作者:Pablo Samuel Castro、Marc G. Bellemare
来源:Google AI Blog,机器之心
摘要:在过去几年里,强化学习研究取得了多方面的显著进展。
在过去几年里,强化学习研究取得了多方面的显著进展。这些进展使得智能体能够以超越人类的水平玩游戏,其中比较可圈可点的例子包括:DeepMind 的 DQN 在 Atari 游戏上的表现、AlphaGo、AlphaGo Zero 以及 Open AI Five。具体来说,在 DQN 中引入重播记忆(replay memory)使得智能体能够利用先前的经验,大规模分布式训练使得智能体能够将学习过程分配给多个工作线程(worker),分布式方法使得智能体能够建模完整的分布,而不仅仅是它们的期望值,从而了解它们所在环境的完整情况。这种进步非常重要,因为算法催生的这些进展还可用于其他领域,如机器人学(参见:前沿 | 谷歌提出 Sim2Real:让机器人像人类一样观察世界)。
通常来讲,取得此类进展需要在设计上进行快速迭代(通常没有明确的方向),打破已有方法的结构。然而,多数现有强化学习框架并不同时具备可让研究者高效迭代 RL 方法的灵活性和稳定性,因此探索新的研究方向可能短期内无法获得明显的收益。再者,复现现有框架的结果通常太过耗时,可能会导致科学复现性问题。
谷歌介绍了一款基于 TensorFlow 的新框架,旨在为强化学习研究者及相关人员提供具备灵活性、稳定性及复现性的工具。该框架的灵感来自于大脑中奖励–激励行为的主要组成部分「多巴胺」(Dopamine),这反映了神经科学和强化学习研究之间的密切联系,该框架旨在支持能够推动重大发现的推测性研究。
谷歌还发布了一组相关的Colab(https://github.com/google/dopamine/blob/master/dopamine/colab/README.md),以说明该框架的使用方法。
易用性
清晰性(clarity)和简明性(simplicity)是该框架设计过程中的两个关键考量因素。谷歌提供的代码很紧凑(大约 15 个 Python 文件)且记录良好。原因在于谷歌研究人员专注于街机模式学习环境(ALE,一个成熟、已被充分了解的基准)和四个基于价值的智能体:DQN、C51、精心设计的 Rainbow 智能体简化版和 Implicit Quantile Network 智能体(上个月才在 ICML 大会上得到展示)。谷歌希望这一简明性特点可使研究者容易理解智能体的内在工作原理,快速尝试新想法。
复现性
谷歌非常看重强化学习研究中的复现性。因此,谷歌提供了其代码的完整测试;这些测试见文档附表。此外,谷歌的实验框架遵循 Machado 等人(2018)关于利用 ALE 标准化经验评估的推荐方法。
基准测试
对于新研究者来说,对自己的想法进行快速的基准测试是非常重要的。谷歌提供四个智能体的完整训练数据,包括 ALE 支持的 60 个游戏,格式为 Python pickle 文件(对于使用谷歌框架训练的智能体)和 JSON 数据文件(用于对比其他框架训练的智能体)。谷歌还提供了一个网站,研究者可以使用该网站对所有提供智能体在所有 60 个游戏中的训练运行进行快速可视化。下图即谷歌的 4 个智能体在 Seaquest 上的训练运行(Seaquest 是 ALE 支持的 Atari 2600 游戏之一)。
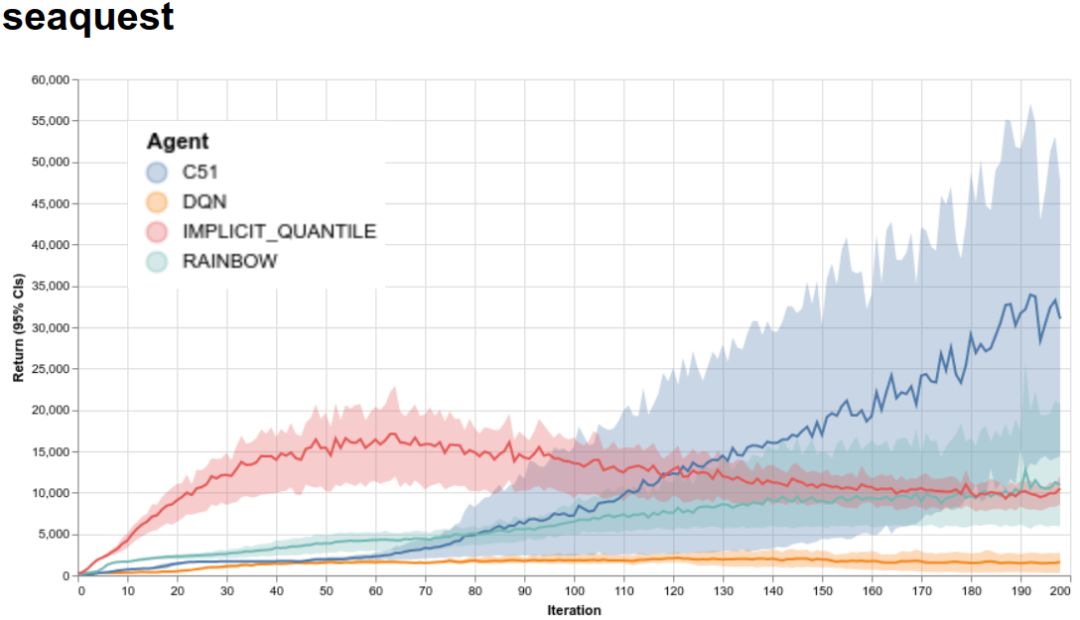
谷歌的 4 个智能体在 Seaquest 上的训练运行。x 轴表示迭代,每个迭代是一百万个游戏帧(实时游戏 4.5 小时);y 轴是每次游戏获取的平均分。阴影区域表示 5 个独立运行的置信区间。
谷歌还提供利用这些智能体训练的深度网络、原始统计日志以及用于 Tensorboard 可视化的 TensorFlow 事件文件。相关地址:https://github.com/google/dopamine/tree/master/docs#downloads
谷歌希望其框架的灵活性和易用性能够帮助研究者尝试新想法。谷歌已经在研究中使用了该框架,发现它可使很多想法快速迭代,具备很强的灵活性。谷歌期待看到社区使用这一框架。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


附参数对比表)




![[转载]ubuntu 12.10 软件源更新列表](http://pic.xiahunao.cn/[转载]ubuntu 12.10 软件源更新列表)












