背景
美团是全球领先的一站式生活服务平台,为6亿多消费者和超过450万优质商户提供连接线上线下的电子商务网络。美团的业务覆盖了超过200个丰富品类和2800个城区县网络,在餐饮、外卖、酒店旅游、丽人、家庭、休闲娱乐等领域具有领先的市场地位。平台大,责任也大。在移动端,如何快速定位并解决线上问题提高用户体验给我们带来了极大挑战。线上偶尔会发生某一个页面打不开、新活动抢单按钮点击没响应、登录不了、不能下单等现象,由于Android碎片化、网络环境、机型ROM、操作系统版本、本地环境复杂多样,这些个性化的使用场景很难在本地复现,加上问题反馈的时候描述的往往都比较模糊,快速定位并解决问题难度不小。为此,我们开发了动态日志系统Holmes,希望它能像大侦探福尔摩斯那样帮我们顺着线上bug的蛛丝马迹,发现背后真相。
现有的解决办法
- 发临时包用户安装
- QA尝试去复现问题
- 在线debug调试工具
- 预先手动埋点回捞
现有办法的弊端
- 临时发包:用户配合过程繁琐,而且解决问题时间很长
- QA复现:尝试已有机型发现个性化场景很难复现
- 在线debug:网络环境不稳定,代码混淆调试成本很高,占用用户过多时间用户难以接受
- 手动埋点:覆盖范围有限,无法提前预知,而且由于业务量大、多地区协作开发、业务类型多等造成很难统一埋点方案,并且在排查问题时大量的手动埋点会产生很多冗余的上报数据,寻找一条有用的埋点信息犹如大海捞针
目标诉求
- 快速拿到线上日志
- 不需要大量埋点甚至不埋点
- 精准的问题现场日志
实现
针对难定位的线上问题,动态日志提供了一套快速定位问题的方案。预先在用户手机自动产生方法执行的日志信息,当需要排查用户问题时,通过信令下发精准回捞用户日志,再现用户操作路径;动态日志系统也支持动态下发代码,从而实现动态分析运行时对象快照、动态增加埋点等功能,能够分析复杂使用场景下的用户问题。
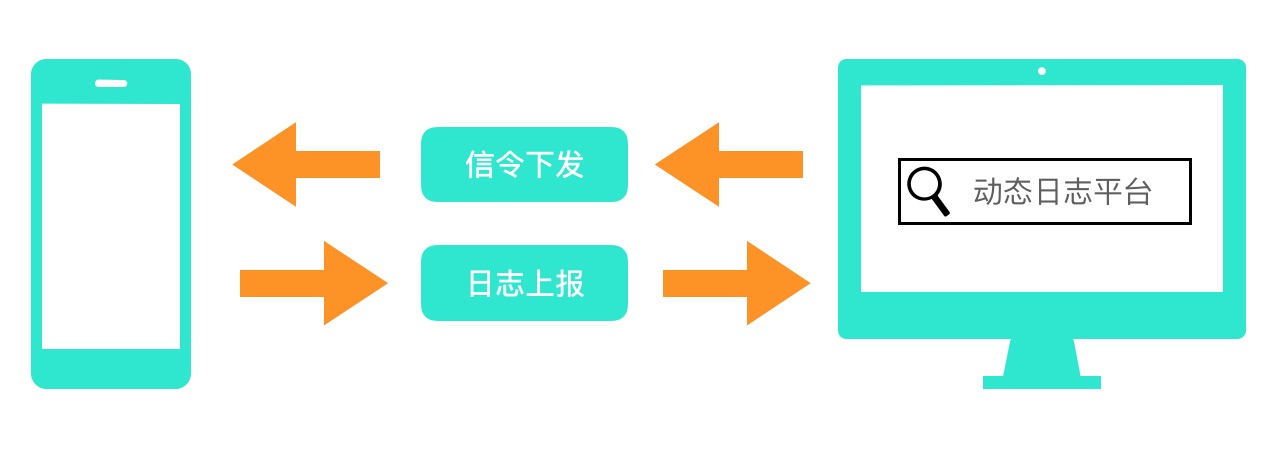
自动埋点
自动埋点是线上App自动产生日志,怎么样自动产生日志呢?我们对方法进行了插桩来记录方法执行路径(调用堆栈),在方法的开头插入一段桩代码,当方法运行的时候就会记录方法签名、进程、线程、时间等形成一条完整的执行信息(这里我们叫TraceLog),将TraceLog存入DB等待信令下发回捞数据。
public void onCreate(Bundle bundle) {//插桩代码if (Holmes.isEnable(....)) {Holmes.invoke(....);return;}super.onCreate(bundle);setContentView(R.layout.main);}
历史数据
Tracelog形成的是代码的历史执行路径,一旦线上出现问题就可以回捞用户历史数据来排查问题,并且Tracelog有以下几个优点:
- Tracelog是自动产生的无需开发者手动埋点
- 插桩覆盖了所有的业务代码,而且这里Tracelog不受Proguard内联方法的限制,插桩在Proguard之前所以方法被内联之后桩代码也会被内联,这样就会记录下来对照原始代码的完整执行路径信息
- 回捞日志可以基于一个方法为中心点向前或者向后采集日志(例如:点击下单按钮无响应只需要回捞点击下单按钮事件之后的代码执行路径来分析问题),这样可以避免上报一堆无用日志,减少我们排查问题的时间和降低复杂度
Tracelog工作的流程
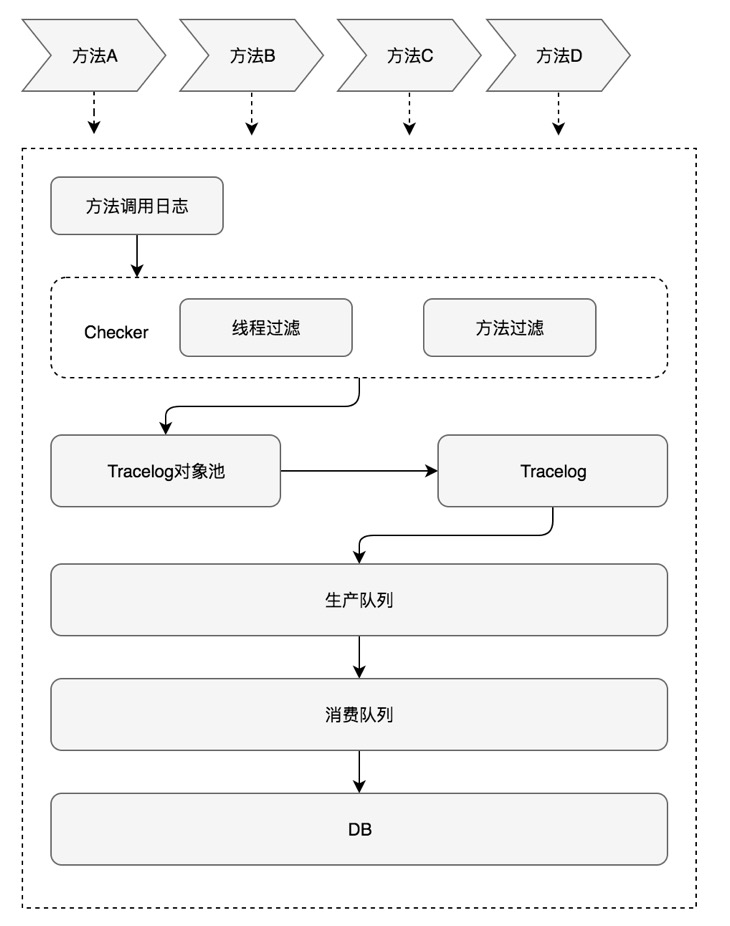
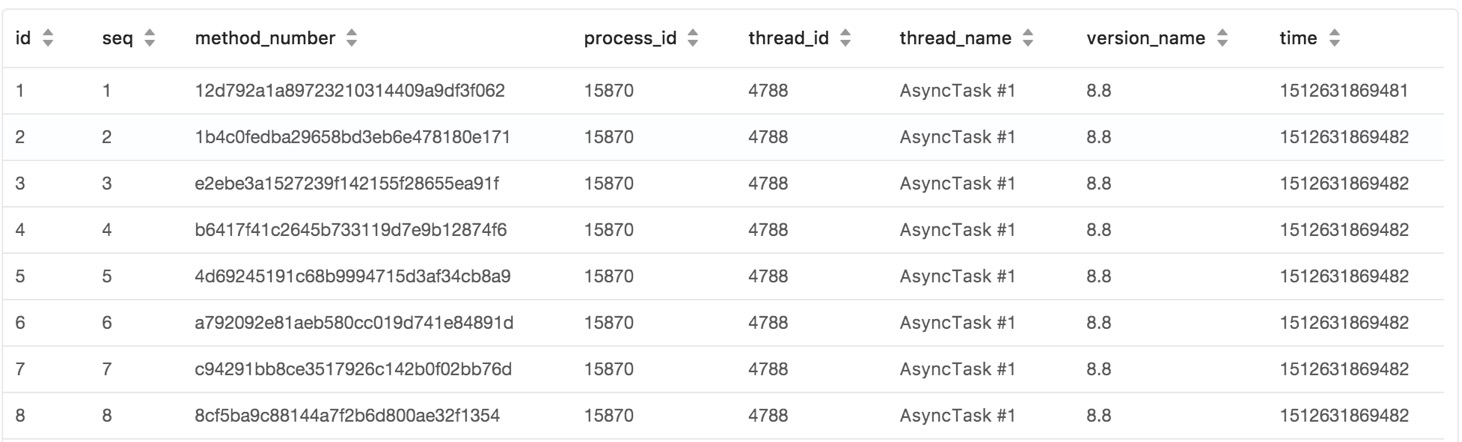
方法运行产生方法调用日志首先会经过checker进行检测,checker包含线程检测和方法检测(减少信息干扰),线程检测主要过滤类似于定时任务这种一直在不断的产生日志的线程,方法检测会在一定时间内检测方法调用的频率,过滤掉频繁调用的方法,方法如果不会被过滤就会进行异步处理,其次向对象池获取一个Tracelog对象,Tracelog对象进入生产队列组装时间、线程、序列号等信息,完成后进入消费队列,最后消费队列到达固定数量之后批量处理存入DB。
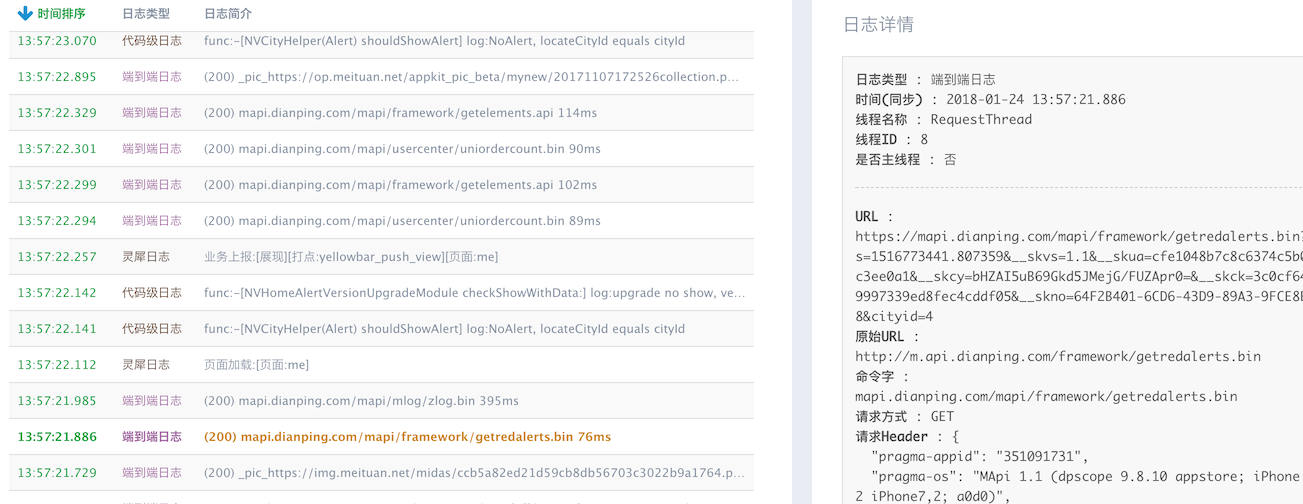
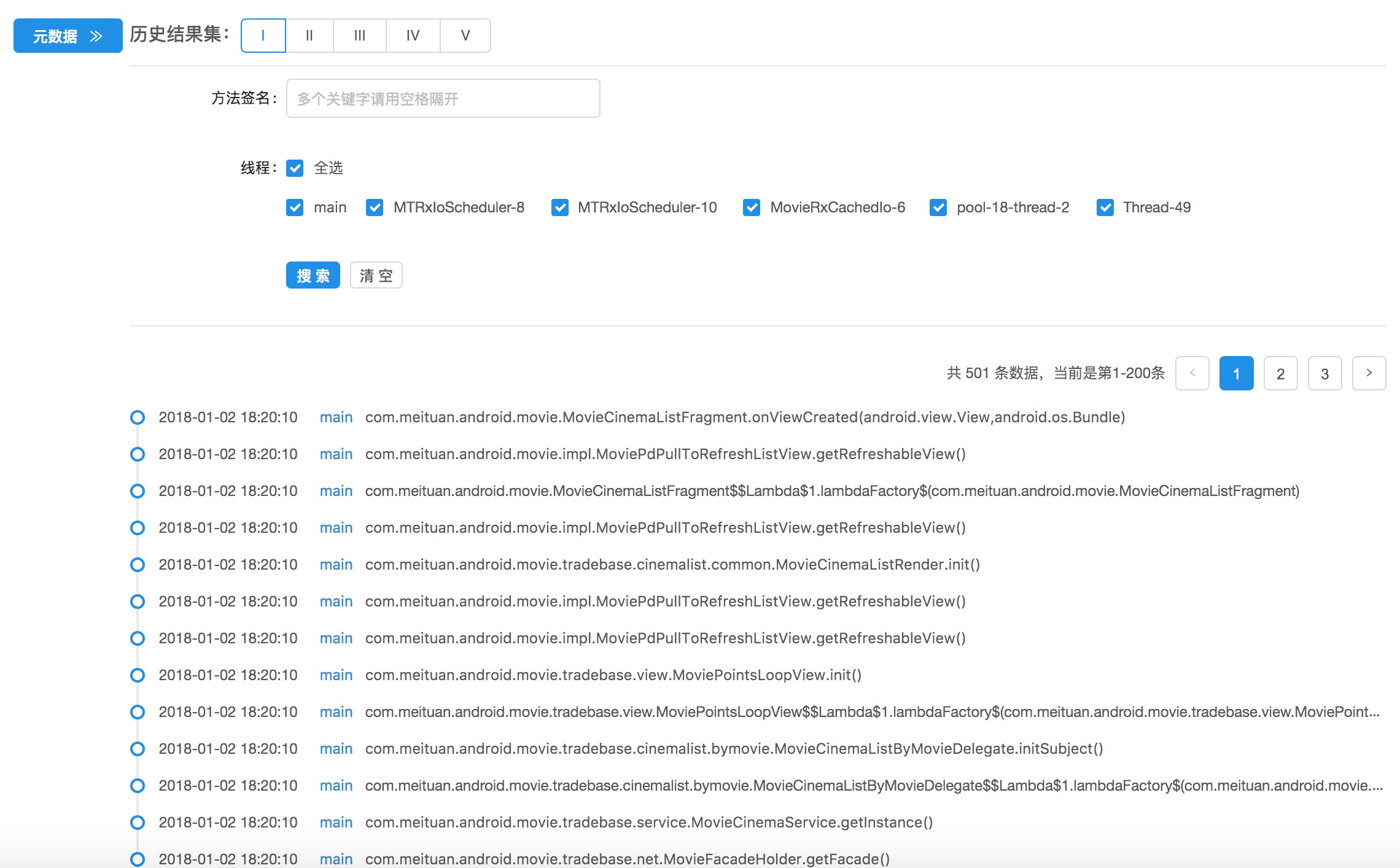
Tracelog数据展示
日志回捞到Trace平台上按时间顺序排列展示结果:
问题总结
我们的平台部署实施了几个版本,总结了很多的案例。经过实战的考验发现多数的场景下用户回捞Tracelog分析问题只能把问题的范围不断的缩小,但是很多的问题确定了是某一个方法的异常,这个时候是需要知道方法的执行信息比如:入参、当前对象字段、返回值等信息来确定代码的执行逻辑,只有Tracelog在这里的感觉就好比只差临门一脚了,怎么才能获取方法运行时产生的内存快照呢?这正是体现动态日志的动态性能力。
动态下发
对目标用户下发信令,动态执行一段代码并将结果上报,我们利用Lua脚本在方法运行的时候去获取对象的快照信息。为什么选择Lua?Lua运行时库非常小并且可以调用Java代码而且语言精简易懂。动态执行Lua有三个重要的时机:立即执行、方法前执行、方法后执行。
- 立即执行:接受到信令之后就会立马去执行并上报结果
- 方法前执行:在某一个方法执行之前执行Lua脚本,动态获取入参、对象字段等信息
- 方法后执行:在某一个方法执行之后执行Lua脚本,动态获取返回值、入参变化、对象字段变化等信息
在方法后执行Lua脚本遇到了一些问题,我们只在方法前插桩,如果在方法后也插桩这样能解决在方法后执行的问题,但是这样增加代码体积和影响proguard内联方法数,如何解决这个问题如下:
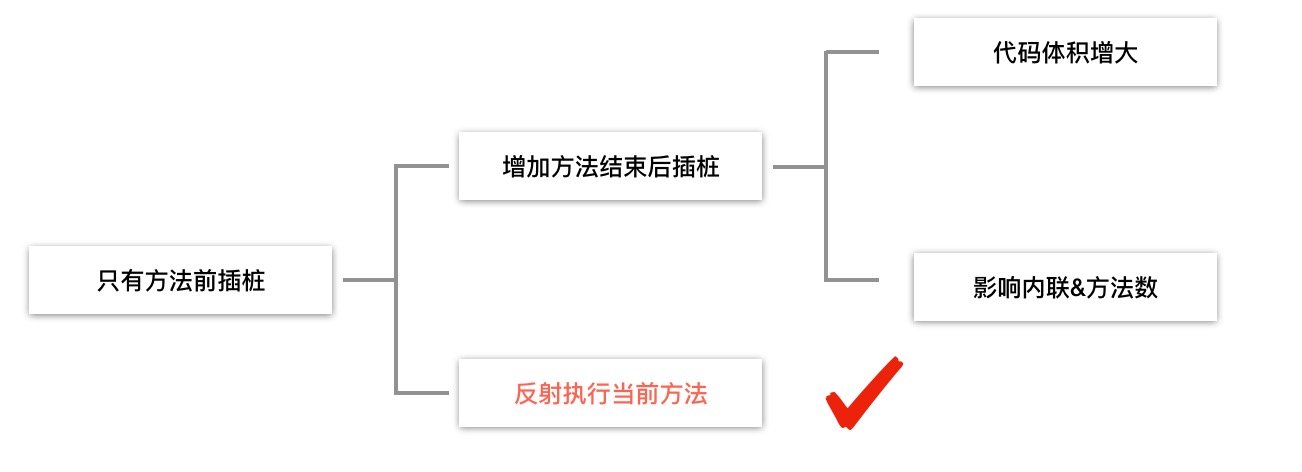
我们利用反射执行当前方法,当进入方法前面的插桩代码不会直接执行本方法的方法体会在桩代码里通过反射调用自己,这样就做到了一个动态AOP的功能就可以在方法之后执行脚本,同样这种方法也存在一个问题,就是会出现死循环,解决这个问题的办法只需要在执行反射的时候标记是反射调用进来的就可以避免死循环的问题。
我们还可以让脚本做些什么呢?除了可以获取对象的快照信息外,还增加了DB查询、上报普通文本、ShardPreferences查询、获取Context对象、查询权限、追加埋点到本地、上传文件等综合能力,而且Lua脚本的功能远不仅如此,可以利用Lua脚本调用Java的方法来模拟代码逻辑,从而实现更深层次的动态能力。
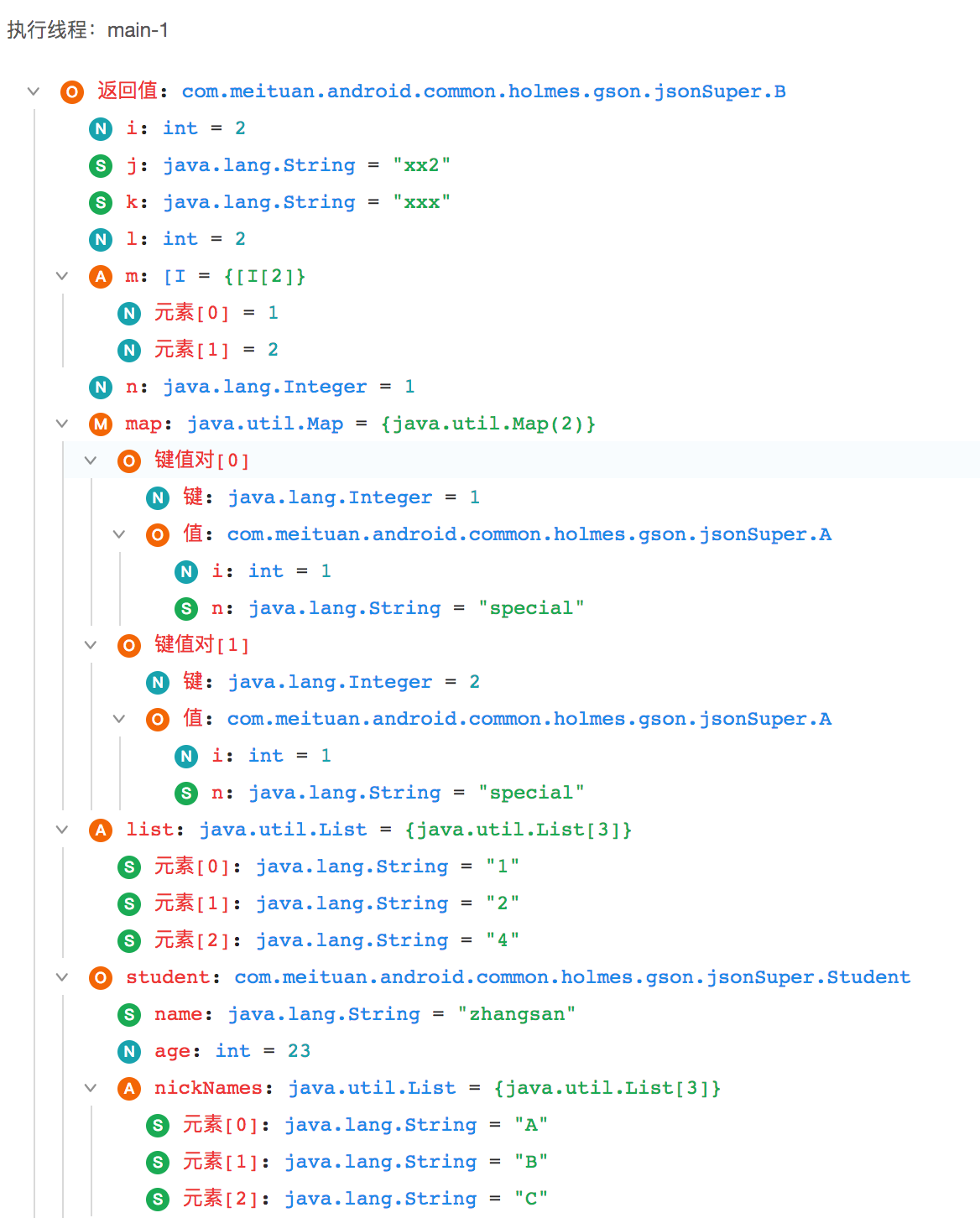
动态下发数据展示
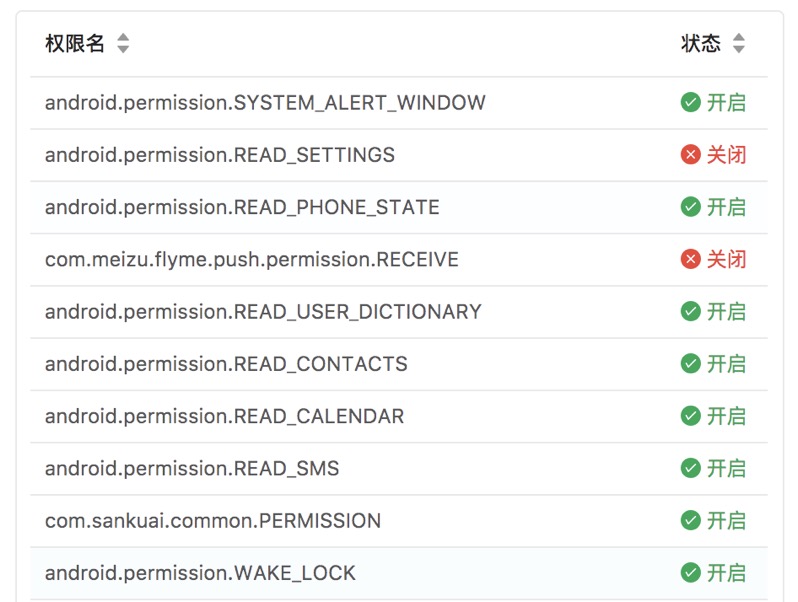
技术挑战
动态日志在开发的过程当中遇到了很多的技术难点,我们在实施方案的时候遇到很多的问题,下面来回顾一下问题及解决方案。
数据量大的问题
主线程卡顿
- 1. 由于同时会有多个线程产生日志,所以要考虑到线程同步安全的问题。使用synchronized或者lock可以保证同步安全问题,但是同时也带来多线程之间锁互斥的问题,造成主线程等待并卡顿,这里使用CAS技术方案来实现自定义数据结构,保证线程同步安全的情况下并解决了多线程之间锁互斥的问题。
- 2. 由于数据产生太多,所以在存储DB的时候就会产生大量的IO,导致CPU占用时间过长从而影响其他线程使用CPU的时间。针对这个问题,首先是采取线程过滤和方法过滤来减少产生无用的日志,并且降低处理线程的级别不与主线程争抢CPU时间,然后对数据进行批量处理来减少IO的频率,并在数据库操作上将原来的Delete+insert的操作改为update+insert。Tracelog固定存储30万条数据(大约美团App使用6次以上的记录),如果满30万就删除早期的一部分数据再写入新的数据。操作越久,delete操作越多,CPU资源占比越大。经过数据库操作的实际对比发现,直接改为满30万之后使用update来更新数据效率会更高一些(这里就不做太多的详细说明)。我们的优化成果从起初的CPU占比40%多降低到了20%左右再降到10%以内,这是在中低端的机器上测试的结果。
创建对象过多导致频繁GC
- 日志产生就会生成一个Tracelog对象,大量的日志会造成频繁的GC,针对这个问题我们使用了对象池来使对象复用,从而减少创建对象减低GC频率,对象池是类似于android.os.Message.obtain()的工作原理。
干扰日志太多影响分析问题
- 我们已经过滤掉了大部分的干扰日志,但还是会有一些代码执行比较频繁的方法会产生干扰日志。例如:自定义View库、日志类型的库、监控类型的库等,这些方法的日志会影响我们DB的存储空间,造成保留不了太多的正常方法执行路径,这种情况下很有可能会出现开发这关心的日志其实已经被冲掉了。怎么解决这个问题那?在插桩的时候可让开发者配置一些过滤或者识别的规则来认定是否要处理这个方法,在插桩的方法上增加一个二进制的参数,然后根据配置的规则会在相应的位上设置成0或者1,方法执行的时候只需要一个异或操作就能知道是否需要记录这个方法,这样增加的识别判断几乎对原来的方法执行耗时不会产生任何影响,使用这种方案产生的日志就是开发者所期望的日志,经过几番测试之后我们的日志也能保留住用户6次以上的完整行为,而且CPU的占用时间也降低到了5%以内。
性能影响
对每一个方法进行插桩记录日志,会对代码会造成方法耗时的影响吗?最终我们在中低端机型上分别测试了方法的耗时和CPU的使用占比。
- 方法耗时影响的测试,100万次耗时平均值在55~65ms之间,方法执行一次的耗时就微乎其微了
CPU的耗时测试在5%以内,如下图所示:
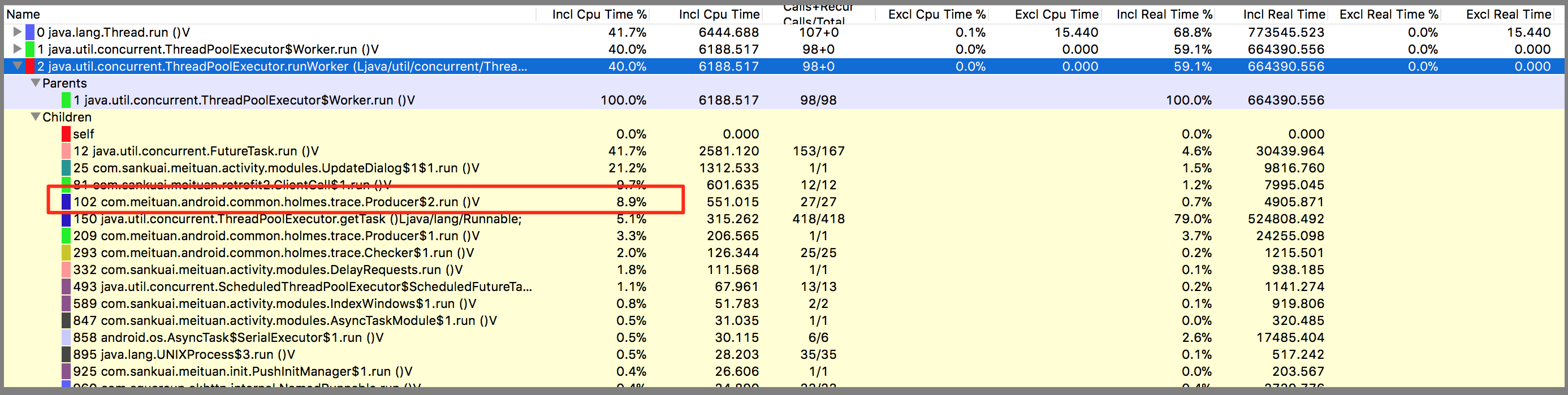
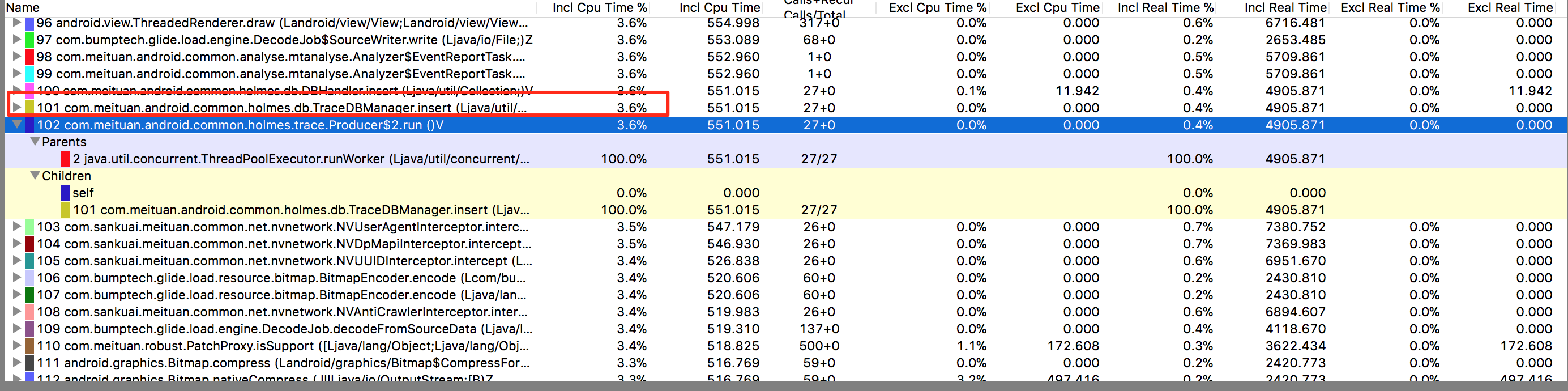
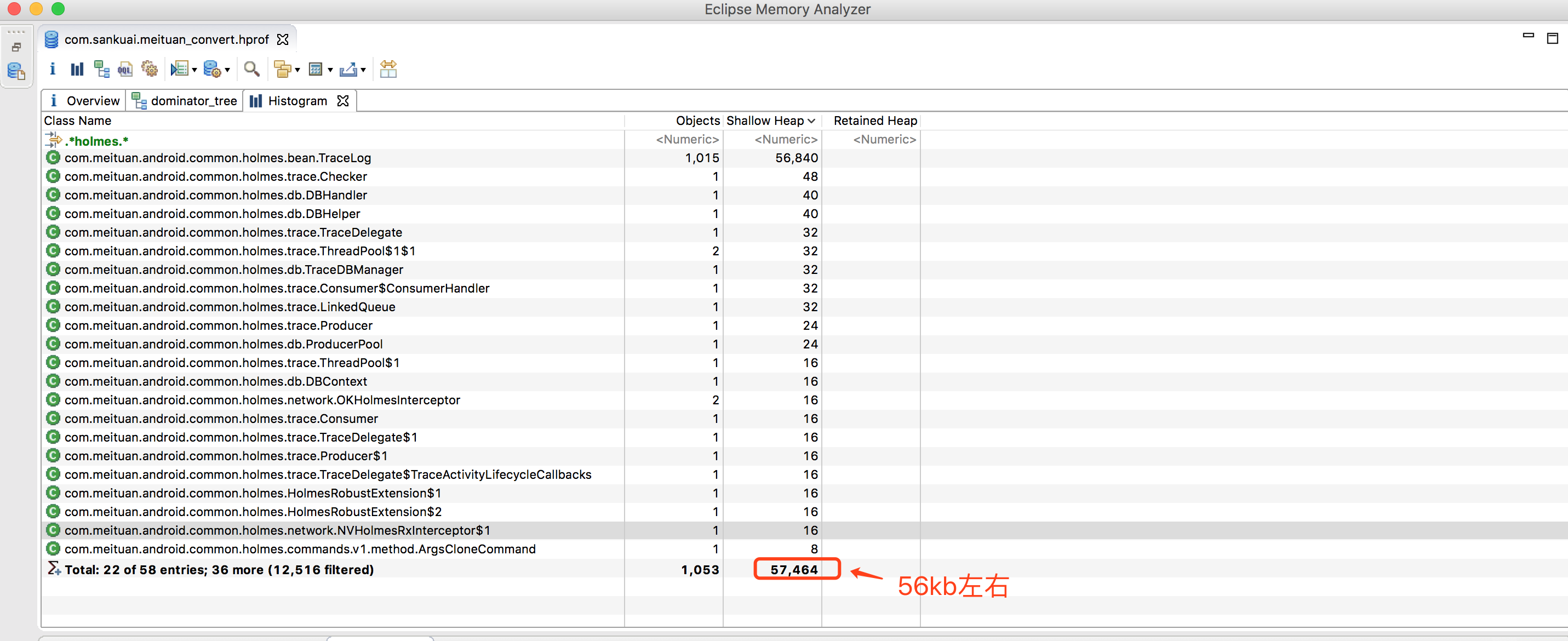
内存的使用测试在56kB左右,如下图:
对象快照
在方法运行时获取对象快照保留现场日志,提取对象快照就需要对一个对象进行深度clone(为了防止在还没有完整记录下来信息之前对象已经被改变,影响最终判断代码执行的结果),在Java中clone对象有以下几种方法:
- 实现一个clone接口
- 实现一个序列化接口
- 使用Gson序列化
clone接口和序列化接口都有同样的一个问题,有可能这个对象没有实现相应的接口,这样是无法进行深度clone的,而且实现clone接口也做不到深度clone,Java序列化有IO问题执行效率很低。最后可能只有Gson序列化这个方法还可行,但是Gson也有很多的坑,如果一个对象中有和父类一样的字段,那么Gson在做序列的时候把父类的字段覆盖掉;如果两个对象有相互引用的场景,那么在Gson序列化的时候直接会死循环。
怎么解决以上的这些问题呢?最后我们参照一些开源库的方案和Java系统的一些API,开发出了一个深度clone的库,再加上自己定义数据对象和使用Gson来解决对象快照的问题。深度clone实现主要利用了Java系统API,先创建出来一个目标对象的空壳对象,然后利用反射将原对象上的所有字段都复制到这个空壳对象上,最后这个空壳对象会形成跟原有对象完全一样的东西,同时对Android增加的一些类型进行了特殊处理,在提高速度上对基本类型、集合、map等系统自带类型做了快速处理,clone完成的对象直接进行快照处理。
总结
动态日志对业务开发零成本,对用户使用无打扰。在排查线上问题时,方法执行路径可能直接就会反映出问题的原因,至少也能缩小问题代码的范围,最终锁定到某一个方法,这时再使用动态下发Lua脚本,最终确定问题代码的位置。动态日志的动态下发功能也可以做为一种基础的能力,提供给其他需要动态执行代码或动态获取数据的基础库,例如:遇到一些难解决的崩溃场景,除了正常的栈信息外,同时也可以根据不同的崩溃类型,动态采集一些其他的辅助信息来帮助排查问题。
作者介绍
- 少飞,美团高级工程师,2015年加入美团,先后负责用户行为日志SDK、性能监控SDK、动态日志、业务异常监控
- 陈潼,美团资深工程师,2015年加入美团,先后负责代码静态检查、网络层优化、动态日志等基础设施开发工作
- 利峰,美团高级工程师,2017年加入美团,目前主要负责动态日志性能优化相关工作
招聘
美团平台客户端技术团队长期招聘技术专家,有兴趣的同学可以发送简历到:fangjintao#meituan.com。详情请点击:详细JD