如何写标题
1、用一句话概括你所做的工作;
2、字数忌长(尽可能不要超过20单词,40-60 字符比较合适);
3、考虑搜索引擎的影响,包含关键词。
4、例子
例子1:Enhancing slope one recommendation through local information embedding (目的:enhance the performance of an existing algorithm;技术:local information embedding)
例子2:Sentiment based matrix factorization with reliability for recommendation (目的: reliability for recommendation;技术: sentiment based matrix factorization)
如何写摘要
1、几句话概括你所做的工作;
2、用语要简单,最好让外行也能看懂;
3、尽量避免把所有细节都说清楚,尽量避免用很专业的术语来描述,尽量避免出现数学符号。
例子1:英文摘要写法(十句)
(1) The description of the area and the problem. XXX is an important issue in XXX.
(2) Existing works. There are some
(3) The drawback/limitation of the existing works. However, ...
(4) The content of the paper. In this paper, we propose ...
(5)~(7) Detailed explanation of our work. First, .... Second,.... Third, ....
(8)~(9) Experimental results ...
(10) The significance of the paper (maybe unnecessary).
例子2:
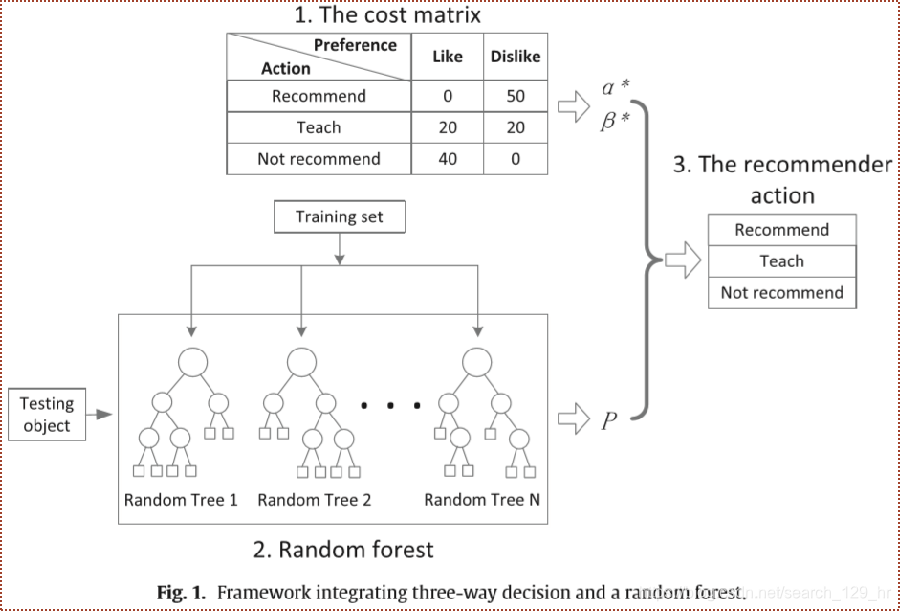
Recommender systems guide their users in decisions related to personal opinions about items. Sentence 1, the problem statement. Most existing systems implicitly assume the recommender behavior as a binary classification. Sentence 2, existing work. That is, the incoming item is either recommended or not. Sentence 3, limitation of existing work. In this paper, we propose a framework integrating three-way decision and random forest to build recommender systems. Sentence 4, the main content. First, we consider both misclassification costs and teacher cost. Sentence 5, the first technique. Misclassification costs are paid for wrong recommendation behaviors, while teacher cost is paid to consult the user actively for her tendency. Sentence 5', more about the first technique. Second, with these costs, a three-way decision model is built and rational settings of $\alpha^*$ and $\beta^*$ are computed. Sentence 6, the second technique. Third, we build a random forest to compute the probability $P$ that a user likes an item. Sentence 7, the third technique. Fourth, $\alpha^*$, $\beta^*$ and $P$ are employed for determining the recommender behavior to users. Sentence 7', the fourth technique. The performance of the recommender is evaluated by the average cost. Sentence 7', more about the main content. Experiments results on the well-known MovieLens dataset show that the threshold pair (,
) determined by three-way decision is optimal not only on the training set, but also on the testing set. Sentences 8 and 9, the experimental setting and the result.
如何写引言
1、比题目和摘要更进一步,用几段话说清你的工作;
2、要点是充分论证你所做工作的必要性和重要性,要让审稿人认同并迫不及待想往下看;
3、行文逻辑严密,论证充分:
(1)说明问题是什么;
(2)目前最好的工作面临什么挑战;
(3)我们的方法能缓解上述挑战。
4、例子:摘要扩充为引言
(1) Recommender systems attempt to guide users in decisions related to choosing items based on inferences about their personal opinions. Most existing systems implicitly assume the underlying classification is binary, that is, a candidate item is either recommended or not.

(2) Here we propose an alternate framework that integrates three-way decision and random forests to build recommender systems.


(3) With these costs, a three-way decision model is built, and rational settings for positive and negative threshold values and
are computed.

(4) We next construct a random forest to compute the probability that a user will like an item.


(5) Finally, ,
, and
are used to determine the recommender’s behavior.

重要写作工具
1、LaTex
(1)强烈建议⽤LaTex代替Word;
(2)科技排版系统:CTEX
2、Bibtex
(1)⾃动⽣成参考⽂献列表
3、MetaPost
(1)编程画⽮量图
参考文献
[1] 如何做研究、如何写论文,周志华,南京大学
[2] 机器翻译学术论⽂文写作⽅方法和技巧,刘洋,清华大学
[3] 张恒汝,闵帆,Three-way recommender systems based on random forests, Knowledge-Based Systems, 2016, 91: 275-286.
[4] 张恒汝,闵帆,石兵,Regression-based three-way recommendation,Information Sciences, 2017, 378, 444-461.
[5] 沈蓉萍,张恒汝,于洪,闵帆,Sentiment based matrix factorization with reliability for recommendation. Expert Systems with Applications, 2019.
[6] 张恒汝, 闵帆,吴彦学, 付卓林, 高磊, Magic barrier estimation models for recommended systems under normal distribution, Applied Intelligence, 2018: 1-8.

 - 机器学习纳米学位)
)

--YAMNet简介)

)
)
——通过Netbeans开发环境生成oracle数据库中表的对应hibernate映射文件...)

--YAMNet进一步分析)
.doc...)
--输入输出及方案讨论)

--接口输入输出讨论)




...)