背景
PolarDB-X是一款计算存储分离的分布式数据库,分布式的处理能力是PolarDB-X的核心特性之一,单个数据库实例的多个计算节点会均摊全部的SQL流量,这样就可以通过节点的扩缩容来快速满足不同的流量峰值场景。
在PolarDB-X 1.0时代,用户常常使用分库分表的方式对库表进行拆分从而达到数据和流量在多个节点间均衡,该模式下拆分键的选择对数据库的性能表现起关键性的作用,要选出最佳的拆分键组合就要求用户在建表初就对业务库的库表结构和数据分布非常熟悉。
为了帮助用户降低使用分布式数据库的技术门槛,PolarDB-X 2.0时代引入了透明分布式的理念,用户无需再逐一指定拆分键,使用分布式数据库就像使用单机MySQL一样简单,同样也能享有分布式数据库的优异特性。这既是用户体验上的一次升级,也是技术架构和理念的一次飞跃,从中间件模式进化到云原生架构,数据库不再是需要用户费心维护的高级技术组件,而是一种随用随得的云服务,让用户可以充分享受云架构带来的技术红利。
在PolarDB-X 2.0的AUTO模式下,数据库会按照表的主键自动Hash分区,将数据均匀的分布到各个数据节点中,最理想的情况就是各分区间数据和流量都是均衡的,能充分发挥出多节点的分布式处理能力。为了达到最理想的效果,就要求数据库尽量避免出现热点分区,包括流量的热点和数据量的热点。避免热点的出现,首先就需要能快速便捷地发现热点分区,从而能进行针对性的处理。因此快速准确地找出热点分区就成为PolarDB-X2.0所需的一项重要能力。
效果展示
功能概览
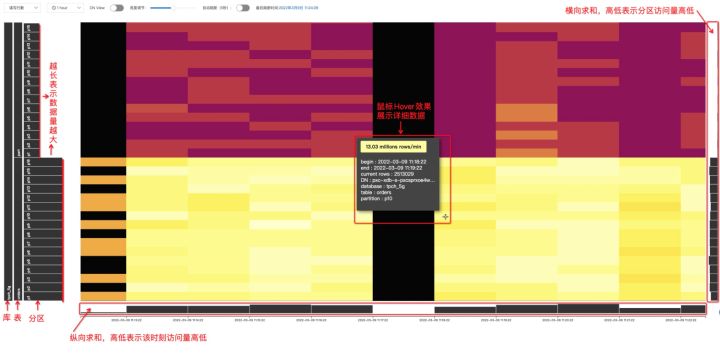
首先选取一个小范围数据做介绍,如下图,纵轴表示了逻辑库、逻辑表、逻辑分区间的关系,并且分区按照逻辑序号进行排序,横轴表示时间,图像下方和右方的柱形图表示了汇总数据,下方柱形图表示纵向的求和,即某时刻所有分区的访问量的求和,右方的柱形图表示横向的求和,即某分区所有时间范围内的访问量求和。
存储节点视角
如何想查看存储节点视角的热点情况,可以点击上方“DN View”按钮切换到存储节点视角,数据会按照不同的存储节点进行分类,可以方便分析出数据在物理存储节点间是否均衡,是否存在物理存储节点的热点。

TPC-C热点分析
用TPC-C流量进行测试,可以看到一个完整的热力分布情况,从图中可以明显发现TPC-C的流量存在两块热点区域,并且通过纵轴的宽度对比也能发现数据量的热点。

设计考量
1.展现方式尽可能简洁易懂
热点数据具有多种维度耦合的特点:数据量、访问量、时间、各分区间的关系、逻辑库表和分区间的关系、物理节点和逻辑库表间的关系、热分区和冷分区的区别,这些分析所必须的关键要素间相互耦合,缺一不可。要将复杂的信息整理清晰,给用户一个很清晰简洁的呈现。
2.避免影响数据库核心功能
要准确找出热点分区,就必须对数据库的数据量和请求量进行采集,流量和数据量是持续变化的,因此采集的过程也需要是持续的,这就更加要求信息采集的过程不能对数据库的核心功能造成负面影响。
3.实现链路减少对外部组件的依赖
随着PolarDB-X产品的发展,衍生出了多种部署形态,有阿里云上部署的公有云版本、有面向线下PoC场景部署的K8s版本、还有面向用户私有环境轻量化部署的DBStack版本,还有贡献给社区的开源版本等等,为了尽可能让更多的版本拥有同等能力,使用的外部组件需要尽可能的少,这样多形态部署时面临的兼容性问题才会最少。
4.控制采集数据量
因为流量数据的采集是一个持续的过程,理论上就会产生无穷无尽的统计数据,因此必须要限制统计数据的大小,要有数据时效范围,否则无穷大的数据无法存储。数据量尽可能的小也能减少数据传输过程中的IO和网络压力,减少对内核核心功能的影响。
设计方案
交互方式
经过在多种类型图表间对比,以及和业界其他相关解决方案的对比,最终选择用“热力图”这个形式来展示分区热度信息,横轴表达时间,纵轴则表达分区,用对应矩形的颜色明暗来表示访问热度的高低。一眼看去,最明亮的矩形就是热度最高的分区。

热力图可以很好表达访问量的热点,那么如何展示数据量的热点呢?我们创新性的利用了纵轴做文章,纵轴每个分区的高度都是相等的,但是宽度可以不相等,数据量越大的分区,宽度就越宽,这样一来,通过宽度的比较一眼就能发现数据量最大的分区。

有了以上两个展现的基本要素,再添加上一些动画:缩放、拖拽、颜色调整、hover等其他交互效果,就能很清晰完整的表达热点分区的信息了。
数据处理
时间轴的处理
根据热力图的展示特点,数据采集的频率定在1分钟/次,采集的统计数据最多保留7天,估算下来热力图的横轴最多会有 7 * 24 60 = 10080 个点,数据按照时间来存储就需要 10080 行数据。然而,浏览器展示的网页宽度通常在 1000px 单位左右,如果用户要看7天的全量数据,那么 1px 单位的宽度里就需要塞进10个时间轴,这种展示效果就会大打折扣了。因此必须对时间轴的数据进行处理,减少时间轴的标识密度,但是又不能丢失数据。
要减少时间轴的数量,很容易想到的方案就是降低采样精度,比如把采集频率改为30分钟/次,但是如果用户只看1小时内的数据,那页面就剩下2个时间点了,显然也是不能接受的。这样降低采样频率就会出现一个矛盾点:小时间段范围的显示精度要求和大时间段的显示效果要求间的矛盾。
因此,最终选择对时间轴进行分级处理,远时间范围的数据降低精度,近时间范围的数据保留高精度,这样也符合大部分用户的使用习惯,最近的数据看得更详细。采集精度改为最近1小时内数据1分钟/次,第1~8小时内数据2分钟/次,第8~24小时内数据6分钟/次,第24小时~7天内数据30分钟/次。这样时间轴最大数量就从100080减少到了60 + 210 + 160 + 288 = 718 个。
因此采用的数据结构如下图,多层环形队列,每一层从队尾插入新数据,从队头挑选出要指定的数据进行合并后插入下一层的队尾,然后从队头删除已合并的数据。每个环都有指定大小,当环满时向下合并数据,最后一层环满时直接丢弃数据。

分区轴的处理
热度统计数据的定时采集过程为了避免外部组件的依赖,因此利用了内核的调度器,在主计算节点每分钟发起一次采集任务,任务下推到各个存储节点获取原始数据,最终在主计算节点上处理。由此可见,采集过程的性能消耗和分区数量有很大关系,当分区数量少时,几乎无性能消耗,但是当分区数量特别多时,各个存储节点就会返回大量数据汇总到主计算节点,计算节点需要解析和排序,就会造成很大的内存和CPU压力。
因此,采集的分区数量必须要保持在一定的界限范围内,需要在保障热点诊断功能可用的同时又不影响数据库内核的性能。根据视觉效果和数据大小的实际情况计算发现,展示的分区数控制在 1600 以内会达到最佳的效果,默认单张表16个分区的情况下可以支持100张表的热点分析,可以满足大部分的应用场景。
分区表个数超多的情况也是会实际存在的,因此我们设计了将分区数超过1600且小于8000的情况,可以对分区统计信息进行合并,降低分区精度来支持分区数超大情况的热点分析,理论上已经可以支持1000张表的热点分析了。
对于数万或者数十万张表的情况,无论是信息的采集过程还是前端展示都会对内核和功能链路造成较大的资源压力,因此对于极端情况,默认不进行热点数据的采集,但是支持用户动态修改数据库参数,来指定需要进行热点分析的库表,指定分析范围按需分析。
综上,对小规模分区精确展示、中等规模分区降低精度显示、超大规模分区可指定范围显示,覆盖了多种不同的用户需求。
性能分析
为了检验热点分析功能对数据库内核性能的影响,进行了几组TPC-C的对比实验,结论是该功能对内核的性能影响极小。在将 PolarDB-X 内核的CPU压力压到最大的情况,分别测试开启该功能和页面刷新持续获取诊断结果的极端条件下,对性能的影响控制在1%左右波动,考虑到测试过程的正常统计误差,可以认为该功能对内核性能影响极小。


功能彩蛋
当用户没有建任何分区表时,页面没有数据可供显示,常规思路是前端显示一行文字“暂无数据”来提醒用户,这就让用户无法体验到该功能的乐趣。为了让用户在没有数据时也能提前体验到热点分析功能的快乐,PolarDB-X对空白页“搞事情”,结合热力分析功能的前端特色,绘制出“NO DATA”的图像,让用户没有数据时也能同样体验到热点分析功能。

当用户的分区数量超出显示上限时,会绘制出“TOO BIG”的图像进行提示。

热力分析功能除了上述“主流”用法之外,开动你的小脑袋,发挥你的想象力,还能整出各种“非主流”用法,比如我们可以利用热力图像的颜色特点,精确控制分区访问量,整出一个“爱心”的热力图像,你将成为世界上第一个用数据库表白成功的地球人!

原文链接
本文为阿里云原创内容,未经允许不得转载。



















