
来源:gizmodo
摘要:很长一段时间以来,摩尔定律和它的最终结局一直就像房间里的大象,不容忽视。英特尔联合创始人戈登·摩尔在1965年的一篇论文中预测,芯片中的晶体管数量每年将翻一番。
更多的晶体管意味着更快的速度,而这种稳定的增长推动了几十年的计算机进步。这是CPU制造商提高CPU速度的传统方式。但晶体管的这些进步正显示出放缓的迹象。多伦多大学电气和计算机工程教授Natalie Jerger说:“这已经没了动力。”

图片: Alex Cranz, Gizmodo
不只Jerger一个人这么说。2016年,《麻省理工学院技术评论》宣称,“摩尔定律已死”,今年1月,Register发布了一份摩尔定律的“死亡通知”。如果你在过去几年里买了一台笔记本电脑,你可能也注意到了。CPU看起来比前一年快不了多少。英特尔生产了我们的大多数笔记本电脑、台式机和服务器中CPU,自2014年以来,英特尔很少能够让CPU性能提高15%以上,而AMD,即使采用了一些相当激进的新设计方法,通常也只是与英特尔并驾齐驱。
在英特尔和AMD(直到最近)所采用的典型的“单片(monolithic)”设计风格中,CPU由半导体材料组成——通常都是硅。这就是所谓的芯片(die)。在芯片的顶部是一系列晶体管,因为它们都在同一个芯片上,所以它们可以快速地相互通信。更多的晶体管意味着更快的处理速度,理想情况下,当你缩小芯片的尺寸时,晶体管就会更紧密地组装在一起,并且可以更快地相互通信,从而带来更快的处理速度和更高的能源效率。在1974年,第一个微处理器,英特尔的8080,是建立在一个6微米的芯片上。明年的AMD处理器预计将建立在一个7纳米的芯片上。这几乎缩小了1000倍,而且速度快得多。

AMD的Threadripper比英特尔CPU大很多,因为它实际上将许多AMD CPU组合在一起。
(图片:Alex Cranz, Gizmodo)
但AMD最近凭借其听起来荒唐的Threadripper CPU实现了最大的速度提升。这些CPU核心数量从8个到32个不等。核心类似于CPU的引擎。在现代计算中,多核可以并行工作,允许某些利用多核的进程运行得更快。拥有32个内核可以将Blender中3D文件的渲染时间从10分钟缩短到仅一分半钟,PCWorld运行的这个基准测试可以看到这一点。
另外,32核处理器听起来很酷!AMD通过采用chiplet设计实现了这一点。它所有的现代CPU都使用一种叫做Infinity Fabric的东西。今年早些时候在接受Gizmodo采访时,AMD计算和图形业务部门前总经理Jim Anderson称,这是AMD最新的微架构Zen的“秘方”。与此同时,CTO Mark Papermaster称其为“隐藏的宝石”。
Infinity Fabric是一种基于开源的Hyper Transport的新系统总线架构。系统总线完成了你认为它会做的事情——从一个点到另一个点的数据总线。Infinity Fabric的巧妙之处在于它能够非常快地传输数据,并允许用它构建的处理器克服chiplet CPU设计的一个主要障碍:延迟。

图片: Alex Cranz, Gizmodo
chiplet的设计并不新鲜,但它通常很难实现,因为很难在单独的芯片上制造出一堆晶体管,使这些芯片尽可能快地相互通信。但有了AMD的Threadrippers,你就可以在无限的结构上配置许多典型的Ryzen CPU,它们的通信速度就像在一块芯片上一样快。
它运行得非常好,其结果是超高速处理器的制造成本非常低廉,以至于AMD能够以相当于英特尔几分之一的价格出售处理器,而英特尔继续在其高核心数量中使用单片设计。在某种程度上,Infinity Fabric是一种欺骗摩尔定律的方法,因为它不是单个快速CPU,而是通过Infinity Fabric连接的一系列CPU。所以AMD并没有克服摩尔定律的限制,而是绕过了摩尔定律。
Jerger说:“如果你回过头来说,‘好吧,摩尔定律实际上就是关于功能的更大集成。’我确实认为chiplet不会以任何方式帮助整合更多小型晶体管,但它确实帮助我们建立了比上一代人更强大的功能和能力的系统。”
英特尔最新的i9 CPU可能速度很快,但它仍运行在4年前的14纳米的基础上。
(图片: Alex Cranz, Gizmodo)
她指出,在某些情况下,这种围绕chiplet设计的对话是对一家公司更显著的失败的一种偏移。她指的是英特尔,在过去几年里,英特尔一直在努力克服晶体管不能永远微缩的局限性。它一直停留在14纳米处理器,而且一年以来一直承诺10纳米处理器,但未能兑现。对于英特尔来说,这是一个可怕的尴尬,当其他芯片制造商绕着这家芯片巨头跑了几圈之后,情况变得更加糟糕。今年,苹果售出了数百万部内置7纳米处理器的手机和iPad,而AMD则在2019年发货了12纳米处理器,并承诺在2019年推出7纳米处理器。AMD今年在台北举行的Computex大会上也公开让英特尔感到难堪:英特尔承诺在今年年底前推出一款28核的CPU(目前还没有出货),几天后,AMD推出了一款32核CPU,自8月份以来一直在出货,价格是英特尔CPU预计价格的一半。相比之下,英特尔最近承诺的2019年向10纳米工艺迁移的拖延已久的计划显得有些可悲。
这就是为什么你不应该把它对chiplet CPU设计的拥抱看作是一个巧合。在某种程度上,这似乎是英特尔在鼓吹很酷的创新,以转移人们对重大创新失败的关注,甚至跟上竞争对手的步伐。

英特尔的带有AMD GPU的G系列CPU就是英特尔采用chiplet设计的一个例子。
(图片:Alex Cranz, Gizmodo)
不过,尽管这款chiplet CPU是为了分散英特尔10纳米问题的注意力,但它实际上也相当酷。英特尔在chiplet设计方面的首次尝试是在去年春天相对低调地推出了G系列CPU。G系列CPU实际上是与AMD合作开发的,AMD提供了GPU,英特尔的CPU可以与之通信。英特尔没有依赖AMD的Infinity Fabric之类的东西,而是开发了一种名为嵌入式多模互连桥(EMIB)的东西,它可以让CPU、GPU和4 GB的高带宽内存以接近同一芯片上一系列组件的速度进行通信。它的速度很快,当我们在3月份进行测试时,它给我们留下了深刻的印象。它预示着一个很酷的未来,我们的集成GPU最终会变得像英伟达GTX和RTX系列这样的分立GPU一样快。
但EMIB也像是对英特尔本月早些时候宣布的一款产品进行的一次试水,该产品预计明年上市:它是一款10纳米CPU,带有集成3D堆叠的chiplet设计。与EMIB和Infinity Fabric一样,3D堆叠也是一种chiplet设计工具。但是,Infinity Fabric和EMIB只是让传统CPU部件更快地相互通信的方法,而3D堆叠增加了另一个维度。
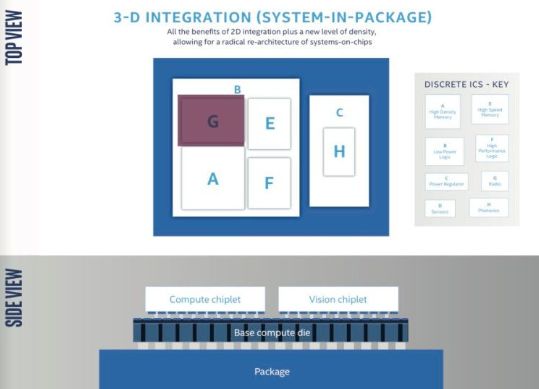
使用3D堆叠的CPU布局示例。(图片:英特尔)
通常芯片被放置在一个水平面上,这样芯片的每个部分都可以与散热器接触,保持凉爽。3D堆叠,如果可以正确处理散热,则可以把CPU构建得更高而非更大。有点像高层建筑vs牧场式住宅。
英特尔对3D堆叠技术非常感兴趣,它认为3D堆叠技术比Infinity Fabric或EMIB更能避开摩尔定律。据英特尔工艺与产品集成总监Ramune Nagisetty称,这是摩尔定律的“进化”。她在几周前的谈话中澄清了一些事情:
“如果你花时间去挖掘戈登·摩尔写的那篇论文,你就会明白这一点。这真的很有趣,因为在那篇论文中的一段,他实际上预示了封装集成的使用。他没有使用我们今天使用的语言,但他确实说过,建立一个由小功能组成的大系统是更加经济的,这些小功能是分开封装并相互连接的。”
我不确定我是否完全同意Nagisetty认为这是一种演变的观点,但她和Jerger都承认,摩尔最初的论文中的语言有一些灵活性,而且这些封装集成(或称为chiplet设计)的确让新的CPU设计模式超出了摩尔在1965年设想的模式。
今年,我们还没有确切地看到摩尔定律的死亡,但英特尔和AMD都知道死期在快速逼近,二者选择了稍微不同的想法。这些公司现在正在接受一种允许他们制造许多更小、更定制化的芯片的设计,而不是制造一种速度快得令人难以置信、适用于大多数人的单一芯片。
对于Jerger而言,这种灵活性是令人兴奋的。她说:“在这之前,一切都是关于大批量生产——我必须生产大多数人想要的东西,因为这是我赚钱的唯一途径。现在,你可能会变得更加多样化,我认为这让学术界和初创企业有机会做一些很酷的硬件设计。”
想象一下,CPU是专门为你的计算机的精确需求而构建的。这就是我们正在走向的潜在未来。这一切都是从把单片芯片拆成chiplet开始的。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”








)






)



函数详解)
