
来源:AI科技评论
编译:Don
校对:青暮
“如果我们能够揭示大脑的某些学习机制或学习方法,那么人工智能将能迎来进一步的发展,”Bengio如是说。
深度学习依赖于精妙设计的算法,一行行精妙绝伦的公式让冰冷的计算机学习出只有人脑才能执行的任务。深度学习算法虽然启发自人脑的结构单元和学习机制,但这种简单的“模拟”其实并不是人脑真正运行的方式。在最新的研究进展中,科学家们正在抽丝剥茧,利用人工神经网络的算法机制揭示人脑的工作方法。
时间回到14年前,2007年,彼时神经网络和深度学习还是一个冷门的领域。一群深度学习的先锋研究人员悄悄的在一次人工智能学术会议后秘密碰头,举办了一场“非法”的学术研讨会。之所以说它是“非法”的,是因为主会场没有允许他们举办正式的神经网络相关的研讨会,毕竟当时神经网络还是个异类小众群体,支持向量机和随机森林等传统机器学习算法才是所谓的“主流正道”。
在这场非正式的研讨会的最后,来自多伦多大学的Geoffrey Hinton教授压轴发言。彼时的Hinton还不像今日一样名声大噪享誉全球,当时他的身份还是一位认知心理学家和计算科学家,正在深度学习网络领域的研究泥淖中苦苦奋战。在发言之初,他很幽默的说:“大约是一年多以前,有一次我回家吃晚饭的时候说,‘我想我终于弄明白大脑是怎么工作的了!‘,然后我15岁的女儿无奈地撅起嘴回讽我道,‘唉老爸,您又来了,咱别这样了行不’”。
当场在坐的观众都笑了,Hinton接着说,“所以,这就是大脑的工作原理”。这个成功的返场包袱让大家再次忍俊不禁。
在Hinton的这个玩笑背后,是一个神经网络领域一直都在苦苦求索的话题:用人工智能来理解人脑。时至今日,深度学习网络统治了人工智能领域,是当之无愧的新时代的弄潮儿,其背后最大的功臣之一,便是大名鼎鼎的反向传播算法Backpropagation。有时人们也会亲昵的将其简称为Backprop算法。这个算法能让深度学习网络的权重根据学习的目标和喂入的数据学习知识,给算法赋予多种多样的能力,比如图像分类、语音识别、自然语言翻译、自动驾驶中路况的识别,或者其他更玄妙的能力。

Geoffrey Hinton,多伦多大学的认知心理学家和计算科学家,引领了深度学习网络技术的很多重大突破,包括反向传播算法。
但是多年来的生物学研究都表明,生物大脑不太可能使用反向传播机制来进行学习。来自Montreal大学的计算机科学家、魁北克人工智能研究所科学主任、也是2007年那场“非法”的研讨会的组织者之一Yoshua Bengio说,“相对于深度学习算法,人脑更加强大,它拥有更好的泛化和学习的能力”。而且各种证据都显示,在大脑的解剖和生理构造上,特别是在皮质层,人脑是几乎不可能利用反向传播机制进行学习的。

Yoshua Bengio,Montreal大学的人工智能研究员和计算科学家,他也是研究具有生物合理性的学习算法的科学家之一,这些算法和反向传播一样具有很好的学习能力,但是在生物学的角度上也更加合理和可信。
在深度学习领域,一直以来,Bengio和很多同样受到Hinton启发的研究人员都在思考一个更具生物学意义的问题,就是人脑是如何工作和学习的。相对于简单的深度学习算法来说,人脑是一个更趋于完美的有机主体,如果我们能对它的学习机制有所了解,肯定能够促进深度学习的发展。
因此,相关的研究人员一直在苦苦求索这个人脑中的与“反向传播”学习算法相匹配的生物机制。近年来,人们已经取得了一些相关的进展,其中最有前景的三个发现包括——反馈对齐(FeedBack Alignment)、均衡传播(Equilibrium Propagation)和预测编码(Predictive Coding)。还有一些研究人员甚至将生物学中某些类型的皮质层神经元的特性和注意力机制等过程具体化到他们的算法之中,力求揭示人脑神经元学习背后的奥秘。研究人员的每一个进步都让我们对大脑的学习机制有了更深一步的理解。
“大脑是一个巨大的谜团,人们普遍相信,如果我们能够揭示大脑的某些学习机制或学习方法,那么人工智能将能迎来进一步的发展”,Bengio如是说,“但是揭示人脑的工作机制本身也具有极高的研究价值”。
1
使用反向传播进行学习
深度学习网络的基础之一便是生物学中的神经元模型理论,该理论由加拿大心理学家Donald Hebb提出。数十年来,深度学习网络算法的研究都是在该理论的指导下完成的。在理论模型可以通常可以被简单地概括为“一起激活的神经元相互连接”。具体来说,这是指,活动越相关的神经元之间的联系越强。这句简单的“真理”启发了无数后世的研究,源于它的若干规则和算法也成功地落地在一些学习和视觉分类任务中。
但是当神经网络的规模变得十分庞大的时候,由于需要逐步从大量数据中的误差中学习最优的权重,反向传播算法的效果就会差很多了。对于那些处于较深层数的深层神经元而言,它们很难通过残留的梯度发现自身误差,从而不能很好的更新权重并降低误差。所以在这种情况下,深层的神经元经常会出现不学习、不收敛和不拟合的问题。这种问题被称作梯度消失。斯坦福大学的计算神经学家和计算科学家Danniel Yamins说,“Hebb法则是一种反馈利用机制,它非常局限,只在某些很特殊情况下才会起作用,并且对误差十分敏感”。

Daniel Yamins,Stanford大学计算神经学家和计算科学家。他正在研究如何识别生物大脑中到底“运行着”哪些算法。
然而,这是目前为止神经学家能够发现和利用的最佳的模拟人脑学习的机制了。甚至在20世纪50年代那个深度学习算法和思想还未统治人工智能领域的时候,Hebb法则就启发了第一个神经网络模型的诞生。在那个上古时代,神经网络中的每个神经元都仅能接受一个输入,也只能产生一个输出,就跟生物神经元一样。神经元在计算中会将输入乘以一个所谓的“突触权重”,该突触权重表示所连接的输入重要度,然后将加权的输入们求和。这个加和便构成了各神经元的输出。到了20世纪60年代,神经元被组织成了网络,形成一个具有输入层和输出层的全连接网络。而具有该雏形结构的神经网络模型可以用来解决一些简单的分类和回归问题。在训练的过程中,神经网络的目标是最小化输出和真值之间的误差,并据此调整各神经元的权重取值。
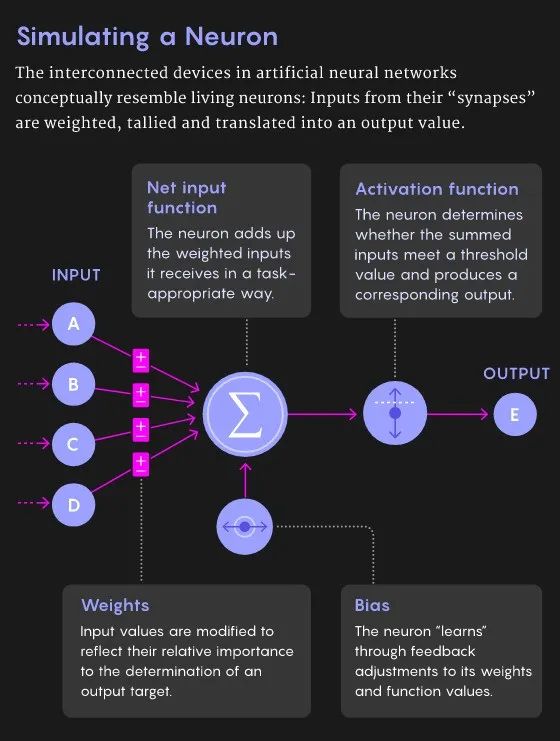
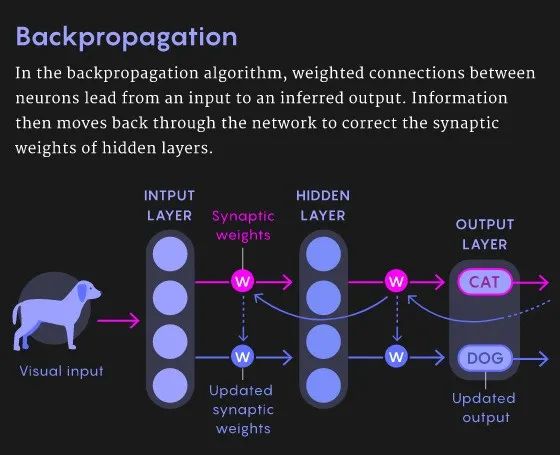
而到了20世纪60年代,神经网络由于添加了输入和输出层,网络的结构开始从三明治向多层夹心巨无霸进化,也就是网络层数开始增多。随之而来的是深层神经元的梯度消失问题。当时没有人知道如何有效地训练这些深层神经元,也没有妥善的方法能够高效地训练具有众多隐藏层的神经网络。这个困境直到1986年才得到解决,而解决的标志便是那篇由Hinton、已故的David Rumelhart和来自美国Northeastern大学的Ronald Williams共同发表的反向传播算法论文。
反向传播算法可以分成前向和反向传播两个阶段。在前向的阶段中,当网络得到一个输入数据,它会根据当前模型的权重得到一个输出,而该输出和理想的目标输出之间存在着一些误差。而后在反向的阶段中,学习算法将根据误差值为每个神经元的权重进行有针对性的更新,从而使输出和目标值之间的误差变小。
为了理解这个学习的过程,我们将网络的实际输出和理想输出之间的误差用一个“损失函数”来进行表示,它描述了模型前向输出结果和期望输出之间的差异。这个损失函数就像是一个二维的“山谷和丘陵”图像,当一个网络的实际输出和期望输出之间的误差较大的时候,对应着二维图形的丘陵部分;当误差较小时,就对应于图形中的山谷。当网络根据指定输出进行前向推理时,得到的输出所对应的误差会对应于二维图像中的某个确切点,而学习的过程就是使该误差从“丘陵”位置沿着“山坡”找到“山谷”的过程。在山谷的位置误差和损失值是很小的。而反向传播算法就是一种更新神经元权重从而降低损失和误差的方法。
从计算的角度和算法的本质上来说,在反向传播阶段中,算法会计算每个神经元的权重对误差的贡献度,然后根据误差结果对这些权重进行修改和更新,从而提高网络的性能、降低损失值并得到理想的输出。这个计算过程是从输出层向输入层传递的,方向是从后层向前层进行的,因此人们将其称为反向传播。反向传播算法会利用输入和输出的期望值所组成的数据集反复调整网络的权重,从而得到一组可以接受的收敛的权重。
2
人脑不可能使用反向传播机制
反向传播算法在很多神经科学家的眼里是一个十分简陋和天真的机制,他们认为在大脑中绝对不会基于反向传播机制进行学习。其中最有名的反对者是Francis Crick,他是诺贝尔奖得主,也是DNA结构的共同发现者。而如今,Fancis则是一位神经科学家。在1989年时,Crick写道:“就学习过程而言,大脑不太可能使用反向传播机制来进行学习”。
科学家们普遍认为反向传播算法在生物学上是不可信的,这主要是基于几个主要的原因。首先,在计算原理上来说,反向传播算法分成了两个明确的阶段,一个前向、一个反向。但是在生物大脑的神经网络中,实现这样的机制是很难的。第二个是计算神经学家称之为梯度/权重传递的问题:反向传播算法会复制或者传递前向中的所有的权重信息,并根据误差更新这些权重从而使网络模型的准确度更高、性能更好。但是在生物大脑的神经元网络中,各个神经元通常只能看到与其连接的神经元的输出,而看不到形成输出的权重分量或其内部的计算过程。Yamins说,从神经元的角度来看,“它们可以知道自己的权重,但问题是它们还需要知道其他神经元的权重,从生物学的角度上来看,这有点困难”。
从生物神经学的角度来看,任何实际的生物模型和学习机制都要满足这样的限制:神经元只能从邻近的神经元获取信息。但显而易见的是,反向传播算法可能需要很远处的神经元的权重信息。所以“话说回来,大脑几乎不可能利用反向传播进行计算和学习”,Bengio说。
尽管探索的困难重重,Hinton和其他的科学家也痛快地接受了挑战,开始研究生物学中大脑的学习过程,努力地探索生物大脑中的“反向传播”学习机制。宾夕法尼亚大学的计算神经学科学家Konrad Kording说:“可以预期的是,第一篇提出大脑会执行类似反向传播学习的论文可能和反向传播的论文一样具有跨时代的意义”。庆幸的是,在过去的十余年中,随着人工神经网络的爆发,人们也开始发力研究生物大脑中的“反向传播”学习机制。
3
更符合生物特性的学习机制
其实在深度学习领域中,除了反向传播之外还有一些更符合生物特性的学习算法存在。比如2016年,来自Google伦敦DeepMind团队的Timothy Lillicrap和他的同事提出了反馈对齐(Feedback Alignment)算法。该算法并没有传递权重,从而在生物学中也就更加的“合理”了。这个算法不会依赖于前向传递的权重矩阵,而是转而使用一个随机初始的反向传递矩阵。在算法中,一旦算法为一个神经元分配了一个权重,这些权重将不会像反向传播算法一样来来回回微调和改变,因此不需要为反向传播过程传递任何权重。
这种算法在算法的角度上来看,虽然不怎么合理,但是很令人惊讶的是,这个家伙很管用,网络能够通过这个算法学到比较合理的结果。由于前向推理的前向权重会随着每次反向传递而更新,因此网络仍旧会降低损失函数的梯度,但是学习和优化的实现方法是有所不同的。在该算法中,前向的权重和随机选择的反向权重会缓慢地对齐,并最终得到正确的结果,因此该算法被称为反馈对齐Feedback Alignment。
“事实证明,这种学习算法不是很糟糕,”Yamins说,至少对于简单的学习任务来说是这样的。但是对于那些复杂的问题,比如当网络规模十分大、神经元数量很多、网络层数很深的情况而言,反馈对齐机制还是不如传统的反向传播有效。这是因为相对于从反向传播得到的误差反馈信息而言,每次传递前向权重的更新都不是那么的准确,所以这样的学习机制就会需要更多的数据。
科学家们同时也在探索另一个领域,就是一种既能达到反向传播的学习效果,又能满足Hebb法则的生物合理性要求的学习算法。简单来说就是如何让算法只利用其相邻神经元的信息进行学习和权重的更新。比如Hinton就提出了一个想法:每个神经元同时进行两组计算。Bengio说,“这基本上就是Geoffs在2007年所说的那件事儿”。
在Hinton工作的基础上,Bengio的团队在2017年提出了一个学习方法,该方法需要一个具有循环连接的神经网络,也就是说,如果神经元A激活了神经元B,那么神经元B反过来也会激活神经元A。这个网络在得到一些输入的时候,会产生一些“回响”(reverberating),因为每个神经元都会立即对其相邻的神经元产生反馈。
最终,网络会达到一种相对稳定的状态,在该状态下,网络会在输入和各神经元之间维持一个平衡状态,并产生一个输出,然而这个输出和理想值之间存在一定的误差。然后,算法将改变神经元的权重,从而使网络的实际输出朝着理想输出值靠拢。这将使得另一个信号通过网络反向传播,从而起到类似的作用。最终,网络就能找到一个新的平衡点。
“算法背后的数学之美在于,如果你比较修改前和修改后的权重,你就能得到改变梯度所需的所有信息,”Bengio说。网络的训练只需要在大量带标签的训练数据上重复这个“均衡传播(Equilibrium Propagation)”的过程就能找到最终的结果。
4
预测感知
在生物学中,大脑感知过程的新研究也体现了神经元只能对局部环境做出反应的特性。Beren Milidge是Edinburgh大学的博士生,也是Sussex大学的访问学者,他和他的同事们一直在研究这种大脑神经元的感知机制,也就是我们所谓的预测编码(Prediction Encoding)和反向传播之间的关系。Milidge说:“如果在生物大脑中预测编码机制真实存在的话,那它将为我们提供一个生物学上合理的背景支撑”。
预测编码理论假设大脑不断地对输入做出预测,这个过程涉及神经处理的层次结构。为了产生一定的输出,每一层都必须预测下一层的神经活动。如果某个高层的神经元认为“我需要提取出一张脸的抽象特征”,它会认为它的下一层会利用这个脸的特征进行更高层更抽象的活动。如果下一层利用了该信息,那么就印证了我提取脸的操作是正确的,反之就说明这个特征没有意义,因为它没有被利用。概括来说,下面一层会利用上一层所提取出的有用特征,有用的特征就像是落在视网膜上的光子一样。这样的话,预测就从高一层流向低一层了。
但是话说回来,误差可能发生在网络的每一层中,每一层的输入和输出之间都会存在或多或少的差异,这些差异的叠加才形成最终的误差。最底层的网络根据收到的感知信息调整权重从而最小化误差。这种调整可能会引起刚刚更新的层和上面层之间产生误差,因此较高的层必须重新调整权重来最小化预测误差。这些误差逐渐累积并同时向上传递。网络产生误差和权重调整贯彻始终,并前后传递,直到每一层的预测误差达到最小。
Millidge已经证明,通过适当的配置,这种学习方法的预测编码网络可以收敛到和反向传播算法十分类似的权重。他说:“你可以将网络训练得非常非常接近于反向传播的权重结果。”
但是相对于深度学习网络的传统的反向传播算法来说,预测编码网络需要一次又一次地进行的迭代传播,仅仅传播一次是不能够收敛的。网络的学习过程是一个一个渐进修改的过程,预测编码网络通常需要几十上百甚至千余次的传播才能收敛。迭代也是需要时间的,因此这种迭代的机制是否具有生物合理性取决于在真实的大脑中每次传播所需的时长。其中的关键点在于,生物大脑的神经网络必须快到在外部世界的输入发生变化之前,就收敛到一个稳定的状态下。
Milidge说:“学习的过程肯定很快,比如说,当有一只老虎向我扑来的时候,我肯定不可能让我的大脑反复计算、反复传播个几百次,然后告诉我:跑!那样的话估计我腿还没迈开就成了老虎的下午茶了。”尽管如此,他说:“所以在真实的大脑中,一些误差和不准确是可以接受的,预测编码应该能够很快的计算出一个可以接受的、一般来说都很管用的较优结果”。
5
椎体神经元
除了上述的比较“高级”的研究之外,也有很多科学家致力于基础研究,比如根据单个神经元的特性建立起具有类似反向传播能力的模型。在标准的神经元中,存在着一种生理结构叫做树突,树突从其他神经元中收集信息,并且将信号传递到神经元的细胞体中。所有的输入在细胞体中被整合。这个输入到整合的现象可能会导致神经元激活,从而产生轴突到突触后神经元树突的动作电位和生物电尖峰,当然在某种情况下也不会产生对应的动作电位。
但并不是所有的神经元都有这种结构。特别是对于锥体神经元来说。锥体神经元是大脑皮层中最丰富的神经元类型,它具有树状结构,并且具有两组不同的树突。树突的神经干向上伸展并开叉,分成所谓的顶端树突;而神经元根部向下延伸并形成基部树突。
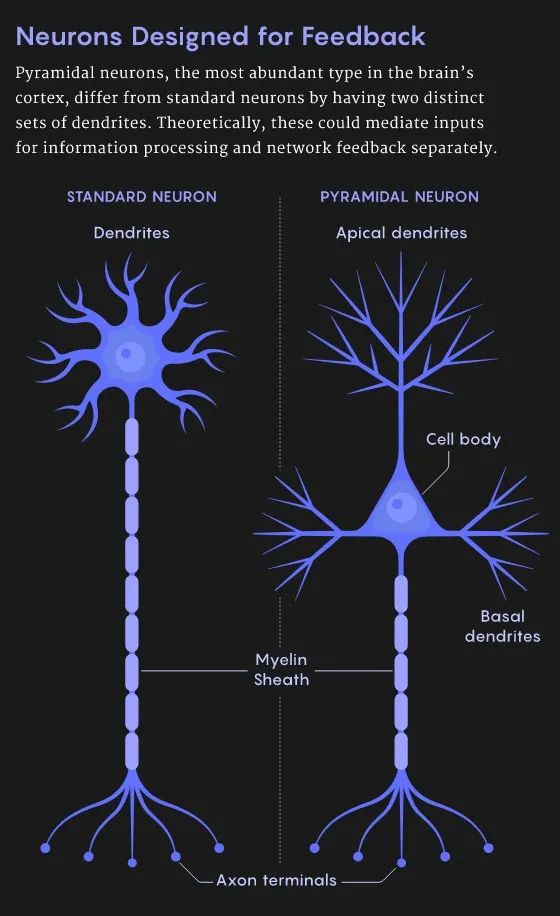
Kording在2001年就曾独立提出过相应的神经元模型。无独有偶,最近来自McGill大学和Quebec人工智能研究所的Blake Richards及其同事也提出了类似的神经元模型。这些模型已经表明神经元可以通过同时进行正向和反向的计算来形成深度学习网络的基本单元。其模型的关键在于从输入神经元的信号中分离出正向推理和反向误差的传播分量,这两种误差分量是分别由基底树突和顶端树突分别处理的。这两种信号的信息可以同时在神经元中进行编码,经过处理后可作为输出发送到轴突,并转换为生物电信号。
Richards说,在他们团队的最新研究中,“我们已经验证了锥体神经元模型的可用性,我们通过算法来模拟锥体神经元的计算,并且验证锥形神经元网络能够完成各种任务的学习 。然后我们将网络模型进行初步的抽象,并利用这个由锥体神经元所组成的抽象模型进行更加复杂的任务,这些复杂的任务和普通的机器学习算法和神经网络所做的任务一样。”
6
注意力机制
在反向传播机制中,算法默认需要一个“老师”。具体来说,“老师”就是算法中损失值对各权重的偏导梯度,通过老师的“指导”,算法能够据此修改权重的大小。也就是说,我们需要一个提供误差信息的机制。但是来自荷兰阿姆斯特丹神经学研究所的Pieter Roelfsema说:“大脑中是没有一个老师的,它也没有一个器官或者机制来告诉每一个运动皮层的神经元对应的监督信息,每个皮层也无从知晓自己到底是应该激活还是静息”。
Roelfsema认为,虽然没有老师的信息,但是大脑可以利用注意力机制来实现类似的效果以解决问题。在20世纪90年代末,Roelfsema和他的同事们发现,当一只猴子注视一个物体的时候,大脑皮层中代表该物体的神经元就会表现得更加活跃。猴子大脑中的注意力信息充当了老师的角色,为皮层中的神经元提供反馈监督信息。“这是一个具有高度选择性的反馈信号,”Roelfsema说,“这不是误差信号,它只是对所有这些神经元说:嘿伙计,我们要做一件事儿,你得出把力激活一发了。”
Roelfsema认为,当基于注意力的这种反馈信号和神经科学领域中某些已有或者还未发现的现象相结合的时候,能够在生物大脑中实现类似于反向传播的学习效果。例如,剑桥大学Wolfram Schultz和其它人已经证明,当动物执行的某些动作产生比预期还好的效果的时候,生物大脑中的多巴胺系统就会被激活,从而产生正向的激励效果。“多巴胺是一种神奇的神经调节剂,能让动物们产生愉悦和幸福的感觉, 当我们获得了多巴胺的正向激励时,它将遍布我们的全身,强化神经元对于这种反应和动作的认可”。
Roelfsema说,理论上来说,注意力反馈信号只能激活那些负责一个动作的神经元,通过更新它们的神经元权重来对整体的强化信号做出反应。Roelfsema和他的同事们基于这个想法实现了一个深度神经网络,并研究了它的数学特性。“结果是,这种机制能够达到和反向传播一样的数学结果。但是从生物学的角度上来看,注意力机制的权重调整方法显然更加合理”。
Roelfsema的团队已经将该工作发表到了2020年12月的NeuroIPS在线会议上。他表示,“我们可以通过这个方法训练深度网络,它只比反向传播算法慢了2至3倍。”因此,他说,“在所有符合生物合理性的学习算法中,基于注意力的学习机制已经是其中最好的一个了”。
但是,我们的大脑真的是利用这些看似很玄学的机制来进行学习的吗?似乎目前的研究不足以证明这一点。这些机制只是我们的一些经验假设而已。Bengio说:“我认为我们的研究忽略了一些东西。以我的经验而言,这可能是一些很小的机制和细节,也许我们只需要对现有的方法稍作修改就能起到奇效。”
那我们如何去确定哪种学习算法在生物中是合理的呢?Yamins和他的斯坦福同事提出了一些建议。他们通过分析1056个深度网络中的学习方法,发现可以通过神经元子集随时间的活动现象来确定大脑的学习方法。这种信息能够从猴子大脑的活动记录中获取。Yamins说:“事实证明,如果我们能够收集到正确的观测数据,那确定生物大脑的学习方式就变得十分简单了。”
每每想到这些好处,计算神经学家们都会暗自欣喜。Kording说:“大脑其实有很多种可以实现学习的方法,就像反向传播一样有效。生物的进化十分奇妙,我相信反向传播是有效的,而进化论会推着我们朝着这个方向演进的!”
原文链接:
https://www.quantamagazine.org/artificial-neural-nets-finally-yield-clues-to-how-brains-learn-20210218/
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


)


)
)

)


)


)

)


)
