ML工作流的痛点

机器学习工作流中存在诸多痛点:
- 首先,很难对机器学习的实验进行追踪。机器学习算法中有大量可配置参数,在做机器学习实验时,很难追踪到哪些参数、哪个版本的代码以及哪个版本的数据会产生特定的结果。
- 其次,机器学习实验的结果难以复现。没有标准的方式来打包环境,即使是相同的代码、相同的参数以及相同的数据,也很难复现实验结果。因为实验结果还取决于采用的代码库。
- 最后,没有标准的方式管理模型的生命周期。算法团队通常会创建大量模型,而这些模型需要中央平台进行管理,特别是模型的版本所处阶段和注释等元数据信息,以及版本的模型是由哪些代码、哪些数据、哪些参数产生,模型的性能指标如何。也没有统一的方式来部署这些模型。
MIflow 就是为了解决机器学习工作流中的上述痛点问题而生。它可以通过简单的 API 实现实验参数追踪、环境打包、模型管理以及模型部署整个流程。
MIflow的第一个核心功能: MIflow Tracking。

它可以追踪基于学习的实验参数、模型的性能指标以及模型的各种文件。在做机器学习时实验时,通常需要记录一些参数配置以及模型的性能指标,而 MIflow 可以帮助用户免去手动记录的操作。它不仅能记录参数,还能记录任意文件,包括模型、图片、源码等。
从上图左侧代码可以看到,使用 MIflow的 start_run可以开启一次实验;使用 log_param 可以记录模型的参数配置;使用log_metric 可以记录下模型的性能指标,包括标量的性能指标和向量的性能指标;使用 log_model 可以记录下训练好的模型;使用 log_artifact 可以记录下任何想要记录的文件,比如上图中记录下的就是源码。
MIflow的第二个核心功能:MIflow Project 。

它会基于代码规约来打包训练代码,并指定执行环境、执行入口以及参数等信息,以便复现实验结果。而且这种规范的打包方式能够更方便代码的共享以及平台的迁移。
如上图, miflow-training 项目里包含两个很重要的文件,分别是 content.yaml 和 MLproject。content.yaml 文件中指定了 project 的运行环境,包含它所有依赖的代码库以及这些代码库的版本;MLproject 里指定了运行的环境,此处为conda.yaml,指定了运行的入口,即如何将 project 运行起来,入口信息里面包含了相应的运行参数,此处为 alpha 和 l1_ratio 两个参数。
除此之外,MIflow 还提供了命令行工具,使得用户能够方便地运行 MIflow project 。比如打包好project 并将其上传到 git 仓库里了,用户只需要通过 mIflow run 指令即可执行project ,通过 -P 传入 alpha 参数。
MIflow 的第三个核心功能: MIflow Models。
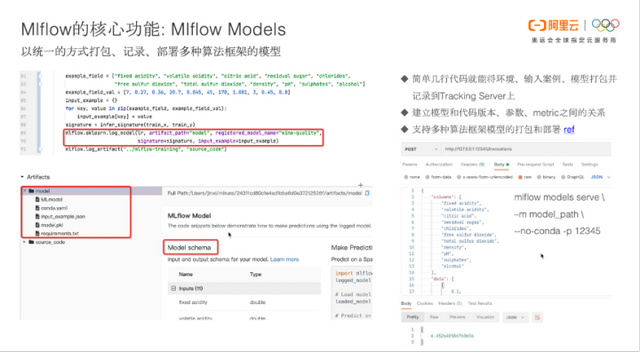
它支持以统一的方式打包记录和部署多种算法框架模型。训练完模型后,可以使用 MIflow 的 log_model将模型记录下来,MIflow 会自动将模型进行存储(可存储到本地或 OSS 上),而后即可在 MIflow WebUI 上查看模型与代码版本、参数和metric 之间的关系,以及模型的存储路径。
此外,MIflow 还提供了 API 用于部署模型。使用 mIflow models serve 部署模型后,即可使用 rest API 调用模型,得到预测的结果。
MIflow 的第四个核心功能: MIflow Registry。
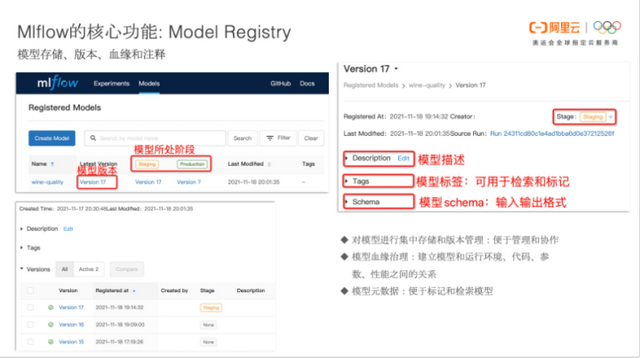
MIflow 不但能够存储模型,还提供了 WebUI 以管理模型。WebUI 界面上展示了模型的版本和所处的阶段,模型的详情页显示了模型的描述、标签以及schema。其中模型的标签可以用于检索和标记模型,模型的schema 用于表示模型输入和输出的格式。此外,MIflow 还建立了模型以及运行环境、代码和参数之间的关系,即模型的血缘。
MIflow 的四个核心功能很好地解决了机器学习工作流中的痛点,总结起来可以分为三个方面:
- MIflow Tracking 解决了机器学习实验难以追踪的问题。
- MIflow Project解决了机器学习工作流中没有标准的方式来打包环境导致实验结果难以复现的问题。
- MIflow Models 和Model Registry 解决了没有标准的方式来管理模型生命周期的问题。
Demo演示
接下来介绍如何使用 MIflow 和 DDI 搭建机器学习平台以管理机器学习的生命周期。

在架构图中可以看到,主要的组件有 DDI 集群、OSS和 ECS 。DDI 集群负责做一些机器学习的训练,需要启动一台 ECS 来搭建 MIflow 的tracking server 以提供 UI 界面。此外还需要在 ECS 上安装 MySQL 以存储训练参数、性能和标签等元数据。OSS 用于存储训练的数据以及模型源码等。
部署要点请观看演示视频:
https://developer.aliyun.com/live/248988
作者:李锦桂 阿里云开源大数据平台开发工程师
原文链接
本文为阿里云原创内容,未经允许不得转载。



















