
来源:财新网
概要:相比于之前的历次技术进步,“人工智能革命”所引发的冲击更为巨大,其对经济学造成的影响也将更为广泛和深远。
人工智能技术的突飞猛进,对经济社会的各个领域都产生了重大影响,这种影响当然也波及到了经济学。很多一线经济学家纷纷加入了对人工智能的研究,不少知名学术机构还组织了专门的学术研讨会,组织学者对人工智能时代的经济学问题进行专门的探讨。
事实上,经济学家并不是最近才开始关注人工智能的。在理论层面,经济学对决策问题的探讨与人工智能所研究的问题有很多不谋而合之处,这决定了两门学科在研究上存在着很多交叉之处。从历史上看,经济学家对人工智能的理论关注至少有过三次高潮:第一次高潮是上世纪五六十年代,人工智能这门学科的奠基之初。当时,有不少经济学家参与了这一学科的建设。例如,诺贝尔经济学奖得主Herbert Simon就是人工智能学科的创始人之一,也是“符号学派”的开创者。在他看来,经济学和人工智能有不少共通之处,它们都是“人的决策过程和问题求解过程”,因此在进行人工智能研究的过程中,他融入了不少经济学的思想。第二次高潮是在本世纪初。当时,经济学在博弈论、机制设计、行为经济等领域都取得了不少的进展,这些理论进展被频繁地应用在人工智能领域。最近经济学家对人工智能问题的关注是第三次高潮。这次高潮主要是在以深度学习为代表的技术突破的推动下发生的,由于深度学习技术强烈依赖于大数据,因此在这轮高潮中的不少讨论集中在了与数据相关的问题上,而在对人工智能进行建模时也重点体现出了规模经济、数据密集等相关的性质。
至于应用层面,经济学和人工智能这两个领域的互动更为频繁。目前,在金融经济学、管理经济学、市场设计等领域都可以看到人工智能的应用。
从总体上看,最近有关人工智能的经济学大致可以分为三类:
第一类研究是将人工智能视为分析工具。一方面,人工智能的一些技术可以与传统的计量经济学相结合,从而克服传统计量经济学在应对大数据方面的困难。应用这些新的计量技术,经济学家可以探索和构建新的经济理论。另一方面,人工智能的发展也为采集新的数据提供了便利。借助人工智能,诸如语音、图像等信息都可以较为容易地整理为数据,这些都为经济学研究提供了重要的分析材料。
第二类研究是将人工智能作为分析对象。从经济学角度看,人工智能具有十分鲜明的性质。首先,人工智能是一种“通用目的技术”(General Purpose Technology,简称GPT),可以被应用到各个领域,其对经济活动带来的影响是广泛和深远的。现在,在分析经济增长、收入分配、市场竞争、创新问题、就业问题,甚至是国际贸易等问题时,都很难回避人工智能所造成的影响。其次,人工智能是一种强化的自动化,它会对劳动力产生替代,并造成偏向型的收入分配结果。再次,当前的人工智能技术发展强烈依赖与大数据的应用,这就决定了它具有很强的规模经济和范围经济,这两个特征对产业组织、竞争政策、国际贸易等问题都会产生重要影响。以上的所有这些特征共同决定了分析和评估人工智能对现实经济造成的影响应当成为经济学研究的一个重要话题。
第三类研究是将人工智能作为思想实验。作为一门学科,经济学是建立在理想化的假设基础之上的。在现实中,很多假设并不成立,因此经济学的预言就和现实存在着一定的差距。而人工智能的出现,从某种意义上来讲是为经济学家提供了一个可能的、符合经济学假设的环境。这同时也为检验经济理论的正确性提供了一个场所。
在本文中,笔者将对最近几年来有关人工智能的经济学文献进行梳理,对相关的重要文献进行介绍。考虑到在上述三类研究中,第三类的科幻性较强,而科学性相对不足,因此本文将暂时不涉及这类研究,对此感兴趣的读者可以自行参考Hanson(2016)等代表性文献。
一、人工智能的相关概念简介
在正式展开对人工智能经济学的讨论之前,我们需要先对文献中经常提及的几个概念——“人工智能”、“机器学习”和“深度学习”进行一下解释。初略来讲,人工智能的概念是最大的,机器学习是其的一个分支学科,而深度学习又是机器学习的一个分支(如图1)。
图1:人工智能、机器学习和深度学习的关系
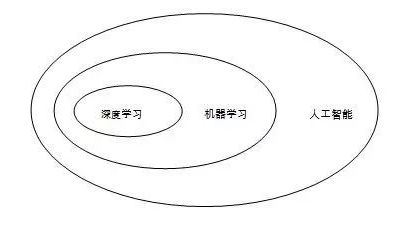
机器学习(Machine Learning)是人工智能的一个分支学科,是实现人工智能的一种方法。它使用算法来解析数据,从中学习,然后对真实世界中的事件做出决策和预测。和传统的为解决特定任务而专门进行编程的思路不同,机器学习“让计算机拥有在没有明确编程的条件下拥有学习的能力”,并通过对大量数据的学习找出完成任务的方法。
在最广的意义上,人工智能是“让智能体(agent)在复杂环境下达成目标的能力”。关于智能体应该怎样达成目标,不同的学者有不同的理解。早期的学者认为,人工智能应当模仿人类的思考和行动,其目的在于创造出能和人类一样思考的机器。而较近的一些学者则认为,人类的思维方式只是一种特定的算法,人工智能并不一定要模仿人类,而应该在更广的范围上让智能体合理地思考和行动。以LeCun、 Tagmark为代表的一些学者甚至认为一味模仿人脑只会限制人工智能的发展。人工智能包括很多分支学科,例如机器学习、专家系统、机器人学、搜索、逻辑推理与概率推理、语音识别与自然语言处理等。
根据学习的特征,机器学习可以分为三类:有监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning)。
有监督学习是通过对有标签的数据样本(a sample of labelled data)进行学习,从而找出对输入和输出之间的一般性法则。例如,对于房地产企业来说,他们拥有大量房屋属性,以及房价信息的数据,如果他们希望对这些数据进行学习,通过建模找出房价和各类房屋属性之间的关系,那么这个过程就是有监督学习。进行有监督学习的算法主要有两类,一类是回归(Regression)算法,另一类是分类(Classification)算法。
无监督学习所面对的数据样本则是没有标识的,其任务在于通过学习这些数据从而找出数据中隐藏的潜在规律。例如,艺术鉴赏家经常需要对名画的流派进行鉴定。显然,在任何一张画上都不会存在任何明确标识的特征信息,因此鉴赏家们只能通过大量欣赏画作去增加主观体验。久而久之,他们会发现某些画家会固定使用一些作画技巧,通过对这些技巧的识别,他们就能对画作的流派进行鉴定。在这个过程中,鉴赏家们的学习就是无监督学习。聚类(Clustering)算法进行无监督学习的主要算法。
强化学习是在动态环境中进行的学习,学习者通过不断试错,从而使得奖励信号最大化。例如,学生通过做习题来温习功课,每次做完习题后,老师都会批改习题,让他们知道哪些题做对了,哪些题做错了。学生根据老师的批改,找出错误、纠正错误,让正确率不断提高,这个过程就是强化学习。
近年来备受关注的深度学习(Deep Learning)是机器学习的一个研究分支。它利用多层神经网络进行学习,通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。在传统的条件下,由于可供学习的数据过少,深度学习很容易产生“过度拟合”等问题,因而影响其效果。但随着大数据的兴起,深度学习的力量就开始体现出来。今年来人工技术的迅速发展,很大程度上是由深度学习的发展推动的。
二、作为研究工具的人工智能
人工智能是经济学研究的有力工具。一方面,人工智能中的机器学习目前已开始逐步融入计量经济学,在经济学研究中有了较多应用。另一方面,语音识别、文本处理等技术也为经济学研究的素材收集提供了便利。在本节中,我们不对人工智能在素材搜集上的应用进行探讨,只集中讨论机器学习在经济学中的应用。由于这个原因,在本节中“人工智能”和“机器学习”可以被视为是同义词。
(一)人工智能对计量经济学的影响
1、计量经济学与机器学习:从孤立到融合
统计学关注的问题有四个:(1)预测(Prediction),(2)总结(summarization),(3)估计(estimation),以及(4)假设检验。计量经济学是统计学的一个子学科,因此以上四个问题同样也是其关心的主题。但作为一门为经济学研究服务的统计学,计量经济学对于因果关系的关注是更为突出的,因此它更强调总结、估计和假设检验,而对于预测的关注则相对较少。由于强调对因果问题的解释,所以计量经济学对估计结果的无偏性和一致性予以了特别的关注,将大量精力投入到了解决“内生性”等可能干扰估计结果一致性的问题上。
相比于统计学和计量经济学,机器学习是一门更为应用性的学科。它所关注的问题更多是预测,而不是对因果关系的探究。因为这个原因,决策树(Decision Tree)、支持向量机(SVM)等分类模型,以及在计量经济学中很少被用到的岭回归(Ridge Regression)、套索算法(LASSO)等,都在机器学习中被大量使用。
由于关注的焦点不同,传统上计量经济学和机器学习之间的交集很小,在某些情况下,两者甚至存在着一定的矛盾。Athey(2018)曾给出过一个例子:假设我们手头有一批旅馆的入住率和价格的数据。如果我们要利用价格来预入住率,那么得到的模型通常显示入住率和价格之间存在着正向关系。理由很简单,当旅馆发现自己的更受欢迎时,会倾向于抬高自己的价格。但如果我们考虑的问题是当企业降价时会有什么后果,那涉及到的就是因果推断问题。此时,根据需求定律,如果我们的设定没有出错,那么所得到的模型通常会显示入住率和价格之间存在着负向关系。
但随着大数据时代的到来,这两个学科之间的交集开始逐渐增大。
一方面,在大数据条件下机器学习的方法逐渐展现出了其应用价值。传统计量经济学关注的都是样本较小、维度较低的数据,对于这样的“小数据”,传统计量方法是可以较好应付的。但是当数据的数量和维度极具扩大后,这些方法就开始变得捉襟见肘了。例如,在计量分析时,研究者会很习惯于将大量的被解释变量都加入到模型,然后对其进行估计。这在数据量较小时能行之有效,但当数据量极为庞大时,其对于运算能力的要求将是惊人的。这就要求研究者必须先对模型进行“降维”,找出最关键的那些解释变量,此时机器学习的一些算法,例如LASSO就会起到作用。
另一方面,机器学习可以为寻找因果关系提供启发。因果推断的方法通常是针对一个定义良好(well-defined)的模型采用的,而在现实中,研究者事实上甚至不了解应该选择怎样的模型。此时,机器学习的方法就有了用武之地。Varian(2014)曾经举过一个泰坦尼克号乘客年龄与幸存概率的例子。他利用了两种方法对这一问题进行了分析,其中一种是在寻求因果关系时常用的Logit模型,而另一种则是机器学习中常用的决策树方法。根据Logit模型,乘客年龄和幸存率之间的关系并没有显著的关系。而决策树模型则显示,儿童和60岁以上的老年人会拥有更高的生存概率,这是因为在泰坦尼克号沉没之前,老人和孩子被允许优先逃离。很显然,在这个例子中,决策树能够为我们带来更多的有价值信息,有了这些信息,研究者就可以构建进一步的模型来进行因果推断。
这里值得说明的是,如果训练集很小,那么机器学习的算法很容易会导致过度拟合(overfit)的问题,此时其优势很难体现出来。而在大数据条件下,过度拟合问题的影响大大减小,其价值也就显露了出来。
2、机器学习在因果推断中的应用
前微软首席经济学家、斯坦福大学教授Susan Athey曾在Science上发文讨论了机器学习在因果推断和政策评估中的作用。她指出,过去更多被用于预测的机器学习在因果推断领域有很强的应用前景,未来的计量经济学家应当更多将机器学习的技术与现有的计量经济理论相结合。
机器学习在因果推断中的第一个应用是将用来取代常规方法中一些不涉及因果关系的步骤。例如,在因果推断分析中,倾向性得分匹配法(Propensity Score Matching)是经常被用到的。使用这一方法的第一步是要依赖于核估计等方法计算出倾向性得分,而这些估计在协变量众多的情况下是难以进行的。为了在众多的协变量中筛选出有用的部分,一些研究者就提出了将LASSO、Booting、随机森林等常用于机器学习的算法应用到协变量筛选的过程中去,然后再用得到的结果按照传统的步骤进行匹配。
机器学习在因果推断中的第二个应用是对异质性处理效应的估计。过去的因果关系推断,主要是在平均意义上展开的,其关注的焦点是平均处理效应(Average Treatment Effect,简称ATE)。这样的分析固然有重要的价值,但在不少情况下它并不能满足实际应用的需要。举例来说,当医生决定是否要对一位癌症病人采用某项疗法时,如果他仅知道平均来看这种疗法可以让病人的存活时间增加一年,这显然是不够的。由于同一疗法对于不同病人的效果区别很大,因此在决定是否采用该疗法时,医生就需要进一步知道不同特质的病人在采用这种疗法时会有怎样的症状。换言之,除了ATE外,他还需要关注异质性的处理效应(Heterogeneous Treatment Effect)。
Athey and Imbens(2015)将机器学习中常用的分类回归树(Classification and Regression Trees)引入到了传统的因果识别框架,用它们来考察异质性处理效应。他们比较了四种不同的分类回归树算法——单树法(Single Tree)、双树法(Two Trees)、转化结果树法(Transformed Outcomes Tree)以及因果树法(Causal Tree),并特别强调了因果树法的作用。Wager and Athey(2015)推广了因果树方法,讨论了如何用随机森林(Random Forest)来处理异质性处理效应。Hill(2011)、Green and Kern(2012)则采用了另一种思路——贝叶斯可加性回归树(Bayesian Additive Regression Tree,简称BART)来考察异质性处理效应,这种方法在某种意义上可以被视为是贝叶斯版的随机森林方法。不过,BART方法的大样本性质目前仍然是不清楚的,因此其应用还存在着一定的局限。
关于机器学习在因果推断中的应用的更多介绍,可以参考Athey and Imbens(2016)的综述。这里有两点需要强调。首先,因果推断理论和机器学习理论的交叉并不是单向的。以图灵奖得主Judea Pearl为代表的一些人工智能专家认为,现在强人工智能技术不能得到突破的原因就在于现有的机器学习理论没有考虑因果性。如果没有因果性,就不能进行反事实分析(Counterfactual Analysis),智能体就无法应对纷繁复杂的现实情况。因此,这些学者建议,未来的机器学习应当考虑吸纳因果推断理论的成果,为实现自动化推理奠定基础。其次,在机器学习领域发展最快的深度学习到目前为止并没有在经济学研究中发挥作用。这可能是因为深度学习的学习过程本身是一个黑箱,不适合被用来作为因果识别的工具所致。
(二)人工智能在行为经济学中的应用
人工智能可以为行为经济学的研究提供一种思路。相对于传统的经济学,行为经济学的研究方法是十分开放的,它试图通过纳入其他学科(例如心理学、社会学)的理论,来解释传统经济学所不能解释的人类行为。可能解释人的行为的变量很多,究竟哪些变量真正有用就称为了问题,此时机器学习的方法就可以被用来帮助研究者选出那些真正有价值的变量。
目前,已有一些行为经济学的文献借用了机器学习的方法。例如,Camerer,Nave and Smith(2017)在分析“非结构化谈判”(unstructured bargaining)问题时采用了机器学习的方法,用其来帮助寻找影响谈判结果的行为要素。Peysakhovich and Naecker(2017)则利用机器学习的方法对人们在金融市场中的风险选择问题进行了研究。
除了指出机器学习在分析中的应用外,Camerer(2017)还将机器学习和人类的决策进行了对比。在他看来,人类的决策可以被认为是一种不完美的机器学习。过度自信、对于错误很少改正等行为缺陷在某种意义上可以被认为是机器学习中的“过度拟合”问题。从这个角度出发,Camerer认为人工智能的发展将会有助于人类更有效地进行决策。
三、作为研究对象的人工智能
作为一种新技术,人工智能技术已经进入了经济生活的各个领域,对生产、生活的各个方面都产生了重大影响。目前,已经有不少文献对这些影响进行了分析。在本节中,我们将分领域对这些研究进行一些简要的介绍。
(一)人工智能与经济增长
1、关于人工智能与经济增长的理论探讨
从理论渊源上看,关于人工智能对经济增长影响的讨论其实是关于自动化对经济增长影响讨论的延续。Zeira(1998)年曾提出过一个理论模型,用来分析自动化的增长效应的模型。在这个模型中,某一产业的产品可以通过两种技术——手工技术和工业技术进行生产。在这两种技术中,手工技术所需的劳动力投入更高,但所需的资本投入却更低。究竟两种技术中的哪一种被用来进行生产,取决于技术水平。如果生产率很低,那么更多依靠手工技术进行生产就更有利;而当生产率突破了一定的临界点时,转而采用工业技术进行生产就会变得更合算。这样,技术进步就会产生两个效应:一是直接对生产效率的提升;二是通过自动化来实现生产方式的改变。一个经济中有很多产业,不同产业实现自动化的临界条件不同,因此生产率的增长和自动化的程度将呈现一种连续函数关系。当自动化程度较高时,经济中的资本回报份额也就越高,因此当经济处于最优增长路径时,增长率将主要取决于两个条件:生产率的增长速度,以及经济中的资本回报份额,更高的生产率,以及更高的资本回报份额都会让经济获得更高速的增长。
Aghion et al(2017)对人工智能对经济增长的可能影响进行了全面的分析。他们的分析是从“人工智能革命”的两个效应——自动化和“鲍莫尔病”出发的。一方面,和其他任何的技术进步一样,人工智能的应用会在导致生产率提升的同时促进自动化进程的加速。这将会导致生产过程中人力使用的减少,从会让经济中的资本回报份额增加。但另一方面,“人工智能革命”也会遭遇所谓的“鲍莫尔病”,即非自动化部门的成本的提升,这会导致经济中资本回报份额的降低。一般来说,随着经济的发展,经济中的落后部门对经济发展的影响将会变得更为重要。在这种条件下,“鲍莫尔病”的影响将会变得更加不可忽视。
将两种效应综合起来看,人工智能的使用对经济增长的影响将是不确定的。虽然人工智能的使用可以确定地让生产率增长速度得到提升,但至少从短期看,它对于资本回报份额的影响却是不确定的。因此,并不能确定经济增长率究竟会如何变化。
在正常条件下,资本的回报份额不会无限上升,在稳态时它会维持在某个小于1的值,此时经济增长的速度将主要依赖于生产率的变化速度。据此可以得出结论,人工智能究竟如何影响经济增长,将主要取决于其对技术进步率的影响方式。如果人工智能带来的只是一次短期的冲击,那么它只会让生产率产生一次性的增加,其作用将是暂时的。而如果人工智能的应用会带来生产率的持续增加,那么经济增长率也将随之持续增加,从而出现“经济奇点”。在几位作者看来,“经济奇点”出现的最关键条件是突破知识生产这一瓶颈。这点是否能够实现,主要要看人工智能是否可以真正取代人类进行知识生产。
在论文中,几位作者还对增长的分配效应进行了探讨。在他们看来,人工智能技术的应用将会引发“技术偏向型”的增长,让高技能的工人获益,低技能的工人受损。而由技术导致的企业组织结构变化会强化这种效应——密集使用人工智能技术的企业会向本企业内部职工支付较高的工资,同时将一些技术含量较低的生产环节外包给工资更低的低技能工人。由这些因素造成的收入分配效应将是不容忽视的。
值得一提的是,在Aghion et al(2017)的讨论中,决定人工智能对增长影响的一个关键因素是人工智能会对创新、对知识生产产生怎样的作用,但关于这个问题,几位作者并没有作更多的展开分析。Agrawal et al(2017)的论文对此进行了补充。这篇论文借鉴Weitzman(1998)的观点认为,知识生产的过程很大程度上是一种对原有知识的组合过程,而人工智能的发展不仅有助于人们发现新的知识,更有助于人们将既有的知识进行有效的组合。几位作者在Jones(1995)的模型中植入了知识组合的过程,用这个新模型来分析了人工智能技术的影响。结果发现,人工智能技术的引入将通过促进知识组合来让经济实现显著的增长。
2、关于人工智能与经济增长的争论
关于人工智能会对经济增长产生怎样的影响,存在着很多的争议。在本节中,我们将对两个重要的争论进行讨论。第一个争论是,人工智能技术究竟能否真正带来经济增长。第二个争论是,人工智能技术是否可以真正引发“经济奇点”(Economic Singularity)的到来。
(1)人工智能是否能带来经济增长
关于这个问题的讨论,实际上是关于 “索洛悖论”(Solow Paradox)的讨论的继续。“索洛悖论”又称“生产率悖论”(Productivity Paradox),是由Robert Solow在探讨计算机的影响时提出的。当时,他感叹道:技术转变随处可见,但在统计数据却没有显示技术对增长产生的影响。此后,有不少研究都佐证了Solow的这个观察,认为包括计算机、互联网等新技术的出现并没有对经济增长产生实质性的影响。
这类观点的代表人物是Tyler Cowen和Robert Gordon。Cowen在一部畅销书中指出,被认为十分重要的计算机、互联网技术并没有像之前的技术革命那样让生产率获得突破性的进步,并且从目前的技术发展看看,所有“低垂的果实”都已经被摘尽了,因此经济将会陷入长期的“大停滞”。而Gordon则由对美国的经济增长状况的长期趋势进行分析发现,最近的技术进步实际上只带来了很低的生产率进步。
人工智能技术的兴起也同样遭遇了“索洛悖论”的质疑。尽管从直观上看,人工智能对生产生活的各个方面都产生了重要影响,但到目前为止,经验证据却同样难以对这种影响给予证实。在一次著名的辩论中,Gordon等学者对人工智能的作用提出了质疑,认为人们对其的期盼显然是过高了。
针对“技术怀疑论者”的质疑,以Brynjolfsson为代表的“技术乐观派”旗帜鲜明地表达了反对。在Brynjolfsson及其合作者看来,以计算机、互联网为代表的现代技术毫无疑问对提高生产率和促进经济增长起到了关键作用,而人工智能等新技术的影响可能还要更为巨大。
至于为什么从统计中并不能看出人工智能等技术的贡献,Brynjolfsson et al(2017)给出了详细的讨论。在他们看来,有四种可能的原因可以被用来解释人们对技术进步的主观感受和统计数据之间的背离。第一种解释是“错误的希望”(false hopes),即人们确实高估了技术进步的作用,而实际上技术并没有能带来人们所期盼的生产率进步。第二种解释是“测量误差”(mismeasurement),即统计数据并没有真正反映出技术进步所带来的产出,因而就对其增长效应做出了低估。第三种解释是“集中化的分配和租值耗散”(concentrated distribution and rent dissipation),即尽管人工智能等新技术确实可以带来生产率的增长,但只有部分明星企业享受到了由此带来的好处。这不仅加剧了收入分配的不平等,也让少数企业获得了更高的市场力量,而这些因素反过来会导致生产率的下降。第四种解释是执行滞后 (implementation lag)。新技术作用的发挥,需要配套的技术、基础设施,以及组织结构的调整作为基础。而在目前看来,这些配套工作是相对滞后的,因此就可能导致人工智能的力量不能充分得到发挥。几位作者在对上述四种可能的解释进行了逐一检验后发现,最后一种解释是最有说服力的。因此,他们认为人工智能的作用是不可忽视的,但现阶段滞后的配套工作限制了其作用的发挥。随着相关配套工作的完成,“人工智能革命”的力量将会逐步释放出来。
(2)人工智能是否会带来“经济奇点”
“奇点”(Singularity)最初是一个数学名词,指的是没有被良好定义(例如趋向于无穷大),或者出现奇怪属性的点。未来学家Kurzweil在自己的书中借用了这个名词,用来指人工智能超越人类,从而引发人类社会剧变的关键时刻。而所谓“经济奇点”,指的则是一个关键的时间点,当越过这个时间点后经济将保持持续增长,并且增长速度会持续加快。
在历史上,有不少经济大师曾对“经济奇点”有过憧憬,宏观经济学的创始人凯恩斯、诺贝尔奖得主赫尔伯特·西蒙都是其中的代表。尽管截止目前这些憧憬都没有变成现实,但随着人工智能技术的发展,关于“经济奇点”的讨论又开始高涨。一些“技术乐观派”学者认为,由于人工智能可以大幅提升生产率,并且可以完成很多人类无法完成的任务,因此“经济奇点”不久就会到来。
这种“技术乐观派”的观点引发了很多争议。Nordhaus(2015)从经验方面对此给出了质疑。Nordhaus指出:首先,随着新技术的发展成熟,它们的价格急剧下降,因此它们的相关产业对经济的贡献也迅速下滑。这意味着,相对落后的产业,而非新产业将成为经济增长的关键。其次,尽管人们给予了互联网、人工智能等新技术很多希望,但它们并没有能切实带来生产率的大幅度提高。再次,至少从美国的现实看,目前投资品的价格并没有出现急速的下滑,投资也没有出现迅速增长的势头。综合以上几点分析,Nordhaus认为“经济奇点”可能还只是一个遥远的梦想。Aghion et al(2017)从理论上对“经济奇点”进行了分析。他们认为,“经济奇点”是否能到来,主要要看知识增长的瓶颈能否打破。尽管内生增长模型已经说明了知识作为一种产品是可以生产的,但这个过程是需要人的参与的。随着经济增长的进行,人口增长减缓,能作为生产要素投入到知识生产过程的人力也会减少。除非人工智能可以替代人类从事创意工作、进行知识生产,否则这一重要瓶颈就很难被突破。而至少在现在,人工智能还没有发展到这一水平。
(二)人工智能与就业
技术的进步在推进生产率提升的同时,会带来“技术性失业”。作为一项革命性的技术,人工智能当然也不例外。与以往的历次技术革命相比,“人工智能革命”对就业的冲击范围将更广、力度将更大、持续也将更久。
目前,人工智能对就业的可能冲击已经成为了重要的政策话题,有不少文献对此进行了探讨。需要指出的是,由于在讨论人工智能对就业和收入分配的影响时,通常把人工智能作为一种强化版的自动化来处理,因此在以下两节中,我们在介绍人工智能影响的文献外,还将介绍自动化和机器人影响的文献。
1、关于人工智能和自动化就业影响的理论分析
Autor et al(2003)提出的ALM模型是研究人工智能和自动化的就业影响的基准模型。在ALM模型中,生产需要两种任务——程式化任务和非程式化任务配合,其中程式化任务只需要低技能劳动,而非程式化任务则需要高技能劳动。在几位作者看来,自动化只能用来完成程式化任务,而不能用来完成非程式化任务,因此它对低技能劳动形成了替代,而对高技能劳动则形成了互补。在这种假设下,自动化的冲击将是偏向性的,它对低技能劳动者造成损害,但却会给高技能劳动者带来好处。Frey and Osborne(2013)对ALM模型进行了拓展。在新的模型中,而非程式化任务则既需要程式化劳动需要高技能劳动和低技能劳动的共同投入。在这种设定下,自动化对于高技能劳动者的作用将是不确定的,在一定条件下它们也会受到自动化的损害。
Benzell et al(2015)在一个跨期迭代(OLG)模型中讨论了机器人对劳动力进行替代的问题。他们指出,在一定条件下,机器人可以完全替代低技能工作,并替代一部分高技能工作,这会导致对劳动力需求的减少和工资的下降。虽然在采用机器人后,由生产率提升会带来的价格下降可以在一定程度上改善劳动者福利,不过从总体上讲它并不能完全弥补就业替代对劳动力造成的损害。因此,几位作者认为机器人的使用可能会带来所谓的“贫困化增长”(Immiserizing Growth)——虽然经济增长了,但社会福利却下降了。为了防止这种现象的发生,几位作者建议要推出针对性的培训计划,并对特定世代的人群进行补贴。
Acemoglu and Restrepo构造了一个包括就业创造的模型。在模型中,自动化消灭某些就业岗位的同时,也会创造出劳动更具有比较优势的新就业岗位,因此其对就业的净效应要看两种效应的相对程度。他们发现,在长期均衡的条件下,结果取决于资本和劳动的使用成本。如果资本的使用成本相对于工资足够地低,那么所有职业都将被自动化;反之,自动化就会有一定的界限。此外,几位作者还指出,如果劳动本身是异质性的,那么自动化的进行还将导致劳动者内部收入差异的产生。
2、关于人工智能和自动化就业影响的实证分析
Autor et al (2003)对1960-1998年的美国劳动力市场进行了分析。结果发现在1970年之后,“计算化”(Computerization)导致了“极化效应”——对程式化工作的需求大幅下降,但同时导致了对非程式化工作需求的增加。尤其是在1980年之后,这种趋势更加明显。Goos and Manning(2007)利用英国数据对ALM模型的结论进行了检验,结果发现技术进步在英国也导致了“极化效应”的出现。随后,Autor and Dorn(2013)、Goos et al(2014)等文献分别对美国和欧洲的数据进行了分析,也同样发现了“极化效应”的存在——在技术进步的冲击下,大批制造业的就业机会被服务业所抢占。
Graetz and Michaels(2015)分析了1993-2007年间17个国家的机器人使用及经济运行状况。发现平均而言机器人的使用让这些国家的GDP增速上涨了0.37个百分点。同时,机器人的使用还让生产率获得了大幅增加,并减少了中、低端技能工人的劳动时间和强度。Acemoglu and Restrepo(2017)利用1990年到2007年间美国劳动力市场的数据进行了研究。结果发现,机器人和工人的比例每增加千分之一,就会减少0.18%-0.34%的就业岗位,并让工资下降0.25%-0.5%。
3、关于人工智能和自动化就业影响的预测和趋势分析
除了实证研究外,也有不少学者采用不同的方法对人工智能对就业的影响进行了预测,其结果相差很大。Frey and Osborne(2013)曾对美国的702个就业岗位被人工智能和自动化替代的概率进行了分析,结果表明47%的岗位面临着被人工智能替代的风险。Chui,Manyika,and Miremadi, (2015)则预测,美国45%的工作活动可以依靠现有技术水平的机器来完成;而如果人工智能系统的表现可以达到人类中等水平,该数字将增至58%。相比之下,Arntz, M., Gregory,T., and Zierahn(2016)的预测则要乐观得多,他们认为OECD国家的工作中,只有约9%的工作会被取代。在国内,陈永伟和许多(2018)用Frey and Osborne(2013)的方法对中国的就业岗位被人工智能取代的概率进行了估计,结果显示在未来20年中,总就业人的76.76%会遭受到人工智能的冲击,如果只考虑非农业人口,这一比例是65.58%。
除了基于计量方法的预测外,也有一些经济史学者根据历史经验对人工智能的就业影响进行了分析。在一次麻省理工学院组织的研讨会上,Gordon指出从第一次工业革命以来的这250年间,还没有哪个发明引起了大规模的失业。尽管工作岗位持续地在消失,却有更多的就业机会涌现了出来。在他看来,同样的机制将会保证“人工智能革命”并不会造成剧烈的冲击。而Mokyr则认为,随着经济的发展,服务性行业的比例将会上升,这些行业相对来说较难被人工智能所替代。即使人工智能替代了其中的一部分岗位,但老龄化等问题会带来巨大的劳动力需求,由此提供的就业岗位将足以抵消人工智能带来的影响。
此外,还有一些学者认为在分析人工智能的就业影响时,应当综合考虑其他各种因素。例如Goolsbee(2018)认为现有的研究大多是从技术可行性角度去思考人工智能的就业影响,而没有分析价格因素和调整成本,也没有考虑冲击的持续时间。显然,如果忽略了这些因素,只是抽象地说人工智能会替代多少劳动力,其政策意义将大打折扣。
4、对于人工智能就业影响的政策探讨
尽管不同学者关于“人工智能革命”影响的估计存在很大差异,但大部分学者都认为,同历史上的各次技术革命一样,“人工智能”在长期将会创造出足够多的新岗位以代替被其摧毁的岗位,因此问题的关键就是通过政策平滑好短期的冲击,让就业结构完成顺利转换。
应对短期就业冲击的最重要政策是加强教育。很多研究指出,“人工智能革命”对就业的最大影响并不是让就业岗位绝对减少了,而是从旧岗位被淘汰的那部分劳动者不适应新岗位。因此,为了让劳动者们适应新岗位,政府应当负责提供教育和职业指导。由于“人工智能革命”的冲击是持续性的,因此相关的教育也应当有持续性。为了解决失业人员的培训支出,可以探索“工作抵押贷款”,让失业人员以未来获得的工作为抵押来获取贷款,用以进行相关培训。
(三)人工智能与收入分配
人工智能可能通过多个渠道对收入分配发生影响。首先,从理论上讲,人工智能是一种偏向性的技术(Directed Technical Change或Biased Technical Change),它的使用会对不同群体的边际产出产生不同作用,进而影响他们的收入状况。这中效应体现在两个层次上,第一个层次是在不同要素之间,这主要会影响不同要素回报的分配;第二个层次是在劳动者内部,这主要影响不同技能水平的劳动者的收入分配。其次,人工智能的使用还会对市场结构造成改变,让一些企业获得更高的市场力量,进而让企业拥有者获得更多的剩余收入。当然,以上这些效应最终如何起作用,还和相关的政策有很大关系。
1、人工智能对于要素回报的影响
要素回报的差异是造成收入分配差别的最主要原因之一。近年来,资本回报率在全世界范围内都呈现出了增加的趋势,更多的收入和财富向少数资本所有者聚集,这导致了不平等的加剧。而人工智能技术的应用,则可能强化这种要素收益的不平等。
人工智能是一种“技术偏向性”的技术。一方面,它的普及将会减少市场上对劳动力的需求,进而降低劳动力的回报率;而与此同时,作为一种资本密集型技术,它可以让资本回报率大为提升。在这两方面因素的作用下,资本和劳动这两种要素的回报率差别会继续扩大,这会引发收入不平等的进一步攀升。
2、人工智能对不同劳动者的影响
技术的偏向性不仅体现在不同生产要素之间,还体现在劳动者群体内部,不同技能劳动者在面临技术进步后,其收入变化会有很大差异。从性质上看,人工智能是技术偏向性的,它对于不同就业岗位的冲击并不相同。人工智能的一个重要作用是自动化,而目前已有很多研究证明了自动化对不同技能劳动者带来的不同影响。在现阶段,遭受自动化冲击较为严重主要是那些以程式化任务为主,对技能要求较低的职业。自动化的普及不仅压低了从事这些职业的劳动者的收入,还造成了相当数量的相关人员失业。而如此同时,自动化对那些非程式化、对技能要求较高的职业,则主要起到了强化和辅助作用,因此面对“人工智能革命”的冲击,从事这些职业的劳动者的收入不仅没有下降,反而出现了上升。尽管关于人工智能的技能偏向性的研究还较少,但从逻辑上讲,作为一种实现高级自动化的技术,它也将会产生类似的效应。
需要指出的是,随着人工智能技术的发展,自动化的范围已经不再像过去那样局限于程式化较强,对技能要求较低的职业,很多程式化较低、对技能要求很高的职业,如医生、律师也面临着自动化的冲击。在这种背景下,当分析自动化的影响时就需要对自动化的类别进行分析。如果自动化是对低技能劳动进行替代,那么它将会扩大工资的不平等;而如果自动化是对高技能劳动进行替代,那么它或许将有助于缩小收入的不平等。
3、人工智能对利润分配的影响
除了改变要素的边际收益外,人工智能还会可能通过另一条间接渠道——改变市场力量来对收入分配产生影响。
经济学的基本理论告诉我们,当市场结构不是完全竞争时,市场中的企业就可能获得经济利润,而经济利润的高低则和企业的市场力量密切相关。近年来,世界各国的市场结构都呈现出了集中的趋势,大量占据高市场份额的“超级明星企业”(Superstar Firms)开始出现,并凭借巨大的市场力量获得巨额利润。不少学者认为,高技术的使用是导致“超级明星企业”一个重要原因,而人工智能作为一种重要的新技术显然会强化这一趋势。不过,就笔者所知,目前还没有文献对人工智能影响收入分配的这一渠道进行过专门的实证分析,因此这种猜测暂时只存在于理论层面。
4、政策对人工智能分配效应的影响
技术变迁的收入分配效应必然受到政策因素的影响,合理的政策措施可以让技术变迁过程更有包容性,使所有人更好地共享技术变迁的成果。Korinek and Stiglitz(2017)曾对“人工智能革命”中的分配政策进行过讨论。他们指出,尽管像人工智能这样的技术进步可以让社会总财富增加,但由于现实世界中的人们不可能完全保险,也不可能进行无成本的收入分配,因此就难以让这些技术进步带来帕累托改进,在一些人因技术进步受益的同时,另一些人则会受到损害。为了扭转这种情况,政策的介入是必要的。政策必须对技术进步带来的两种效应——剩余的集中和相对价格的变化做出回应,而为了达到目的,税收、知识产权政策、反垄断政策等政策都可以发挥一定作用。Kaplan(2015)对相关收入分配政策进行了全面探讨。他建议,考虑到人工智能对不同人群带来的不同影响,应该考虑对那些因这项技术获益的人征税,用来补贴因此而受损的人们。Cowen(2017)指出,良好的社会规范将有助于政策作用的发挥,因此在进行收入分配时,必须要注意相关的社会规范的培育。
(四)人工智能与产业组织
毫无疑问,人工智能技术的发展将对产业组织和市场竞争产生极为显著的影响。它将通过影响市场结构、企业行为,进而影响到经济绩效,而所有的这些现象都将对传统的规制和竞争政策提出新的挑战。
1、人工智能对市场结构的影响
人工智能对于市场结构的影响是通过两个渠道进行的。第一个渠道是技术的直接影响。使用人工智能技术的企业可以获得生产率的跃升,这将使它们更容易在激烈的市场竞争中胜出。同时由于人工智能技术需要投入较高的固定成本,但边际成本却较低,因此这就能让使用人工智能的企业具有了较高的进入门槛。这两个因素叠加在一起,导致了市场变得更为集中。第二个渠道是技术引发的企业形式变革。企业的组织形式是随技术的变化而变化的。在人工智能技术的冲击下,平台(Platform)正在成为当今企业组织的一种重要形式。由于平台通常具有“跨边网络外部性”,因而会导致“鸡生蛋、蛋生鸡”似的正反馈效应,这让平台企业可以迅速膨胀占领市场,并形成一家独大的现象。 综合以上两种因素,人工智能技术的迅速发展推动了一批“超级巨星企业”企业的出现,并让市场迅速变得高度集中。
需要指出的是,人工智能对于市场结构的影响不仅反映在横向关系上,还反映在纵向关系上。Shapiro and Varian(2017)指出,由于机器学习的特殊性,那些采用机器学习的企业更倾向于垂直联合以获取更多数据并削减机器学习的成本。根据这一理论我们可以预见,随着人工智能技术的发展,大型平台企业对下游的并购趋势将会加强,而推动这种并购整合的动因将不再是争夺直接的利润或市场份额,而是争夺数据资源。
2、人工智能对企业行为的影响
人工智能技术的发展将会对企业的不少行为发生影响。很多以前难以采用的策略将会变成现实。
一个例子是算法歧视(Algorithmic Discrimination)。在传统的经济学中,由于企业的信息越苏,“一级价格歧视”只在理论上出现。而在人工智能时代,借用大数据和机器学习,企业将有可能对每个客户精确画像,并有针对性地进行索价,从而实现“一级价格歧视”,获得全部的消费者剩余。即使企业不进行“一级价格歧视”,人工智能技术也能够帮助他们更好地进行二级或三级价格歧视,从而更好地攫取消费者剩余。
另一个例子是算法合谋(Algorithmic Collusion)。合谋一直是产业组织理论和反垄断法关注的一个重要问题。市场上的企业可以通过合谋来瓜分市场,从而提升企业利润的目的。产业组织理论的知识告诉我们,企业的这种合谋会导致产量减少、价格上升、消费者福利受损。但是,在传统的经济条件下,由于存在信息交流困难以及“囚徒困境”等问题,合谋是很难持久的。尽管从理论上讲,重复博弈机制可以帮助企业合谋的实现,但事实上由于难以监督违约、难以惩罚违约,以及难以识别经济信息等问题的存在,这也很难真正达成。但随着人工智能技术的发展,过去很难达成的合谋将会变成可能。与过去不同的是,企业之间的合谋不再需要相互猜测合谋伙伴的行动,也无需要通过某个信号来协调彼此的行为。只要通过某种定价算法,这些问题都可以得到解决。在这种背景下,企业数量的多少、产业性质等影响合谋难度的因素都变得不再重要,在任何条件下企业都可以顺利进行合谋。
除了算法歧视以及算法合谋外,人工智能技术的发展还会引发很多新的竞争问题。例如,平台企业可以借助搜索引擎影响人们的决策,或者通过算法来影响人们在平台上的匹配结果。
(五)人工智能与贸易
人工智能对于贸易产生的影响将是多方面的:其一,作为一种重要的技术进步,人工智能将对要素回报率产生重大影响,并改变不同要素之间的相对回报状况,这会让各国的动态比较优势状况发生明显的变化。其二,作为一个新兴的产业,人工智能的相关技术和人才也成为了贸易的重要对象,而各国的战略性贸易政策将会对该产业的发展产生关键作用。其三,在微观上,人工智能的使用也将影响企业的生产率状况,根据“新新贸易理论”,这将会影响企业的出口决策。
不过,目前在现有文献中直接讨论人工智能与国际贸易的文献还相对较少,就笔者所知,Goldfarb and Trefler(2018)是目前唯一一篇对这一问题进行专门讨论的论文。在这篇论文中,两位作者首先指出了人工智能产业的两个重要特点:规模经济以及知识密集。人工智能产业对于数据的依赖非常强,规模经济的属性决定了它们在人口基数更为庞大、各类交易数据更为丰富的国家(如中国)更容易得到发展。而知识密集的特征则决定了知识的扩散、传播方式将对各国人工智能的发展起到重要影响。
在认识了人工智能产业的基本特征后,两位作者讨论了战略性贸易保护政策在发展人工智能产业过程中的有效性。在两位作者看来,传统的战略性贸易保护文献有一个重要的缺陷,即只有当存在着利润时,战略性贸易保护政策才是起作用的。但是,一旦产业由于政府的保护而产生了超额利润,只要进入门槛足够低,更多的企业就会进入这个产业,直至利润被压缩到零。而在这种情况下,战略性贸易保护政策就失效了。由于人工智能产业具有很强的网络外部性,所以在这个产业中有企业先行发展起来,其规模就为其构筑起很高的进入门槛,这意味着即使产业有很高的利润也不会有新企业继续进入。在这种条件下,战略性贸易保护政策就会变得更有效了。
两位作者通过几个模型对几类政策,如补贴政策、人才政策,以及集群政策的影响进行了讨论。他们指出,这些政策究竟是否能成功,主要要看人工智能所依赖的知识外部性究竟来自于本国范围还是世界范围。如果人工智能依赖的知识外部性主要来自于本国,那么政府就可以通过产业政策和战略性贸易保护政策对企业进行有效扶持,从而让企业在世界范围内更具有竞争力。但如果人工智能依赖的知识外部性是全世界范围内的,由于知识的扩散会相当容易,因此以上政策的作用就不会明显。
在论文的最后,两位作者着重对隐私政策进行了讨论。从经验上看,更强的隐私保护会限制企业对数据的获取,进而会阻碍以数据为关键资源的人工智能产业的发展。因此,在实践中,隐私保护政策经常被作为隐性的贸易保护政策来对付国外企业。但这两位作者看来,这类政策也同时会损害本国企业,因此是不可取的。他们建议,出于支持本国企业的目的,政府可以采用其他一些扶持政策,例如数据本地化规则、对政府数据访问的限制、行业管制、制定本地无人驾驶法规,以及强制访问源代码等。
(六)人工智能与法律
人工智能的兴起带来了很多新的法律问题。例如,人工智能在一定程度上可以替代或辅助人进行决策,那么在这个过程中人工智能是否应该具有法律主体地位?在应用中,人工智能需要利用其他设备或软件运行过程中的数据,那么谁是这些数据的所有人,谁能够作出有效的授权?在遭遇人工智能造成的事故或产品责任问题时,应该如何区分人工操作还是人工智能本身的缺陷?对于算法造成的歧视、合谋等行为应当如何应对?……这些问题都十分实际,但却充满了争议。限于篇幅,笔者只想对两个问题进行专门讨论,对于更多人工智能引发的法律问题的探讨,可以参考Pagallo(2013),Erzachi and Stucke(2016),Stucke and Grunes(2016)等著作。
1、人工智能带来的隐私权问题
现阶段人工智能的应用是和数据密不可分的。例如商家在利用人工智能挖掘消费者偏好时,就必须依赖从消费者处搜集的数据(包括身份信息、交易习惯数据等)。对于消费者来讲,让商家搜集这些数据将是有利有弊的——一方面,这些数据可以让商家更充分地了解他们的偏好,从而为他们更好地服务;另一方面,消费者的这些数据被搜集后也会带来很多问题,例如可能被商家进行价格歧视,受到商家的推销骚扰,在部分极端的情况下甚至可能因此而受到人身方面的威胁。
在数据的搜集和交换不太频繁的情况下,消费者在遭受因数据引发的麻烦时很容易追踪到责任源头,因此他们可以有效地对出让数据而带来的风险进行成本收益分析。在理性决策下,一些消费者会选择自愿出让自己的数据。但是,随着大数据和人工智能技术的发展,这种情况发生了改变:(1)商家在搜集了数据后可以更持久保存,可以在未来进行更多的使用,因此消费者出让数据这一行为带来的收益和遭受的累积风险之间将变得十分不对称;(2)由于现在商家搜集数据的行为已经变得十分频繁,当消费者遭受了数据相关的问题后也很难判断究竟是哪个商家造成的问题,因此事实上就很难进行追责;(3)商家在搜集消费者数据后,可能并没有按照其事先向消费者承诺的那样合理使用数据,而消费者却很难惩罚这种行为。
在上述背景下,如何对数据使用进行有效治理,如何在保护消费者合法权益的基础上有效利用数据就成为了一个需要尤其值得关注的问题。目前,对于人工智能条件下如何保护消费者隐私的争议很多,有学者认为应当由政府进行更多监管,有学者认为应当由企业自身进行治理,有学者则认为应该由民间团体组织治理。总体来讲,几种思路都各有其利弊,因此这一问题目前仍然是一个开放性问题。
2、人工智能的产品责任问题
人工智能及使用人工智能技术的设备(如机器人)可以大幅度提高生产率,但同时也会更大的使用风险。在这种背景下,界定人工智能的产品责任,明确一旦发生了事故,究竟人工智能制造者需要为此承担多大责任,就成为了一个关键的问题。
在讨论类似人工智能这样的高新技术的产品责任时,一个需要着重考虑的问题是责任划分对创新激励的影响。在一篇较近的论文中,Galasso(2017)对这个问题进行了讨论。他建立了一个简单的模型:企业可以选择人工智能产品的研发强度,研发强度会改变产品对企业带来的收益,以及产品发生事故的概率。一旦事故发生,企业会承担一个固定的损失,法律决定了发生事故时企业需要承担的责任比例。Galasso求解了企业利润最大化时企业的最优研发强度。结果发现,产品责任的划分会影响产品的研发响度,要求企业承担更多责任会增加安全产品的研发强度,减少危险产品的研发强度;反之,如果要求企业承担更少责任会减少安全产品的研发强度,增加危险产品的研发强度。不过,只要研发带来的收益足够高,安全责任将不会对是否研发的决策产生影响,而只会改变边际上的研发强度,从而影响技术革新的速度。据此,Galasso认为在考察人工智能相关产品的产品责任问题时,应当十分重视其对创新的影响,并强调应该对成本收益的动态效应进行关注。
四、结论
作为一门致用之学,经济学是在回应现实发展的过程中不断发展的。每一次重大的技术进步都会带来生产生活的巨大改变,而这些改变最终也会体现在经济学上。第一次工业革命带来的生产方式和阶级结构的变化为李嘉图、马克思等经济学家的研究提供了鲜活的素材;第二次工业革命带来的经济结构变化和社会结构的变化催生了宏观经济学、产业经济学、发展经济学等经济学分制;信息革命则为产业组织、信息经济学和网络经济学的应用提供了用武之地。
相比于之前的历次技术进步,“人工智能革命”所引发的冲击更为巨大,其对经济学造成的影响也将更为广泛和深远。相信在不久的将来,人工智能将作为重要的研究工具和研究议题进入经济学的主流。
在本文中,笔者对近期以来有关人工智能的经济学文献进行了一些梳理和介绍,希望这些微小的工作可以为有志于研究人工智能的经济学者提供一些借鉴和帮助。由于这支文献发展很快,所以这个综述难免挂一漏万,加之笔者水平所限,其中可能还会有不少错误,关于这些,还望各位读者可以不吝批评指正。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。由互联网进化论作者,计算机博士刘锋与中国科学院虚拟经济与数据科学研究中心石勇、刘颖教授创建。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

(精简))
)

(精简))


![[导入]韩语基本会话](http://pic.xiahunao.cn/[导入]韩语基本会话)

(精简))

)


(精简))

)
)

(精简))
