
来源:人机与认知实验室
翻译:朱浩然
摘要:
人工智能和机器学习的最新研究在很大程度上强调了通用学习和越来越大的训练集以及越来越多的计算。
相反,我提出了一种以认知模型为中心的混合,知识驱动,基于推理的方法,该方法可以为比当前可能的更丰富,更健壮的AI提供基础。
1.迈向强大的人工智能
尽管没有人完全知道深度学习或人工智能将在未来几十年发展,但是如果我们要达到一个新的水平,那么既要考虑过去十年所学到的知识,又要研究下一步应该研究的东西。
让我们将其称为健壮的人工智能新水平:虽然不一定是超人或自我完善的智能,但可以依靠它以系统和可靠的方式将其所学知识应用到广泛的问题中,从各种知识中综合知识来源,这样它就可以灵活,动态地对世界进行推理,以一种我们对普通成年人所期望的方式,将它在一个环境中学到的东西转移到另一环境中。
从某种意义上说,这是一个微不足道的目标,既不像“超人”或“人工智能”那样雄心勃勃,也没有像它那样无边无际,但也许是迈出重要的一步,并且是可以实现的,如果我们要实现这一目标,那是至关重要的一步。创建我们可以信赖的人工智能,无论是在我们的家中,在道路上,在医生的办公室和医院,在企业中还是在社区中,我们都可以信赖。
简而言之,如果我们不能指望人工智能能够可靠地表现,那么我们就不应该信任它。(当然,事实并非如此:可靠性不能保证可信度;相反,可靠性不能保证可信度。这只是许多前提条件之一,包括价值和良好的工程实践;请参阅Marcus和Davis(Marcus&Davis,2019)进行进一步讨论。)
§
有人可能会将强大的AI与例如狭义的智能,可以很好地完成单个狭窄目标(例如下棋或识别狗的品种)的系统进行对比,但这些系统往往以非常单一的任务为中心,并且不健壮且无法转移到甚至适度不同的环境(例如,到不同尺寸的电路板,或从一个具有相同逻辑但字符和设置不同的视频游戏到另一个视频游戏),而无需进行大量的重新培训。当将这些系统应用到要在其上进行训练的确切环境时,它们通常会表现出令人印象深刻的良好效果,但是,如果环境与他们在其上进行训练的环境有所不同,有时甚至是很小的差异,我们通常就无法指望它们。这种系统在游戏环境中已显示出强大的功能,但在现实世界的动态,开放式流程中尚未被证明是足够的。
还必须将强大的智能与我称之为点画式智能进行对比,点智能在许多情况下都有效,但在许多其他情况下却失败了,表面上看起来很相似,以某种无法预测的方式。图1展示了一个视觉系统,该视觉系统通常可以识别校车,但是在积雪的道路中(左)无法识别翻倒的校车(左),而阅读系统(右)可以正确地解释一些句子,但在阅读过程中却失败。存在无关的干扰物。

任何密切关注AI文献的人都将意识到,健壮性从一开始就一直遥遥无期。尽管已经投入了巨大的资源,但深度学习迄今仍未解决该问题。
相反,到目前为止,深度学习技术已证明是数据饥渴,浅薄,易碎且泛化能力有限(Marcus,2018)。或者,正如Francois Chollet(Chollet,2019年)最近所说的那样,人工智能一直未能达到其理想:尽管我们能够设计出在特定任务上表现出色的系统,但它们仍然存在明显的局限性,脆弱性,数据量饥饿,无法理解与培训数据或创建者的假设略有不同的情况,并且在没有人类研究人员的大量参与的情况下无法调整自己的工作方式来应对新颖的任务。
用Facebook AI研究人员团队的话说(Nieet al。,2019)
“越来越多的证据表明,最先进的模型学会了利用数据集中的虚假统计模式……而不是像人类那样灵活而可概括地学习意义。”
正如Yoshua Bengio在最近的一篇文章(Bengio等人,2019年)中所指出的那样,一个关键的弱点是当需要将机器学习方法推广到训练分布之外时,当前的机器学习方法似乎很薄弱,而这在实践中通常是需要的。
我们怎样才能将AI提升到一个新的水平?
§
我认为,如果不首先开发具有我和ErnieDavis所说的深刻理解的系统的能力,我们就不会获得强大的情报,这不仅具有关联和辨别复杂数据集中细微模式的能力,而且还具有查看任何场景并解决一些问题,例如记者可能会问:谁,什么,什么地方,为什么,何时以及如何。
在美好的一天,像被广泛讨论的神经网络GPT-2这样的系统可以产生故事和类似的给定句子片段,可以传达表面上似乎反映出深刻理解的东西。例如,给定一个句子片段(以粗体显示),例如“两个士兵走进酒吧”,它通常可以产生流利且听起来似真实的连续感,例如人,酒吧,饮料和金钱之间的关系:
两名士兵走进摩苏尔的一家酒吧,把所有的钱都花在了喝酒上。
但是,无论许多GPT-2例子看起来多么引人注目,事实都是它的表示很单薄且不可靠,类似于Nie等人(2019)所指出的那样,通常在密切检查下会崩溃(Marcus,2020)。这是两个典型案例,取材自我于2019年12月在NeurIPS(Marcus,2019)上提出的开发中基准测试。
•昨天我把衣服放在干洗店里了,还没捡起来。我的衣服在哪里?在我妈妈的房子里。
•原木上有六只青蛙。两只离开,三只加入。现在原木上的青蛙数是十七。
首先,GPT-2可以正确预测查询片段后面的元素类别(即位置),但无法跟踪干洗位置。在第二篇中,GPT-2再次正确预测了正确的响应类别(在这种情况下为数字),并且再次无法掌握细节。正如Marcus(Marcus,2020; Marcus,2019)所讨论的那样,这种错误非常普遍。显然,我们将需要更稳定的基材以实现坚固性。
§
一切照旧主要集中在稳步改善深度学习工具箱中的函数逼近和组合工具,以及收集更大的训练集并扩展到越来越大的GPU和TPU集群。可以想象通过收集更大的数据集,以各种方式扩充这些数据集以及在基础架构中纳入各种改进来改进像GPT-2这样的系统。尽管这些方法具有价值,但需要进行更根本的重新思考。
可能会采用更多激烈的方法。例如,Yoshua Bengio为大幅扩展深度学习工具包提出了许多复杂的建议,包括开发通过对分布变化的敏感性统计提取因果关系的技术(Bengio等人,2019)和自动提取模块化的技术。结构(Goyal et al。,2019),我都十分同情。
但我认为这还不够,可能需要更强有力的药物。特别是,本文的建议,即我们必须重新集中精力,致力于开发一个框架,用于构建能够常规获取、表示和操作抽象知识的系统,使用这些知识来构建、更新和推理复杂的外部世界内部模型。
§
从某种意义上说,我将要咨询的是回归到三个问题:经典人工智能知识、内部模型和推理,但希望以新的方式,用现代的技术来解决它们。
这些问题都是经典人工智能的核心。例如,约翰·麦卡锡在他的开创性论文《程序与常识》(Programs withCommon Sense)中指出了常识知识的价值[McCarthy 1959];道格·莱纳特(Doug Lenat)将常识知识的机器表达形式作为他毕生的工作来解释(Lenat,Prakash,&Shepherd,1985;Lenat,2019)。由TerryWinograd(谷歌创始人Larry Page和Sergey Brin的导师)设计的经典AI“blocks world”系统SHRLDU围绕一个内部的、可更新的世界认知模型展开,该模型表示软件对一组堆叠物理对象的位置和属性的理解(Winograd,1971)。然后,SHRLDU对这些认知模型进行推理,以便推断出随着时间的推移,世界的状态。
浏览一下机器学习领域最新论文的标题,你会发现很少有人引用这些观点。一小部分人会提到推理,另一小部分人可能会提到实现常识的愿望,大多数人会(故意地)缺乏丰富的认知模型,比如个人和物体,它们的属性,以及它们之间的关系。
例如,一个像GPT-2这样的系统,做它所做的事情,不管是好是坏,没有任何明确的(直接表示和随时共享的)常识知识,没有任何明确的推理,也没有任何它试图讨论的世界的明确的认知模型。
许多人认为这种缺乏费力编码的显性知识的优势。GPT-2并不是反常的,而是一种当前趋势的特征,即远离经典人工智能的关注,转向一种不同的、更为数据驱动的范式,这种范式是由深度学习的复苏所推动的(大约2012年)。随着DeepMind备受推崇的Atari游戏系统(Mnihet al.,2015)的出现,这一趋势加速发展,正如后面所讨论的,该系统在不使用任何详细认知模型的情况下成功地玩了各种各样的游戏。
最近,强化学习的创始人之一Rich Sutton在一篇广为阅读的文章中明确了这一趋势。这篇名为“痛苦的教训”的文章明确建议不要利用人类的知识:
从70年的人工智能研究中可以得到的最大教训是,利用计算的一般方法最终是最有效的,而且在很大程度上……研究人员试图利用人类对该领域的知识,但从长远来看,唯一重要的是利用计算。…人类知识方法倾向于使方法复杂化,使它们不太适合利用利用计算的一般方法。
在某种程度上,将人类知识构建到机器学习系统中甚至在机器学习界被视为作弊,当然也不可取。在DeepMind最有影响力的论文之一“掌握围棋的游戏而不需要人类知识”中,其目标是完全放弃人类知识,以便“学习、制表、超人在挑战领域的熟练程度”(Silver等人,2017)。如果能从大规模的语料库中归纳出常识,并且有最小的先验约束,那么机器学习社区的一大群人将非常高兴。【当然,盲目地同化所有人类所说的一切,都会以自己的方式产生问题。正如ConceptNet的主要维护者Robyn Speer所说,我们的雄心壮志应该更好:“我们希望避免仅仅因为电脑对人来说很糟糕就让电脑对人来说很糟糕。我们希望提供的(知识表达)不仅是技术上最好的,而且在道德上也很好。】模型构建也被证明是一项艰苦的工作,而且普遍的看法是,如果能跳过这一步,生活会更轻松。
§
问题是,即使有大量数据,也有像GPT-2(Radford等人,2019)那样的Transformer(Vaswani等人,2017)这样的基础,当代神经网络收集的知识仍然是零散的和点状的,可以说是有用的,当然令人印象深刻,但永远不可靠(Marcus,2020)。
上面的例子(如果你把洗好的衣服放在家里,显然不可能还在你妈妈家里)和更明确的GPT-2测试中都暗含着这种不可靠和不可靠,比如:
如果打破玻璃瓶水,水可能会滚动。
如果打破玻璃瓶水,水可能会破裂一些并溅到地板上。水会产生气泡,当瓶子中的水量增加时气泡会膨胀。
如果您打破了一个装有玩具兵的玻璃瓶,玩具兵可能会跟随您到那里。
至关重要的是,萨顿关于用“通用方法”代替人类知识的价值的例子来自封闭性领域,例如游戏,对象分类和语音识别,而常识则是开放性的。在Go之类的游戏中获胜与解释和评估新闻故事或解决现实世界中意料之外的计划问题大不相同,例如阿波罗13号机如何确定如何在宇航员所在的濒危航天器上解决空气过滤器问题快速耗尽。这是一种一次性解决方案,似乎超出了无知识的深度强化学习所可能管理的范围。当要知道干洗地点在哪里时(就像前面的例子一样,昨天,我把衣服放在干洗店里了,还没有捡起来。),您需要一个世界的内部模型,以及一种随着时间的推移更新模型的方法,这是一些语言学家称为话语更新的过程(Bender&Lascarides,2019)。像GPT-2这样的系统根本没有那样的功能。
当纯粹的计算能力应用于开放式领域,如会话语言理解和对世界的推理时,事情就不会完全按照计划进行。结果总是过于尖刻和零散,不可靠。
是时候反思一下了:如果我们接受了深度学习的教训,但人类的知识和认知模式再次成为寻求人工智能的一流公民,我们的系统会是什么样子?
2,一种混合的、知识驱动的、基于认知模型的方法
许多认知科学家,包括我自己,都以一种循环的方式来对待认知:有机体(例如人类)从外部吸收感知信息,他们基于对信息的感知建立内部认知模型,然后做出尊重的决策。这些认知模型,其中可能包括有关外部世界中存在哪种类型的实体,它们的属性是什么以及这些实体之间如何关联的信息。认知科学家普遍认识到,此类认知模型可能不完整或不准确,但也将它们视为有机体如何看待世界的关键(Gallistel,1990;Gallistel&King,2010)。即使是不完美的形式,认知模型也可以作为世界的有力指南。在很大程度上,有机体在世界上的繁荣程度取决于这些内部认知模型的良好程度。
电子游戏实质上是按照类似的逻辑运行的:该系统具有某种世界内部模型,并且该模型会根据用户输入(以及游戏模拟世界中其他实体的活动)定期进行更新。游戏的内部模型可能会跟踪角色的位置,角色的健康状况和所有物等。)游戏中发生的事情(用户朝特定方向移动后是否发生碰撞)是该模型动态更新的功能。
语言学家通常根据一个相似的循环来理解语言:句子中的单词被解析成一个语法,映射到一个语义上,这个语义指定了各种实体参与的事件之类的事情。该语义用于动态更新世界模型(例如,各种实体的当前状态和位置)。机器人学的许多工作(虽然不是全部)都是以类似的方式进行的:感知、更新模型、做出决策。(有些工作,特别是对物体抓取的端到端的深度学习不起作用。)
当前论文最强烈、最核心的观点是,如果我们不做类似的事情,我们就不会成功地寻求强大的智能。如果我们的人工智能系统不能利用对世界及其动力学的大量知识,对外部世界的过于详细、结构化、内部模型进行描述和推理,它们将永远类似于GPT-2:它们会利用大量的相关数据库,正确地处理一些事情,但它们不会理解正在发生的事情,我们也不会能够依靠他们,特别是当现实世界中的情况偏离训练数据时,就像他们经常做的那样。【如果GPT-2的输入范围扩大到包括感性输入而不仅仅是文本输入,它会做得更好吗?也许,但我不认为仅仅扩大输入范围就能解决系统缺乏明确的内部模型的根本问题。同时,值得注意的是,盲童发展出丰富的内部模型,学习了相当多的语言以及如何将其与这些模型联系起来,完全没有视觉输入(Landau,Gleitman,&Landau,2009)。】
§
为了拥有能够以健壮的方式对世界进行推理的系统,我们需要什么计算先决条件?想要将深度学习(主要侧重于学习)和经典AI(更关注知识,推理和内部认知模型)之间的桥梁联系起来,将需要做什么?
作为热身运动,可以考虑将简单的任务作为较大挑战的替代品。假设您正在构建一个机器学习系统,该系统必须基于少量数据来获得广泛范围的概括,并且您将获得少量这样的训练对,其输入和输出均表示为二进制数:
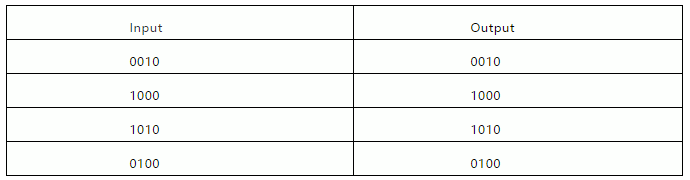
对于任何人来说,很快就会发现这里有一个笼统的概括(称为“规则”),例如恒等式的数学定律f(x)= x +0。适用于新案例[f(1111)= 1111; f(10101)= 10101,依此类推]。
令人惊讶的是,一些神经网络体系结构(例如,多层感知器,最近被一本教科书描述为深度学习的典型例子)遇到了麻烦。这是一个多层感知器的示例,输入在底部,输出在顶部,中间是一个隐藏层。对于任何接触过神经网络的人来说,它应该看起来很熟悉:
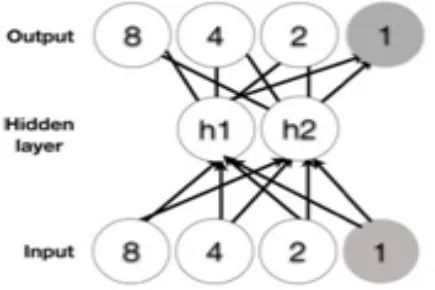
多层感知器接受身份功能训练
这样的网络可以容易地学习将输入与输出相关联,并且实际上“通用函数逼近”的各种定律可以保证这一点。给定足够的训练数据和通过训练数据进行的足够迭代,网络可以轻松掌握训练数据。
当一切顺利的时候(例如,如果架构设置正确,并且没有陷入学习的局部极小值),它还可以推广到其他示例,这些示例在重要方面与所看到的示例相似。在“培训分配范围内”,例如:
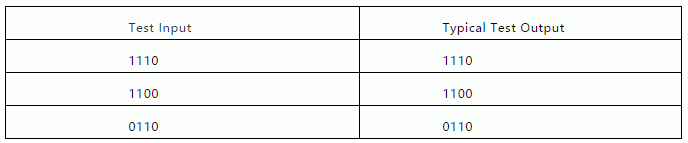
但是,在训练分布之外进行泛化却是完全不同的局面:
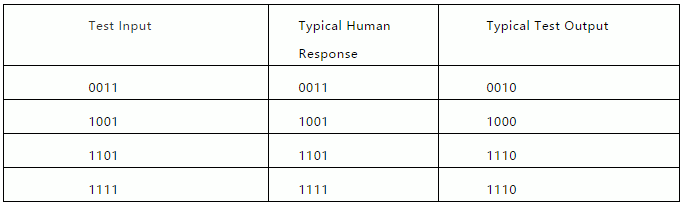
这样的例子表明,尽管在训练分布范围内的案例表现良好,多层感知器神经网络毕竟还没有学习到身份关系。如果同一系统仅针对偶数在f(x)=x上进行训练,则不会将身份函数扩展到奇数,这不在训练分布范围内(Marcus,1998)。举几个例子,每个输出节点,包括最右边的代表“ 1”位的节点,都应以类似的方式处理:我们采用了最左边的位抽象为最右边的位的抽象概念。经过反向传播训练的多层感知器对不同的东西有反应。最右边的节点始终为零,因此网络将继续预测最右边的节点将始终为零,而不管输入的性质如何,例如,得出f(1111)=1110。网络以其自己独特的方式进行了概括,但并未概括人类自然会发生的身份关系。
添加隐藏层不会改变网络的行为(Marcus,1998);添加具有更多节点的隐藏层也不会改变(Marcus,1998)。当然,可以将任意数量的解决方案组合在一起来解决特定的问题(仅从偶数、二进制示例中学习身份),我在这里仅使用简单的身份示例,仅用于说明目的,但是在训练分布之外进行外推的问题很普遍,并且越来越得到认可。JoelGrus在这里给出了一个类似的例子,游戏fizz buzz和Lake and Baroni(Lake&Baroni,2017)展示了一些现代自然语言系统如何容易受到类似问题的影响,无法以各种方式将抽象模式概括为新单词。Bengio在最近的NeurIPS演讲(Bengio,2019)中对现存的中枢神经网络的能力进行了限制。在规范的神经网络架构中,广泛的共性(如同一性)的非均匀扩展是非常普遍的,在我看来,它仍然是进展的主要障碍。
§
从本质上讲,某些种类的现存神经网络(例如此处讨论过的反向传播训练的多层感知器)在两方面表现出色:记忆训练示例,以及在围绕这些示例的点云内插点,这些点围绕超维空间的某些簇(我称之为在培训空间中进行概括),但在培训空间之外(在Bengio的措辞中,即培训分布)中,它们的推广效果很差。
多层感知器:善于在训练样本空间内推广,而不善于在训练样本空间外推广同一性函数。
结果是出现了两个密切相关的问题:
1.特质:在开放式领域中,如果系统缺乏可靠的方法来概括超出训练示例空间的内容,则不能信任这些系统。如果你把每个单独的系统看作一个函数逼近器,那么目前流行的系统往往擅长于记忆示例,并且擅长于训练示例附近的许多(尽管不是全部)示例,这使得它们对于围绕分类的许多应用程序很有用。但是,如果超出培训范围,他们就很穷了。例如,最近的一个数学学习系统擅长于1+1=2;1+1+1=3到1+1+1+1+1=6,但在1+1+1+1+1+1+1=7和所有更大的例子中都失败了。(想象一下,在一个计算机程序中编写一个FOR循环,其中只有小于7的计数器值才能信任执行)。(相比之下,微软Excel的Flash-fill是一种基于归纳程序综合的符号系统,在许多情况下更有效(Polozov&Gulwani,2015)。
2.过分依赖训练制度的具体细节:尽管所有正常的人类学习者都掌握了他们的母语和对世界的理解,但尽管环境千差万别,神经网络往往对确切的细节非常敏感,例如训练项目的呈现顺序(因此有一篇关于神经网络“课程”的文献)。同样地,三十年来人们已经知道,它们容易受到灾难性干扰的影响,即早期的关联被后来的关联覆盖(McCloskey&Cohen,1989),这使得它们对项目呈现的顺序非常敏感。潜在的解决方案仍在定期提出(McClelland,2019年),但问题仍然存在。同样,正如最近的一篇论文(Hillet al.,2019)所说,“网络表现出的泛化程度在很大程度上取决于给定任务实例化的环境细节。”
§
特质和无法推断超出训练分布范围与我们许多常识性知识的普遍性相矛盾。这也使因果关系难以估量;另见Pearl和Mackenzie(Pearl&Mackenzie,2018)。
从引言中扩展一个例子,大多数普通的成年人和儿童将认识到(大概是从特定的经验中得出的)以下抽象的因果归纳是正确的:如果您打破了一个盛装液体的瓶子,一些液体将会(其他事情正在发生)相等)可能会越过瓶子。
这样的真理是抽象的,因为它们不仅适用于某些特定项目,而且适用于大型的,不限成员名额的实体类别,而与瓶子的颜色或形状或瓶子的大小无关,无论瓶子是否装有水,咖啡,或不寻常的软饮料。我们希望对于装有滚珠轴承或游戏骰子的瓶子也能有类似的概括,即使我们以前对破碎瓶子的经验几乎只涉及盛装液体的瓶子。
几乎每个人也都会意识到以下概括是不切实际的:如果您打破了一个盛装液体的瓶子,那么一些液体(其他东西将相等)可能会卷走300米。
同样,无论个人经验如何,我们都可以通过多种方式扩展此知识,因为对于大小不一的瓶子,甚至比以前遇到的瓶子大或小的瓶子,这种主张都不太可能成立。
在这种意义上,我们如何代表和操纵并获得抽象的知识,不仅涉及特定实体,还涉及整个事物类?
外推的挑战意味着像反向传播训练的多层感知器这样的通用工具本身并不是适合该工作的工具。相反,我们必须找到一种替代的机制来学习,表示和扩展抽象知识。
2.1混合架构
2.1.1变量上的符号运算提供了唯一的已知解决方案,但解决方案是局限的
解决方案变量上的符号运算提供了一个潜在的答案-每天几乎每秒使用数万亿次的解决方案,几乎是世界上所有软件的基础。特别是,实际上,每个计算程序都包含四个基本概念:变量,实例,将变量绑定到实例的绑定以及对变量的操作。
这些想法中的每一个都是小学代数所熟悉的,其中像x和y这样的实体是变量。特定数字(2、3.5等)是这些变量可能绑定的实例(例如,x当前可能等于3)。操作包括加法和乘法。这些使得可以表示诸如y = x + 2之类的关系,这些关系自动扩展到某个类中的所有值(例如,所有数字)。将变量连接到实例的过程有时也称为变量绑定。
当然,计算机程序是建立在同一根基石上的。算法主要是根据对变量执行的操作来指定的。将变量绑定到实例,调用算法,执行操作,并返回值。
重要的是,核心操作的指定方式通常适用于某个类的所有实例(例如所有整数、所有字符串或所有浮点数)。核心操作通常包括一些基本操作,如算术运算(加法、乘法等)、比较(x的值是否大于y的值)和控制结构(对变量n当前绑定到的任何值执行n次操作;如果x的值超过y的值,则选择备选方案a),否则选择备选方案b等)。一级近似(忽略bug、程序员逻辑中的错误等),这意味着正确实现的函数适用于某个类中的所有输入,完全独立于它们可能暴露于或不暴露于的输入。
值得注意的是,这种根据操作定义的功能定义事物的方法是与标准机器学习完全不同的范例。机器学习系统通常通过Judea Pearl将其比作曲线拟合的过程来学习将输入变量与输出变量相关的函数,而程序员通常根据变量的运算来独立于训练数据来定义其算法。不用说,它已经很好地服务于传统的计算机程序员,支持从操作系统到Web浏览器到视频游戏再到电子表格等的所有内容。
至关重要的是,通常将系统对变量的核心操作构建为独立于经验而系统地工作。例如,微处理器中的循环移位操作的机制是由一组并行的子操作定义的,每个子操作一个位,直到微处理器字的宽度。不管以前是否使用过该操作,其操作都相同,因此无需学习。程序员可以放心地预期,无论经验如何,换档操作都将起作用,并且无论经验如何,将来都将以此方式继续进行。所有这些机制(变量,实例,绑定和操作)的优点在于,它允许程序员以某种抽象级别指定事物,并以某种可靠性作为副产品。
总的来说,关于变量,绑定,实例和对变量的操作的这四个假设构成了符号操纵的核心(Newell,1980;Marcus,2001)。(符号本身只是对其他系统使用的事物进行编码的简单方式,例如用于表示ASCII代码中的字母的二进制数字模式,或允许神经网络中的输出节点表示特定单词的编码据我所知,目前所有的系统都使用它们;请参阅Marcus 2001,第2章。某些符号处理系统可能只有少量的操作,例如加法,连接和比较,而另一些符号可能具有更丰富的操作(例如,复杂逻辑公式的统一),就像微处理器的大小可能有所不同一样。他们的核心指令集。可以在符号处理体系结构上构建递归,但这并不是绝对的逻辑要求。
正如我所说(Marcus,2001;Marcus,1998;Marcus,Vijayan,Bandi Rao,&Vishton,1999;Berent,Marcus,Shimron,&Gafos,2002;Berent,Vaknin,&Marcus,2007),某种形式的符号操纵似乎对人类认知是必不可少的,比如当一个孩子学会了一种抽象的语言模式,或者一个像姐妹这样的词的含义可以被理解应用于无限多的家庭,或者当一个成年人以一种新颖的方式扩展了一种熟悉的语言模式,这种方式超越了训练分布(Berent et al.,2002;Berent et al.,2007)。一些最有力的证据来自1999年的一项研究(Marcus等人。,1999年),我的同事和我展示了7个月大的婴儿能够识别简单的抽象模式,比如拉塔塔中的ABB模式,并将它们从一组训练样本中推断出完全由不同音节组成的新字符串,这些音节在语音上与他们的训练集没有重叠。随后的研究表明,即使是新生儿似乎也有能力进行这种推断。Gallistel和King(Gallistel和King,2010)认为变量的存储和检索对于动物认知至关重要。例如,蜜蜂似乎能够将太阳方位角功能扩展到它们未曾接触过的光照条件。(Dyer和Dickinson,1994年)。
符号处理的通用机制也为结构化表示提供了基础(Marcus,2001)。例如,计算机程序通常使用由符号构成的树形结构,这些符号通过对变量的操作组合而成,以表示各种各样的事物(例如层次结构文件夹或目录)。
同样,符号操纵的机制允许跟踪个体随时间变化的属性(例如,以数据库记录的形式)。这些能力似乎对于人类语言(如递归句子结构)以及随着时间的变化而对个体和对象的了解至关重要(Marcus,2001)。【《代数思维》的第5章提供了一些示例,这些示例在消除连接主义模型的范围之外,其中许多示例依赖于实体随着时间的推移而存在。)这种机制非常强大。世界上所有的Web浏览器,世界上所有的操作系统,世界上所有的应用程序等都建立在它们之上。 (具有讽刺意味的是,几乎在世界上所有神经网络的规范和执行中都使用了相同的工具)。】
§
然而,在历史上,主流的深度学习在很大程度上试图摆脱符号操纵机制,而这种机制往往是有意回避的,这是为什么神经网络提供了一种替代经典范式的号召的一部分。鲁梅尔哈特和麦克莱兰(1986,#39979;)在著名的PDP书籍中,将符号操纵视为一种边缘现象,而不是人类计算的本质。2015年,辛顿将符号比作“发光的以太”,认为将符号逻辑作为人工智能的一个组成部分的追求是,
认为光波只能通过在发光的以太中造成干扰而在太空中传播的信念,这是不正确的……与科学家……被令人信服的但不正确的类比误导了,他们只知道他们知道具有所需特性的系统。
令人惊讶的是,在神经网络上的大量工作中也缺少个人的数据库式记录之类的想法,而仅在很小的研究中发现了诸如层次结构化句子之类的复杂结构化表示形式,而这两者的规范输入和输出是简单的矢量或二维位图,而巧妙地避免了针对个人的分层数据结构和记录。(DeepMind有趣的新MEMO架构(Banino等人,2020年)几乎代表了一个记录数据库。)
并非一定要这样。例如,原则上,人们可以尝试构建与符号操纵兼容的神经网络采用的术语中的“实现连接主义”,也可以尝试建立与之兼容的神经网络。无需依靠符号操纵原理(“消除联系主义”)或两者之间的某种混合,就可以进行操作。到目前为止,绝大多数工作都是消除主义的,但这种优势反映了社会学事实,而不是逻辑上的必要性。
我预计,几年内,许多人会想,为什么这么长时间以来,深度学习在很大程度上没有使用符号操纵这一极具价值的工具;实际上,人类所有伟大的工程成就都依赖于某种符号推理,人类在日常认知中利用它们的证据是巨大的。事实上,正如我将在下面讨论的,随着一种新的、更广泛的实用主义的暗示,事情终于开始改变了,我希望这种实用主义能够克服先前的教条。
本文的第一个主要主张是:要建立一种强大的,知识驱动的AI方法,我们必须在工具包中使用符号处理机制。太多有用的知识是抽象的,如果没有表示和操纵抽象的工具就无法做到,并且迄今为止,我们知道的唯一可以可靠地操纵这种抽象知识的机器就是符号操纵的设备。
遗憾的是,就变量本身而言,运算的手段对学习没有任何帮助。【归纳逻辑编程(Cropper,Morel和Muggleton,2019年)是一种纯粹基于规则的学习方法,值得一些考虑,尽管不在本文的讨论范围之内。】
正是从那里,混合架构的基本需求,结合符号操作和其他技术,如深度学习,最根本的东西出现了。深度学习提高了学习的门槛,特别是在大型数据集上,符号操作为表示和操作抽象设置标准。很明显,我们需要把两者(或类似的东西【虽然我很有信心,强大的智能将依赖于某种混合,将符号运算与机器学习机制相结合,但目前尚不清楚深度学习(如目前实践的)是否会在其作为主导机器学习机制的角色中发挥最后的作用,或者这种角色是否会在某种继承者身上发挥,e、例如,在数据和能源使用方面更易处理或更高效。诸如统计关系学习(Raedt,Kersting,Natarajan,&Poole,2016)和概率规划(Bingham et al.,2019)等受到较少关注的方法非常值得考虑;有关概述,请参见van den Broeck(van den Broeck,2019)。】)结合起来。
2.1.2混合动力通常是有效的
混合动力并不是什么新鲜事物:Pinker和我在三年前(Marcus等,1992)提出,关于儿童如何学习英语过去时的最好解释是混合动力:一条规则(添加到动词词干)形成规则动词的过去式,以及类似神经网络的系统来获取和检索不规则动词。长期以来,明显需要将符号知识与感知知识相结合(例如,人们希望能够通过将对马的外观的感知知识与将斑马比作有条纹的马相类似的语言定义相结合来识别斑马【现有的零射击学习文献试图整合各种形式的多模态知识,但据我所知,目前没有一个系统能够利用字典定义中的精确信息。】)。
像Ron Sun(Sun,1996)这样的计算机科学家在整个1990年代都倡导混合模型。Shavlik(Shavlik,1994)表明,有可能将(有限的)逻辑子集转换为神经网络。D’AvilaGarcez,Lamb和Gabbay(D’Avila Garcez,Lamb和Gabbay,2009年)是有关神经符号方法的重要早期工作。
坏消息是这些早期的混合方法从来没有受到太大的关注。当时的结果并不令人信服(可能部分是因为在TPU之前的日子里,神经网络本身的能力不足)。而且神经网络社区经常不屑一顾混合动力(以及涉及符号操纵的任何事物)。直到最近,混合符号在历史上一直被困在符号方法和神经方法之间的交火中。
好消息是,符号操纵世界和深度学习领域之间的早就应该融化了。例如,Yoshua Bengio在我们2019年12月的辩论中谈到了合并可以按名称传递变量的技术,这是一些早期计算机语言中使用的标准符号操作技术。越来越多的努力正在积极尝试将符号和神经网络更紧密地构建在一起,有时出于实际需要,有时出于研究工作以开发新方法。
世界上一些最庞大、最活跃的商业人工智能系统,比如谷歌搜索,实际上是混合了符号操作和深度学习的混合体。虽然Google搜索并不是我们心目中强大的人工智能,但它是一个高效的人工智能信息检索系统,能够以高精度、大容量的方式工作。它的设计者以高度数据驱动的方式对其进行了广泛的优化,目前(根据多种来源)通过混合经典的、符号操作的人工智能技术(例如,表示和查询谷歌知识图的工具,它使用经典的符号图结构表示知识,这些符号图结构使用神经网络社区的工具(例如,BERT和RankBrain)。谷歌做了大量的实证实验,看看什么在大范围内运作良好,而事实上,即使在深度学习的时代,他们仍然使用谷歌知识图,这既说明了符号的价值,也说明了混合动力车的价值。(不幸的是,我知道没有详细的公开讨论各个组成部分的相对优势和劣势。)
OpenAI的Rubik求解器(OpenAI等人,2019)(尽管它并未如此推销)是用于解决Rubik立方体的认知方面的符号算法与针对手动操作方面的深度强化学习的混合体。
Mao等人(Mao,Gan,Kohli,Tenenbaum,&Wu,2019)最近提出了一种用于视觉问答的混合神经网络符号系统,称为NS-CL(神经符号概念学习者的缩写),该系统超过了他们研究的深度学习方案。Janner等人的相关工作(Janner等人,2018年)。通过对单个对象的显式记录进行深度学习,以便做出预测和基于物理的计划,远远超过可比的纯黑盒深度学习方法。Evans和Grefenstette(Evans和Grefenstette,2017)展示了混合模型如何更好地捕捉各种学习挑战,例如挑战multlayer感知机的游戏fizzbuzz。Smolensky和Schmidhuber等团队将BERT与张量积(Smolensky et al.,2016)相结合,形成了一个表示符号变量及其绑定的正式系统(Schlag et al.,2019),创建了一个称为TP Transformer的新系统,从而在一个数学问题集上取得了更好的结果。
神经符号模型的基础工作是(D'Avila Garcez,Lamb,&Gabbay,2009),它检验了符号系统和神经网络之间的映射,并显示了传统神经网络中可以表示的知识种类的重要限制,并从表征和推理能力的角度论证了符号和神经网络在构建混合系统中的价值。在一级近似下,传统的神经网络可以被认为是命题逻辑的引擎,并且缺乏表示量化语句的好方法,就像在谓词演算中使用诸如every和some之类的量词一样。逻辑张量网络(Serafini&Garcez,2016)旨在在深度张量神经网络中实现形式逻辑。
统计关系学习(Raedtet al.,2016)代表了另一种有趣的方法,旨在将逻辑抽象和关系与概率和统计结合起来,正如Vergari et al.最近关于概率电路的工作一样(Vergari,Di Mauro,&Vanden Broek,2019)。Domingo的Markov逻辑网络试图将符号操作与机器学习的优势结合起来(Richardson&Domingo,2006)。Uber的Pyro(Bingham等人,2019年)
Arabshahi等人(Arabshahi,Lu,Singh,&Anandkumar,2019)展示了如何通过用作堆栈的外部内存来扩充树LSTM。Fawzi等人(Fawzi,Malinowski,Fawzi,&Fawzi,2019)最近提出了一个用于搜索多项式不等式证明的混合系统。Minervini等人(Minervini、Bošnjak、Rocktäschel、Riedel和Grefenstette,2019)最近提出了一种混合神经符号推理系统,称为贪婪神经定理证明器(GNTP),可用于大规模数据库;Gupta等人(Gupta、Lin、Roth、Singh和Gardner,2019)也在推理方面取得了进展。艾伦人工智能研究所(Allen Institute for AI)的亚里士多德(ARISTO)是一个复杂的多部分混合系统,在八年级科学考试中显著优于其他系统(Clark et al.,2019)。Battaglia已经发表了许多关于物理推理系统的有趣论文,这些系统集成了符号图和深度学习(例如,Cranmer,Xu,Battaglia,&Ho,2019)
所有这些只是一个快速发展领域的几个例子。现在阻碍胜利者还为时过早,但要构建将符号方法的优势与机器学习的见解相结合的体系结构,还有很多第一步,以便开发更好的技术,从大型、通常是嘈杂的数据集中提取和概括抽象知识。
2.1.3对混合模型和符号操纵的普遍反对意见
尽管人们对研究混合模型的兴趣日益浓厚,并且有多种考虑,但是在机器学习社区的某些地方,人们对符号操纵的厌恶情绪日益高涨。如前所述,例如,杰弗里·欣顿(Geoffrey Hinton)认为,欧洲对混合动力汽车的投资将是“巨大的错误”,并将混合动力汽车的研究比作电动汽车时代使用过时的汽油发动机。
但是据我所知,Hinton近年来没有写过多篇有关他为何反对部分象征性混合模型的文章。
以下是我从其他人那里听到的一些常见异议,并对每个异议都做出了简短回应:
•符号在生物学上不合理。对此异议至少存在四个问题(关于相似的观点,另请参见Gallistel和King(Gallistel&King,2010年))。
首先,仅仅因为我们还没有确定支持符号操纵的神经机制并不意味着我们永远不会。已经确定了一些有希望的可能的神经基质(Frankland&Greene JD,2019;Marcus,Marblestone,&Dean,2014;Legenstein,Papadimitriou,Vempala,&Maass,2016),其他文献指出了理论上合理的神经基质(Marcus,2001)。没有令人信服的证据表明,没有这样的机制根本不可能存在于大脑的湿部。今年我们已经看到树突中的一个小隔间可以计算XOR(Gidon etal.,2020),这增加了单个神经元可能比通常假设的复杂得多的可能性。例如,对符号操作至关重要的变量值的存储和检索可能在单个神经元内起作用(Gallistel&King,2010)。
第二,大量心理学证据(见上文第2.1.1节)支持这样一种观点,即符号操作在大脑中是具体化的,比如婴儿将新的抽象模式扩展到新项目的能力,成年人将抽象的语言模式概括为他们没有直接数据的非本族语的能力,蜜蜂将太阳方位角函数概括为他们没有直接观察到的光照条件的能力。人类还可以学习在外部表示的符号上应用形式逻辑,并编程和调试符号表示的计算机程序,所有这些都表明,至少在某些配置中,神经软件确实可以(在某种程度上,部分受内存限制)操纵符号。我们可以理解语言本质上是无限多样的,从无数的句子中推断出无数的意义。在整个认知过程中,作为变量运算特征的自由概括是普遍存在的。
第三,现有的神经认知证据的缺乏几乎没有告诉我们什么。我们目前还没有详细了解加里·卡斯帕罗夫水平的象棋是如何在大脑中实现的,但这并不意味着加里·卡斯帕罗夫的象棋在某种程度上依赖于非神经机制。
最后,即使结果表明大脑没有使用符号操纵机制,对于人工智能为什么不能使用这些机制,也没有原则性的论据。人类没有浮点运算芯片,但这并不意味着他们在人工智能中应该是多余的。人类显然有写一次的机制,可以立即检索短期记忆,这是某种形式变量绑定的前提,但我们不知道相关机制是什么。这并不意味着我们不应该在人工智能中使用这种机制。
•过去,符号系统/混合系统运行不佳。我经常听到这种说法,但是在我看来,这是一个奇怪的说法。将混合模型描述为明显无效或过时的混合体,这并不是现实的准确描述,而实际上已经对其进行了积极有效的研究,如2.1.2.10节中所述。
•符号操纵/混合系统无法缩放。尽管这里有一些真正的问题需要解决,而且必须花大量的精力来约束符号搜索,以便能够实时处理复杂的问题,Google说
知识图似乎至少是这一异议的部分反例,最近在软件和硬件验证方面取得的大规模成功也是如此。Minervini等人(Minervini等人,2019年)和Yang等人(Yang,Yang,&Cohen,2017年)等论文在构建端到端可区分的混合神经符号系统方面取得了实际进展,这些系统在规模上起作用。与此同时。没有正式的证据证明不可能充分缩放,给予适当的启发,存在。
在过去的三十年中,我看到了很多对符号的偏见,但是我还没有看到对它们的有说服力的论据。
2.1.4确定给定系统是否为混合系统并不总是一件容易的事
一种常见的(虽然不是普遍的)对符号的偏见产生了一个特殊的社会学事实:研究人员偶尔会建立包含符号操纵装置的系统,却不承认(甚至不考虑事实)他们已经这样做了;我在马库斯,2001中给出了一些具体的例子。例如,如上所述,OpenAI Rubik的立方体解算器(OpenAIet al.,2019)包含了一个被称为Kociemba算法的符号组件,但只有非常细心和成熟的读者才会认识到这一点。“混合”和“象征”这两个词从未被提及。而“神经”这个词出现了13次。
因为你不能总是通过粗略的检查来告诉我们一个给定的系统是如何工作的,所以从逻辑上讲,有可能无意中构建一台有效地执行符号操作的机器,而没有意识到这样做。事实上,一个网络设计师可能会无意中发现一些与符号FPGA同构的东西,而从来没有意识到它。
正如本吉奥在我们最近的辩论后对话中所建议的那样,深度学习系统可以为符号操纵提供一个真正的替代方案,这是可以想象的:
我敢打赌,深度学习变体可以实现人类可能实际执行的类似符号的计算形式,但使用的基底与GOFAI非常不同,限制与人类经历的类似(例如,只有很少的递归级别),在GOFAI推理中,除了能够学习和处理不确定性之外,还避免了与搜索问题相关的主要效率问题。
我们不能想当然地认为任何给定的神经网络都提供了一种替代方法。
评估一个系统是执行“类似符号的计算”的替代方案,还是使用真正的符号操纵操作进行计算的唯一方法是探索映射:考虑该体系结构及其组件是否映射到符号操纵的组件(在某种意义上,化学映射到物理学)。Marr(Marr,1982)的计算水平清楚地表明了这一点:任何给定的计算都可以以多种方式实现,并且不是每个实现都是透明的。化学映射到物理上,但这并不意味着映射很容易被发现。“正确”的神经网络可能映射到符号操纵机器上,也可能映射到符号操纵机器上;真相可能很难辨别。
我坚信,任何健壮的系统都会有某种机制来绑定变量,并在绑定后对这些变量执行操作。但我们看不出来。
§
为了避免这听起来很奇怪,回想一下映射对于理解神经科学以及它与计算的关系同样重要。无论我们的大脑中实现了什么样的计算,都是在没有任何有意识的决策的情况下实现的;它们是进化的。其中很少有透明的。这是神经科学家和那些致力于以大脑为灵感的人工智能方法的人工智能研究人员的工作,他们对大脑进行逆向工程,以找出存在哪些计算。任何驱动大脑的东西都可能会或不会映射到我们目前的理论。当我们评估大脑如何工作的一些理论时,我们正在评估大脑的机制是否符合这个理论。有些理论将包含与大脑中发生的实际过程同构的结构,而另一些则不会。Knudsen和Konishi(Knudsen和Konishi,1979)对谷仓猫头鹰声音定位的仔细研究是一个很好的例子,说明了一个神经回路最终是如何被破译并映射到基础计算上的;很少有研究项目能与之相媲美。
人工智能中也出现了类似的问题:当一个系统工作时,理解是什么驱动了它的性能是有价值的,但往往是不重要的。
一个系统将所有的经验存储在一个单独的内存中,而不是可以检索和计算出来的,可以用“神经”的术语来描述,但是它的组件可以识别地起到维护变量、绑定、实例和变量操作(如检索)的作用。
如果我们通过某种搜索过程(无论是随机的、试错的、进化的、AutoML的或其他方法)来创建适当的综合系统,我们将解决部分工程问题,但不一定科学地理解是什么使这些模型起作用。后者是逆向工程的工作,是发现和拒绝可能的映射,就像神经科学一样。
如果完美的神经网络降临到我们身上,我们可能会通过广泛的测试发现它是有效的;要理解它是如何工作的,还需要另一个科学发现阶段。如果我们发现一些成功的神经网络,结果发现它的组成部分恰好完美地映射到符号操作上,那么这将不仅是神经网络的胜利,而且也是符号操作的胜利——不管系统设计者的意图是什么。相应地,如果没有一个系统的组成部分映射到符号操纵上,这将是符号操纵的失败。
任何一个通情达理的人都会认识到,到目前为止,理解人类大脑是如何工作的是多么的困难,而当神经网络变得越来越复杂时,同样的道理也会变成现实。人类大脑本身就是一个令人印象深刻的神经网络的例子,它有效地(通过进化)降临到我们身上;它似乎工作得很好,但我们不知道为什么【寻求实现细节和算法描述之间的映射(如果它们存在的话)也可能具有实际价值,因为,例如,一旦发现了那些映射,一些低级的神经网络类计算可能会更有效地在纯符号级别上进行计算。相反,一些被称为神经网络的模型,如Lample和Charton最近关于符号集成的研究(Lample和Charton,2019),经过仔细检查,结果发现有严重的局限性,并且严重依赖于符号处理器(Davis,2019)。对符号和神经成分如何协同工作有一个清晰的、有原则的理解可能是非常有价值的。】
2.1.5总结
符号操作,特别是对变量的操作机制,提供了一个自然但不完整的解决方案,来解决在训练机制之外进行外推的挑战:用对变量的操作来表示一个算法,并且它固有地被定义为扩展到某类的所有实例。它还提供了一个清晰的基础来表示结构化的表示(例如在生成语言学中被视为基础的树结构)和记录个人及其行为属性。
它所缺乏的是一个令人满意的学习框架。混合可以是两个世界的最佳结合的一种方式:从大规模数据集学习的能力,如深度学习所示,以及表示抽象表示的能力,这些抽象表示是世界上所有计算机编程语言的语法和语义货币。我猜想它们是安全获得可靠情报的先决条件。
用于研究混合模型的资源远远少于用于避免符号操纵的“纯”深度学习系统的资源,但第2.1.2节中回顾的来自广泛研究实验室的越来越多的工作,更不用说谷歌搜索的成功,所有这些都表明了对混合体系结构进行更深入研究的价值。
遗憾的是,我们还没有走出困境。将强大的数据驱动学习技术与符号操作的表示和计算资源相结合的混合模型可能是鲁棒智能所必需的,但它们肯定是不够的。接下来我将描述三个进一步的研究挑战。
2.2大规模的、抽象的、有因果关系的知识
符号操作允许抽象知识的表示,但是积累和表示抽象知识的经典方法,一个称为知识表示的领域,一直是残酷的艰苦工作,远远不能令人满意。在人工智能的历史上,Doug Lenat于1984年发起的以机器可解释的形式创造常识知识的最大努力是被称为CYC的系统(Lenat等人,1985)。它需要数千人-年的时间,几乎是巨大的努力,以精确的逻辑形式捕捉心理学、政治学、经济学、生物学和许多其他领域的事实。
到目前为止,回报并不令人信服。关于CYC的报道相对较少(这使得评估变得很有挑战性,尽管你可以看到这个有趣的黑客新闻线索),商业应用程序看起来很温和,而不是势不可挡。大多数人,如果他们了解CYC的话,都认为它是一种失败,而目前很少有研究人员广泛使用它。似乎很少有人愿意尝试建立具有可比广度的竞争体系。(像googleknowledgegraph、Freebase和YAGO这样的大型数据库主要关注事实,而不是常识。)
考虑到CYC需要付出的努力,以及它对整个领域的影响是多么的小,很难不被GPT-2这样的Transformers所激发。当他们工作得很好时,他们看起来几乎是神奇的,好像他们自动地、几乎毫不费力地吸收了世界上大量的常识知识。从某种程度上说,Transformers给人的感觉是,它将自己所吸收的任何知识与对人类语言看似复杂的理解无缝地结合在一起。
这对比鲜明。然而,知识表示社区几十年来一直在努力用精确的方式来描述容器及其内容之间的关系,而自然语言理解社区几十年来一直在努力进行语义分析,而GPT2这样的Transformers似乎是在不借助于语法的情况下解决了棘手的问题任何明确的知识工程(或语义分析)-无论如何。
例如,在GPT-2中没有知识工程规则,没有相对于容器的液体规格,也没有关于水甚至是液体的规格。在前面的示例中
如果打破玻璃瓶装的水,装满的水可能会流出,会发出飞溅的声音。
从概念H20(化学中水的表达)到单词water都没有映射,也没有动词语义的任何显式表示形式,例如中断和流动。
再举一个例子,GPT-2似乎也对火进行了编码:
点火的一个好方法是使用打火机。
点燃火的一个好方法是使用火柴
与Lenat数十年的以机器可解释的形式对人类知识进行手工编码的项目相比,乍看之下,这既代表了一夜的成功,也代表了惊人的劳动力节省。
§
问题在于GPT-2的解决方案只是对知识的近似,不能替代知识本身。特别是,它所获得的是近似的统计数据,即单词在大型语料库中是如何共存的,而不是概念本身的清晰表述。换句话说,它是单词用法的模型,而不是思想的模型,前者是后者的近似模型。
这样的近似值就像是一个复杂的三维世界的阴影。通过使用与瓶子相关的单词,瓶子和打破的概念在语料库上投射了阴影,这些阴影编码了人类互动的一个子集。Transformers分析单词留下的阴影,就像柏拉图的洞穴寓言中的囚徒一样。麻烦的是,对阴影的分析(即在这些语料库中如何使用单词的共现统计分析)并不一定能揭示瓶的真正含义或破碎含义。
事实是,GPT-2几乎不了解与它所分析的单词相关的概念的相关性(无关紧要)。考虑一下发生了什么情况,例如,按照弗兰克·基尔(Frank Keil,1992)的经典实验,如果您将感知功能与更深的概念理解相对立:
如果您在浣熊上穿上服装使它看起来像臭鼬,那将是臭鼬。
如果将飞机喷漆成看起来像龙,那将是龙。
显然,仅了解某个概念中如何使用单词的某些统计属性不足以理解基础概念的本质,例如使飞机变成飞机而不是龙的原因(反之亦然)。这份最近匿名的,正在审查的手稿也提出了类似的观点。
我想起了像Nigel Richards这样的Scrabble冠军,他们在不懂法语的情况下赢得了法国Scrabble™比赛;各个单词仅用作游戏代币,而与它们的含义无关。本质上,GPT-2可以预测单词序列作为游戏代币的属性,而不会暗示所引用的基本概念。
它做得如此之好,以至于有时会引起“伊丽莎效应”,在这种效应中,幼稚的人对机器的归属要比对机器的实际归属更多,但是除了表面的概念理解之外,别无所求。
如果我们继续探究起火的例子,我们会得到类似的结果
点火的一个好方法是用干燥的棉球遮盖保险丝!
点燃火的一个好方法是使用一品脱大小的炉子
“火”,“融合”,“光”等词都是相互关联的;GPT-2能够做到这一点,但这还不足以让GPT-2引发对火的性质的概念性理解;结果参差不齐。换句话说,就像朱迪亚·珀尔(Judea Pearl)所说的那样,这种异常行为是您试图通过近似统计单词用法的统计曲线来诱导世界如何运转时得到的结果,而不是归纳出对世界的更抽象,因果的理解。【在深度学习社区的某些部分中,有一种积极的努力试图整合因果方法;我的猜测是,如果不在因果知识的表示和操作上增加一些固有的约束,这就不可能成功,很可能导致某种混合网络。】有时行得通,有时却行不通。
一个人不可能用如此缺乏可靠性保证的零件来设计一个健壮的系统。
§
用如此低的可靠性试图用零件构建系统的一个问题是,下游推理将不可避免地受到影响。拥有知识的全部目的是将其用于行动,解释和决策中。如果您不知道会引起火灾的原因,或者瓶子破裂时会发生什么,则很难推断周围的情况。同样,您不能可靠地进行计划。想象一下,一个家用机器人无法点燃顽固的炉灶,用干燥的棉球花了几个小时,一个又一个地覆盖了一个保险丝。
语言理解也不可避免地会受到影响,因为我们经常根据话语的真实性和语境来消除话语的歧义(Tanenhaus,Spivey-Knowlton,Eberhard和Sedivy,1995)。像GPT这样的系统具有一定程度的词语用法语境,但缺乏对认知语境和合理性的可靠表示。
在充满了如此浅薄的概念理解的系统中,可解释性和可解释性也将变得难以捉摸。将棉球和打火机凝结成同等有效的点火方式的系统可能没有内部一致性来满足可解释性的需求。
如果对基本概念没有连贯的因果理解,则可能没有办法在复杂的实际环境中设计鲁棒性。Pearl是对的:如果我们的系统仅依赖于曲线拟合和统计近似,则它们的推论必然会很肤浅。
这使我想到了本论文的第二个主要主张:归结,表示和操纵通常具有因果关系的结构化,抽象知识的大型数据库的系统方法是强大情报的先决条件。
2.2.1强大的人工智能将需要什么样的知识?
以下是一些基本注意事项:
•大部分(但重要但并非全部)知识(请参阅下文)都可以学习。没有人生来就知道打火机会着火,干燥的棉球不会起火,玻璃瓶破裂时可能会做什么。可以想象,可以像CYC那样,将这些知识硬连接到AI系统中,对每个事实进行手工硬连接,但是现代机器学习爱好者显然不愿意这样做。而且由于总是有新知识要收集,因此有必要学习新的抽象机制(通常是因果知识)。
••一个健壮的系统可能利用的知识中,有相当一部分是象征性地表现出来的外部文化知识。例如,维基百科的绝大多数内容都是口头表达的,一个强大的情报机构应该能够利用这种知识。(目前的深度学习系统只能在非常有限的范围内做到这一点。)大部分知识都是根据变量之间的量化关系进行有效编码的(例如,对于所有x、y和z,x、y和z都是人,如果有一个人y是x的父母和z的孩子,那么x就是z的孙子;对于所有x,x是一个物种,x物种的生物体产生的后代也是x物种的后代,等等)。
•健壮的系统需要的知识中有很大一部分可能是抽象的。当前的系统擅长表示特定事实,例如BORN(ABRAHAMLINCOLN,KENTUCKY)和CAPITAL(KENTUCKY,FRANKFORT),但缺少表示和有效处理信息的方式,例如如果瓶子坏了,其他条件相等时,瓶子中的内容物可以逃逸。
•规则和例外必须并存。规则动词(walk-walked)与不规则动词(sing-sang)共存。不会飞的企鹅和其他很多会飞的鸟类共存。机器必须能够以某种方式来表示知识,就像语言学家所说的泛型:知识通常是真实的,但也有例外(飞机会飞,但我们认识到,一架特定的飞机可能会被停飞),甚至不必在统计上准确地反映病例(蚊子携带疟疾是重要的知识,但只有一小部分蚊子实际携带疟疾)。只能获取规则而不能获取例外的系统(例如Evans和Grefenstette(Evans和Grefenstette,2017))是构建能够获取抽象知识但还不够的系统的一个有趣步骤。
•一个健壮的系统可能是因果关系,并支持反事实的知识的一个重要部分。例如,封闭的人并不知道国家有首都,他们知道这些首都在政治上是由人民的行动决定的,而且这些决定有时会被改变。奥尔巴尼是纽约州目前的首府,但如果首府(事实上)被烧毁,我们认识到该州可能会选择一个新的首府。孩子们知道,当玻璃瓶落在坚硬的地板上时,那些瓶子可能会碎。
•尽管在网上搜集诸如首都和出生地等事实知识相对容易,但我们掌握的许多抽象知识很难通过网络搜集;例如,很少有人会写关于破碎瓶子及其内容的文章。大多数情况下,正如列纳特曾经指出的,作家不会写下常识,因为他们的读者已经知道了。(盲目拉网也有其他问题;例如,历史偏见,比如医生是男性,往往会被天真的拉网系统自动延续下去。)
•相关知识的范围必须非常广泛。例如,理解一部小说可能需要技术、政治实体、金钱、天气、人际交往、礼仪、性、暴力、贪婪等方面的知识。例如,约翰·格里沙姆(johngrisham)的第一部畅销小说《公司》(TheFirm)中的关键情节转折就建立在对影印机能做什么、能做多快的理解上,与对人类动机和时间推理的深刻理解并列。
•很难将知识付诸实践。拥有一个庞大的知识数据库是一回事,其中包括有关复印机及其运行速度的事实,另一种方法是将这些知识(在大量其他不太相关的信息库中)整合到关键任务的时间推理中,即英雄律师在陷入秘密但高尚的信息收集行为之前所处的狭窄时间窗口。以一种有效的方式将抽象的知识与现实世界中的具体情况联系起来,本质上是一个尚未解决的问题。
••人类知识的一些小而重要的子集可能是天生的;健壮的人工智能也应该从一些重要的先验知识开始。在当代的ML中,人们常常强烈地希望将知识和天赋最小化;正如下面第2.2.3节所讨论的,我认为这是一个错误。
2.2.2案例研究:容器
让我们更详细地考虑一个案例研究-一个事实(在通常情况下),带盖的茶壶中的水只能从壶嘴出来。
正如读者现在所期望的那样,GPT-2有时会做到这一点。

原则上,我们也许可以通过众包获得这一特定事实,但由于人们很少陈述如此明显的事实,而且更不经常精确地陈述,我们不应该指望它。尽管我们可能需要在我们的数据库中有这样一个事实,例如,如果我们正在构建人工智能来支持一个仿人的老年人机器人的决策,我们可能不会提前预料到这种需要。
如果我们能从更一般的知识中得出这样的事实就更好了,例如,如果我们遇到一个外表陌生的茶壶,我们就会知道它是什么,以及如何与它互动。
Ernest Davis、NoahFrazier Logue和我提出了一个框架(Davis、Marcus和Frazier Logue,2017),可以帮助解决这类挑战:一大套独立动机的逻辑公理,这些公理不是茶壶特有的,都是通用的,主要由大多数普通人在思考后认识到的抽象组成是真的,从中可以对容器做出正确的推断。
总的来说,公理所处的框架是相当普遍的:关于时间、空间、操纵、历史、行动等的公理。这些公理包括如下陈述(这里有一些稍微简化的解释):
•物理世界由一系列物体组成,这些物体在时间和空间上移动。
•对象是不同的;也就是说,一个对象不能是另一个对象的一部分,也不能在空间上与另一个对象重叠。
•物体占据某个三维范围的区域;它不能是一维的曲线或二维曲面。
•特定数量的液体可以占据特定体积的任何区域。
•封闭容器是完全包裹内腔的一个物体或一组物体。
•直立开口容器是顶部开口的开口容器。
配备了此类知识的探索性机器人(以及将知识与感知模型和认知模型联系起来的其他机械)也许可以推断出带有几乎隐藏的壶嘴的形状异常的水壶的使用和功能:

理查德·威廉姆斯·宾恩斯(Richard Williams Binns,1837-1903年)设计的茶壶,其右手下方带有隐藏式喷嘴。
经过一定的扩展,这样一个系统可以提供一个系统的基础,这个系统可以推理出送纱器的用途,即使人们以前从未见过送纱器;最终,人们希望,这些基础可以作为机器人系统的一个组成部分,可以在一个动作过程中应用这些知识,比如编织。

喂纱器。纱线球停留在较大的开口中,并保持在那里,即使将单股纱线拉出也是如此。
并推断出新的供料器(或与用户进行交流),甚至是完全不同的供料器:

这种情况在目前的神经网络方法中并没有自然地表现出来。首先,这样做可能需要一个对象的先验概念,而这个对象本身在大多数当前的神经网络中并不容易表示。然而,这些知识需要成为健壮的人工智能的核心部分,我们必须拥有获取这些知识的策略和能够获取、表示和操作这些知识的体系结构——其中一些在本质上似乎是象征性的。
原则上,也许我们提出的公理中有一小部分是天生的,其他人是学来的,尽管到目前为止我还不知道有哪个系统能够学习这类公理。(这里再次强调,具有嵌入式知识的神经符号系统可能会有所帮助。)
重要的是,这组框架本身会聚集到一组相当容易识别的域中,例如关于空间、时间和因果关系的知识,如这里所示:
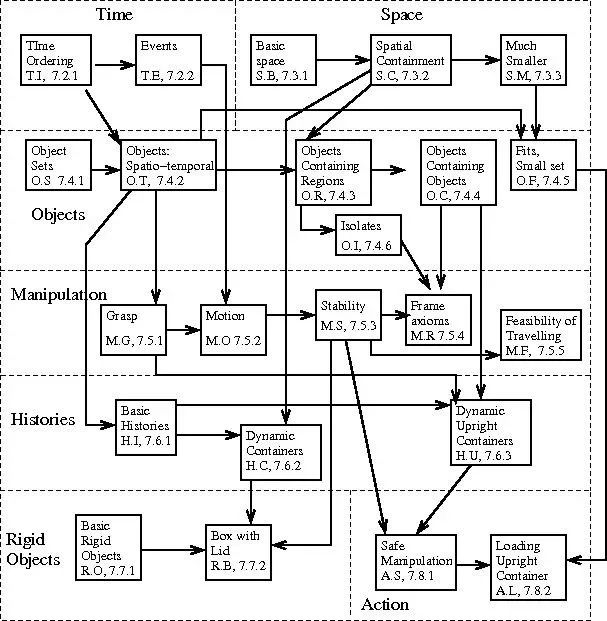
容器知识框架,摘自(Davis et al。,2017)
2.2.3固有的知识框架
把我们带到本土主义。虽然没有人可能认为所有的抽象知识都是与生俱来的,但其中一些可能是与生俱来的,而让某些知识与生俱来的论点最终非常简单:你一开始知道的越多,其他知识就越容易学习;如果你能缩小自己的范围,你就可以限制你试图寻找的假设空间寻找。
LeCun关于卷积的开创性工作(LeCun,1989)事实上是对这一点的一个有力的实证证明,表明在数字识别任务中学习,在一个预连线的层次结构配备了平移不变特征检测器(使用卷积)的系统中,准确度更好,相对于一个更简单的体系结构来说。唯一的先天优势,卷积,已经被证明是非常有价值的。
然而(许多,并非所有)机器学习研究者反对在他们的系统中加入更多的固有约束,画出一条看似任意的线,这样网络参数(有多少层,损失函数是什么,使用什么输入节点编码方案等等)对于先天性来说是公平的游戏,但大多数其他事情通常是公平的预计将被学习(马库斯,2020年)。有些人甚至认为这是一个值得骄傲的地方;正如一位研究人员在一封电子邮件中告诉我的那样,“如果你主要对理解‘学习’感兴趣,那自然会导致你贬低‘手工编码’。”
我在2019年12月与Yoshua Bengio的辩论同样具有启发性。他说,预先指定卷积是可以接受的,因为它只需要“三行代码”,但担心将先验知识(先天/先验知识的位)的集合远远扩展到卷积之外,特别是如果这些先验知识需要指定多于几位的信息
正如我在那里向他表达的那样,我不会太担心那些零碎的东西。超过90%的基因组在大脑发育过程中表达(Miller et al.,2014;Bakkenet al.,2016),其中相当数量的基因在特定区域选择性表达,从而产生详细的初始结构。有许多机制可以通过使用少量的基因来指定复杂的结构;本质上,基因组是以半自主的方式构建结构的压缩方式(Marcus,2004);没有理由认为生物大脑仅限于几个“小”先验。凯文·米切尔最近在辩论后的一次跟进中很好地总结了形势。
的确,基因组中没有足够的信息来说明神经发育的确切结果,即大脑中每个神经元的数量、位置和连通性。基因组只编码一组无意识的生化规则,当这些规则在发育中的胚胎的动态自组织系统中发挥作用时,会导致在自然选择定义的操作参数范围内的结果。但这些操作参数有很大的空间,包括我们认为是先天的各种因素。在许多物种中有大量证据表明,根据基因组中的指令,许多不同的先天前驱确实预先连接到神经系统中。
如果基因组有足够的先天先兆的空间,那么现代人工智能系统可能还有更大的空间;我们生活在一个计算机内存以千兆字节和兆字节来衡量的时代,而不是以字节或千字节来衡量的时代。对于人工智能来说,真正的问题不应该是,我们的先验知识库有多小?但是什么样的先验知识能最有效地为学习创造条件呢?就其本身而言,最小化比特数并不是目标。
§
如果有三个关于先天性的建议反复出现,它们就是时间、空间和因果关系的框架。
例如,康德强调从时间、空间和因果关系的“流形”开始的价值。斯皮尔克长期以来一直认为,一些基本的,核心的知识,对象,集合和地点可能是先决条件,以获得其他知识。正如她所说(斯佩尔克,1994年),
如果儿童天生具有感知物体、人、场景和地点的能力,那么他们可能会利用自己的感知经验来了解这些实体的属性和行为……然而,如果他们不能在他们的环境中挑出那些实体。儿童如何才能了解某个领域中的实体,这还很不清楚.
戴维斯和我在我们对容器的分析(见上图(Davis等人,2017))和我们最近的书(Marcus&Davis,2019)中都同样强调了先前的空间,时间和因果关系框架的价值。 ; 多年来,许多其他发展心理学家也指出了类似的方向(Landau,Gleitman和Landau,2009;Carey,2009;Leslie,1982;Mandler,1992)。
正如斯佩尔克(Spelke)和康德(Kant)都强调的那样,一旦您了解了物体及其在时间中的传播方式,就可以了。您可以开始填写其属性,并开始获得环游世界所需的知识。
残酷的事实是,相反的方法(从近乎空白的板块开始,然后在海量数据集上对其进行训练)到目前为止还没有成功(Marcus 2020)。一些大型公司(例如Google,Facebook,Microsoft等)对由大数据集训练的相对空白的模型进行了全面的测试,并提供了几乎无限的时间,金钱,计算人员和研究人员,但他们仍然无法可靠地推理出时间,空间或因果关系。如果没有这样的能力,我们的系统将永远不会足够强大以应付现实世界的变化。
肯定是时候考虑一种更自然的方法了。
§
好消息是,尽管在深度学习社区中人们常常不赞成本土主义,但从历史上看,越来越多的迹象表明对``先验者''更加开放(例如Burgess等人,2019年; Rabinowitz等人,2018年) ; Maier等人,2017)。
当然,每个神经网络实际上都是先验的,其形式是先天(即预先建立,而不是通过相关系统学习)对特定层数,特定学习规则,特定连通性模式,特定表示方案的承诺(例如输入和输出节点代表什么),等等。但是,这些先验本质上很少是概念性的。
真正的问题可能是关于可以代表什么样的先验,以及我们所需要的先验是否可以自然地用我们已经拥有的工具来代表,或者我们是否需要新的工具来代表更广泛的先验。深度学习社区似乎可以将卷积(自然适合神经网络框架)用作先验,但是到目前为止,该社区对具有更复杂先验的模型的关注程度大大降低,例如关于对事物永恒性的先天认知【参见Marcus(2001),第5章中有关为什么估计对象的轨迹本身不足以进行讨论的讨论】,或用于理解随时间变化的事件的时间演算。
我们应该问的不是我能去掉的的最起码的内在结构是什么?而是我需要什么样的先验呢?以及我现有的体系结构能否有效地将它们合并?我们是否可以建立一个更丰富的具有深层学习基础的内在基础,或者在这个框架中可以方便地内在地表达的东西是否有限制?我们是否需要显式的符号操纵机制来表示其他类型的抽象,比如因果抽象?事实证明,深度学习擅长表达关于物体外观的知识,但不太擅长获取和表达关于物理世界如何运作的知识(Zhang,Wu,Zhang,Freeman&Tenenbaum,2016),关于人类如何相互作用,以及更普遍的因果关系。
其他方法,如概率规划,允许显式表示的符号约束,同时努力学习微妙的统计信息,值得认真考虑。
§
退一步说,人类对世界的绝大多数了解都是从中学到的:
事实上,船只倾向于漂浮而不是沉没
事实上,如果船只在水线以下形成洞,它们确实会下沉。
打火机比棉球更适合点火
破碎的瓶子会泄漏
一次又一次,几乎没完没了。无论我们拥有什么样的核心知识,都必须有大量的知识来补充。
认为普通人可能知道(或立即承认是真的)数百万或数千万这样的事实并非没有道理;其中绝大多数必须通过经验、明确的指示或其他方式来学习。重要的是,几乎所有这些知识都可以付诸实践,指导行动和决策(例如,如果我们发现船在水线以下有一个洞,我们会选择不上船)。
但重要的是,我们所学到的知识中有相当一部分是因果性和抽象性的,根据上一节的讨论,这可能需要使用某种混合体系结构。
同时,纯粹的预先连线永远不够,因为世界本身在不断变化;例如,总会有新的因果原理与新的技术联系在一起。如果有人介绍一个流行的新玩意儿叫花花公子™,我们很快就会知道虚拟机是做什么的,如何打开和关闭它,以及如何让它做自己的事情。正如Gopnik和Sobel(Gopnik和Sobel,2000)优雅地展示的那样,孩子们很自然地做到了这一点;我们需要能够做到这一点的机器。
但是我们可能不能也不应该仅仅从经验中学习我们所有的抽象和因果知识。当这么多的知识已经被编成法典的时候,这样做将是极其低效的;例如,为什么要让每个系统重新认识到,即使物体被遮挡,它们仍然存在于空间和时间中,而这是一个普遍的真理?此外,正如我们所看到的,例如在GPT-2的讨论中,从无到有的学习到目前为止是不可靠的。如果没有一些先验知识,例如生理和心理推理的基础知识,我们可以称之为常识的东西几乎都学不好。我们需要一些核心知识来指导剩下的学习。
妥协和创新的必要性再次显现出来。我们显然需要能够获得新的因果知识的系统(可能是神经符号的杂种),但为了获得这种知识,我们可能需要比我们迄今使用的更强大的先验知识。
因此,我的第三个主要主张是:我们不应该把每一个新的人工智能系统从零开始,当作一张白板,对世界知之甚少,而应该寻求建立从时间、空间和因果关系等领域的初始框架开始的学习系统,以加快学习速度并大量限制假设空间。
无论这些框架是用形式逻辑(la-Cyc)表示还是用其他方法表示,也许还没有发明出来,我强烈怀疑它们是朝着健壮智能方向取得任何重大进展的先决条件。再多的天赋也不能代替学习,但不专注的学习是不够的。这个游戏的名字是找到一组先天的先验知识,无论是小的还是大的,这将最有利于学习我们系统最终需要的巨大知识库。
尽管如此,光靠知识是不够的。这些知识必须用推理工具付诸实践,在认知模型的背景下,我接下来要谈到的两个主题。
2.3.推理
在一个著名的轶事,可能更好地在复述,但显然是基于一个核心的真相,传奇演员劳伦斯奥利弗是在现场与年轻的达斯汀霍夫曼,谁放弃了一些睡眠,以使他的角色可能会出现疲惫不堪。奥利弗对霍夫曼说:“亲爱的孩子,你看起来真糟糕。你为什么不试着演戏呢?这样容易多了。”
我对记忆和推理的看法是一样的。目前的人工智能方法主要是试图通过记忆(或至少是近似地记忆)整个世界的概率密度函数来应对世界的复杂性,代价是无法满足地需要越来越多的数据。考虑到世界的指数级复杂性,这一策略不太可能奏效。
推理提供了另一种选择;你不需要记住所有的东西,也不需要在你以前可能遇到的近邻之间进行插值,而是进行推理。你没有记住柏拉图、亚里士多德、欧里庇得斯和我们前面的其他数十亿人都是凡人的事实,而是学到了一个普遍的真理,所有的人都是凡人,并根据需要将这个普遍的真理应用到这个范畴的具体实例中。
正如我们所看到的,神经网络,如Transformers(至少像目前通常使用的那样,在端到端的方式中,与符号操作工具隔离)太不可靠,不适合合理的推理。它们可能在某些时候起作用,但不太可靠;只要有足够的知识可用,符号操纵至少提供了朝着正确方向前进的希望。
在经典模型中,推理引擎的最佳例子是CYC(相当于一个符号系统)能够在最佳情况下执行的那种推理。举个例子,CYC的创始人Doug Lenat(Lenat,2019,#3132},re Romeoand Juliet)最近的一次讨论,在这里用两个图抽象出来,提供了故事的概要,一些与故事相关的知识,一些常识知识,以及CYC推理的一个例子(复杂推理者和大规模知识的结合)在最佳情况下可以得出

图2罗密欧与朱丽叶,以及一些与故事相关的知识样本,例如故事中的特定时刻和特定时间点的知识;摘自Lenat 2019。正如后面所讨论的,中间和右边的面板反映了CYC对情节的认知模式的一部分。

图3相关常识知识样本,以及CYC得出的复杂推论;Lenat 2019
上图中间和右面板的详细程度——列出了时间点和在这些时间点上保持正确的陈述——是我将称之为丰富认知模型的一个例子。它是一个认知模型,因为它是一个复杂场景的内在升华,它的丰富之处在于它充满了关于特定主人公在特定时间点做什么、知道什么、打算什么和期望什么的微妙信息。
同样地,我们可以认为下图左半部分所示的常识知识相当丰富,因为它所编码的行为、后果和人类互动的信息错综复杂。其中一些知识可能被明确地表示出来(例如,饮用某种毒物的后果可能是立即死亡),一些可以想象的知识可能是从更一般的事实在网上衍生出来的。(例如,“如果一个人死了,他们就不必和任何人结婚”可能是从一个更普遍的观察中得出的,即义务往往只适用于活着的人。)无论哪种方式,拥有如此广泛的知识储备的回报来自于可以得出的推论的复杂程度(下图右侧),以及在他们的可解释性水平上,这两者与迄今为止通过深度学习产生的任何东西都处于完全不同的水平。
一些观察结果:
•如果不广泛使用结构化表示、变量操作和个人记录,这种方法是不可能的。
•这是一个最好的概念证明,表明拥有丰富的认知模型和丰富的生物学、心理理论等知识的潜在价值。
•然而,它在很大程度上依赖于知识工程师手工完成的大量前期工作,这些工程师已将《罗密欧与朱丽叶》手工翻译成形式逻辑;一个能够在可比水平上自动生成此类表示和推理的系统将是一个重大突破。
•推理本身不一定是通往强大人工智能的瓶颈;真正的瓶颈可能在于在现实世界推理的上下文中获得正确的信息。
当然,CYC远非完美。世界上有太少的东西是以充分的预先包装的形式提供给CYC的。CYC没有太多的自然语言前端,也没有远见;要让它变得合理,你需要把你的问题用逻辑的形式表示出来。由于很少有问题是以这种方式预先包装的,因此直接的商业应用相对较少。但是,在一个将大规模抽象知识与以各种形式逻辑实现的高阶推理相结合的系统中,精细推理是可能的,这是一个存在的证明。
即便是CYC的推理能力,无疑也有很大的提升空间。它的表示主要是(或者完全是)高阶逻辑的东西;不清楚它能在多大程度上表示不确定性,以及对统计分布的推理,等等。正如伯特兰·罗素曾经说过的,“人类所有的知识都是不确定的、不精确的和部分的”,现在还不清楚CYC能处理多少不确定性、不完整性和不精确性。【另一个问题是人类在推理中面临的诸多限制,如确认偏差、动机推理、语境效应、连接谬误等。在一个理想的世界里,我们会从人类做得好的事情中学到东西,但把这些异常现象抛在脑后。关于为什么人类可能进化出这种认知效率低下的讨论,即使这种认知错误在功能上可能不是最优的,参见Marcus(Marcus,2008)】
有人怀疑,就像经典人工智能和神经人工智能中的许多其他东西一样,它很可能是脆弱的,高度依赖于数据库中的特定知识以及复杂场景映射到其内部逻辑的精确方式。
尽管如此,它——或者其他能够做类似工作的东西,也许使用不同的方法——似乎是通往稳健推理的必经之路。一个不能理解罗密欧和朱丽叶的情节摘要的人工智能不太可能胜任现实世界的复杂性。一个人工智能,可以推理的动机交互人类作为复杂的事件,因为他们随着时间的推移展开有战斗的机会。
乐观的可能性是,一旦混合架构(architecture)知识的先决条件得到更好的发展,推理可能会自行解决;悲观的可能性是,我们可能需要在推理本身方面进行重大改进,至少在可伸缩性和处理不完整知识的能力方面是如此。在我们把前两个房子——建筑学和知识表示——整理好之前,我们可能真的无法分辨。
但我们已经知道:由于世界的复杂性,我们需要这样的东西。很明显,我们需要新的基准来推动我们的系统进行罗密欧与朱丽叶场景所体现的那种复杂的推理。由于我们既不能预先对每一个场景进行编码,也不希望总是在已知的场景之间进行插值,因此一个能够有效地利用大规模背景知识的推理系统,即使在可用信息不完整的情况下,也是鲁棒性的先决条件。
Minervini等人最近的研究(Minervini等人,2019年)给了我希望,一种神经符号混合的方法可以开辟新的领域。Besold等人(Besold、Garcez、Stenning、van der Torre和van Lambalgen,2017)提供了另一个起点。人们在努力这一事实给了我更多的希望;如果我们要前进,推理和知识需要成为一流的公民,看到人们在努力是件好事。
2.4认知模型
一种特殊的知识是随着时间的推移积累起来的关于特定事务状态的知识,例如我们在谈话过程中可能了解到的关于一个朋友的信息,在阅读新闻过程中了解到的关于一个国家的信息,或者在读一本书时了解到的关于一群人的信息。在认知心理学中,我们称这种累积表征为认知模型。你的认知模式可能和我的不同;你的可能更详细,我的可能不太详细,但我们都经常使用它们。但最起码,认知模型可能包括一些实体的知识(例如,故事中的人物和他们拥有的物品),一些属性的知识(例如,物品的大小和颜色,人物的目标等),以及关于时间和事件的信息(角色x在什么时候遇到角色y,以及x在时间t知道什么)。
CYC/罗密欧和朱丽叶插图中的命题和时间标记,例如关于相信什么和什么时候相信的复杂事实的显式表示,是丰富的认知模型在人工智能系统中可能编码的一个例子。人们还可以想到Johnson Laird(Johnson Laird,1983)关于心理模型的工作。如果我告诉你有一个空书架,然后解释说我把两本书放在书架上,你就构建了一个包含两本书的书架的内部表示。如果我告诉你我在书架上又加了一本书,你就更新你的表示,这样你就有了一个包含三本书的书架的内部表示。理解事物在很大程度上就是推断出它是什么的模型,并最终能够推断出它是如何运作的,以及接下来会发生什么。
这绝不是一个微不足道的过程。任何一个GOFAI研究者都可以描述,原则上,一个人如何手动构建(一些)复杂的认知模型,但在特定场合推断正确的认知模型可能是一个复杂的过程,在给定的情况下,往往有一个以上的似是而非的答案,而且目前还不可能自动化。
CYC的例子罗密欧和朱丽叶是令人信服的,因为系统得出的推论是复杂和明智的,但令人失望的是,基本模型是手工编码的,而不是从剧本中归纳出来的。这使得该系统可以很好地用于演示目的,但在现实世界中,为了让认知模型为强大的人工智能铺平道路,我们需要找到从数据流(如视频或文本)中自动推断它们的方法。
这是一个如此困难的问题(在下面讨论的场景理解领域之外)大多数人转而从事其他的工作,并在令人惊讶的程度上尝试完全不使用认知模型。
例如,DeepMind的Atari游戏系统DQN几乎完全缺乏明确的认知模型。当DQN学会玩突围游戏时,它并没有将单个棋盘的位置抽象成表示单个棋盘的位置和范围的场景图;也没有直接表示划桨的位置、球的速度或游戏的基本物理,也没有任何抽象的实现弹跳的动力使游戏如此引人入胜。在强化学习语言中,系统是无模型的。【头发分裂者(不知道怎么翻译hair-splitters)可能会争辩说,存在某种自我生成的内部模型,指出系统的内部状态在某种程度上与经典认知状态相关,而MuZero这样的系统更是如此(Schrittwieser et al.,2019)。在我看来,这种系统转移到新环境的能力有限(见正文)破坏了这类强有力的主张。】然而超人的成就已经实现了。(值得注意的是,在一些游戏中,如Pong,在已知的起始条件下是严格确定的,完全不看屏幕就可以成功地玩(Koul,Greydanus,Fern-arXiv预印本)附件十四:1811.12530, & 2018, ).
但是,像DQN这样的系统的成功有什么教训呢?在我看来,这个领域过于笼统了。在像Breakout这样的封闭领域中,只要有足够的数据(通常远远超过人类在类似情况下所需的数据),无模型强化学习通常效果非常好。但这并不意味着无模型强化学习是解决智力问题的一个好方法。
问题在于,无模型解在诱导它们的精确环境之外,泛化能力很差。Kansky等人(Kansky等人,2017年)通过修补Breakout以令人信服的方式展示了这一点;即使是将拨片向上移动几个像素之类的微小变化也会导致性能大幅下降。人类通过内部认知模型进行工作,可以很快得到补偿;无模型的深度强化学习系统往往无法做到这一点,相反,经常需要大量的再培训,正是因为它们缺乏丰富的环境认知模型。
GPT-2(见Marcus,2019,2020)等电流互感器在语言理解方面的失败范围反映了类似的情况:预测总体趋势之间的分歧(如短语mom's house出现在单词附近的可能性,以及语料库GPT-2中的短语drop、off、pick、up和clothing)以及表达、更新和操纵认知模型的能力。当BERT和GPT-2未能跟踪干洗将在何处时,这直接反映了GPT和BERT不能代表单个实体随时间演化的特性。如果没有认知模型,这样的系统就会消失。
有时他们从统计学中得到好运,但是缺乏认知模型,他们没有可靠的基础来推理。
认知模型的缺乏对于任何希望使用Transformers作为下游推理系统输入的人来说也是一个惨淡的消息。语言理解的全部本质是从语篇中导出认知模型;然后我们可以对我们导出的模型进行推理。Transformers,至少在他们目前的形式,只是没有做到预测词类是令人印象深刻的,但就其本身而言,预测并不等于理解。
§
正如我们在第4.3节中看到的罗密欧和朱丽叶的例子,CYC是非常好的,因为它可以(至少在一些非琐碎的程度上)超过认知模型的推理(例如它的时间点列表和关于在不同时间点已知的人物和地点的事实,节选于图2),与背景(常识知识)相关,但仍然存在着可悲的缺陷,因为它无法单独推导出相关的认知模型。任何一个系统,如果能够将自然语言维基百科的绘图摘要(如图2左面板中的一个)作为输入,并自动导出自己的详细认知模型(类似于CYC的程序员手工构建的模型),这样下游的推理者就可以对其进行推理,这将是相对于传统推理的一个重大进步当前AI。
不幸的是,很少有人致力于从描述随时间发展的事件的文本(更不用说视频)中推导出丰富的认知模型。Pasupat和Liang的一篇论文(Pasupat和Liang,2015)试图将句子解析成可在表上运行的可编程查询,但该系统并不试图随着时间积累模型。Facebook人工智能研究的一些论文,例如记忆网络(Bordes,Usunier,Chopra,&Weston,2015)和循环实体网络(Henaff,Weston,Szlam,Bordes,&LeCun,2016),可以将简单的故事作为输入并回答一些关于它们的基本问题。但是这些系统(a)需要大量的输入,相对于他们回答的每个问题,(b)似乎范围有限,很大程度上依赖于问答之间的语言重叠,(c)整合先前知识的能力非常有限。也许最重要的是,(d)他们没有产生丰富的认知模型,可以传递给推理者作为他们的输出。彼得·诺维格(Peter Norvig)关于故事理解的论文(Norvig,1986)试图在一个经典的符号操纵框架中做类似的事情,就像沙克和阿贝尔森(Schank&Abelson,1977)的许多开创性工作一样,但据我所知,故事理解不再是当前研究的活跃领域。这是一个被抛弃而不是解决的重要问题。(沙克和阿贝尔森,1977年)
据我所知,最活跃的文献是关于场景理解的研究,其最终目的不仅是解释视觉场景中存在的对象,而且还解释对象之间的关系,例如,不仅仅是识别一个玻璃杯和一张桌子,而是注意到一个特定的玻璃杯在桌子上,在一个特定的房间里玻璃杯靠近桌子边缘,由桌子支撑,依此类推。这已经超出了艺术的范畴【在我看来,目前的工作场景理解能力很差,部分原因是很多工作试图将场景作为一个整体(“人做饭”)来识别,而不是根据一组个人(如人或物体)以及这些实体之间的关系来识别,部分原因是它的目的主要是在没有推理的情况下进行,推理有时对于构建连贯的模型是必不可少的。因为可能性的数量是指数级的,适合于从有限的类别集合中对图像进行分类的技术不太可能满足需要;相反,推理本身必须(与对象分类一起)有助于从场景中归纳认知模型的过程。最近一个很有前途的概率生成模型GENESIS明确地建模了场景组件之间的依赖关系(Engelcke、Kosiorek、Jones和Posner,2019)。另见DeepMind的莫奈(Burgesset al.,2019)和梅林(Wayne et al.,2018)以及(Gregor et al.,2019)中的表达生成模型。e、 g.,inverse graphics papers by Vicarious(Kanskyet al.,2017;George et al.,2017)和Josh Tenenbaum的团队(Mao et al.,2019;Veerapaneniet al.,2019)。】;最终,认知模型归纳需要更进一步;例如,我们还需要确定心理关系,这两种关系都是在表面层面上的,例如,人1正在与人2交谈,最终达到一个更复杂的水平(例如,人1与人2交谈以欺骗人2,这样人2就会给人1钱)。至少我们的一些符号必须以某种方式建立在我们的感知经验中,如果我们要用符号来解释场景,我们必须有从输入中推断符号(以及符号之间的结构化关系)的方法。建立适当的模型还需要能够推断时间边界和时间关系的系统,等等。
场景理解只是一个更大问题的一个例子;每次我们理解一个故事或阅读一篇文章时,我们都需要做同样的事情,在这种情况下,是从文字而不是直接的视觉体验。
在我们第一次对强大智能的探索中,我们不能期望制造出能理解莎士比亚的机器,但我们可以追求比我们所拥有的多得多的东西。我5.5岁和7岁的孩子可能不会自发地理解莎士比亚,但他们所拥有的智力在很大程度上是强大的;他们了解很多关于日常事物的物理相互作用的知识,以及足够了解人类的目标和动机,以理解大量的儿童书籍;已经,早在小学阶段,他们就掌握了欺骗、误解和动机等概念,这些概念在《罗密欧与朱丽叶》的故事中非常关键。他们可以在各种各样的操场上攀爬和机动,还可以谈论各种各样的话题。
最终,推理和认知模型可以以几乎无限的方式结合起来。例如,假设在中午12点,一个孩子被单独留在一个房间里,房间里有一个装有饼干的封闭饼干罐。中午12:05,人们注意到罐子是关着的,但饼干却不见踪影。其间发生了什么?结合时间和空间推理,你可以很容易地推断出(a)孩子打开了罐子(b)孩子拿走了饼干,(c)孩子吃了饼干,(d)孩子关上了罐子。对于加分,你可以推断(b)一定发生在(c)和(d)之前,但是(c)和(d)的顺序是未知的。结合生物学理论,你可以把孩子理解为一个容器,并意识到饼干现在被包含(部分消化)在里面,已经从一个开口(一张嘴)进入另一个容器(胃)。没有任何理由认为,如果没有内部的认知模型和推理机制,人工智能将能够有力地做出这种推论。没有这一点,就不可能可靠地理解一个侦探小说,一个超越闲聊的对话,或者几乎任何人类互动的叙述。
我有两个猜想
•如果没有混合体系结构、丰富的先验知识和复杂的推理技术,我们就无法以适当、自动化的方式构建丰富的认知模型。举一个例子,如果我们看到水体中的涟漪隐约让人想起汽车,在一般情况下,我们应该假设这些涟漪只是涟漪,例如,基于汽车不会漂浮的知识。但我们可能会在黑帮电影的背景下改变我们的前科,在这部电影中,汽车可能会被故意推入水中。场景理解最终不仅仅是标记对象,而是使用最好的可用数据进行连贯的解释,这需要对数据进行一定程度的推理,并结合先验知识。任何单纯依靠标记图像的自下而上方法都可能在各种异常情况下失败,正如我们迄今所看到的,即使是在地图清晰的公共道路上进行自主驾驶的狭窄领域,尽管付出了巨大的努力和数十亿美元的投资。
•如果没有归纳和表现丰富认知模型的能力,我们就无法获得强健的智力。例如,阅读在某种程度上可以被认为是一种以句子为输入,以产生为输出(内部)认知模式的功能。当我们发现罗密欧自杀时,基于对事实的误解,我们更新了我们的模型。一旦我们更新了我们的模型,我们就会对它们进行推理(考虑到朱丽叶的明显死亡,罗密欧会自杀有意义吗?)。我们的情绪反应也来自于我们对所发生事情的内部认知模式的相对判断。(角色刚才表演的动作是否合乎道德?安全吗?愚蠢?悲剧?)。纯粹的共现统计并没有可靠地得出这一点。Cyc有能力表示丰富的认知模型,但由于它没有感知成分,缺乏足够的自然语言前端,因此不能从数据中归纳模型。Transformers,如果他们成功了,就跳过了归纳和表现丰富认知模型的步骤,但这样做是有风险的,因为他们能够做的推理因此是相当有限的。同样,家用机器人最终也会被限制在他们能够安全参与的行动范围内,因为他们能够通过丰富的认知模型进行归纳、表示和推理。
§
单靠更多的数据可能无法解决这个问题。在我编辑这篇手稿的时候,谷歌发布了Meena(Adiwardana et al.,2020),在341GB的海量语料库上进行训练,几乎是GPT-2训练的10倍,相当于大约341000本书,远远超过大多数人一辈子的阅读量。
根据谷歌的博客“走向一个可以谈论……任何事情的对话代理”,Meena“可以进行比现有最先进的聊天机器人更明智和具体的对话。”像GPT-2一样,Meena创作的散文既非常流畅,也非常有主题性。它最好的对话是惊人的,该报报道说,它设置了一个新的艺术状态,在新的衡量标准“感性和特异性”。但同样的核心基础——世界内部认知模式仍然缺失。
考虑一下这个片段
你最喜欢的乐队是什么?Avengedsevenfold。
人类:哦,这是个好答案!你最不喜欢哪个乐队?Avengedsevenfold。
哦,我以为你喜欢Avengedsevenfold?米娜:是的。那是我最喜欢的乐队。
每个答案都是连贯的,但从一个答案到下一个答案却没有连贯性。Meena抓住了这样一个事实,即某些短语,如乐队名称,往往与短语,如“最喜爱的乐队”;但没有持久的记录,Meena的喜好,即使是一个简短的对话长度,因此完全不一致。
在第77次对话中也可以看到大致相同的情况。Meena在自称“学习”广东话和已经母语流利的广东话之间摇摆不定:
人类:你的新年决心是什么?米娜:减掉60磅学广东话学法语人类:你不觉得,那很牵强吗?
米娜:不是真的。我现在瘦了35磅,我已经能说广东话到一个基本的水平,而且我已经在学校学法语了。
人类:哇!真令人印象深刻!
米娜:我在一边学法语,这对我来说真的很容易,因为我的母语是粤语。
没有认识到你不能学习一门你已经知道的语言(缺少背景知识),也没有内在的模式来判断米娜是否会说广东话。一句一句的预测很突出;总体上是不连贯的。
§
当我在修改这篇论文的初稿时,我开始用“猫在垫子上”这句话起草一个图表。我的计划是展示如何解释这个句子,从语法到语义,再到可更新的认知模型,跟踪实体(如猫和垫子)及其属性和彼此之间的关系;目标是展示GPT-2是如何试图缩短这条路径,从而得到混合的结果。
我还没来得及画完这幅图,我5.5岁和7岁的孩子们就从我身后望过去,咯咯地笑着大声念着“猫在垫子上”这句话。我转向年长的那个,问他:“你能把一头大象放在垫子上吗?”他回答说,这要看情况;如果这是一个真正的大垫子,你可以,如果这是一个小垫子,你不能。他立即形成了一个虚构的世界和实体的模型,填充了这个世界,并应用他的一般常识知识的理论世界,完全没有标签的例子。
当他离开房间时,我问了他妹妹,我5.5岁的女儿。她很好地理解了前面的谈话,并对我的问题给出了一个同样恰当的答案。当我问她一座房子是否能放在垫子上时,她证明了自己同样擅长构建一个模型,并对其未指明的参数进行推理,从而得出合理的结论。
我们不可能建立可靠、健壮的人工智能系统,因为这些系统无法与小孩子通常做的基本推理和模型构建相匹配。等待认知模型和推理从越来越大的训练语料库中神奇地出现,就像等待奇迹。
底线是:目前针对建立认知模型系统的研究太少。强调端到端的学习和大量的训练集已经从核心的更高层次的认知转移。大多数研究人员甚至没有试图构建围绕认知模型的系统,而且(除了在像自动驾驶这样的狭隘领域之外)越来越少的研究人员专注于发现相对于输入流(如文本或视频)导出和更新认知模型的一般方法这一相关挑战。很少有人把重点放在结合先前的常识来推理这些模型上,例如大象相对于猫的大小,以及这与各种大小的垫子的关系。
在我看来,构建能够将语言和感知输入映射到丰富的、不断发展的认知模型的系统应该是该领域最优先考虑的问题之一。
换言之,更紧迫的是,花在改进大规模单词级预测模型上的每一刻,即lagpt-2和Meena,都是一个可以更好地用于开发派生、更新和推理认知模型的技术的时机。
如果我们想建立健壮的人工智能,我们就不能再等了。
3.讨论
3.1. 一种围绕着持久的抽象知识的智慧
没有我们,或者像我们这样的生物,世界将继续存在,但它将无法被描述、提炼或理解。鸟可以拍打翅膀,也可以带着它飞行。有关联,但没有因果关系的描述。人类生活充满了抽象和因果描述。我们的孩子大部分时间都在问为什么;科学家问这样的问题是为了产生理论。我们的力量很大一部分来自于我们以科学、文化和技术的形式理解和描述世界的努力。
大部分的努力都以知识的形式达到高潮,有些是具体的,有些是一般的,有些是口头的,有些不是。经典人工智能的很大一部分目标是以机器可解释的形式提取这些知识;CYC是这方面最大的项目。
一路上的某个地方,人工智能领域走了一个不同的方向。大多数研究人员,如果他们了解CYC的话,会认为这是一个失败,而目前很少有研究人员会将他们的目标描述为积累知识,就像Lenat所描述的那样。【也许Google知识图(Google Knowledge Graph)最接近,但据我所知,知识图的目标是积累有助于消除搜索查询歧义的具体事实,比如法国有一个叫巴黎的城市,而不是抽象的常识。】
像Transformers这样的系统的部分成功导致了一种虚幻的感觉,即CYC规模的机器可解释的人类知识表示是不必要的,但我认为这是一个错误。然而,正如我们所看到的,尽管Transformers作为统计推断引擎给人留下了深刻的印象,但它们离成为强大智能的坚实基础还有很长的路要走。他们不可靠,他们的知识参差不齐。
他们的推理能力很差,而且随着时间的推移,他们无法建立事件的认知模型;没有明显的方法将它们与更复杂的推理和认知模型建立系统联系起来,也没有办法将它们用作可解释、可调试的智能的框架。
这篇论文的重担是主张研究重点的转变,转向构建健壮人工智能的四个认知前提:混合架构,将大规模学习与符号操作的表征和计算能力相结合,大规模知识库可能利用固有的框架,这些框架将符号知识与其他形式的知识结合起来,推理机制能够以可处理的方式利用这些知识库,丰富的认知模型与这些机制和知识库协同工作。
随之而来的是对可能更加异构的体系结构的需求。到目前为止,许多机器学习都集中在相对同质的体系结构上,其中单个神经元的能力仅限于求和和和集成,通常不超过少数预先指定的模块。正如最近的研究所表明的,这是一种过分简单化的说法;在宏观层面上,仅大脑皮层就有数百个解剖和可能的功能区域(Van Essen、Donahue、Dierker和Glasser,2016);在微观层面上,如前所述,即使是单个神经元的单个树突室也可以计算XOR的非线性(Gidon等人,2020)。Adam Marblestone、Tom Dean和我认为(Marcus et al.,2014),大脑皮层不太可能用一个标准电路来计算它的所有功能;神经计算中可能存在一个重要的多样性,这在计算神经科学或人工智能中还没有被捕捉到。
两个数字以定性的方式反映了我认为我们近年来一直在做的事情,以及我们应该做的事情。这些数据的第一点也是最重要的一点很简单:潜在的人工智能(和机器学习)模型的空间是巨大的,而且只有一小部分可能存在的东西被探索过。空白板岩经验主义模型已经得到了很好的研究,并且得到了很好的资助,沉迷于人工智能早期难以想象的计算资源和数据库;已经有了一些真正的进展,但如此多种形式的脆性仍然是一个严重的问题;是时候探索具有类似活力的其他方法了。
向前发展至少需要我们建立一个模型,原则上能够代表和学习我们在语言和更高层次认知方面所需要的各种东西。
目前大多数系统甚至都不在正确的范围内。至少,充分的知识框架要求我们能够通过变量运算,以代数的方式表示和操作我们的知识的一部分;很可能这些知识的一些(大的)子集是按照结构化表示进行编码和维护的,这些知识中的大部分必须与特定的个体有关,并允许对其进行追踪。
Transformer体系结构有解决所有这些问题的方法,但如果不加以补充,最终不太可能成功;同时,我们绝对不能期望所有相关知识都是预先固定的。
本文的有力预测是,健壮的人工智能必然存在于图4所示的交叉点。
图4:Venn图在广阔的智能模型空间中勾勒出了一些模型和架构,重点关注学习和符号操作的维度。代数思维的假设(马库斯,2001),以及目前猜想的核心是,成功的智力模型需要对变量、结构表征和个体记录进行运算。NS-CL[第2.1.2节中提到的神经符号概念学习者(Mao et al 2019)]代表了许多此类可能的混合模型之一,其中许多尚待发明。本文认为,在新的十年里,这一交叉区域应该成为通用智能研究的中心。
同时,这个交叉点内可能模型的空间是巨大的,甚至可能是无限的;说正确的架构是有一个开始,但只是一个开始,就像说一个网络浏览器可能应该用一种语言来编写,那就是图灵等价物。很好,很真实,而且。。。现在怎么办?拥有一套合适的基本体只是一个开始。
这里有一种方法来思考这个问题:有无限多的可能的计算机程序,其中只有一些例示应用程序,如(例如)web浏览器或电子表格,并且只有一个子集表示健壮的web浏览器或电子表格。类似地,有无限多的系统包含结构化表示、个人记录、对变量的操作,所有这些都在允许学习的框架内,但只有其中一些系统会实例化健壮的智能。如果本文的主旨是正确的,那么结合学习和符号操作的混合体系结构对于健壮的智能是必要的,但还不够。
例如,还需要正确的宏观结构,包括多个领域的丰富知识,如图5所示:
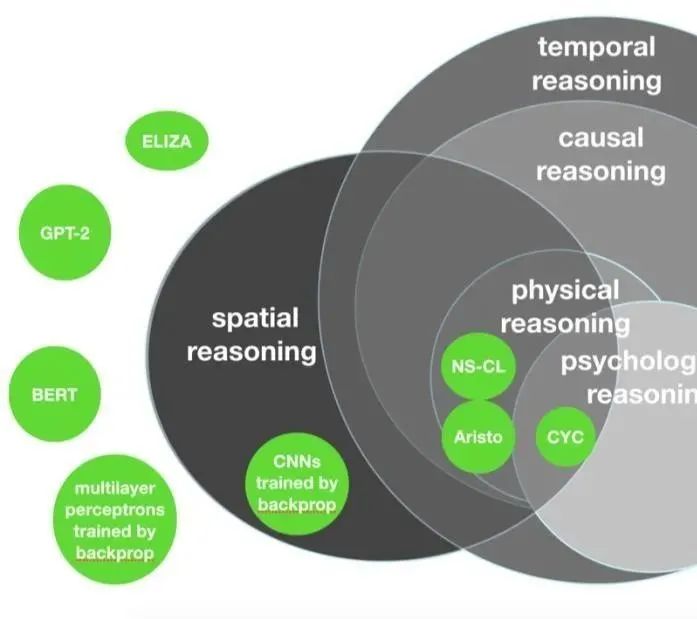
图5:Venn图强调系统的需要,包括空间、物理、心理、时间和因果推理的机制。大多数当前的神经网络缺乏明确的机制来进行这些形式的推理,也缺乏对这些领域进行表示和推理的自然方式(但参见Cranmer et al.,2019)
将这两个数字的要点与当前的趋势相比较。大多数(并非全部)深度学习的当前工作都回避了对变量、结构化表示和个人记录的操作;同样地,深度学习在很大程度上没有大规模抽象知识、丰富的认知模型和明确的推理模块。总的来说,关于合成认知的原语应该是什么的讨论还不够。深度学习在很大程度上取得了它所取得的成就,没有了这种传统的计算精确性,也没有任何看起来像是物理推理、心理推理等明确模块的东西。
但是,如果认为在诸如语音识别和对象标记等主要围绕分类的领域中,效果相当好的东西,必然会可靠地用于语言理解和更高层次的推理,这是一种谬误。可以肯定的是,一些语言基准已经被打破,但一些深刻的东西仍然缺失。当前的深度学习系统可以学习任意一点信息之间无尽的关联,但仍然无法深入;它们无法代表世界的丰富性,甚至根本不了解外部世界的存在。
那不是我们想去的地方。
在重新启动人工智能即将结束时,我和欧内斯特·戴维斯敦促
简言之,我们实现常识和最终的一般智力的方法是:首先开发能够代表人类知识核心框架的系统:时间、空间、因果关系、物理对象及其相互作用的基本知识、人类及其相互作用的基本知识。将这些嵌入到一个可以自由扩展到各种知识的体系结构中,始终牢记抽象性、组合性和个体跟踪的中心原则。
开发强大的推理技术,能够处理复杂的知识,
不确定,不完整,可以自上而下和自下而上自由工作。将这些与感知、操纵和语言联系起来。用这些来建立丰富的世界认知模型。最后一个重点是:构建一种人类启发的学习系统,使用人工智能拥有的所有知识和认知能力;将所学知识融入其先前的知识;像孩子一样,贪婪地从各种可能的信息来源学习:与世界互动,与人互动,阅读,看视频,甚至被明确教导。把这些放在一起,你就可以得到深刻的理解。(马库斯和戴维斯,2019年)。
我们的结论是“这是一个很高的要求,但这是必须要做的。”即使在GPT-2这样的Transformers在我们付印之后出现了戏剧性的增长,我认为没有理由改变我们的要求。
Weconcluded "It’s a tall order, but it’s what has to be done." Even after the dramatic rise of Transformers such GPT-2,which came out after we went to press, Isee no reason to change ourorder.
3.2我们还能做些什么吗?
很显然,是的。
3.2.1工程实践
首先,实现稳健性不仅仅是发展正确的认知前提,也是发展正确的工程实践。戴维斯和我在第十章“重新启动人工智能”中简要讨论了这一点,而汤姆·迪特里希在他的AAAI Presidential Address 演讲(迪特里希,2017)中有一个非常好的讨论,我在《重新启动人工智能》问世后才发现这一点。Davis和我强调了冗余和指定公差等技术,这些技术长期以来一直适用于其他形式的工程。Dieterich提出了八条建议,非常值得一读,比如构造对奖励敏感的优化函数和直接构造检测模型故障的机器;和我们一样,他也强调了因果模型的必要性和冗余的价值。Joelle Pineau关于可复制性的观点也很重要(Henderson et al.,2017)。
3.2.2.文化
还有一件事需要解决,既与认知前提有关,也与良好的工程实践无关,那就是文化:某些东西与深度学习社区的某些元素严重不符,不利于进步。这是一个房间里的大象,必须承认和解决,如果我们要向前迈进。
尤其是外界的观点,尤其是批评的观点,往往被视为一种极端的侵略(双方几十年的敌对行动所导致的)【第二个文化问题,正如这篇手稿的一位读者所指出的,是深度学习的倡导者经常过于看重大数据,常常假设(有时是错误的)复杂问题的答案基本上可以在越来越大的数据集和越来越大的计算集群中找到。整个领域,如语言学,在很大程度上都被忽视了。这不可能是好事。】,这种侵略不应在知识论述中占有一席之地,特别是在一个几乎肯定需要成为跨学科的领域,如果要取得进展。
学生们并不是对这种动态视而不见,他们逐渐认识到,公开宣称符号操纵是人工智能的一个组成部分,可能会对他们的职业生涯造成损害。例如,在我与Bengio辩论之后,一位来自著名深度学习实验室的年轻研究人员私下给我写信,说“其实我两年来一直想写一些……关于符号人工智能的东西,每次都不想写,因为担心它会对我未来的职业道路产生这样或那样的影响。”
这是一种适得其反的状态。正如辛顿本人曾经说过的那样,“马克斯·普朗克说过,‘科学跨过此次葬礼而前进。’未来取决于某个对我所说的一切深表怀疑的研究生。”进步往往取决于学生认识到长辈理论的局限性;如果学生不敢说话,那就是一个严重的问题。
3.3.一点一点地看清整个大象(事物)
好消息是,如果我们能够开始共同努力,进展可能并不遥远。如果健壮智能的问题已经解决了,就完全没有必要写这篇文章了。但是,也许,只是也许已经足够了,如果我们眯着眼睛,看看周围的碎片,如果我们把它们放在一起的话,我们也许能够想象大象的样子。
一些想法:
•深度学习向我们展示了从海量数据中可以学到多少。同现统计等可能只是可靠知识的影子,但确实有很多影子,只要我们敏锐地意识到它们的优点和局限性,也许我们可以利用这些影子,使用更复杂的技术。
•在丰富的知识基础和丰富的认知模型存在的情况下,CYC显示了复杂推理的潜在能力,即使它本身不能直接从语言或知觉输入中推导出这些模型。
•像NS-CL(Mao等人,2019年)这样的系统向我们表明,符号操纵和深度学习至少在原则上可以整合成一个无缝的整体,既能感知又能推理。
这样的例子太多了。如果我们能够打破僵局,停止60年来阻碍进展的敌对行动,转而集中精力,努力在这些世界之间架起桥梁,前景就是好的。稍微混合一些比喻,也许避开下一个可能的人工智能冬天的最好方法可能是让我们的帐篷不是在一根柱子上休息,而是在许多柱子上休息。
3.4结论、前景和影响
没有什么要求我们放弃深度学习,也不放弃正在进行的专注于新硬件、学习规则、评估指标和培训制度等主题的工作,但它促使我们从学习或多或少是唯一一等公民的观点转变为学习是更广泛的联盟的核心成员的观点欢迎使用变量、先验知识、推理和丰富的认知模型。
我提倡一个四步计划:首先开发混合的神经-符号结构,然后构建丰富的、部分先天的认知框架和大规模知识数据库,然后进一步开发对这些框架进行抽象推理的工具,最终开发出更为复杂的认知机制认知模型的表征与归纳。综上所述,朝着这四个先决条件取得进展,可能会为比目前更丰富、更智能的系统提供基础。最终,我认为这将重新定义我们所说的学习的含义,导致一种(也许是新的)学习形式,它通过抽象的、类似语言的概括,从数据中,相对于知识和认知模型,将推理作为学习过程的一部分。
如果我所描述的没有一个是单独的或者甚至是集体的,我相信,它至少足以让我们更接近一个我们可以信任的人工智能框架。
把事情说得稍微不同一点:我呼吁的一种研究方法是,首先确定一组动机良好的初始原语(可能包括对变量的操作、注意机制等),然后学习如何在之后重新组合这些原语,考虑到这些原语,从本质上说,学习什么是良好的实践。直到后来,一旦这些优秀软件工程的原则被确定,我们才有可能进入极其复杂的现实世界能力。大多数机器学习工作基本上都试图跳过开头的步骤,以经验的方式处理复杂的问题,而从未试图建立一个关于语言和更高层次认知真正需要什么初始原语的坚定理解。跳过这些最初的步骤,到目前为止还没有使我们获得语言理解和可靠的、可信赖的、能够应对意外情况的系统;现在是重新考虑的时候了。
在我看来,如果我们不改变方向,我们就不可能解决我们对人工智能最直接的担忧。当前的范式长期依赖数据,但缺乏知识、推理和认知模型,根本无法让我们获得可以信任的人工智能(Marcus&Davis,2019)。无论我们想建造与我们一起生活在家中的通用机器人,还是在不可预知的地方驾驶我们四处走动的自动车辆,或是对罕见疾病和普通疾病同样有效的医疗诊断系统,我们需要的系统不仅仅是挖掘大量数据集以获得更微妙的关联。为了做得更好,实现安全性和可靠性,我们需要对世界有丰富的因果理解的系统,这需要从更加注重如何用抽象的因果知识和详细的内部认知模型来表示、获取和推理开始。
§
罗马不是一天建成的。孩子们有大量的常识,能够推理,并学习复杂的知识,但他们仍然需要数年的时间才能拥有(大多数)成年人的成熟度、广度和能力。他们已经开始获得一些知识,具体的方面,在这里和现在,但仍然要学习,特别是有关微妙的领域,如政治,经济,社会学,生物学和日常人际交往。
通过利用混合体系结构中的创新,弄清楚如何利用认知模型和大规模背景知识可靠地构建、表示和推理,如第2.1.2节所述,将是一个重要的步骤,并可能在未来十年中占据大部分时间,但不会是整个过程。
重要的是,这些关键认知前提的进步可能会使人工智能成为一个自给自足的学习者,就像一个聪明的学童一样,但它们本身并不能保证产生一个完整的认知存在。也就是说,它们可能会导致自我教育的机器,在某些方面就像一个孩子,对世界有着不完全的了解,但却有着获取新思想的强大天赋。这当然只是一个开始,但它将使已经发生的事情看起来只是序幕,一些我们还不能完全预见的新事物。
4.致谢
为了纪念雅克·梅勒,1936-2020,科学家,《认知》杂志的创始人,跨学科认知科学的伟大倡导者,我们需要将人工智能提升到一个新的水平。
这篇文章的一部分是对我与Yoshua Bengio于2019年12月23日在加拿大蒙特利尔,由蒙特利尔AI的Vince Boucher组织的AI辩论的反思。我感谢约书亚和文斯使这成为可能我也感谢迪恩阿比奥拉,道格贝米斯,艾米莉本德,文斯鲍彻,厄尼戴维斯,汤姆迪特里奇,佩德罗多明戈斯,查兹费尔斯通,阿图尔达维拉加塞兹,丹尼尔卡尼曼,卡蒂娅卡彭科,克里斯蒂安克斯汀,路易斯兰姆,亚当马布尔斯通,梅兰妮米切尔,艾亚德纳瓦尔,巴尼佩尔,Jean-Louis Villecroze和Brad Wyble,他们阅读并评论了本手稿的早期草稿,Mohamed Amer和Dylan Bourgeous进行了有益的讨论。最重要的是,要特别感谢厄尼戴维斯,我在人工智能这么多的共鸣板;这篇论文很大程度上归功于我们的对话,和我们的联合研究。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

)



”)




)









)