多种存储形态,满足不同场景的需求,同时支持冷热数据一体化管理的能力。
- 时序定制存储引擎:Lindorm TSDB 引擎针对时序数据的特征,定制基于 LSM Tree 结构的时序引擎,在日志写入、内存组织结构、时序数据存储结构以及 Compaction 策略上都针对时序特征优化,保证极高的写入吞吐能力。在引擎内部支持内置的预处理计算引擎,支持对时序数据进行预降采样、预聚合,来优化查询效率。
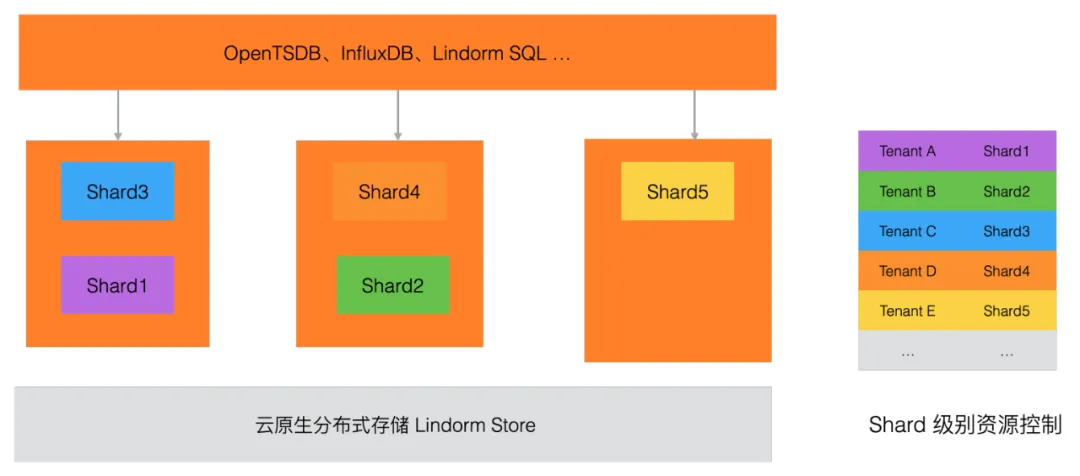
- 多维数据分片、弹性伸缩:Lindorm TSDB 引擎支持横向扩展,通过对时间线进行 Hash 分片,将海量时间线数据分散到多个节点存储;在节点内部,支持按时间维度进一步切分,支持集群的无缝扩容,同时也能解决云原生监控场景时间线膨胀的问题;通过 Serverless 形态实现任意规模的弹性伸缩。
- 定制时序 SQL 查询:Lindorm TSDB 引擎提供时序 SQL 访问能力,针对时序场景定制特色计算算子,用户学习、使用成本低。
- 边云同步一体化:Lindorm TSDB 引擎提供轻量级边缘部署的版本,解决边缘时序存储需求,并支持边缘侧数据与云端无缝同步,以便充分利用云上基础设施来进一步挖掘数据价值。
三 Lindorm TSDB 关键技术
1 时序定制存储引擎
Lindorm 基于存储计算分离架构设计,以适应云计算时代资源解耦和弹性伸缩的诉求,其中云原生存储分布式存储 Lindorm Store 为统一的存储底座,向上构建各个垂直专用的多模引擎,包括宽表引擎、时序引擎、搜索引擎、文件引擎。LindormStore 是面向公共云基础存储设施(如云盘、DBFS、OSS) 设计、兼容 HDFS 协议的分布式存储系统,并同时支持运行在本地盘环境,以满足部分专有云、专属大客户的需求,向多模引擎和外部计算系统提供统一的、与环境无关的标准接口。
基于云原生分布式存储 LindomStore,Lindorm TSDB 采用针对写入优化的 LSM Tree 结构来存储时序数据,并结合时序数据的特征,在日志写入、内存组织结构、时序数据存储结构进行时序压缩,最大化内存利用效率、磁盘存储效率;同时在 Compaction 策略上也针对数据通常有序产生的特征进行优化。通过引擎自带的 WAL 日志,Lindorm TSDB 能非常方便的支持实时的数据订阅,以及在引擎内部对数据进行针对性的降采样、聚合等预处理操作。
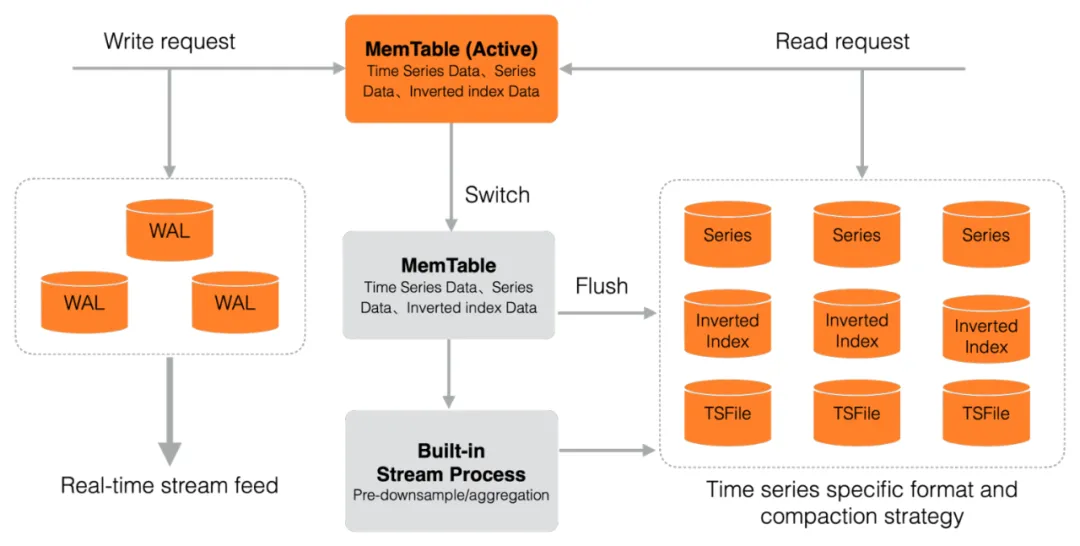
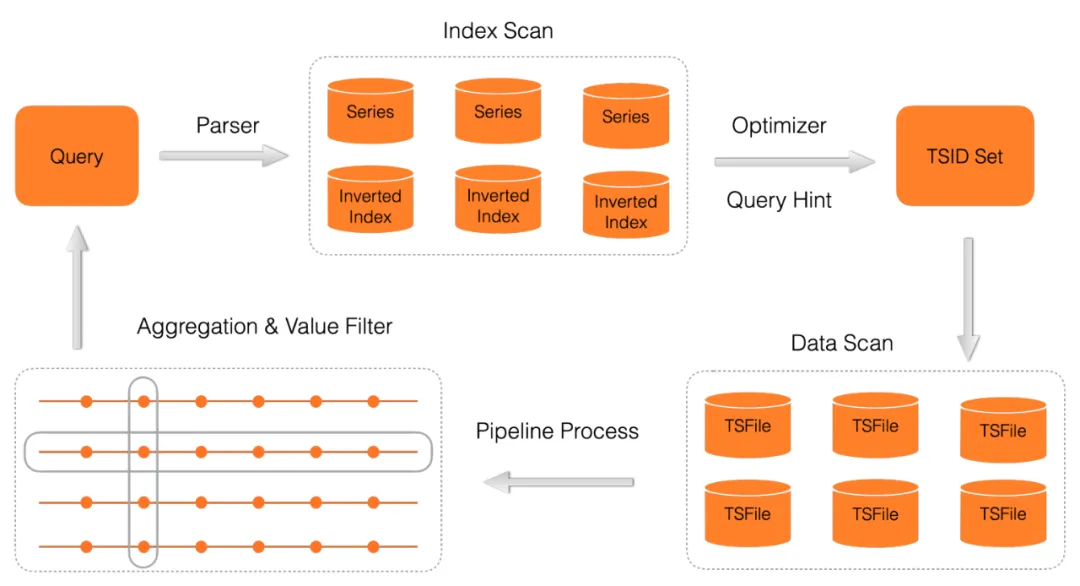
Lindorm TSDB 针对时序数据的查询,支持丰富的处理算子,包括降采样、聚合、插值、过滤等。用户的查询请求经过 Parser 解析后,通常分为多个主要的处理阶段,以 Pipeline 的形式高效处理。
- Index Scan:根据用户指定的查询条件,基于正排索引 + 倒排索引找出所有满足条件的时间线 ID 集合。
- Data Scan:基于第1阶段找出的时间线 ID,从 TSFile 读取对应时间范围的数据。
- Aggregation/Filter: 针对第2阶段的扫描结果,对时间线数据进一步的处理,包括在一条时间线上对数据按一定周期进行降采样,或对多条时间线相同时间点上的数据进行聚合(sum、count、avg、min、max等)操作等。
2 分布式弹性
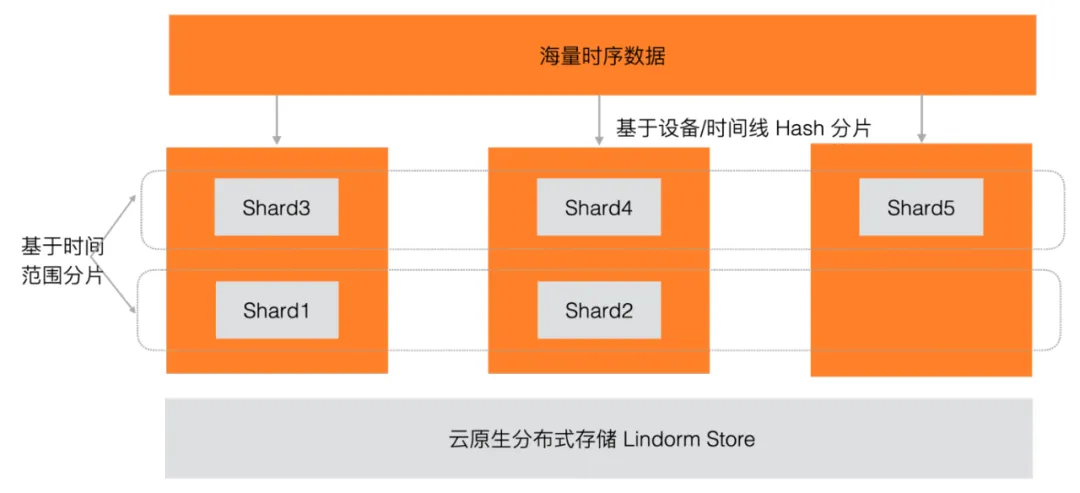
Lindorm TSDB 具备横向扩展的能力,海量的时间线数据会被分散存储到多个 Shard 中,Shard 是集群中独立的数据管理单元,Shard 内部是一个自治管理的 LSM Tree 存储引擎(参考2.2),包含单独的 WAL、TPI、TSFile 等文件。
在水平方向,时间序列数据会根据 metric + tags 组成的时间线标识,采用 Hash 分片的策略,将数据分到多个节点;在垂直方向(时间轴维度),分到同一个节点的数据,可按照时间维度进行切分,这样每个 Shard 就负责一部分时间线在一定时间范围内的数据管理。
水平方向的分片能保证集群的负载均分到各个节点,后续还会结合业务特征,支持业务自定义的分片策略,优化读写效率;垂直方向(按时间范围)的分片,对于膨胀型时间线场景(比如云原生监控的场景,容器频繁上下线导致大量老时间线的消亡,新时间线的创建)非常有帮助,同时在集群扩容时,也可以借助时间分片策略来尽可能的减小对写入的影响。
3 TSQL 时序查询
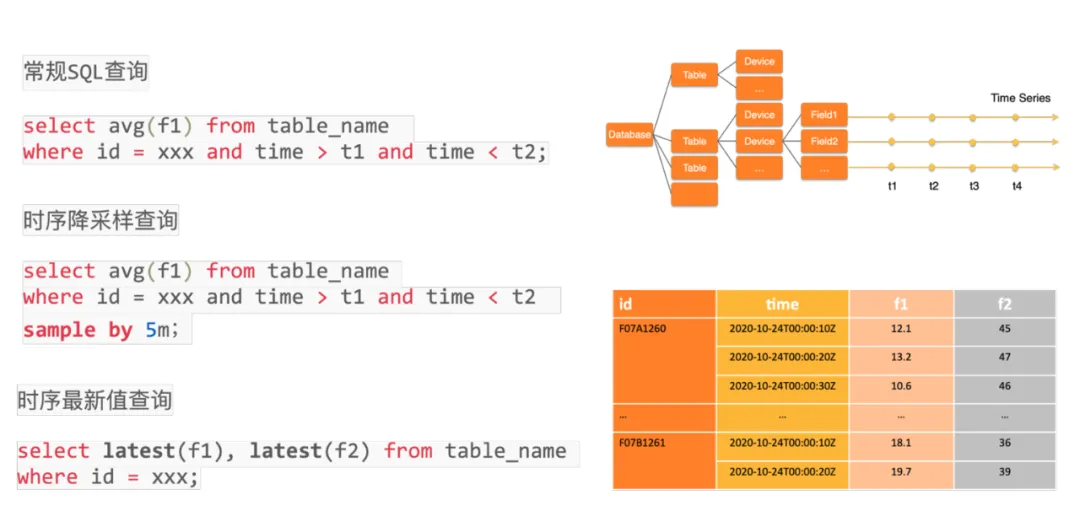
Lindorm TSDB 提供 SQL 访问能力,Lindorm TSDB 的数据模型针对物联网场景高度优化定制,概念上尽量保留开发者对数据库的普遍理解,一个实例包含多个数据库,一个数据库包含多张表,表里存储多个设备的时序数据,每个设备包含一组用于描述设备的 Tag、设备包含多个 Field 指标,新的指标数据随时间持续不断的产生。除了支持常规的 SQL 基础能力,Lindorm TSDB 还定制了 sample by、latest 等算子,用于方便的表达时序降采样、时序聚合、最新点查询等常见的时序操作,简化使用的同时,增强了时序 SQL 的表达能力,让用户使用时序数据库更加简单、高效。
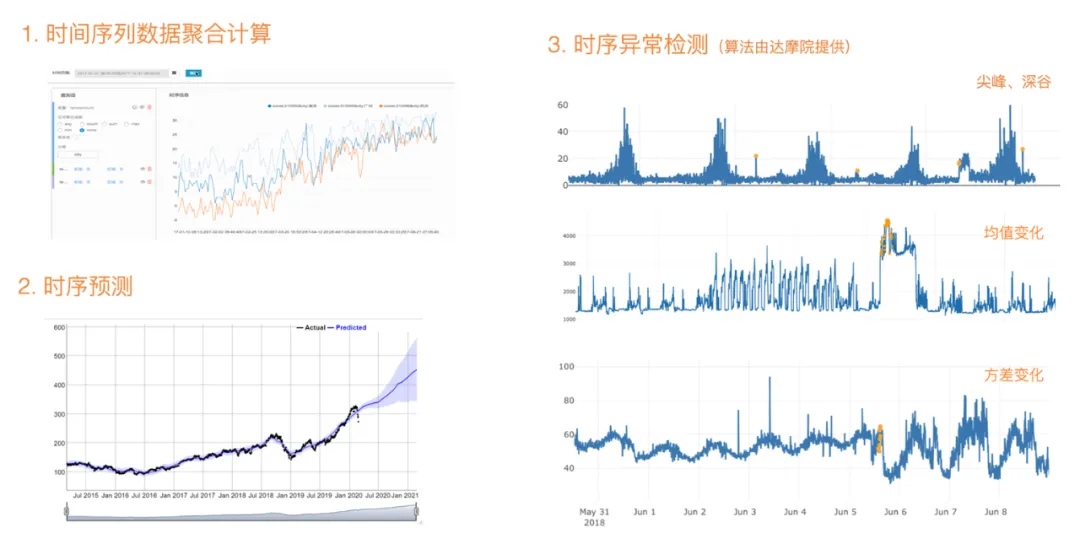
基于 TSQL 查询接口,Lindorm TSDB 还能针对时序数据进行一系列的拓展分析,包括时序数据预测、异常检测等,让应用能更好的发挥时序数据价值。
4 Serverless
Lindorm TSDB 通过时序定制的存储引擎、结合分布式扩展的能力,能很好的满足大规模时序场景的业务需求。但对于一些业务访问较小的应用场景起步成本相对较高,例如在平台级的应用监控、IoT 场景,平台需要管理大量用户的时序数据,而大部分用户的数据规模初期都相对较小,为了进一步降低用户的使用成本,适应从小到大任意规模的时序存储需求,更好的赋能上层的应用监控、物联网类 SaaS 平台服务,未来 Lindorm 将会沿着多租户 Serverless 服务模式持续演进,提升弹性能力。
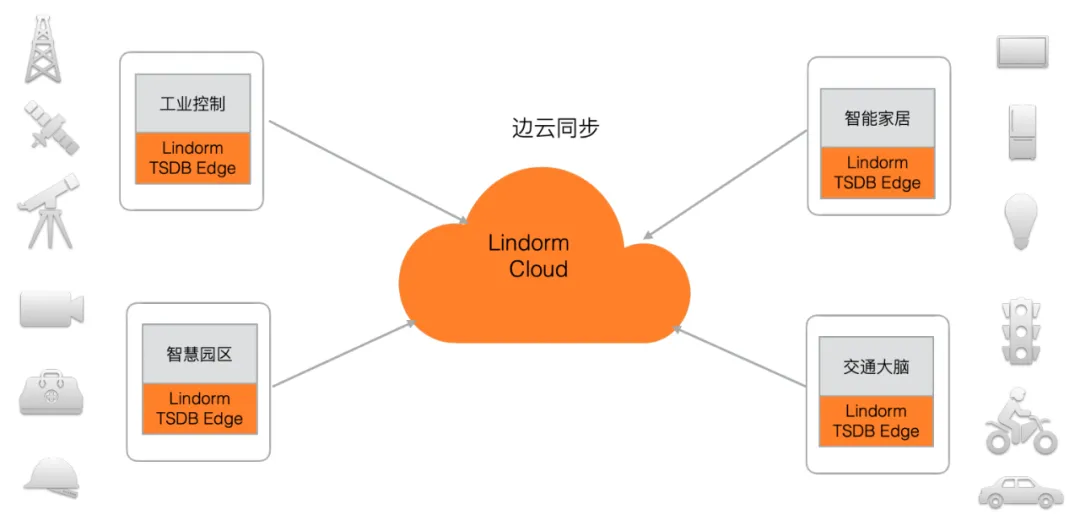
5 边云同步
随着 IoT 技术的发展,边缘计算需求日益明显,在智能家居、工业工控、智慧园区、交通大脑等场景,考虑到网络带宽成本等原因,数据通常需要先就近本地存储,并周期性的同步到云端进行进一步分析处理。为了方便边缘侧的部署,Lindorm TSDB 支持边缘轻量级部署的版本,并支持数据全量、增量同步到云端,形成边云一体化的解决方案。
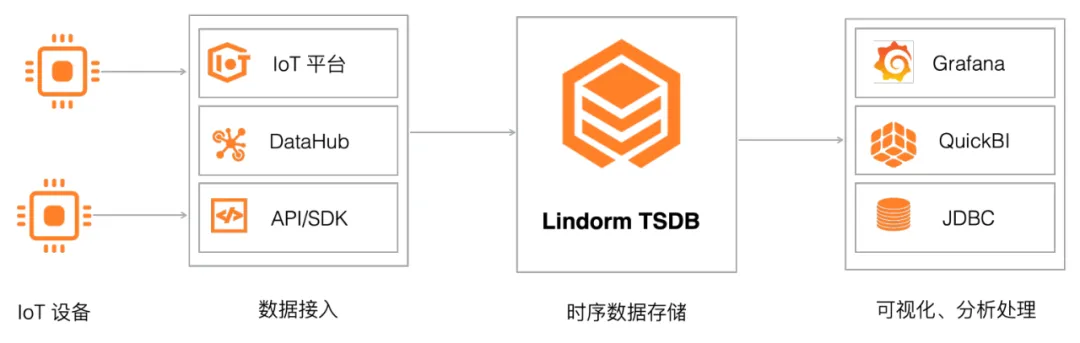
四 时序存储解决方案
1 物联网设备数据存储
Lindorm TSDB 是物联网设备运行数据存储的最佳选择,无缝与阿里云 IoT 平台、DataHub、Flink 等进行连接,极大的简化物联网应用开发流程。例如通过 Lindorm TSDB,你可以收集并存储智能设备的运行指标,通过自带的聚合计算引擎或BI类工具进行智能分析,深入了解设备运行状态。
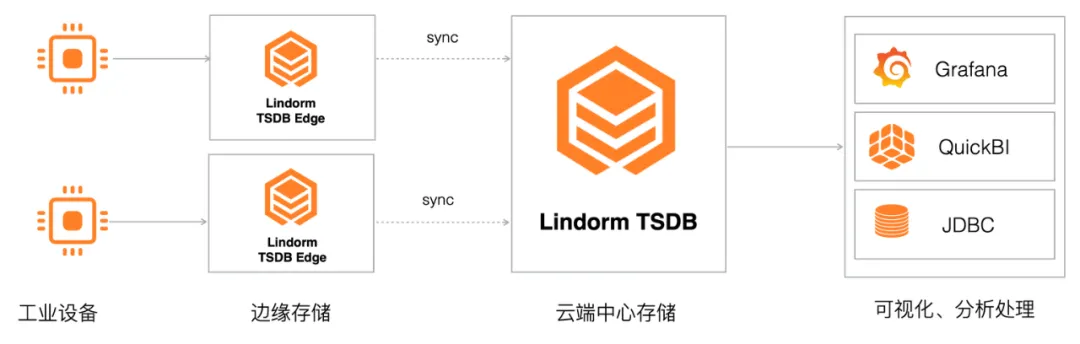
2 工业边缘时序存储
Lindorm TSDB 边缘版非常适合工业互联网场景,在边缘侧轻量化输出,与工业设备就近部署,同时支持将数据同步到 Lindorm 云端。例如通过 Lindorm TSDB,你可以实时采集工业生产线设备的运行指标,对产线的运行状况进行分析及可视化,从而优化产线运行效能。
3 应用监控数据存储
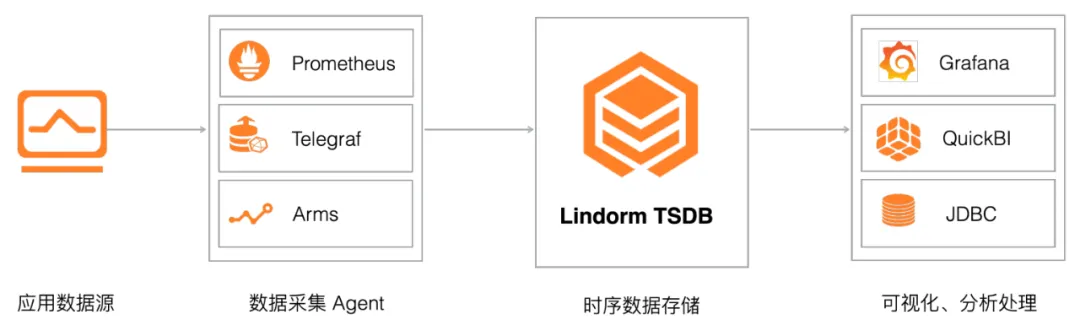
Lindorm TSDB 非常适合应用监控数据存储,无缝对接 Prometheus、Telegraf、ARMS 等监控生态,提供针对监控指标的高效读写与存储,同时提供聚合分析、插值计算等能力。例如通过 Lindorm TSDB,你可以收集应用程序的 CPU、内存、磁盘等指标的使用情况,并进行分析及可视化,实时监测应用运行情况。
五 总结
从互联网&大数据时代的分布式,到云计算、5G/IoT时代的云原生多模,业务驱动是Lindorm不变的演进原则。面对资源按需弹性和数据多样化处理的新时代需求,Lindorm以统一存储、统一查询、多模引擎的架构进行全新升级,并借助云基础设施红利,重点发挥云原生弹性、多模融合处理、极致性价比、企业级稳定性的优势能力,全力承载好经济体内部和企业客户的海量数据存储处理需求。
Lindorm TSDB 时序引擎面向物联网、工业互联网、应用性能监控等领域的时序数据存储需求,全面拥抱云原生,并充分利用云原生基础设施,定制时序存储引擎,构建海量低成本的时序数据存储与处理能力,提供边云一体化的时序存储解决方案。未来 Lindorm 引擎将继续在弹性伸缩、低成本海量存储、多模融合、时序流计算等方向持续突破,构建万物互联的数据底座。
原文链接
本文为阿里云原创内容,未经允许不得转载。



配合开启OSS防盗链功能)





![java 判断日期连续_如何在Java中检查日期是否大于另一个日期?[重复]](http://pic.xiahunao.cn/java 判断日期连续_如何在Java中检查日期是否大于另一个日期?[重复])






![python socket能做什么_[python]初探socket](http://pic.xiahunao.cn/python socket能做什么_[python]初探socket)


