ltp︱基于ltp的无监督信息抽取模块:https://zhuanlan.zhihu.com/p/44890664
无监督信息抽取较多都是使用哈工大的ltp作为底层框架。那么基于ltp其实有了非常多的小伙伴进行了尝试,笔者私自将其归纳为:
- 事件抽取(三元组)
- 观点抽取
“语言云” 以哈工大社会计算与信息检索研究中心研发的 “语言技术平台(LTP)” 为基础,为用户提供高效精准的中文自然语言处理云服务。 pyltp 是 LTP 的 Python 封装,提供了分词,词性标注,命名实体识别,依存句法分析,语义角色标注的功能。
- 技术文档:http://pyltp.readthedocs.io/zh_CN/latest/api.html#id15
- 介绍文档:https://www.ltp-cloud.com/intro/#introduction
- 介绍文档:http://ltp.readthedocs.io/zh_CN/latest/appendix.html#id5
需要先载入他们训练好的模型,下载地址
初始化pyltp的时候一定要留意内存问题,初始化任何子模块(Postagger() /NamedEntityRecognizer()等等)都是需要占用内存,如果不及时释放会爆内存。 之前比较好的尝试是由该小伙伴已经做的小项目:liuhuanyong/EventTriplesExtraction,是做三元组抽取的一个实验,该同学另外一个liuhuanyong/CausalityEventExtraction因果事件抽取的项目也很不错,辛苦写了一大堆规则,之后会对因果推理进行简单描述。
笔者也自己写了一个抽取模块,不过只是简单评论观点抽取模块。 留心的小伙伴可以基于此继续做很多拓展:搭配用语挖掘,同义词挖掘,新词挖掘 code可见:mattzheng/LtpExtraction
1 信息抽取 - 搭配抽取
code可见:mattzheng/LtpExtraction
1.1 逻辑整理
整个逻辑主要根据依存句法分析,笔者主要利用了以下的关系类型:
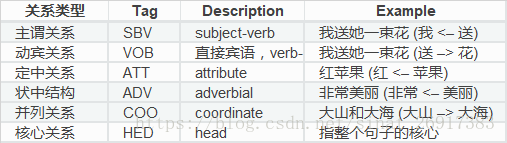
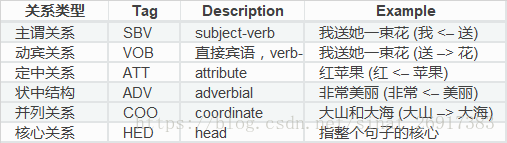
那么笔者理解 + 整理后得到四类抽取类型:
- 搭配用语查找(SVB,ATT,ADV)
- 并列词查找(COO)
- 核心观点抽取(HED+主谓宾逻辑)
- 实体名词搭配(词性n )
其中笔者还加入了停词,可以对结果进行一些筛选。
1.2 code粗解读
这边细节会在github上公开,提一下code主要分的内容:ltp启动模块 / 依存句法解读 / 结果筛选。
- ltp模块,一定要注意释放模型,不要反复
Postagger() / Segmentor() / NamedEntityRecognizer() /SementicRoleLabeller(),会持续Load进内存,然后boom... - 依存句法模块,笔者主要是整理结果,将其整理为一个dataframe,便于后续结构化理解与抽取内容,可见:
- 结果筛选模块,根据上述的几个关系进行拼接。
案例句:艇仔粥料很足,香葱自己添加,很贴心。
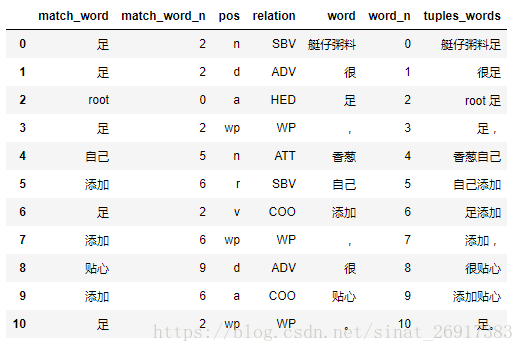
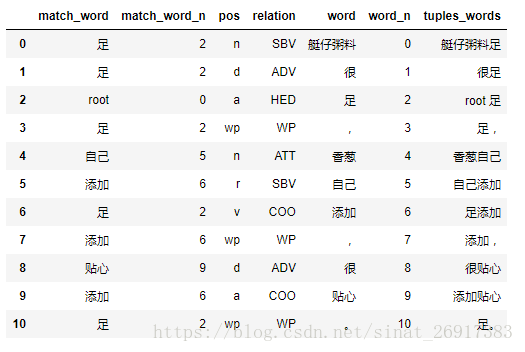
表的解读,其中: - word列,就是这句话主要分词结果 - relation列/pos列,代表该词的词性与关系 - match_word列/match_word_n列,根据关系匹配到的词条 - tuples_words列,就是两者贴一起
同时若觉得需要去掉一些无效词搭配,也可以额外添加无效词进来,还是比较弹性的。
1.3 结果展示
句子一:


句子二:


句子三:


2 三元组事件抽取 + 因果事件抽取
帮这位小伙伴打波广告~
2.1 三元组事件抽取
该模块主要利用了语义角色srl,先定位关键谓语,然后进行结构化解析,核心的语义角色为 A0-5 六种,A0 通常表示动作的施事,A1通常表示动作的影响等,A2-5 根据谓语动词不同会有不同的语义含义。其余的15个语义角色为附加语义角色,如LOC, 表示地点,TMP,表示时间等(一些符号可见笔者另一篇博客:python︱六款中文分词模块尝试:jieba、THULAC、SnowNLP、pynlpir、CoreNLP、pyLTP)。
基于依存句法与语义角色标注的事件三元组抽取 文本表示一直是个重要问题,如何以清晰,简介的方式对一个文本信息进行有效表示是个长远的任务.我尝试过使用关键词,实体之间的关联关系,并使用textgrapher的方式进行展示,但以词作为文本信息单元表示这种效果不是特别好,所以,本项目想尝试从事件三元组的方式出发,对文本进行表示. 项目地址:https://github.com/liuhuanyong/EventTriplesExtraction
使用之后的效果:




这边笔者觉得在结果之上,进行一些清洗的话,效果还是可以的,特别是事件性较强的,有效实体比较多的句子效果会比较好。当然,把这个用在评论中简直...
2.2 因果事件抽取
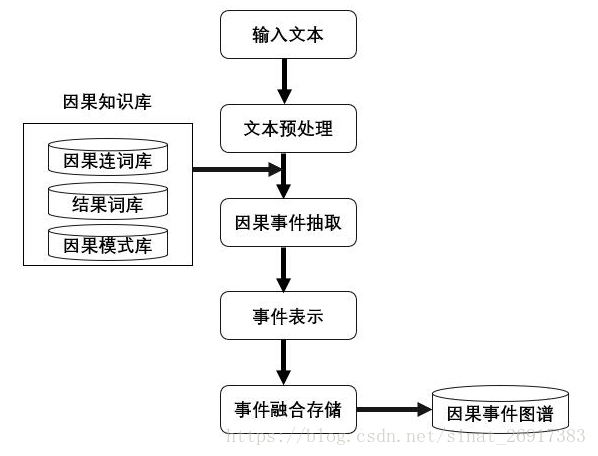
主要包括以下几个步骤:
- 1、因果知识库的构建。因果知识库的构建包括因果连词库,结果词库、因果模式库等。
- 2、文本预处理。这个包括对文本进行噪声移除,非关键信息去除等。
- 3、因果事件抽取。这个包括基于因果模式库的因果对抽取。
- 4、事件表示。这是整个因果图谱构建的核心问题,因为事件图谱本质上是联通的,如何选择一种恰当(短语、短句、句子主干)等方式很重要。
- 5、事件融合。事件融合跟知识图谱中的实体对齐任务很像
- 6、事件存储。事件存储是最后步骤,基于业务需求,可以用相应的数据库进行存储,比如图数据库等。
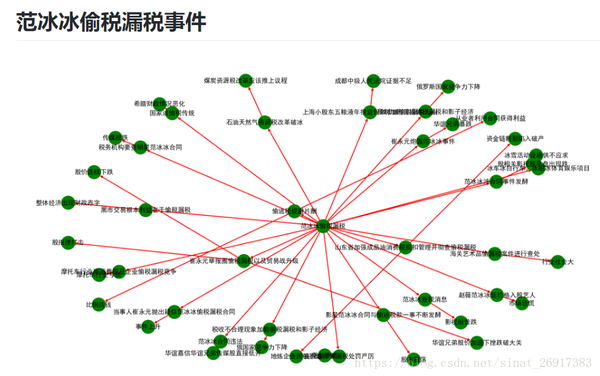
以下是运行结果:


整理之后的结果:





)




)





)



