JSONPath 解析 JSON 内容详解(翻译自 github):https://blog.csdn.net/freeking101/article/details/103048514
JSONPath Online Evaluator:http://jsonpath.com
Python 处理 JSON 我选择 ujson 和 orjson:https://blog.csdn.net/weixin_40247412/article/details/109302522
一、jsonpath
1. jsonpath介绍
用来解析多层嵌套的 json 数据;JsonPath 是一种信息抽取类库,是从 JSON 文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
使用方法:
import jsonpathres=jsonpath.jsonpath(dic_name,'$..key_name')
# 嵌套 n 层也能取到所有 key_name 信息,
# 其中:“$”表示最外层的{},
# “..”表示模糊匹配,当传入不存在的 key_name时,程序会返回false2. JsonPath 对于 JSON 来说,相当于 XPath 对于 XML
jsonpath 安装:pip install jsonpath
官方文档:http://goessner.net/articles/JsonPath
jsonpath-rw:JSONPath 的一个健壮且显著扩展的Python实现,带有一个明确的AST用于元编程。
jsonpath-rw 介绍:https://pypi.org/project/jsonpath-rw/
jsonpath-rw 安装:pip install jsonpath-rw
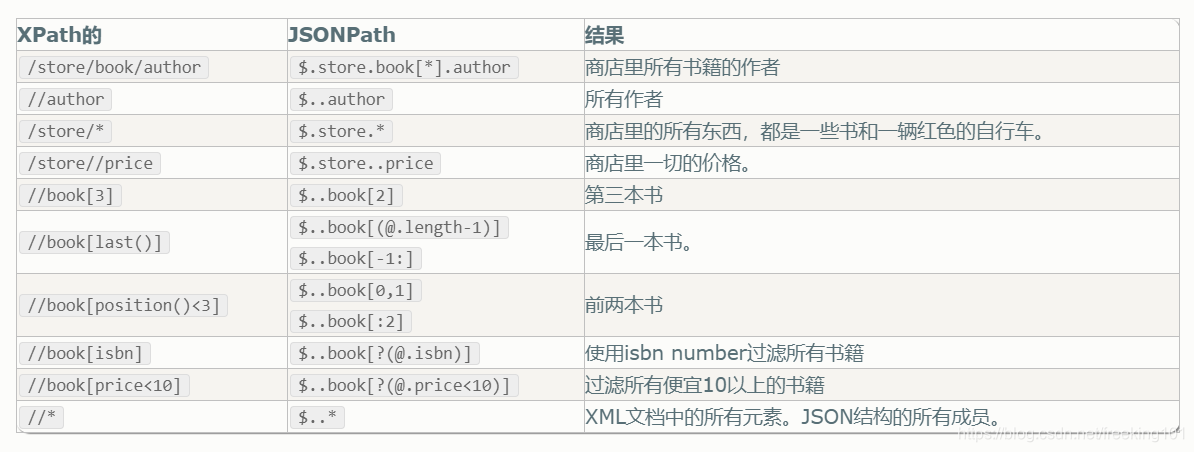
3. JsonPath 与 XPath 语法对比:
Json 结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath 的用法。

对比:
Python 使用示例:
# 使用格式: jsonpath.jsonpath(匹配的字典,'jsonpath表达式')# 找 d字典下面所有的name对应的值,返回一个列表
res2 = jsonpath.jsonpath(d,'$..name') 示例:
import jsonpathdef learn_json_path():book_store = {"store": {"book": [{"category": "reference","author": "Nigel Rees","title": "Sayings of the Century","price": 8.95},{"category": "fiction","author": "Evelyn Waugh","title": "Sword of Honour","price": 12.99},{"category": "fiction","author": "Herman Melville","title": "Moby Dick","isbn": "0-553-21311-3","price": 8.99},{"category": "fiction","author": "J. R. R. Tolkien","title": "The Lord of the Rings","isbn": "0-395-19395-8","price": 22.99}],"bicycle": {"color": "red","price": 19.95}},"expensive": 10}# print(type(book_store))# 查询store下的所有元素print(jsonpath.jsonpath(book_store, '$.store.*'))# 获取json中store下book下的所有author值print(jsonpath.jsonpath(book_store, '$.store.book[*].author'))# 获取所有json中所有author的值print(jsonpath.jsonpath(book_store, '$..author'))# 获取json中store下所有price的值print(jsonpath.jsonpath(book_store, '$.store..price'))# 获取json中book数组的第3个值print(jsonpath.jsonpath(book_store, '$.store.book[2]'))# 获取所有书print(jsonpath.jsonpath(book_store, '$..book[0:1]'))# 获取json中book数组中包含isbn的所有值print(jsonpath.jsonpath(book_store, '$..book[?(@.isbn)]'))# 获取json中book数组中price<10的所有值print(jsonpath.jsonpath(book_store, '$..book[?(@.price<10)]'))if __name__ == '__main__':learn_json_path()4. 使用实例
示例代码 1:
d={"error_code": 0,"stu_info": [{"id": 2059,"name": "小白","sex": "男","age": 28,"addr": "河南省济源市北海大道32号","grade": "天蝎座","phone": "18378309272","gold": 10896,"info":{"card":434345432,"bank_name":'中国银行'}},{"id": 2067,"name": "小黑","sex": "男","age": 28,"addr": "河南省济源市北海大道32号","grade": "天蝎座","phone": "12345678915","gold": 100}]
}res= d["stu_info"][1]['name'] #取某个学生姓名的原始方法:通过查找字典中的key以及list方法中的下标索引
print(res) #输出结果是:小黑import jsonpath
res1=jsonpath.jsonpath(d,'$..name') #嵌套n层也能取到所有学生姓名信息,$表示最外层的{},..表示模糊匹配
print(res1) #输出结果是list:['小白', '小黑']res2= jsonpath.jsonpath(d,'$..bank_name')
print(res2) #输出结果是list:['中国银行']res3=jsonpath.jsonpath(d,'$..name123') #当传入不存在的key(name)时,返回False
print(res3) #输出结果是:False示例代码 2:
以拉勾网城市 JSON 文件 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市。
import json
import jsonpath
import requestsurl = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json'custom_headers = {"Accept": "*/*","Accept-Encoding": "gzip, deflate, br","Accept-Language": "zh-CN,zh;q=0.9","Cache-Control": "max-age=0","Connection": "keep-alive","Host": "www.lagou.com","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ""(KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36"
}response = requests.get(url, headers=custom_headers)
json_obj = json.loads(response.text)
print(json_obj)# 从根节点开始,匹配name节点
city_list = jsonpath.jsonpath(json_obj, '$..name')
print(city_list)
print(type(city_list))# A 下面的节点
jp = jsonpath.jsonpath(json_obj, '$..A.*')
print(jp)# A 下面节点的name
jp = jsonpath.jsonpath(json_obj, '$..A.*.name')
print(jp)# C 下面节点的name
jp = jsonpath.jsonpath(json_obj, '$..C..name')
print(jp)# C 下面节点的第二个
jp = jsonpath.jsonpath(json_obj, '$..C[1]')
print(jp)# C 下面节点的第二个的name
jp = jsonpath.jsonpath(json_obj, '$..C[1].name')
print(jp)# C 下面节点的2到5的name
jp = jsonpath.jsonpath(json_obj, '$..C[1:5].name')
print(jp)# C 下面节点最后一个的name
jp = jsonpath.jsonpath(json_obj, '$..C[(@.length-1)].name')
print(jp)with open('city.json', 'w', encoding='utf-8') as f:content = json.dumps(city_list, ensure_ascii=False, indent=4)print(content)f.write(content)注意事项:
json.loads() 是把 Json 格式字符串解码转换成 Python 对象,如果在 json.loads 的时候出错,要注意被解码的 Json 字符的编码。
如果传入的字符串的编码不是 UTF-8 的话,需要制定字符编码的参数:encoding
dataDict = json.loads(jsonStrGBK);dataJsonStr 是 JSON 字符串,假设其编码本身是非 UTF-8 的话而是 GBK 的,那么上述代码会导致出错,改为对应的。
dataDict = json.loads(jsonStrGBK, encoding="GBK")如果 dataJsonStr 通过 encoding 指定了合适的编码,但是其中又包含了其它编码的字符,则需要先去将 dataJsonStr 转换为Unicode,然后再指定编码格式调用 json.loads()
dataJsonStrUni = data.JsonStr.decode("GB2312")
dataDict = json.loads(dataJsontrUni, encoding="GB2312")字符串编码转换
其实编码问题很好搞定,只要记住一点:任何平台的任何编码,都能和Unicode互相转换。UTF-8 与 GBK 互相转换,那就先把 UTF-8 转换成 Unicode,再从 Unicode 转换成 GBK,反之同理。
# 这是一个 UTF-8 编码的字符串
utf8Str = "你好地球"# 1. 将 UTF-8 编码的字符串 转换成 Unicode 编码
unicodeStr = utf8Str.decode("UTF-8")# 2. 再将 Unicode 编码格式字符串 转换成 GBK 编码
gbkData = unicodeStr.encode("GBK")# 1. 再将 GBK 编码格式字符串 转化成 Unicode
unicodeStr = gbkData.decode("gbk")# 2. 再将 Unicode 编码格式字符串转换成 UTF-8
utf8Str = unicodeStr.encode("UTF-8")- decode: 的作用是将其它编码的字符串转换成 Unicode 编码
- encode :的作用是将 Unicode 编码转换成其他编码的字符串
- 一句话:UTF-8 是对 Unicode 字符集记性编码的一种编码格式
二、Python 序列化之 json、pickle、msgpack 之 dumps、loads 区别于用法
Python 之 Json 模块
json 类型特征
- json 是一种通用的数据类型,一般情况下接口返回的数据类型都是json
- 长得像 Python 字典,形式也是 k-v
- 其实 json 是字符串
- 字符串不能用 key、value 来取值,所以要先转换为 Python 的字典才可以
示例:
import jsontest_str = '''
{"noticeLoginFlag": "1","ticket_id": "gh_45679b88e7a","pgv_si": "s29623456176","pgv_pvi": "1328457192"
}
'''data_dict = json.loads(test_str)
print(data_dict) # 打印字典
print(type(data_dict)) # 打印 data_dict 类型
print(list(data_dict.keys())) # 打印字典的所有keydata_string = json.dumps(data_dict, indent=4, ensure_ascii=False)
print(type(data_string))
print(data_string)
Python 之 simplejson 模块
simplejson 更轻量级,使用方法完全与 json 相同
Python 之 pickle 模块
pickle 类型特征
- pickle 模块用于实现 序列化 和 反序列化。
- 序列化 dumps 可以将 list、dict 等数据结构转化为二进制
- 反序列化 loads 可以将字符串转化为 list、dict
数据结构(可以是列表、字典等)转成字符串:dumps()方法:将一个数据结构编码为二进制数据
import pickledata_dict = {'name': 'king', 'age': '100'}
data_dict_list = [{'name': 'king', 'age': '100'},{'name': 'king', 'age': '100'}
]data_string_1 = pickle.dumps(data_dict)
print(type(data_string_1))
print(data_string_1)data_string_2 = pickle.dumps(data_dict)
print(type(data_string_2))
print(data_string_2)temp = pickle.loads(data_string_2)
print(type(temp))
print(temp)
Python 之 msgpack 模块
安装 msgpack :pip install msgpack
msgpack 类型特征
- msgpack 是一种有效的二进制序列化格式。它使您可以在多种语言(如JSON)之间交换数据。但是它更快,更小。
- 序列化 packb 可以将 list、dict 等数据结构转化为二进制 ( packb 别名为 dumps )
- 反序列化 loads 可以将字符串转化为 list、dict ( unpackb 别名为 loads )
import msgpackdata_dict = {'name': 'king', 'age': '100'}
data_dict_list = [{'name': 'king', 'age': '100'},{'name': 'king', 'age': '100'}
]data_string_1 = msgpack.dumps(data_dict, use_bin_type=True)
print(type(data_string_1))
print(data_string_1)temp_1 = msgpack.loads(data_string_1, use_list=False)
print(temp_1)data_string_2 = msgpack.dumps(data_dict_list)
print(type(data_string_2))
print(data_string_2)示例:
import datetime
import msgpackuseful_dict = {"id": 1,"created": datetime.datetime.now(),
}def decode_datetime(obj):if b'__datetime__' in obj:obj = datetime.datetime.strptime(obj["as_str"], "%Y%m%dT%H:%M:%S.%f")return objdef encode_datetime(obj):if isinstance(obj, datetime.datetime):return {'__datetime__': True, 'as_str': obj.strftime("%Y%m%dT%H:%M:%S.%f")}return objpacked_dict = msgpack.packb(useful_dict, default=encode_datetime, use_bin_type=True)
this_dict_again = msgpack.unpackb(packed_dict, object_hook=decode_datetime, raw=False)print(packed_dict)
print(this_dict_again)


 :fjproducer 逆向 之 困境)


)







 :VB 程序逆向分析)


 :PJ 软件功能限制(不修改jnz的非爆破方法))


 :Delphi 程序逆向特点)