本文转载自公众号:南大Websoft.

时间表达式识别是自然语言理解中一个重要而基础的任务。在以前的研究工作中,研究人员已经发现时间词的类型信息可以给识别提供明显的帮助。本文中我们以词类型序列作为表达式模式,提出了基于模式的时间表达式识别方法,PTime。我们设计了细分的时间词类型来从已有的时间表达式上自动归纳出模式,并选择一个高质量的模式子集用于从新的文本中抽取时间表达式。我们基于表达式模式的方法给结果提供了一定的可解释性,实验表明我们的方法在3个benchmark数据集中的两个上都超过了现有的state-of-the-art方法。
Background
自然语言理解中对时间信息的理解是一个重要部分,可以分为对时间表达式的识别(recognition)和时间表达式的标准化(normalization)这两个步骤,我们关注识别任务。时间表达式的识别多年来已经有大量的研究,但仍有明显的改进空间。目前最常见的时间识别方法,一大类是从序列标注的角度出发建立黑盒的机器学习模型(如一般的NER任务那样);另一大类是基于规则,先识别表达式中基本的词,然后通过规则组合或扩展识别出的部分得到完整的表达式。粗略地说,目前在benchmark数据集上表现最好的方法,要么是在黑盒的CRF模型上结合有效的词类型特征,要么是设计基于词的少数通用启发性规则来做识别。这些方法虽然识别效果好,但是结果的可解释性差,不利于后续的理解;而经典的规则方法虽然能表达复杂的时间表达式结构,在结果上对比这些方法却没有优势。
Motivation
目前在数据集上表现最好的方法都依赖于时间词的类型,或在词类型上人工设计规则,或将类型信息作为机器学习模型的重要特征使用。实际上,词的类型告诉了我们表达式的“类型序列”,这种序列提供了时间表达式的模式信息,例如“29 years”、“two days”这两个不同的表达式共有“数量 时间单位”这样一个构成模式。这些模式又可以帮助我们从文本中抽取新的时间表达式,例如“数量 时间单位”可以从“It took me one month”中抽取出“one month”。然而,我们不能简单地把可能的模式收集起来直接用于识别,这将导致一些错误,因为真实的自然语言是复杂而有歧义的,比如“three quarters”在某些语境中就不是数量“3”加时间单位“一刻钟”,而是“3/4” (如下图所示)。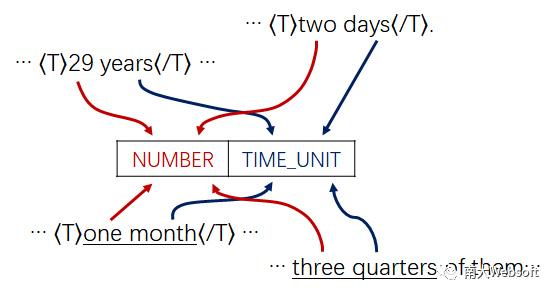
因此,我们得到了一个新的问题:能否从所有可能的时间表达式模式中选取一部分,允许用户可调节地去控制这些模式可能会犯的错误,来适应不同精度和召回率的时间表达式识别需求,得到一个尽量好的表现?
为了回答这个问题,我们把模式的选择过程建模为一个线性约束的子模(submodular)函数优化问题——我们研究组以前提出的the Extended Budgeted Maximum Coverage(EBMC)问题的实例。核心思想是,根据模式能在多大程度上匹配一个时间表达式来度量它对训练集上所有时间表达式的覆盖度,同时用每个模式在训练集上错误抽取的表达式数量来度量选择这个模式的代价。引入一个参数rho来调节允许的总代价的界限,在总代价不超过界限的前提下,最大化选出的模式对时间表达式集合的总覆盖度。
Framework
PTime的框架如下图所示: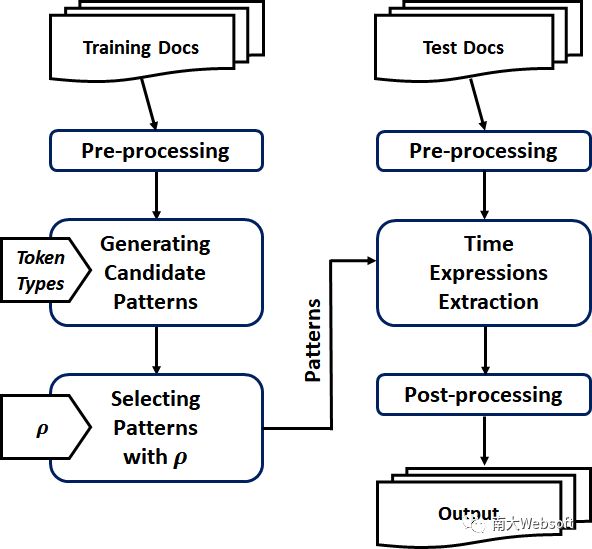
在PTime的工作过程中,文本首先被转换为token的序列。接着我们从语法和语义的角度出发,参考既有工作包括SUTime, SynTime和UWTime,设计了包含32个类别的细分词类型(Token Types),用于把token转换为类型,从训练集的时间表达式上得到模式。针对时间表达式中词汇难以被人工构造的类型穷尽的问题,我们允许模式中出现“untyped token”,即不向上泛化,而是保留原本的词作为模式的一部分(例,在Tweets数据集上,“1小时”可能被缩写成“1 hr”,“hr”不在标准词表中,于是我们保留“数量 hr”这个模式)。当产生候选的模式集合后,我们将选择过程建模为一个EBMC问题的实例,通过一个贪心近似算法求解,最终用选出的模式集合去检查测试集文本,对匹配到的串做简单的合并处理,作为最终的表达式识别结果。
Evaluation
我们的实验测试了3个benchmark数据集TempEval-3,WikiWars和Tweets,结果如下表所示。
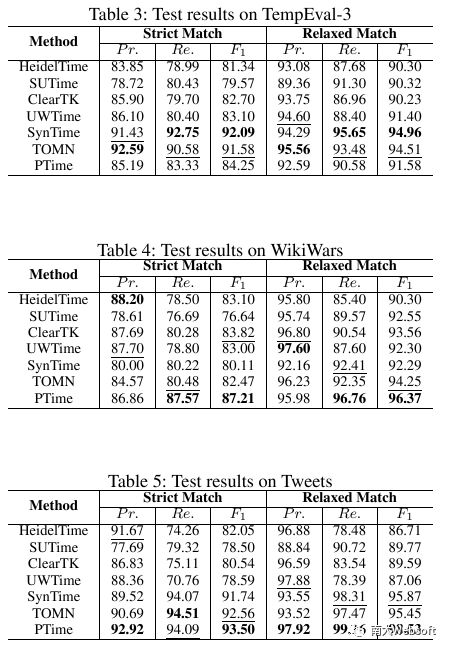
另外,对结果的分析表明各个数据集上存在一些类似“序数 月 年”(例:2018年的第4个月)这样有意义的“公共模式”,我们的方法可以发现帮助发现这些公共模式,并且它们可以反过来提升方法在一般任务上的表现。例如,我们只要简单地把WikiWars和Tweets上的选出的模式的公共部分加到对TempEval-3的测试中,方法的strict match F_1值就可以上升到0.87+。
具体的结果和代码预计会在整理后陆续在http://ws.nju.edu.cn/ptime放出(目前还在整理中)
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。
————用户画像)




)













