实时离线一体化概述
在讲实时离线一体化概述前,可以先回顾一下之前两位阿里同学的精彩演讲。 离线实时一体化数仓与湖仓一体--云原生大数据平台的持续演讲
https://developer.aliyun.com/article/804337
云原生离线实时一体化数仓建设与实践:
https://developer.aliyun.com/article/871926
当前从第一代离线数仓发展到第二代实时数仓,再到第三代实时离线一体化数仓,演进过程和价值可以参考上述两篇文章,今天分享的主要内容是实时离线一体化数仓的新能力。
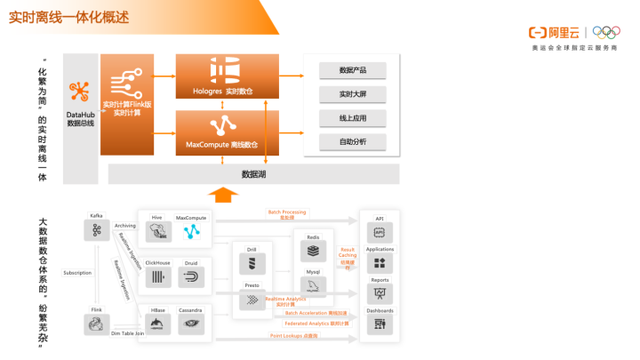
大数据数仓体系从“纷繁芜杂”的一个架构演进到“化繁为简”的实时离线一体化数仓,其核心是基于流式计算引擎对接了 MaxCompute + Hologres离线及实时数仓,并通过互通实现数据的分层处理 。当前这套架构适用于海量数据的数据治理、离线分析、实时分析、数仓集市、多模分析、机器学习在线模型等场景,帮助客户构建一站式的大数据分析平台,释放企业数据价值。
当前解决方案适用场景有数据实时分析+数据离线分析的业务,海量数据计算+分析实时性要求较高的业务。,海量数据分析、点查。多源、多样、流量数据+业务数据的分析服务业务。在实际业务中,如果有对时效性要求比较低的,不需要用到实时分析,还是使用 MaxCompute 离线数仓为解决方案。如果业务场景中,类似在线告警、在线预测等,可以理解为整体链路没有用到离线数据跟实时数据的一个结合。那就是典型的解决方案,比如实时计算Flink+Hologres做为实时性比较高的实时数仓解决方案。
实时离线一体化,主要侧重强调适配于有离线业务和实时在线业务混合的综合应用场景,这样可以解决多元多样流量数据跟业务数据的一个分析服务业务。
实时离线一体化优势
从数据写入来看呢,有实时数据和离线数据,流式数据都可以支持。MaxCompute 在数据写入侧的特点是支持高QPS写入后,即可见即可查。从数据写入的通道来看呢,当前实时离线一体化支持批量数据通道、流式数据通道、实时数据通道。以及在数据写入之前比如kafka、Flink这种中间插件的支持,从一个数据源,从消息服务中间件,把数据写入到 MaxCompute 中间零代码开发,可以直接用 MaxCompute 支持的插件来做。Hologres本身支持高性能写入和实时写入更新,以及写入 即可查的能力,MaxCompute+Hologres相结合,覆盖了批量数据写入、流式数据写入、实时数据写入以及写入即可查的产品支持。
数据计算是多引擎支持,基于 MaxCompute 支持EB量级数据计算,在 MaxCompute 本身计算引擎内支持spark、MR、SQL。数据写入后,MaxCompute支持用 spark 流式处理,也可以用 MaxCompute SQL批处理。多引擎支持下实时计算延迟到秒级乃至毫秒级,单个作业吞吐量可达到百万级。
在数据共享互通方面,是做到了MaxCompute&Hologres的数据互通,存储直读打通,可以从Hologres直读 MaxCompute 的数据,从 MaxCompute 到Hologres,当前上线的功能是通过外表去读取,直读的功能很快也会上线。这样一个优势,可以做到同一份数据,用一个实时引擎一个离线引擎做处理,能够实现数据不移动的情况下,可以在离线数仓处理完,在实时数仓做汇总,或者是从实时数仓读实时数据,结合离线数据去做融合数据计算跟分析。
在分析服务一体化优势方面,这里本身有一个很大的特点是,MaxCompute 本身支持数据的交互式查询是秒级别的,因为MaxCompute提供了查询加速的一个能力,满足的场景就是 秒级查询,如果实时性要求更高如亚秒级毫秒级,可以直接在分析层应用对接到Hologres,支持PB量级亚秒级交互式分析。
实时离线一体产品新能力解读
把实时离线一体化架构优点拆分到整个数仓开发链路里面,对应到一些产品能力。数仓的开发过程是从数据源->数据写入->数据清洗->业务级聚合->数据分析&服务->AI&Reporting。在数据分析服务或者是一些在线应用场景里面,有第三方也有自用的产品应用封装,以及一些AI场景的在线分析服务,这时可以对接到数据分析服务的一个接口,也可以对接到MaxCompute数仓里面的数据,或者是oss的数据,可以根据自身业务场景来决定。
在数据源,我们支持第三方插件,如Kafka Connector,Logstash Connector,Flink Connector。数据写入层,支持批量数据通道、流式数据通道:行文件支持自动merge、实时数据通道。很快会提供基于数据写入的独享资源,也就是商业化资源,目前写入的计算资源是公共集群,免费提供,对于大业务量需求时,可能会出现延迟。不久会发布upsert能力,可以把业务库如rds数据实时更新到MaxCompute。
从数据清洗来看,数据在写入MaxCompute过程中,支持update和delete能力,在这个过程中也在业务聚合这一层做了物化视图和渐进计算,以及规划中的自动化物化视图。在数据分析服务这一层,MaxCompute 提供了查询加速能力,在后付费过程无感知查询加速能力,以及在邀测过程中的预付费独享资源MCQA的查询。之前发布了针对预付费查询加速免费额度的一个能力,每天每个project有500次单个SQL10G 以下的查询额度。后续针对数据服务的一个对接,以及第三方应用的对接,如果用户是预付费,基于已购资源切分出一个资源组,作为独立查询加速资源,来满足包年包月用户。如果对数据分析服务有更高的交互式详细要求,可以对接Hologres。
在Hologres这一侧,我们通过 MaxCompute 到 Hologres 的外表支持以及 Hologres 到 MaxCompute 存储直读,来实现数据的互通。后续的规划能力,我们会做一个元数据打通,以及 MaxCompute 到 Hologres 的直读能力。在上层BI报表分析过程当中,做了生态的一些接入,如网易有数、观远BI、自主分析、在线服务有AI的在线模型,在线训练会直接对接到MaxCompute数仓数据。
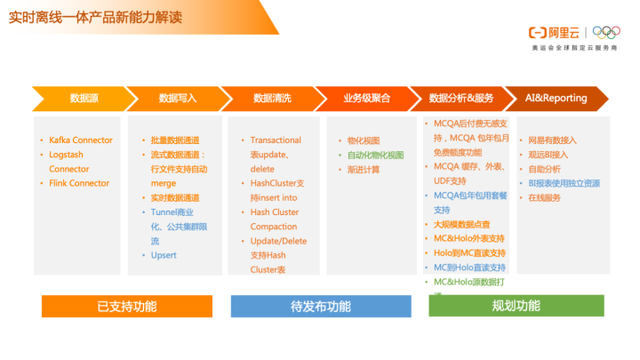
实时离线一体产品新能力渐进计算
渐进计算从概念上来看,是一种能够通过处理增量数据并维护中间状态来完成计算的形式,处于传统流计算和批处理之间。可以看到下图,有一张交易表,是在某一个日期比如十二点一点到两点,每一个时间点都有交易数据。也就是说,通过渐进计算,可以把每一个小时汇总的交易订单金额和交易订单,完成小时级别的统计,汇总到每个小时生产的单独文件,也就是说,渐进计算会自动把交易明细数据,做一个轻度的汇总。这样查数据时,就不需要去统计一个小时或者几个小时的数据,我们可以通过渐进计算完成轻度汇总之后,直接去查统计好的数据。这个示例可以表明,交易订单数据也可以实时或者近实时写入MaxCompute中,也可以实时写入到Hologres。可以根据业务需求来做,比如写入进Hologres,相当于从订单数据到Hologres中,可以在流式链路里面做实时计算去完成小时级别的窗口统计数据,去做轻度汇总。如果写入MaxCompute,可以通过渐进计算完成小时级别的轻度汇总统计。在这个过程中,做到了实时数据实时写入,以及近实时的轻度汇总和上层的聚会,可以对数据分析服务提供数据的查询能力。
渐进计算的用途和优势在于,可以根据数据按窗口周期存储,对查询最近的数据时,可以减少计算,节省计算资源的同时,提高计算效率。每次去访问时,不用去查明细表,可以直接去查轻度汇总数据,这样无论是速度还是体验都有一个巨大的提升。比如从交易订单的数据,通过datahub流式写入到MaxCompute,在MaxCompute中完成渐进计算的轻度汇总,以及后续的数据消费,这一套链路是近实时的。另外一条链路是,datahub通过Flink去消费,由Flink完成各种统计,以及其他维度的计算,再写入到Hologres来提供消费服务的一个能力。
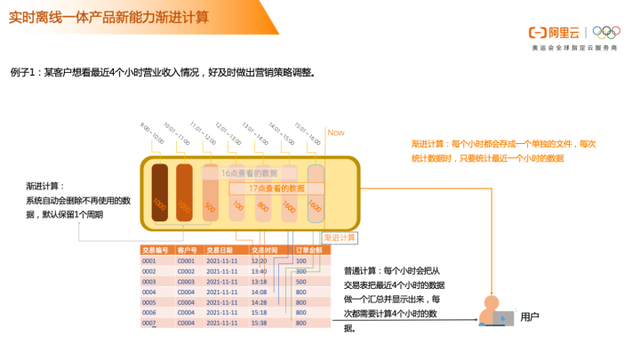
实时离线一体化产品新能力物化视图
物化视图是包括一个查询结果的数据库对象,他是远程数据的本地副本,或者用来生产基于数据表求和的汇总表。可以看下图示例,有一个订单表order保存明细订单记录,org组织机构表保存组织机构数据,如果查数据汇总时,需要把两张表数据先做关联,如下图示例代码。如果有物化视图,视图表就可以取代用户查询汇总的代码脚本,查询时直接查视图表即可。在这个过程中,物化视图支持用户设置数据更新频率,最快是五分钟,可以根据需求来做视图表的更新。
物化视图的用途与优势在于,数据在写入时计算,数据进行预计算,提高查询效率,对客户透明,自动改写。比如订单数据实时的写入,可以通过物化视图每五分钟更新来实现上层应用数据的近实时汇总统计查询。如果这条链路在Hologres,可以走实时数仓链路来完成。MaxCompute 提供的物化视图能力,满足客户对数据时效性要求高,但又不是实时的数据更新需求。
那在整条开发链路里面,流式数据或批量数据写入之后,在 MaxCompute 中可以通过物化视图 和渐进计算来完成数据汇总,再通过MCQA查询加速能力提供秒级别对外数据分析服务的能力。如果对交互式查询返回时延要求高,可以做汇总数据时把数据汇总到Hologres,通过Hologres对外提供数据分析服务能力,这个交互响应时间可以达到毫秒级别。
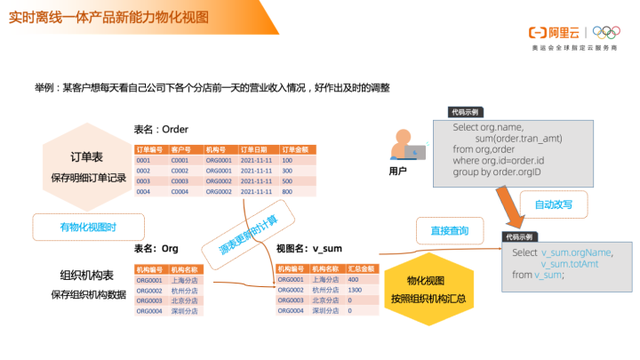
实时离线一体化数仓架构
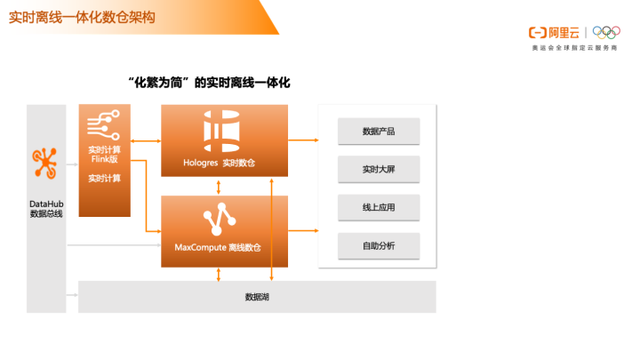
从架构来看,化繁为简之后的架构从左到右,可以直接通过Datahub数据总线把数据写入到 MaxCompute ,也通过实时计算(实时计算Flink版)消费数据总线(DataHub)实时数据写入Hologres提供分析服务。这一套架构有两条链路,如果业务响应时间要求非常高,可以走实时数仓链路,Datahub数据通过Flink完成实时数据计算写入实时数仓Hologres,提供数据给数据产品或者是实时大屏。如果对业务响应时间要求不高的,可以通多Datahub直接写入数据到 MaxCompute。
在实时计算Flink消费实时在线数据时,也有不同的计算指标需要呈现到离线数仓 MaxCompute 中,跟 MaxCompute中的一些数据做聚合计算,可以通过Hologres 直读的方式读取到MaxCompute聚合后的数据。通过Hologres 对外提供在线数据分析服务能力,底层数据可以是Hologres中的数据,也可以是MaxCompute中的数据。当前架构主要体现出的是实时离线一体化,但湖仓一体是在这一套架构中。不管是离线数仓还是实时数仓都可以跟数据湖中的数据互通。
基于当前架构主要提供了三个维度的服务能力
实时链路:通过实时计算(实时计算Flink版)消费数据总线(DataHub)实时数据写入Hologres提供分析服务。
低延时或手动触发:Flink/DataHub通过流式写入MaxCompute,应用物化视图进行预计算提供业务聚合数据基于查询加速的分析服务。消除了对作业和调度的管理。
批处理:MaxCompute支持多种数据来源的数据,进行大量同步和处理的数据计算。
实时离线一体化数仓数据建模
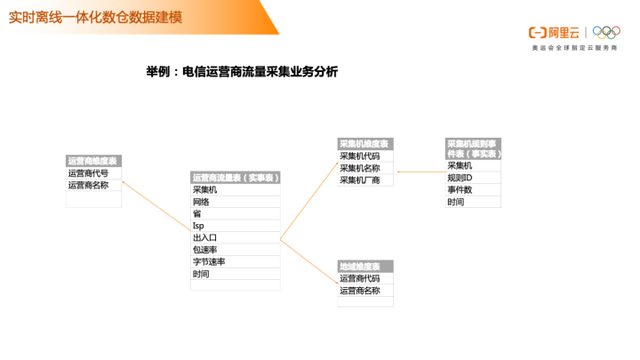
那实时离线一体化怎么使用呢? 可以看下图示例。
电信运营商流量采集业务分析:根据对流量采集业务分析,比较适合数据仓库常用建模方法——雪花模型。依据业务特征和雪花模型建模原则,完成数仓建模。
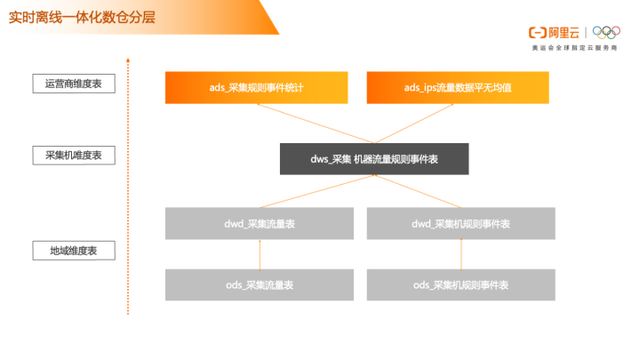
实时离线一体化数仓分层
此示例中,运营商流量表为实时数据表,针对流量表关联了采集机维度表和地域维度表,构建了基于实时流量数据的雪花模型。模型做完后,基于数仓的分层是,ods层为采集的流量表数据和采集机规则表,同步到MaxCompute或Hologres做相应规则处理。在dwd明细数据这一层,主要针对清洗完之后数据形成采集流量明细表和采集机规则事件明细表。如果是实时离线相结合的架构,dwd层数据可以汇总到Hologres中。如果是汇总到MaxCompute,可以用分区表来实现,在分区表内计算时间或者事件规则相符合的数据,在分区表内做轻度汇总。针对汇总表再去完成采集规则事件的统计包括流量数据平均值的统计分析。
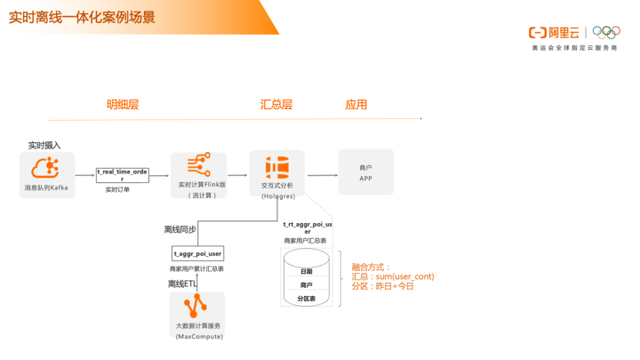
实时离线一体化案例场景
商家用户下单总数
比如商家要根据用户历史下单数给用户优惠,商家需要看到历史下了多少单,历史T+1的数据要有,今天实时的数据也要有,这种场景是典型的实时离线一体化架构。我们可以在Hologres里设计一个分区表,一个是历史分区,一个是今日分区,历史分区可以通过离线的方式生产,今日指标可以通过实时的方式计算,写到今日分区里,查询的时候进行一个简单的汇总。
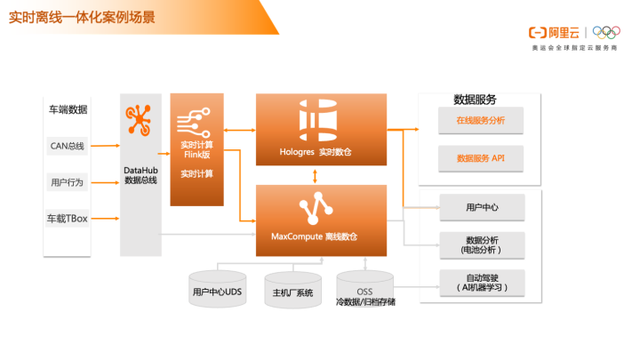
车联网
从左到右数据源有车端数据、CAN总线、用户行为、车载TBox,通过Datahub数据总线,分别写入实时计算Flink版进行消费写入Hologres实时数仓,和MaxCompute 离线数仓做数据分析。实时数据可以通过Hologres直接对数据服务端停供在线服务分析和数据服务API。同时Hologres可以读取在MaxCompute 中产生的批处理结果数据,也可以读取到物化视图或者渐进计算自动汇总的数据。同时MaxCompute 离线数仓也会处理用户中心UDS和主机厂系统数据,这些数据有一些业务数据或者是T+1数据,这些数据处理完后,可以进行冷数据归档到oss,这些数据可以提供给标准的自动驾驶进行AI机器学习。这一套应用场景就是实时离线一体化的标准使用场景。
原文链接
本文为阿里云原创内容,未经允许不得转载。







)











