post请求:
post的请求参数,是不会拼接在url后面的,而是需要放在请求对象定制的参数中
post请求的参数需要进行两次编码,第一次urlencode:对字典参数进行Unicode编码转成字符串,第二次encode:将字符串数据转换为字节类型
- 打开百度翻译
- F12打开控制台,输入hello


- 找到想要的参数后,开始写代码
import urllib.request
import urllib.parse# post请求
url = 'https://fanyi.baidu.com/sug'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.200.400 QQBrowser/11.8.5310.400',
}data = {'kw': 'hello'
}# post请求的参数,必须要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')# post的请求参数,是不会拼接在url后面的,而是需要放在请求对象定制的参数中
request = urllib.request.Request(url, data, headers)
# 模拟浏览器发送请求
response = urllib.request.urlopen(request)
# 获取响应数据
content = response.read().decode('utf-8')
# 把字符串变为json对象
import json
obj = json.loads(content)
print(obj)
注意:
- post请求必须编码,编码之后必须调用encode方法 urllib.parse.urlencode(data).encode(‘utf-8’)
- 参数是放在请求对象定制的方法中 urllib.request.Request(url, data, headers)
请求百度翻译详细翻译:
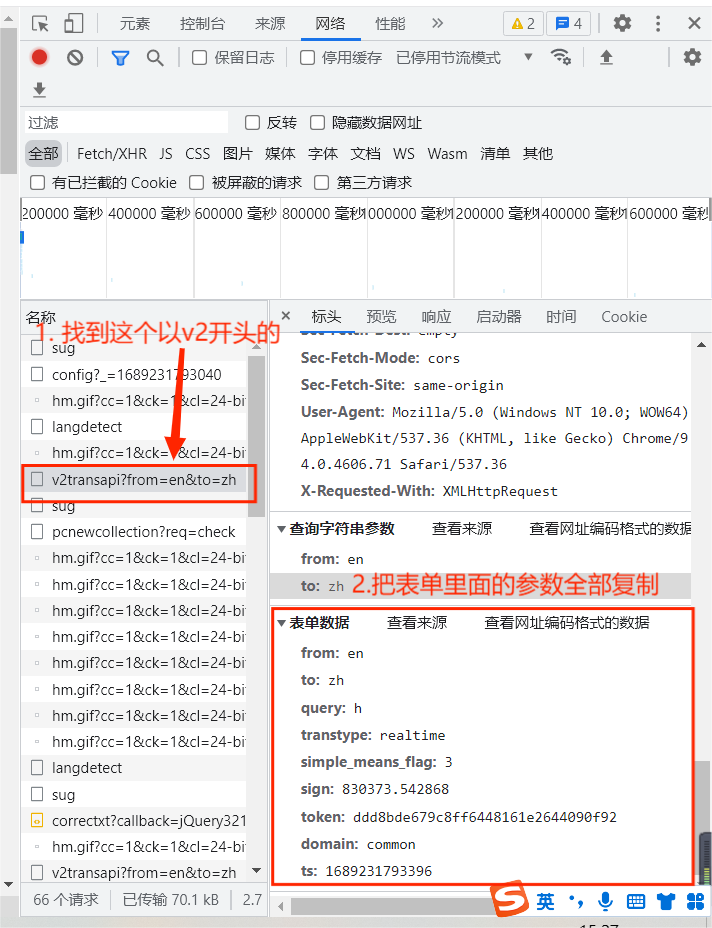
复制到data里面
data = {'from': ' en','to': ' zh','query': ' h','transtype': ' realtime','simple_means_flag': ' 3','sign': ' 830373.542868','token': ' ddd8bde679c8ff6448161e2644090f92','domain': ' common','ts': ' 1689231793396',
}
heads里面加上自己的Cookie
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.200.400 QQBrowser/11.8.5310.400','Cookie': ''
}












)





)
