深度强化学习介绍
强化学习主要用来学习一种最大化智能体与环境交互获得的长期奖惩值的策略,其常用来处理状态空间和动作空间小的任务,在如今大数据和深度学习快速发展的时代下,针对传统强化学习无法解决高维数据输入的问题,2013年Mnih V等人首次将深度学习中的卷积神经网络(Convolutional Neural Networks,CNN)[1][2][3]引入强化学习中,提出了DQN(Deep Q Learning Network)[4][5]算法,至此国际上便开始了对深度强化学习(Deep Reinforcement Learning,DRL)的科研工作。除此之外,深度强化学习领域中一个里程牌事件是2016年的AlphaGo 对战李世石的围棋世纪大战[6][7],谷歌旗下的人工智能团队DeepMind 基于深度强化学习开发出的围棋程序 AlphaGo击败了世界顶级围棋大师李世石,震惊了世界,也因此拉开了深度强化学习从学术界走向大众认知的帷幕。 深度强化学习结合了深度学习[8](Deep Learning,DL)的特征提取能力和强化学习(Reinforcement Learning,RL)的决策能力[9],可以直接根据输入的多维数据做出最优决策输出,是一种端对端(end-to-end)的决策控制系统,广泛应用于动态决策、实时预测、仿真模拟、游戏博弈等领域,其通过与环境不断地进行实时交互,将环境信息作为输入来获取失败或成功的经验来更新决策网络的参数,从而学习到最优决策。深度强化学习框架如下:

上图深度强化学习框架中,智能体与环境进行交互,智能体通过深度学习对环境状态进行特征提取,将结果传递给强化学习进行决策并执行动作,执行完动作后得到环境反馈的新状态和奖惩进而更新决策算法。此过程反复迭代,最终使智能体学到获得最大长期奖惩值的策略。
深度强化学习的数学模型
强化学习[10]是一种决策系统,其基本思想是通过与环境进行实时交互,在不断地失败与成功的过程中学习经验,最大化智能体(Agent)从环境中获得的累计奖励值,最终使得智能体学到最优策略(Policy),其原理过程如下图所示:

上图强化学习基本模型中,智能体(Agent)是强化学习的动作实体,智能体在当前状态下根据动作选择策略执行动作,执行该动作后其得到环境反馈奖惩值 和下一状态,并根据反馈信息更新强化学习算法参数,此过程会反复循环下去,最终智能体学习到完成目标任务的最优策略。 马尔可夫决策过程(Markov Decision Process,MDP)[11]是强化学习理论的数学描述,其可以将强化学习问题以概率论的形式表示出来。 在MDP中可将强化学习以一个包含四个属性的元组表示:{S,A,P,R},其中: S 和 A 分别表示智能体的环境状态集和智能体可选择的动作集





基于值函数的深度强化学习算法
基于值函数(Value based)的学习方法是一种求解最优值函数从而获取最优策略的方法。值函数输出的最优动作最终会收敛到确定的动作,从而学习到一种确定性策略。当在动作空间连续的情况下该方法存在维度灾难、计算代价大问题,虽然可以将动作空间离散化处理,但离散间距不易确定,过大会导致算法取不到最优,过小会使得动作空间过大,影响算法速度。因此该方法常被用于离散动作空间下动作策略为确定性的强化学习任务。
基于值函数的深度强化学习算法利用CNN来逼近传统强化学习的动作值函数,代表算法就是DQN算法, DQN算法框架如下:



基于策略梯度的深度强化学习算法
基于策略梯度(Policy based)的深度强化学习算法是一种最大化策略目标函数从而获取最优策略的方法,其相比Value based方法区别在于:
- 可以学习到一种最优化随机策略。Policy based方法在训练过程中直接学习策略函数,随着策略梯度方向优化策略函数参数,使得策略目标函数最大化,最终策略输出最优动作分布。策略以一定概率输出动作,每次结果很可能不一样,故不适合应用于像CR频谱协同这类动作策略为确定性的问题中。
- Policy based方法容易收敛到局部极值,而Value based探索能力强可以找到最佳值函数。
上述中的策略目标函数用来衡量策略的性能。定义如下:


AC算法
R=\Sigma^{T-1}_{t=1}{r_t}
AC算法框架被广泛应用于实际强化学习算法中,该框架集成了值函数估计算法和策略搜索算法,是解决实际问题时最常考虑的框架。众所周知的alphago便用了AC框架。而且在强化学习领域最受欢迎的A3C算法,DDPG算法,PPO算法等都是AC框架。 Actor-Critic算法分为两部分,Actor的前身是policy gradient,policy gradient可以轻松地在连续动作空间内选择合适的动作(value-based的Q-learning只能解决离散动作空间的问题)。但是又因为Actor是基于一个episode的return来进行更新的,所以学习效率比较慢。这时候我们发现使用一个value-based的算法作为Critic就可以使用梯度下降方法实现单步更新,这其实可以看做是拿偏差换方差,使得方差变小。这样两种算法相互补充结合就形成了Actor-Critic算法。框架如下:
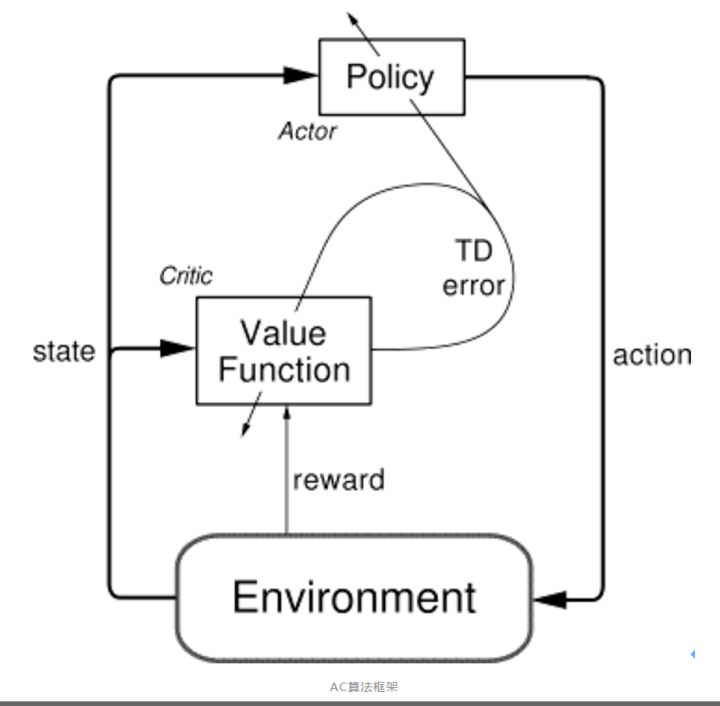
Actor 基于概率分布选择行为, Critic 基于 Actor 生成的行为评判得分, Actor 再根据 Critic 的评分修改选行为的概率。下面分析优缺点:
优点:可以进行单步更新,不需要跑完一个episode再更新网络参数,相较于传统的PG更新更快。传统PG对价值的估计虽然是无偏的,但方差较大,AC方法牺牲了一点偏差,但能够有效降低方差;
缺点:Actor的行为取决于 Critic 的Value,但是因为 Critic本身就很难收敛和actor一起更新的话就更难收敛了。(为了解决收敛问题, Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient,后者融合了 DQN 的一些 trick, 解决了收敛难的问题)。
参考文献
- Ketkar N . Convolutional Neural Networks[J]. 2017.
- Aghdam H H , Heravi E J . Convolutional Neural Networks[M]// Guide to Convolutional Neural Networks. Springer International Publishing, 2017.
- Gu, Jiuxiang, Wang, et al. Recent advances in convolutional neural networks[J]. PATTERN RECOGNITION, 2018.
- MINH V, KAVUKCUOGLU K, SILVER D, et al.Playing atari with deep reinforcement learning[J].Computer Science, 2013, 1-9.
- MNIH V,KAVUKCUOGLU K,SILVER D,et al.Human-level control through deep reinforcement learning[J].Nature,2015,518(7540):529-533.
- 曹誉栊. 从AlphaGO战胜李世石窥探人工智能发展方向[J]. 电脑迷, 2018, 115(12):188.
- 刘绍桐. 从AlphaGo完胜李世石看人工智能与人类发展[J]. 科学家, 2016(16).
- Lecun Y, Bengio Y, Hinton G. Deep learning.[J]. 2015, 521(7553):436.
- 赵冬斌,邵坤,朱圆恒,李栋,陈亚冉,王海涛,刘德荣,周彤,王成红.深度强化学习综述:兼论计算机围棋的发展[J].控制理论与应用,2016,33(06):701-717.9
- 陈学松, 杨宜民. 强化学习研究综述[J]. 计算机应用研究(8):40-44+50.
- L. C. Thomas. Markov Decision Processes[J]. European Journal of Operational Research, 1995, 46(6):792-793.
- Bardi M, Bardi M. Optimal control and viscosity solutions of Hamilton-Jacobi-Bellman equations /[M]// Optimal control and viscosity solutions of Hamilton-Jacobi-Bellman equations. 1997.
- Ruder S . An overview of gradient descent optimization algorithms[J]. 2016.
- R. Johnson, T. Zhang. Accelerating stochastic gradient descent using predictive variance reduction[J]. News in physiological sciences, 2013, 1(3):315-323.
- Sutton, Richard& Mcallester, David& Singh, Satinder& Mansour, Yishay. (2000). Policy Gradient Methods for Reinforcement Learning with Function Approximation. Adv. Neural Inf. Process. Syst. 12.
- Silver, David& Lever, Guy& Heess, Nicolas& Degris, Thomas& Wierstra, Daan& Riedmiller, Martin. (2014). Deterministic Policy Gradient Algorithms. 31st International Conference on Machine Learning, ICML 2014. 1.
- Lillicrap, Timothy& Hunt, Jonathan& Pritzel, Alexander& Heess, Nicolas& Erez, Tom& Tassa, Yuval& Silver, David& Wierstra, Daan. (2015). Continuous control with deep reinforcement learning. CoRR.
原文链接
本文为阿里云原创内容,未经允许不得转载。


)


应用场景与技术解析)










)

)
