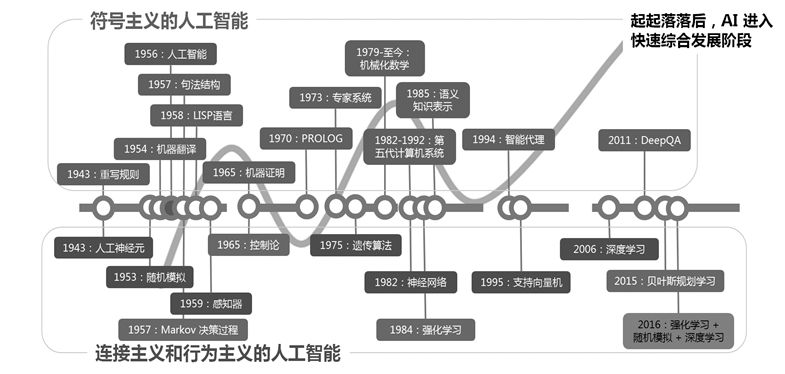
图I:AI从达特茅斯会议(1956年)得名至今已有六十年,期间几起几落,群星璀璨,像一个大舞台,你方唱罢我登场,留下了一些永载史册的理论和成就,但涉及因果的甚少
作者:江生,《为什么》第一译者,华为2012泊松实验室主任,机器学习和应用数学首席科学家
为何需要因果论?
早在两千多年前,亚里士多德等西方哲学家就已经提出了因果的概念,并开始思考事件之间的“导致”关系。从那时起,决定论(determinism)这一哲学立场就一直统治着科学界,其认为宇宙是由因果律支配的一连串事件,一切自然规律都有其因果基础。亚里士多德把因分为四类:目的因、动力因、质料因、形式因。佛教也特别强调因果律,《因果经》说:“欲知前世因,今生受者是;欲知来世果,今生作者是。”
欧洲中世纪经院派哲学家和神学家托马斯·阿奎那把第一个动力因归为上帝。17世纪末、18世纪初,德国数学家、哲学家戈特弗里德·莱布尼茨(1646-1716)在其著作《单子论》中明确提出了“充足理由律”。他说:“单凭这个原则,我们认为:任何一件事情如果是真实的,或实在的,任何一个陈述如果是真的,就必须有一个为什么这样而非那样的充足理由,虽然这些理由常常总是不能为我们所知道。”也就是说,任何事物都有它之所以如此的理由。理由的存在是毋庸置疑的,只是人类常常捕捉不到。
18世纪,苏格兰哲学家、经济学家和历史学家大卫·休谟给出了因果关系的现代定义:“我们可以给一个原因下定义说,它是先行于、接近于另一个对象的一个对象,而且在这里,凡与前一个对象类似的一切对象都和与后一个对象类似的那些对象处在类似的先行关系和接近关系中。或者,换言之,假如没有前一个对象,那么后一个对象就不可能存在。”法国数学家、物理学家、哲学家皮埃尔-西蒙·拉普拉斯(1749-1827)说:“我们应该把宇宙当前的状态视为它上一个状态的果,以及它下一个状态的因。”德国哲学家亚瑟·叔本华(1788-1860)在《充足理由律的四重根》中,则把充足理由律分为四种表现形式:
1) 因果关系:生成的充足理由律;
2) 逻辑推论:认识的充足理由律;
3) 数学证明:存在的充足理由律;
4) 行为动机:行动的充足理由律。
充足理由律是一切科学技术的基础原理。毫不夸张地说,牛顿的经典力学、爱因斯坦的狭义/广义相对论、量子理论,甚至整个科学的发展都是决定论的产物,由此也可见因果关系在科学研究中的重要地位。德国哲学家马丁·海德格尔(1889-1976)认为,没有充足理由律就没有现代的科学技术。
可以说,因果思维是一切科学技术的基础,珀尔在书中给出了很多因果推断的应用实例,它们来自社会各个领域的方方面面:比如,社会科学领域中“伯克利招生悖论”的解决以及对学历和工作经验工资水平影响的分析;公共健康领域中对疫苗接种合理性的探讨,对19世纪伦敦霍乱发生原因的分析,对坏血病预防机制的确定,对吸烟是否致癌争论的解决及吸烟行为对新生儿影响的分析,以及对诸多现实生活中存在的悖论的解决,这些悖论包括有关“运动-胆固醇水平”的辛普森悖论、有关“饮食-体重”的罗德悖论,以及有关止血带作用和好坏胆固醇的悖论,等等;遗传研究领域中巴巴拉·伯克斯的“天性与培养”研究、赖特的“豚鼠毛色”以及“出生-体重”的路径分析研究;教育政策领域中的招生歧视判定和“全民学代数”教育改革计划的有效性评估;气候预测领域中的异常天气事件与全球变暖的关系分析;法律领域中的罪行判定;等等。
既然因果论这么重要,为何它的数学形式化研究一直被滞后,直到最近才初见雏形?主要原因就在于研究因果关系的必备工具之一的统计学在进入20世纪后才真正成为一门严谨的学问。另外,这一滞后还要归咎于统计学的早期先驱(高尔顿、皮尔逊、费舍尔等人)的个人影响,以及该领域长期以来对主观知识和经验的忽略。甚至直到今天,因果图作为一种知识表示的手段在学界仍未得到广泛认可。珀尔在《为什么》一书(第一、二章)中对这段历史背景进行了比较客观的剖析。
在《为什么》一书中,珀尔把因果论分为三个层面,他称之为“因果关系之梯”:第一层级研究“关联”,第二层级研究“干预”,第三层级研究“反事实推理”。珀尔特别指出,我们当前的AI(人工智能)和机器学习只处于最低的第一层级,只是被动地接受观测结果,考虑的是“如果我看到……会怎样”这类问题。处于第二层级的“干预”则关乎主动实施某个行动,考虑的是“如果我做了……将会怎样”“如何做”这类更高级的问题。例如,如果乔服用诺氟沙星胶囊,他的肚子还会疼吗?珀尔开创了一套 演算体系实现了对“干预”问题的回答,这是他引以为豪的研究成果。
第三层级的“反事实”在现实世界里并不存在,它是想象的产物。反事实推理处于因果关系之梯的最高层,其典型问题是:“假如我做了……会怎样?为什么?”这类问题属于反思性问题。例如,假设乔服用诺氟沙星后死亡,对此我们想问的是,假如乔未曾服用过该药物,他存活的概率有多大?人死不能复生,因此现有的AI无法回答此问题。而借助珀尔在第八章所详细介绍的必要性概率计算方法,我们就可以轻而易举地计算出这一问题的答案。反事实推理对人类来说是家常便饭,但对机器来说就没那么容易了。历史学家尤瓦尔·赫拉利认为人类发展出描绘虚构之物的能力正是人类进化过程中的认知革命,反事实推理是人类独有的能力,也是真正的智能。借助它,人类才可以超越现实,在虚构的世界里张开想象的翅膀,在追悔莫及、痛定思痛的反思中变得更加成熟。因果论则为此提供了一套反事实推理的工具,它们在未来有望被应用于实现机器智能——这将是多么令人激动的创新!
因果论与人工智能
人工智能领域中的大多数问题都是决策问题。我们先来介绍一下决策理论的背景:1939年,罗马尼亚裔美国统计学家亚伯拉罕·沃德(1902-1950)撰文指出参数估计和假设检验都是统计决策问题,甚至计划把整个统计学纳入统计决策理论的框架。损失函数是统计决策的起点,它反映了专家知识和特定需求。给定了损失函数,贝叶斯学派将始终如一地选择期望损失最小的决策,有或没有观测数据时都是如此。频率派则需要预先制定决策规则,基于损失函数和样本定义一个风险函数,然后根据某些原则(如极大极小原则、贝叶斯风险原则等)来选择最优的决策。
“观察到某事件”和“使某事件发生”是有本质区别的。如果决策是基于被动接受的观测数据,那么它就处于因果关系之梯的第一层级,强烈地依赖于观测数据,因而难免带有偏颇。而有了第二层级的利器——干预,决策就可以不受观察样本的束缚,把一些样本无法反映的事实揭露出来。这里其实没有什么神秘可言,这些经验或知识早已经写在因果图里了,现在只不过是与数据一起帮助人类或机器更好地做出决策。简而言之,达到第二层级的AI将具有主动实施行动来分析因果效应的能力,这种能力使得决策行为更加智能化。
利用“干预”,我们解决了“吸烟—肺癌”的问题,明确推导出“吸烟”是“肺癌”的因。如今,香烟烟盒上都会标注“吸烟有害健康”,烟草公司也已承认这个因果事实。而处于第一层级的相关性分析只能得出二者是强相关的结论,不具有公共健康的指导意义。
第三层级的反事实推理允许机器拥有“想象能力”。例如,某人服用药物后死亡,经过计算必要性概率,我们可以得出结论:假如此人未曾服用过该药物,则此人几乎必然存活。离开了因果推断,现有的AI技术是不可能解决此类问题的。反事实推理考虑的是一个假想世界,其与现实世界完全相悖,是无法直接通过观测数据进行推理的,必须借助一个因果模型。《为什么》一书提到了一个“学历/工作经验/工资”的因果模型,其中作者的问题,假如爱丽丝为本科毕业,那么她应该拿多少工资——这是一个很好的例子,说明了单靠缺失数据分析无法得出合理的估计。
人工智能大致可分为符号主义、连接主义、行为主义三大流派(见图I)。人工神经网络(ANN)是连接主义的生力军,它是一种模仿生物神经网络的数学模型,可抽象地看作一串带未知参数的复合变换,这些参数是通过数据拟合估计出来的。符号主义的AI多为基于规则的符号系统或逻辑系统,先天具有良好的可解释性。行为主义的AI则涉及最优控制、统计决策等。20世纪80年代至90年代,受困于组合爆炸和算力不济,规则方法逐渐被统计方法取代,数据的重要性得到强调。1995年之后的整整10年,在机器学习领域,ANN被支持向量机和核方法抢去风头,直到2006年,深度学习之父杰弗里·辛顿发表受限玻尔兹曼机的论文掀开了深度学习的新篇章。直至今日,深度学习依然是AI的热点方法,甚至有人将之盲目地等同于AI。其实,机器学习只是AI的一个领域(它的目标是使计算机能够在没有明确程序指令的情况下从经验或环境中学习),机器学习的方法多如牛毛,深度学习只是沧海一粟。
理论上可以证明,人工智能即便在因果关系之梯的最低层级做到极致,也无法跃升到干预层面,更不可能进入反事实的世界。这本书所讨论的几个悖论(伯克森悖论、辛普森悖论、伯克利大学招生悖论等)就曾长期困扰着统计学家,因为这些问题离开了因果论是不可能得到彻底解决的。珀尔也看出了这一问题的症结:缺少因果推断的AI只能是“人工智障”,是永远不可能透过数据看到世界的因果本质的。
作为处在因果关系之梯最低层级的机器学学习技术,大数据分析和深度学习并不神秘,说得通俗一些,大数据分析就是多变量统计分析,深度学习就是隐层多了一些的神经网络而已,理论上没有太多新意。借助算力的提升,这轮AI的火爆主要表现在工程实践比以往更丰富了,应用层面的创新要远远超过基础理论的创新。珀尔教授认为大数据分析和深度学习(甚至多数传统的机器学习)都处于因果关系之梯的第一层级,因为它们的研究对象还是相关关系而非因果关系。
不过,珀尔并没有贬低处于因果关系之梯最低层的相关性分析,他只是在提醒我们不要满足于这个高度,还要继续向上攀登。不同层级之间也可以形成合作,例如,在实践中,深度学习可用于拟合强化学习中的策略,二者强强联手,成为“深度强化学习”,后者曾作为核心技术之一在AlphaGo那里大放异彩。
珀尔的这本科普书来得正是时候。众所周知,这轮AI的爆发在很大程度上得益于算力的提升,例如,深度学习就是人工神经网络借助算力的“卷土重来”,把数据驱动的方法推向了一个巅峰。人们甚至产生了一个幻觉——“所有科学问题的答案都藏于数据之中,有待巧妙的数据挖掘技巧来揭示。”珀尔教授批判了这种思潮,他将因果模型置于更高的位置,把数学或统计建模的荣耀重新归还给了相应领域的专家。我们希望,未来的机器学习可以不再靠炼金术士的碰运气而获得成功,随着知识推理和计算越发受到关注,可解释AI将从关于因果关系的新科学中汲取更多的力量,甚至可以闯进反事实的世界。
人们喜欢从“数据”(巧妇难为无米之炊,没有数据哪来分析?)、“算法”(计算机程序的灵魂)、“算力”(天下武功,唯快不破)和“场景”(因地制宜,因材施教)四个角度谈论AI。珀尔教授试图告诉我们,数据固然重要,但它并不是推断的唯一来源,那些承载着知识或经验的“因果”模型,才是帮助机器从“人工智障”走向人工智能的关键所在。在珀尔看来,大数据分析和数据驱动的方法仅仅处在因果关系之梯的第一层,强人工智能还需要干预和反事实推理,如此让机器具备自由意志才可能实现,二者分属因果关系之梯的第二层级和第三层级。
近十年来,有两项震惊世界的AI壮举,它们分别是“沃森”和AlphaGo(“阿尔法狗”),二者所涉及的最关键的AI技术和因果论有一定的联系。
2011年,IBM公司的智能问答系统“沃森”参加综艺节目《危险边缘》(Jeopardy!)首次打败了人类冠军。“沃森”回答问题既快又准,其背后有知识推理(基于DBpedia、WordNet和Yago等知识库)、句法-语义分析、学习策略(如集成学习)、智能决策等传统机器学习的模块,更有大数据(来自维基百科、词典、新闻、文学作品等2亿页的结构化和非结构化信息)的支持,但其本质上还是一个信息检索系统。
“沃森”每秒可处理500GB数据,相当于阅读100万本书。它能高效地寻找并生成假设或挖掘证据,推翻假设,而非只能简简单单地搜索匹配的内容。即,它考虑的是干预问题:“如果我做了某假设,会有证据推翻它吗?”这是一个巨大的进步,也是“沃森”成功的关键——它登上了因果关系之梯的第二层级。实话实说,虽然IBM(国际商业机器公司)号称沃森是“基于为假设认知和大规模的证据搜集、分析、评价而开发的深度问答技术”,但是它的AI远未达到通过“迷你图灵测试”(见《为什么》第一章)的水平。
2014年,谷歌公司收购了英国的一家AI公司——DeepMind,该公司研发的AlphaGo围棋程序在2016年首次打败了人类顶尖围棋高手李世石,次年横扫所有人类高手取得全胜(包括以3:0战胜柯洁)。聂卫平(九段)称它的水平为“至少二十段”。AlphaGo采用深度强化学习和蒙特卡罗树搜索,其最终版本AlphaGo Zero仅需要3天便可自我训练至战胜李世石的水平。2017年,DeepMind宣布AlphaGo“退役”,不再参加任何围棋比赛。
AlphaGo继“沃森”之后再次掀起了AI狂潮。在棋类游戏中,围棋所包含的巨大的搜索空间(其状态数远远超过整个宇宙中的原子数)一直是机器学习未能攻克的难题,甚至一度被认为在近期内是不可能被AI解决的。距离上一次IBM“深蓝”在国际象棋上战胜人类(1997年5月,深蓝计算机以3.5-2.5击败当时的世界冠军卡斯帕罗夫)已过去20年的现在,AI再次被推至科技界的风口浪尖。有意思的是,落败的人类棋类高手都感觉到了一种无法抵挡、莫名其妙又令人肃然起敬的智能,你可能会不屑一顾地说,那只不过是一些代码,这种感觉上的差异或许在提醒我们对“智能”的本质仍缺乏深刻的理解。我们一直以来对很多相关的话题都很感兴趣:智能存在的多种形态、多个层面,智能如何演化,不同智能之间的碰撞,等等。
AlphaGo的成功不仅让人们看到了强化学习和随机模拟技术(也称“蒙特卡罗”技术)的魅力,也让深度学习变得更加炙手可热。冷静之余,人们认识到AlphaGo的算法更适用于大规模概率空间的智能搜索,其环境和状态都是可模拟的。DeepMind的创始人德米斯·哈萨比斯表示,对于那些环境难以模拟的决策问题(如自动驾驶),这些算法也无能为力。珀尔在《为什么》第十章也谈论了AlphaGo,他认为缺乏可解释性是它的硬伤,“即使是AlphaGo的程序员也不能告诉你为什么这个程序可以执行得这么好。”
笔者认为,我们不应该把AI技术对立起来,而应该相互取长补短。拿强化学习来说,它不同于有监督学习(supervisedlearning)和无监督学习(unsupervised learning),是基于马尔科夫决策过程发展起来的第三类机器学习方法——智能体通过与环境互动变得越来越“聪明”。强化学习和因果推断都寻求策略(policy),其中,行动之间是有因果关系的,但因果推断更开放一些,它可以利用数据之外的知识来推断策略的效果。强化学习允许推断干预的结果,因此能攀上因果关系之梯的第二层级。通过模拟环境,强化学习无须从现实世界获取观测数据来训练模型,所以也有可能产生反事实从而登上因果关系之梯的第三层级。尽管目前的强化学习很少用到先验知识,我们仍很好奇强化学习和因果推断的理论联系。举个例子,在强化学习中,不同任务之间的知识传递能否用上因果关系?
他山之石可以攻玉,未来人工智能的发展也有“综合”的趋势。譬如,语音、图像、视频数据等都可以转换成文字,而AI技术则能帮助我们加深对数据的理解。同时,借助AI技术(包括因果推断)更好地理解数据也能助力模型训练并改进应用效果。同理,因果论和现有的机器学习等AI技术有没有可能联手互惠互利?例如,因果推断所考虑的变量越多,对计算的挑战就越大,那么,基于蒙特卡罗方法的近似计算是否能其助一臂之力?机器学习能否帮助和改进因果建模?这些问题都有待深入的研究。
学术界对“强AI”一直持谨慎态度,多数学者倾向于“弱人工智能”,即思维机器可以在一些具体应用(如棋类游戏、人脸识别、信息检索等)上表现得十分出色,但本质上不可能达到人类的智能,譬如,像科学家一样思考,理解人类的语言并无障碍地与人类交流,创造具有真正美感的艺术,拥有人类的情感……大家没敢对强AI抱有太多的期望,主要原因是我们对如何形式化人类自身的因果推断能力了解甚少。
因果的形式化理论,不仅解决了困扰统计学家很多年的一些悖论,更重要的是,(1)利用“干预”让人类和机器摆脱了被动观察,从而转向主动地去探索因果关系,以便做出更好的决策;(2)利用“反事实推理”扩展了想象的空间,从而摆脱了现实世界的束缚。这两点突破实现了因果革命,并分别构成了因果关系之梯的第二层级和第三层级的内容。沿着因果关系之梯,机器便有望拥有强人工智能。
珀尔教授一生致力于因果关系科学及其在人工智能方面领域的应用,这本科普著作是他毕生思想的沉淀,其中他以平实的话语介绍了因果推断的理论建构,每段文字都浸透着他对因果关系科学的热情。珀尔教授不仅学问做得好,还执着地追求真理,深入地反省自我,勇敢地阐述思想,在这个堆积术语、追逐名利的学术大氛围里,珀尔教授孤单的身影显得尤为意味深长。
为什么要写这本书?在此之前,珀尔教授已经出版过三部因果关系科学的专著,读者群仅限于数据分析或者人工智能的研究者,影响范围很窄。这本书则是这些专著的科普版,其面向更广泛的读者群体,着重阐述思想而非拘泥于数学细节。对渴望了解因果推断的人们来说,它既是因果关系科学的入门书,又是关于这门学问从萌发到蓬勃发展的一部简史,其中不乏对当前的人工智能发展现状的反思和对未来人工智能发展方向的探索。正如作者所期待的,这场因果革命将带给人们对强人工智能更深刻的理解。
珀尔的《为什么》是笔者所知道的目前已出版的唯一一部因果关系科学方面的科普著作,作者在其中深入浅出地把因果关系科学的理论框架及其发展脉络展现给了读者。值得一提的是,那些曾经令人备感困惑的悖论作为经典统计学中的未解之谜,最终也经由因果关系分析而拨云见日,笼罩在其上的迷雾也随之烟消云散了。水落石出后,因果推断显得如此自然,就仿佛一切本该如此。对于每一位想了解因果关系科学的读者来说,以《为什么》为起点就意味着你踏上了一条捷径,在理解此书的基础上阅读因果关系科学方面的专业著作,你的收获将会更大。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

)
:QString类)
![pytorch数据加载时报错OSError: [Errno 22] Invalid argument](http://pic.xiahunao.cn/pytorch数据加载时报错OSError: [Errno 22] Invalid argument)


:透明窗体设置)




:Win10(x64)+Qt5.8(MSVC2013)+OpenCV3.1.0配置过程)



:绘制图像)

题 DP(递推))


:QLayout的属性介绍)