1.组函数(聚合函数)
(1)组函数介绍
组函数操作行集,给出每组的结果。组函数不象单行函数,组函数对行的集合进行操作,
对每组给出一个结果。这些集合可能是整个表或者是表分成的组。
组函数与单行函数区别
单行函数对查询到每个结果集做处理,而组函数只对分组数据做处理。
单行函数对每个结果集返回一个结果,而组函数对每个分组返回一个结果。
组函数的类型
• AVG 平均值
• COUNT 计数
• MAX 最大值
• MIN 最小值
• SUM 合计
组函数的语法

使用组函数的原则
• 用于函数的参数的数据类型可以是 CHAR、VARCHAR2、NUMBER 或 DATE。
• 所有组函数忽略空值。为了用一个值代替空值,用 NVL、NVL2 或 COALESCE 函数。
(2)组函数的使用 AVG 和 SUM 函数
AVG(arg)函数:对分组数据做平均值运算。
arg:参数类型只能是数字类型。
SUM(arg)函数:对分组数据求和。
arg:参数类型只能是数字类型。
示例:求雇员表中的的平均薪水与薪水总额。
select avg(salary) ,sum(salary) from employees;使用 MIN 和 MAX 函数
MIN(arg)函数:求分组中最小数据。
arg:参数类型可以是字符、数字、日期。
MAX(arg)函数:求分组中最大数据。
arg:参数类型可以是字符、数字、日期。
示例 :求雇员表中的最高薪水与最低薪水。
select min(salary),max(salary) from employees;使用 COUNT 函数
COUNT 函数:返回一个表中的行数。
COUNT 函数有三种格式:
• COUNT(*)
• COUNT(expr)
• COUNT(DISTINCT expr)
COUNT(*) :
返回表中满足 SELECT 语句标准的行数,包括重复行,包括有空值列的行。如果WHERE 子句包括在 SELECT 语句中,COUNT(*) 返回满足 WHERE 子句条件的行数。
示例:返回查询结果的总条数。
select count(*) from employees;COUNT(expr)函数 :
返回在列中的由 expr 指定的非空值的数。
示例:显示部门 80 中有佣金的雇员人数。
select count(commission_pct) from employees e where e.department_id = 80;COUNT(DISTINCT expr):
使用 DISTINCT 关键字禁止计算在一列中的重复值。
示例:显示 EMPLOYEES 表中不重复的部门数。
select count(distinct department_id) from employees ;组函数和 Null 值
所有组函数忽略列中的空值。
在组函数中使用 NVL 函数来处理空值。
示例:计算有佣金的员工的佣金平均值。
select avg(commission_pct) from employees;2.创建数据组(GROUP BY)
什么是创建数据组
可以根据需要将查询到的结果集信息划分为较小的组,用 GROUP BY 子句实现。
GROUP BY 子句语法

GROUP BY 子句:GROUP BY 子句可以把表中的行划分为组。然后可以用组函数返回
每一组的摘要信息。
使用分组原则
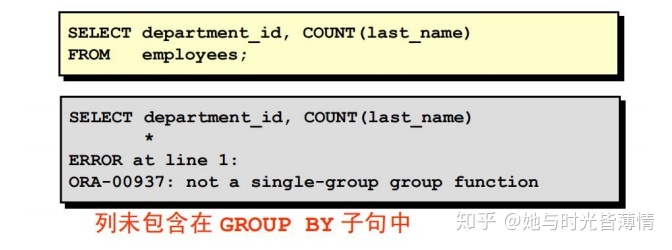
• 如果在 SELECT 子句中包含了组函数,就不能选择单独的结果,除非单独的列出现在 GROUP BY 子句中。如果未能在 GROUP BY 子句中包含一个字段列表,你会收到一个错误信息。
• 使用 WHERE 子句,你可以在划分行成组以前过滤行。
• 在 GROUP BY 子句中必须包含列。
• 在 GROUP BY 子句中你不能用列别名。
• 默认情况下,行以包含在 GROUP BY 列表中的字段的升序排序。可以用 ORDER BY子句覆盖这个默认值。
GROUP BY 子句的使用
我们可以根据自己的需要对数据进行分组,在分组时,只要将需要做分组的列的列名添
加到 GROUP BY 子句后侧就可以。GROUP BY 列不必在 SELECT 列表中。

示例:求每个部门的平均薪水。
select department_id , avg(salary) from employees e group by e.department_id;GROUP BY 子句的执行顺序
先进行数据查询,在对数据进行分组,然后执行组函数。
非法使用 Group 函数的查询
• 在 SELECT 列表中的任何列必须在 GROUP BY 子句中。
• 在 GROUP BY 子句中的列或表达式不必在 SELECT 列表中。
约束分组结果
HAVING 子句 的概念
HAVING 语句通常与 GROUP BY 语句联合使用,用来过滤由 GROUP BY 语句返回的记录集。
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
HAVING 子句语法

示例:显示那些最高薪水大于 $10,000 的部门的部门号和最高薪水。
select e.department_id,max(e.salary) from employees e group by e.department_id having max(e.salary) > 10000;查询那些最高薪水大于 $10,000 的部门的部门号和平均薪水。
select e.department_id,avg(e.salary) from employees e group by e.department_id having max(e.salary) > 10000;嵌套组函数
在使用组函数时我们也可以根据需要来做组函数的嵌套使用。
示例 :显示部门中的最大平均薪水。
select max(avg(e.salary)) from employees e group by e.department_id;3.子查询
子查询介绍
子查询是一个 SELECT 语句,它是嵌在另一个 SELECT 语句中的子句。
子查询语法

• 子查询 (内查询) 在主查询之前执行一次
• 子查询的结果被用于主查询 (外查询)
可以将子查询放在许多的 SQL 子句中,包括:
• WHERE 子句
• HAVING 子句
• FROM 子句
使用子查询的原则
• 子查询放在圆括号中。
• 将子查询放在比较条件的右边。
• 在单行子查询中用单行运算符,在多行子查询中用多行运算符。
示例:谁的薪水比 Abel 高。
用内连接实现:
select em.last_name,em.salary from employees abel,employees em where abel.last_name = 'Abel' and em.salary > abel.salary;用子查询实现:
select em.last_name,em.salary from employees em where em.salary >(select m.salary from employees m where m.last_name = 'Abel');子查询的类型
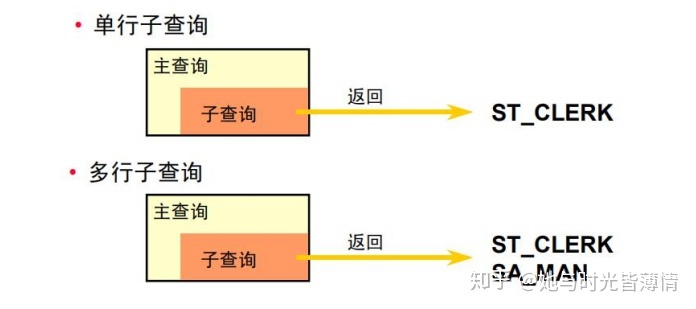
• 单行子查询:子查询语句只返回一行的查询
• 多行子查询:子查询语句返回多行的查询
单行子查询
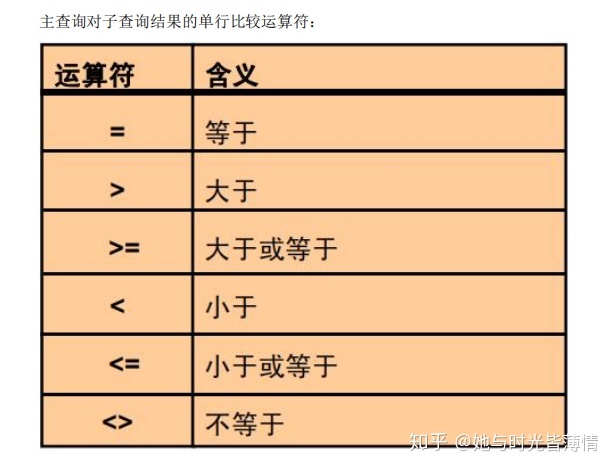
• 仅返回一行
• 使用单行比较符
示例:显示那些 job ID 与雇员 141 相同的雇员的名字与 job ID。
select em.last_name,em.job_id from employees em where em.job_id = (select job_id from employees e where e.employee_id = 141);示例:显示 job ID 与雇员 141 相同,并且薪水 高于雇员 143 的那些雇员。
select e.last_name,e.job_id,e.salary from employees e where e.job_id = (select em.job_id from employees em where em.employee_id = 141) and e.salary > (select emp.salary from employees emp where emp.employee_id = 143);在子查询中使用组函数
示例 :显示所有其薪水等于最低薪水的雇员的 last name、job ID 和 salary。
select em.last_name,em.job_id,em.salary from employees em where em.salary =(select min(salary) from employees);带子查询的 HAVING 子句
可以在 WHERE 子句中使用子查询,也可以在 HAVING 子句中使用子查询。
示例 :显示所有其最低薪水小于 部门 50 的最低薪水的部门号和最低薪水。
select em.department_id,min(em.salary) from employees em group by em.department_id having min(em.salary) > (select min(e.salary) from employees e where e.department_id = 50);什么是子查询错误?
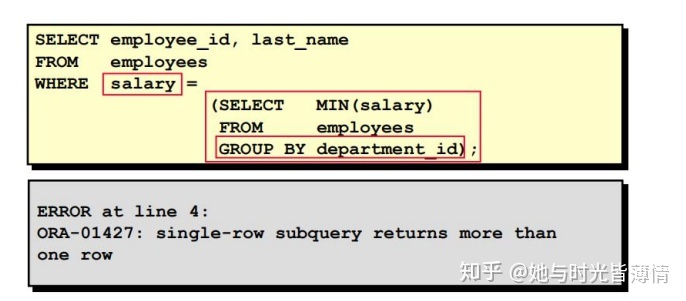
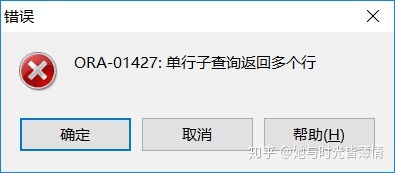
子查询错误:使用子查询的一个常见的错误是单行子查询返回了多行。
多行子查询
• 返回多于一行
• 使用多行比较符
主查询对子查询的多行比较运算符
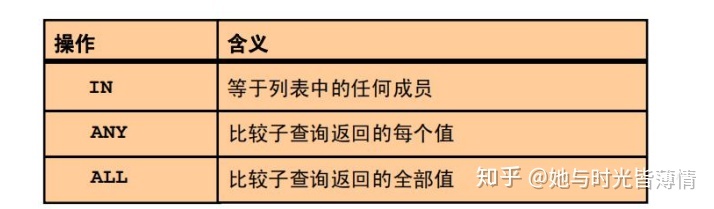
在条件中也可使用 NOT 取反。
4.在多行子查询中使用 IN 运算符
示例 :查找各部门收入为部门最低的那些雇员。显示他们的名字,薪水以及部门 ID。
select e.last_name,e.department_id,e.salary from employees e where e.salary in(select min(em.salary) from employees em group by em.department_id);5.在多行子查询中使用 ANY 运算符

< ANY 意思是小于最大值。 >ANY 意思是大于最小值。
示例
显示工作岗位不是 IT_PROG 的雇员,并且这些雇员的的薪水少于 IT_PROG 工作岗位的雇员的 ID、名字、工作岗位和薪水。
select e.employee_id,e.last_name,e.job_id,e.salary from employees e where e.job_id <> 'IT_PROG' and e.salary < any (select em.salary from employees em where em.job_id = 'IT_PROG') ;6.在多行子查询中使用 ALL 运算符

<ALL 意思是小于最小值。>ALL 意思是大于最大值。
ANY 与 ALL 的区别:
ANY: >ANY 表示至少大于一个值,即大于最小值。
ALL: >ALL 表示大于每一个值,既大于最大值。


)







![计算机软件名称用什么符号,[计算机软件及应用]第九章符号表.ppt](http://pic.xiahunao.cn/计算机软件名称用什么符号,[计算机软件及应用]第九章符号表.ppt)






)

