
耶路撒冷号称三教圣地, 而它的牛逼之处绝不仅在于宗教, 如果你深入了解, 你会发现它的科学,尤其是理论创新也同样牛逼, 尤其是在脑科学和人工智能方向。 当然神族人不是特别关心最接地气的问题, 而是更关注形而上的理论框架。 耶路撒冷的脑与深度学习会就是这样一个杰出的体现。
深度学习有关的核心会议, 从NIPS到ICLR 我们都不会陌生, 这些会议对深度学习在人工智能的应用极为相关。 耶路撒冷的这个会议与之不同的是, 它非常关注深度学习与脑的交叉领域, 关注它们背后共同的指导理论, 在这点上也算是独树一帜。 因为在大家忙于做应用主题的时候, 其实更需要有一些人其思考背后的理论,即使这样的思考在一个时间里不会马上促进应用, 但是在更长远的时间里, 却可能把应用推向一个远高于现在的平衡点。 就像人类在了解牛顿定律以前就能够建造各种各样的桥梁。有人可能会说我们不需要牛顿定律, 而实际上他们没有看到我们有了牛顿定律后所造的桥根本不是一种桥, 不是石拱桥,或者独木桥,而是跨海大桥。 好了,我们直接来说正事, 来总结下会议里一些有趣的内容。
脑与深度学习的关系本来就是一个高度双向的主题, 这个会议围绕以下几个核心问题:
1 深度学习的基础理论, 深度学习为何work又为何不work?
2 如何从心理学和认知科学的角度归纳当下深度学习的不足?
3 如何用深度学习促进对人脑的理解,包含感知(视觉为主), 认知与记忆。 反过来如何促进AI?
会议最大的一个板块, 在于对深度学习理论的剖析, 这个板块可谓大牛云集, 从信息瓶颈理论的创始人Tshiby 到 MIT的 Tomaso Poggio, 从牛津的Andrew Saxe到MIT的Daniel Lee, 都表达了自己的核心观点, 问题围绕的一个主线就是深度学习的泛化能力 。
我们把这个问题分成两个子问题:
深度学习的泛化能力为什么那么好? 大家知道深度学习理论的第一个谜团就是一个大的网络动辄百万参数, 而能够泛化的如此之好, 这是非常不符合贝卡母剃刀原理的(解决同样的问题简单的模型更好),更加作妖的是, 这种泛化能力往往随着参数的继续增加而增强。 这到底是为什么? 几个不同的流派从不同的角度回答了这个问题。
1, 信息流派: 从信息论的角度分析深度学习, Tshiby是该流派的集大成者,也是此次的发言者。 他的核心观点是从把深度网络理解为一个信息管道, 数据, 就是入口的原油 ,里面富集了我们可以预测未来的信息, 那么这个深度网络, 就是首先要把输入数据里那些相关性最高的成分给把握住, 然后再一步步的把我们与预测信息无关的东西给剔除, 最后得到一个与预测对象而非输入数据极为相关的表征。 深度学习的泛化能力, 在于层数越深, 这种对无关信息的抽离的效率就越高, 因为随机梯度下降的训练过程, 每层的网络权重都在做一个随机游走, 越高的层 ,就越容易忘记那些与预测无关的特征, 层数越多, 这个过程其实就越快,我们能够在控制梯度消失的同时拥有更多的层, 会使我们越快的发现那个与预测相关的不变的特征本质。
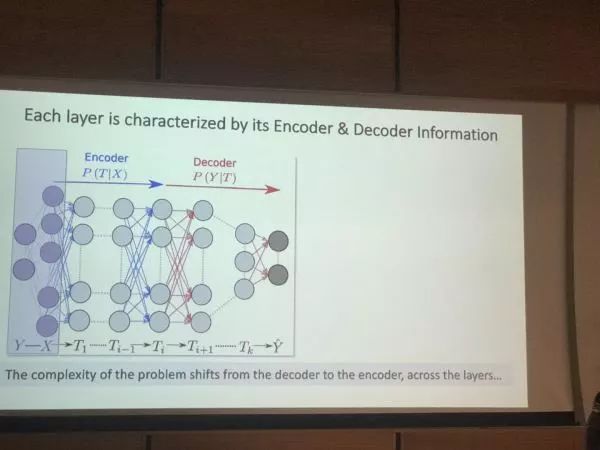
信息瓶颈理论, 深度网络作为信息抽取的管道。
2, 几何流派: 这是Daniel D Lee 的talk 。从Manifold learning的角度理解 , 深度学习的“类" 对应一个在高维空间里得到一个低维流形,。这一个高, 一个低, 就是深度能力泛化能力的源泉。 这个观点的核心起源可以追溯到SVM的max margin solution。 在SVM的世界, 首先我们可以用增加维度的方法把两堆在低维世界混合分不开的点投影到高维空间, 它们就清楚的分割开来。 然后我们用最大间隔来做限制,让这两堆点分的尽可能开, 就可以避免过拟合。
这个做法的本质首先用维度增加增强模型的容量, 然后在模型有了更高容量后我们当然也更容易过拟合。但是我们可以用最大间隔尽可能把数据”打“到一起, 事实上让每个类数据分布的维度尽可能低,这就可以避免过拟合。在深度学习的世界里, 我们每层网络都把之前的数据映射到一个新的流型里, 最简单的假设就是一个球体。比如猫和狗的分类, 就是两个球体, 一个猫星, 一个狗星。 在一个同样的高维空间里, 这两个球的维度越小, 半径越小, 就越容易把它们分开,而且可以分的类越多。 随着深度网络的层数变深, 这个趋势恰恰是每个球的维度越低,半径越小。 如果不同类型的图像对应不同的球,层数越深, 就越容易给它们分开。这个观点的内在事实上和Tshiby的信息瓶颈有异曲同工处, 大家体会下, 那个小球的维度越低是不是在抓取数据里的不变性。
几何学派, 猫星和狗星的分离

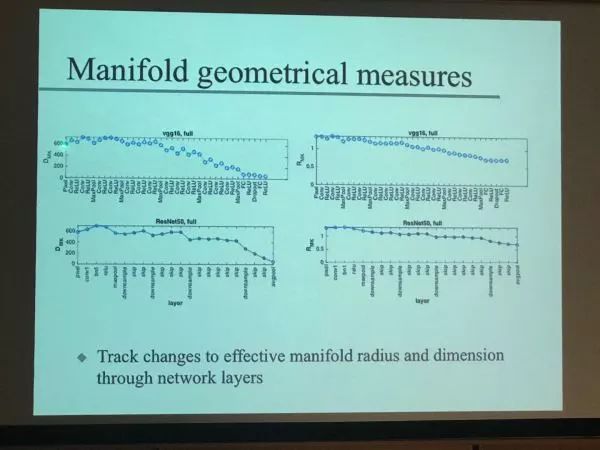
几何流派, 高维空间的低维流型随着层数变深的变化
3, 动力学流派 : 高维空间非线性优化的本质是这种优化随着维度增长效率增加。 这是牛津那位仁兄Andrew Saxe的talk 。 牛津例来是深度学习的阵地, 理论当然当仁不让。 这个talk从非线性优化的角度揭示了深度学习泛化的本质。 网络训练的过程, 事实上是高维空间上一个寻找动力学定点(全局最优)的过程, 每时每刻,梯度下降的方向是由当下x和y的相关性和x和x的自相关性决定的。 当优化进行到定点(最优点)附近时候, 这个相关性信息开始减少, 网络开始对数据里的噪声敏感, 因此我们需要早停法来减少过拟合。 但是, 如果我们的网络足够大,甚至这个早停都不必要我们无需提防这种拟合噪声带来的过拟合。 取得这个结论需要非常复杂的线性代数, 同学们可以参考论文High-dimensional dynamics of generalization error in neural network
会议的另一个部分talk,围绕深度学习的泛化能力为何如此之差, 这不是互相矛盾吗?此泛化非彼泛化也。
1, 先天的偏见与推理的无知
先验误差导致的失灵: 希伯来大学的Shai Shalev 深度网络可以战胜围棋这样牛逼的游戏, 然而你想不想的到, 它可能在学习乘法表的时候都会出错? 这个talk讲解了让深度网络学习并泛化一个乘法表, 然后看在测试集上它是怎么表现得。 非常有趣的是 ,虽然深度网络在训练集上表现完美, 在测试集上出现了让人耻笑的系统误差, 说明它还真的不如一个小孩子的学习能力。 这突出了反应了深度统计学习依然无法绕过统计学习固有的缺陷, 就是缺少真正的推理能力。 而这种系统误差背后的原因, 是网络内在的inductive bias, 这就好像网络自己就带着某种先天的偏见, 我们却对它茫然无知。
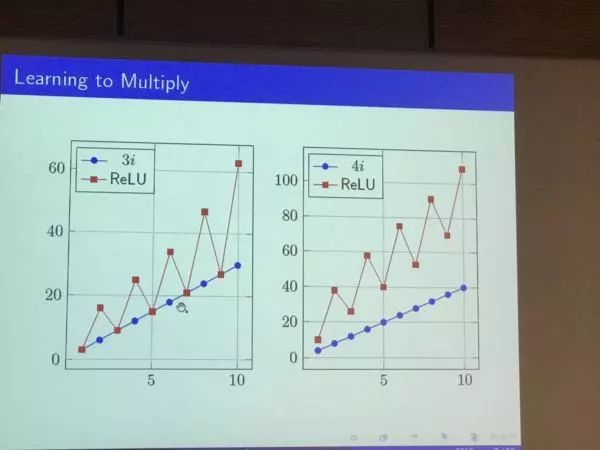
深度学习学乘法出现的难以忍受的系统误差
另一个惊人的talk来自于Montreal University的Anron Courville。 他围绕一个深度学习的当红应用领域VAQ -视觉看图回答问题展开。 这个框架的核心在于让深度网络看图, 回答一个有关图像的问题, 比如图像里有几把桌子几把椅子这种。 我们关键考察那些需要一点推理能力才能回答的问题, 比如回答完了图像里有几个桌子,有什么颜色的椅子后, 问它图像里有什么颜色的桌子。 如果这个网络真的有泛化能力, 它就会回答这个问题。 事实上是我们所设计的超复杂的由CNN和LSTM组成的巨型网络在这个问题面前举步维艰。 它可以找到3张桌子或5张桌子, 但是很难把什么颜色的椅子里学到的东西迁移到桌子里正确回答出灰色的桌子。之后我们从工程学的原理设计了一个全新的结构把这种推理能力人为的迁移进去, 会使问题稍稍好转。

视觉看图回答问题
2, 你不知道的CNN那些缺陷:
1 CNN真是平移不变的吗? Yair Weiss 希伯来大学计算机系的Dean给大家讲解了CNN网络最大的根据-平移不变性是错误的。 我们知道CNN网络建立的基础是它模仿生物感受野的原理,建立了一个共享权值的网络系统 ,这样不同位置的图像部分, 会共享同一种特征偏好, 你的鼻子出现在图像的顶端或下面都是鼻子。
而Yair Weiss却想了一个方法, 证实了CNN, 哪怕你把图像向上移动了一个像素, 都可能造成它整个看法(分类)的变化。 这和那个在动物脸上加噪声看成其它动物的实验类似, 证明了CNN的脆弱性,同时动摇了平移不变的基础。 一开始我也觉得是天方夜谭, 但是看了他的整个试验后开始稍稍信服。 事实上它证实了对于最早期的CNN-neocognitron , 平移不变的确是成立的。 但是对于”现代“CNN, Alexnet, VGG, ResNet, 这个性质却不再成立。 因为现代CNN在整个网络结构里,加入了大量的降采样,比如池化, 这些在空间上离散的降采样操作, 导致了一种惊人的脆弱性,就是平移不变的丧失。 当然, 在实际应用中, 它不够成那么大的问题, 因为你永远可以通过数据增强的方法, 来强化网络里的这些不变性。
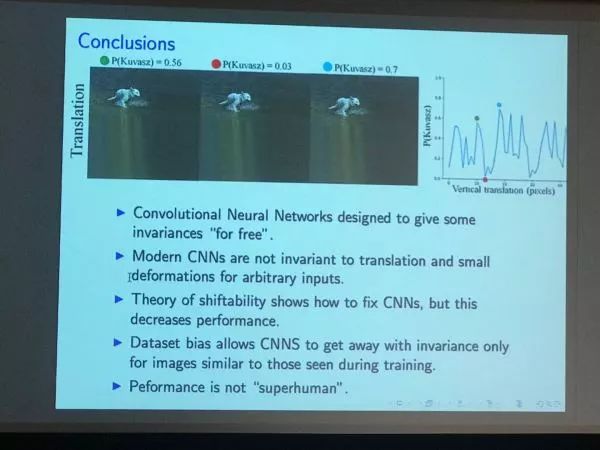
CNN居然不是平移不变的
2,CNN对细节的敏感与对轮廓的忽视。 我们本来相信CNN对不同尺度的图像特征,从细节纹理到图像轮廓, 都会同样器重并做出判断。 而事实上, 来自德国Tubingen的Matthias Bethe, 给我们展示了CNN事实很可能把自己90%的判断依据,放在了细节和纹理上。 也就是说, 它也许可能精确的识别狗和猫,但是它或许真正基于的是狗毛和猫毛的区别做出的判断。 如果你联想一下那么在图像里加入噪声, CNN就可以把熊猫看成长颈鹿的实验, 就觉得这个想法还挺合理的。 它通过它的实验验证了它的这个理论。也就是用那套图像特征迁移的网络, 把一个个图片的纹理抽取, 或者更换掉, 虽然还是猫或者狗, 里面的纹理变了, 那个CNN就彻底傻掉了。 同时它还对比了人的认知测试,看到了CNN的巨大差距。
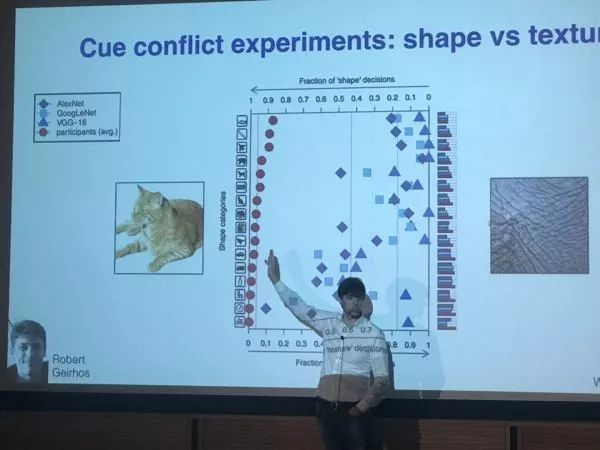
CNN难道只对细节感兴趣?
以上这些研究都暴露了CNN和人脑的区别。 即使是图像识别这个目前AI做的最好的领域, 这个”人工智能“ 也显得太”人工“ 了, 而与”智能“差距甚远。 当然Matthias通过强化对轮廓的训练识别, 可以让它变得更像人一点, 可以识别一定的整体特征, 然而这个时候对总体数据集的识别度会变得更差。到这里,可以说是从深度学习多么好,到了深度学习多么差, 我们毕竟还没有掌握智能最核心的东西,包括符号推理这些, 也没有具备真正的”泛化能力“ , 此处之后的几个talk,就是围绕这个智能的真正核心,探讨人脑有多牛逼了。
脑科学与心理学角度的智能:
1, 有关表征学习:
来自Princeton的Yael Niv讲解了智能科学的核心-表征学习的几个关键问题:首先什么是表征学习, 表征学习的本质概念是学习一个真实世界的神经表示。它可能是从真实世界抽离出来的一些核心特征, 或者我们说的对真实世界的抽象, 而这里面,却可以帮助我们大大增强我们举一反三的学习能力。 比如说你被蛇咬了, 下一次出现运动的细长生物你知道避开。 另一方面, 我们可以把任务根据当下情景在大脑中重构出来, 比如都是讨价还价, 你碰到辣妹可能就没有那么用力了,而是开始谈笑风声起来。我们可以把从相似的任务里学到的经验整合, 或者同一个经验里学到的东西和不同的新的任务结合。
这些都依赖于我们大脑中一套灵活的对不同任务和事物的表征系统。 这个系统我们可以管它叫任务表征系统。Yael 讲了这个任务表征系统的一些基本特性, 比如说贝叶斯证据整合,证据如何互相关联和启发(召唤), 并把这些研究和大量心理学测试联系在一起。 这种对任务的极强的迁移学习能力, 可以从一个任务中的经验,关联到一大堆任务的能力, 是得到更好的泛化能力, 甚至走向通用人工智能的一个关键步骤。 如何能够通过学习得到这种可以迁移的任务表征也将成为重中之重。

表征学习-智能的核心
2, 有关人类记忆的研究:
来自哈佛医学院的Anna Schapiro 讲解了海马记忆的两个根本机制。 我们知道, 海马是人和小鼠短期记忆, 情景记忆的载体。 在海马体内有两种不同的记忆模式。 一个事短期的快速的记忆, 每个记忆由相互独立的神经元基团表达, 另一种是长期的稳固的, 某几个记忆根据它们的共性共享大量的神经元基团。 在夜晚睡眠的时候, 我们白天记住的东西一部分会从短期转向长期,另一部分则会被遗忘。 有意思的是 , 谁会被遗忘, 谁会被增强呢?
事实上Anna的研究表明人脑有一种非常灵活的机制, 可以把那些重要的记忆筛选出来,从短期区域走向长期区域, 而一些不重要的就像被水冲过一样遗忘掉。 这个机理可以由海马体的一个网络动力模型理解。 同时这个研究还一定程度解开人类神经编码的方式。 那些长期记住的事物为什么要共享神经元基团? 这是为了更有效的泛化, 一些类似的事物,或任务,通过共享神经元, 可以更好的提取共性, 预测和它们类似的东西。 反过来这也表明我们大脑内的记忆很多可能是错误的, 类似的东西之间会”相互污染“ ,这就是我们为什么经常会记混或记串。

两种记忆承载的模式, 一种很独立, 一种有重合。
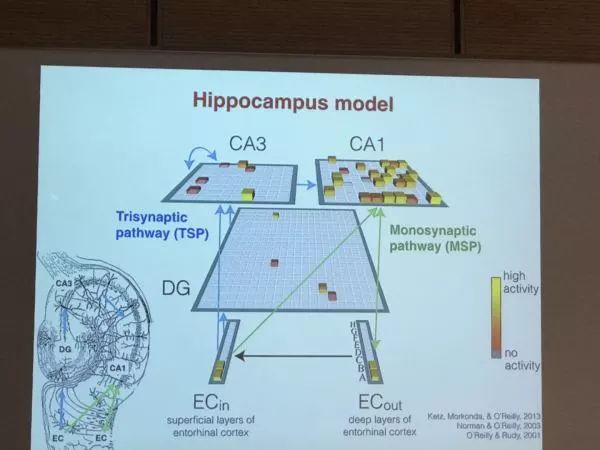
海马模型
最后一个模块,就是围绕人脑和深度学习的关系, 虽然我们的最终梦想是把让人脑牛逼的算法迁移到AI系统, 但是第一步最容易实现的恰好是反过来, 如何借助深度学习这个崛起的工具更好的挖掘人脑的原理。
对于这块,来自斯坦福的Daniel L K Yamins 提出了一个非常酷的研究框架, 就是用reverse eigeerneering(逆向工程, 正是我导师的领域) 研究人脑的感知系统(视觉或听觉皮层)。 对人脑视觉或听觉回路进行建模是我们一直的梦想 ,整个计算神经科学, 围绕如何用数学建模来理解这些现象 ,建立实验数据之间的联系。然而建立这样的模型异常复杂, 需要考虑的生物细节极为繁琐。 现在, 深度学习的网络给我们提供了极佳的工具去理解这些现象。我们的一个想法是用这些深度学习模型去学习具体任务,等到它学会了我们再想法来理解它。 那我说你不还是搞一些toy model 给我吗? 谁信? 没关系, 不是有实验数据吗, 我们先让它能做任务, 再用它来拟合我们的实验数据, 比如你先训练一个CNN来做图像识别, 同时训练好后, 你想法让这个CNN里的神经元活动能够匹配从大脑视觉皮层得到的实验数据, 这样你就得到“生物版” CNN。为了确定它是一个真正的科学, 而不是一种“形似”的骗术, 我们会用这个生物版本的CNN提出一些新的现象预测, 可以拿回到实验检验, 如果真的成立了, 这个用深度学习“构建出来”的模型, 就可以得到一个我们目前阶段最接近真实生物系统的模型。 你可以理解我们做了一个机器猫,它不仅能够捉老鼠,而且各项生理指标也和真猫差不多。
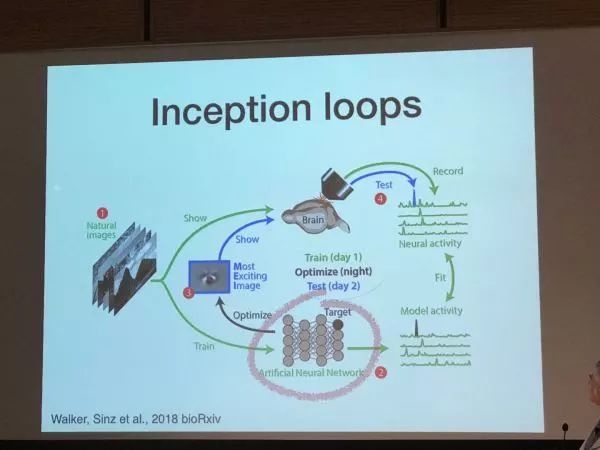
让深度网络和动物看同样的图像,并把它们的内部活动联系起来!
具体可以见Nature论文Using goal-driven deep learning models to understand sensory cortex。
这一类的工作还有一个talk是如何构建一个CNN网络理解人类的视网膜系统,同样的,这个网络既有视觉信息的处理能力, 同时还能够描述生物的神经活动, 甚至可以预测一些生物视网膜特有的现象(如对未来运动信息的预测)。这一类工作可以说打通了生物与工程, 虽然人工神经网络无论在单个神经元还是在功能层面和神经元活动层面都获取了类似于真实生物系统的特性, 我们又有多大可能认为我们用这个方法理解大脑的真正工作机理, 这依然是一个仁者见仁 ,智能见智的过程。
最后, 关于所有人的梦想, 把大脑的牛逼算法迁移到AI, 有一个talk颇有启发。 它来自于斯坦福的Surya Ganguli,如何让深度网络生成语义结构: 一个AI最根本的问题是如何沟通统计主义, 连接主义和符号主义的人工智能, 统计机器学习与深度学习代表了前两者的巅峰, 而早期活跃的符号主义目前只保留了知识图谱这样的果实残留。 事实上, 如果不能让符号主义的思维重新以某个方式进入到深度学习, 真正的AI将很难到来。 而这个方向的第一个步骤就是如何得到语义结构的神经表示。 人类的语言,可以用几千个单词表达十万百万的事物, 由于组合规则和树结构。那些共用特征的概念会被放在一个树枝之上, 而另一些则会放在其它树枝上。 这种特征层级结构, 使得人类的概念学习极为有效率, 只要直接把一个新概念放到它应该在的枝桠上, 有些该有的就都有了。 那么, 基于统计和连接主义的神经网络可不可以再现这种树结构呢?Ganguli 的研究给这个方向提示了可能, 它把学习和非线性系统在高维空间的运动联系起来,训练,就是不同的概念根据其间相似度互相分离的过程。 通过分叉等结构, 把概念的树结构和动力学空间联系在了一起。 详情请见论文: A mathematical theory of semantic development.
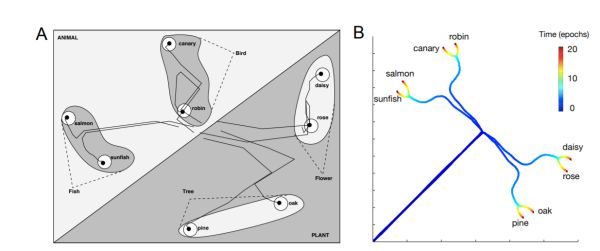
A mathematical theory of semantic development deep neural networks。 学习过程里的概念分离
这个会议, 可以说对于深度学习和脑科学未来的发展, 意义都非常深刻。 我看到的是, 尽管人们都怀揣着统一两个领域的梦想, 但现实的差距还非常遥远, 双方的沟通依然艰难。而这也更突出了这类会议的难能可贵。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

)


)





: Linux 磁盘、分区、挂载、逻辑卷管理 (Logical Volume Manager))









