OpenKG地址:http://openkg.cn/dataset/makg
GitHub地址:https://github.com/Everglow123/MAKG
MAKG网站:http://www.makg.com.cn
开放许可协议:CC BY-SA 4.0 (署名相似共享)
贡献者:东南大学(周恒、张步烨、谭亦鸣),南京邮电大学(李炜卓、季秋),之江实验室(那崇宁)
1. 开放背景
随着智能手机和移动设备的普及,移动应用(又称“APP”) 的数量迅速增长,为用户进行网上购物、教育、娱乐、理财等诸多方面提供了极大的便利。然而,随着越来越多的APP被开发与发布,网络上也存在诸多含有恶意风险的APP,它们或传播不良信息、或侵犯用户隐私,甚至违反国家信息安全法令。对普通的网民来说,构建全面的移动应用知识库信息有助于用户查询和预防APP的诈骗; 对网络安全分析人员来说,APP知识图谱不仅可以帮助网络安全分析人员更加快速地找出潜在风险,也可以在一定程度确保移动网络的安全。
2. MAKG介绍
在相关领域的研究中,DREBIN、AndroZoo++、AndroVault等APP知识库相继被提出。然而,这些知识库的构建仅侧重考虑了部分安卓应用市场的APP,存在来源单一、整体数据量少、属性不够全面等问题,从而无法全面地展示APP的信息。此外,由于已有的APP知识库重点聚焦在单个APP底层数据(如: 应用权限、应用隐私) 的分析上,导致此类方法在一定程度上缺少对APP之间的关联性分析,无法较好实现APP信息的共享与重用。因此,从多源异构数据中构建APP知识图谱,利用APP知识图谱的语义信息对APP进行大规模相关性分析对于APP的应用(如: 风险防控)显得至关重要,同时也能为语义网与网络安全社区研究提供高质量的数据资源。
MAKG (Mobile Application Knowledge Graph) 是一个基于自动化知识抽取算法与知识图谱对齐技术构建的移动应用知识图谱。由东南大学网络空间安全学院与南京邮电大学现代邮政学院贡献。MAKG开源了来自于华为应用市场、小米应用商店、App Store、Google Play四大移动应用商城共计34.7万移动应用(简称APP),包含700万三元组,提供.nt格式的数据下载。
3. MAKG构建
构建移动应用知识图谱具有诸多挑战。早年的英文知识图谱(如: CyC、WordNet) 以及中文知识库(如: HowNet) 大多通过专家手工构建,成本非常高昂。MAKG统一定义了轻量级本体,采用了知识抽取技术与知识对齐技术来补全与实现APP之间的关联,在缓解人工构建成本的同时,较好地为网络安全研究提供服务。相较于传统的概念知识图谱,MAKG的特点在于:
1) 通过爬虫技术收集了国内外应用商店的APP数据,百度百科、快懂百科中APP的infobox信息和摘要信息,网站新闻中有关于风险APP的信息,并根据这些信息统一设计了一个APP本体用以实现APP之间的关联。
2) 通过国际前沿的实体识别与关系抽取技术对APP中的非结构化信息描述进行知识抽取,实现APP信息的补全。
3) 通过国际前沿的实体对齐算法对不同数据源的APP信息进行知识的融合,构建了一个高质量的APP知识图谱。
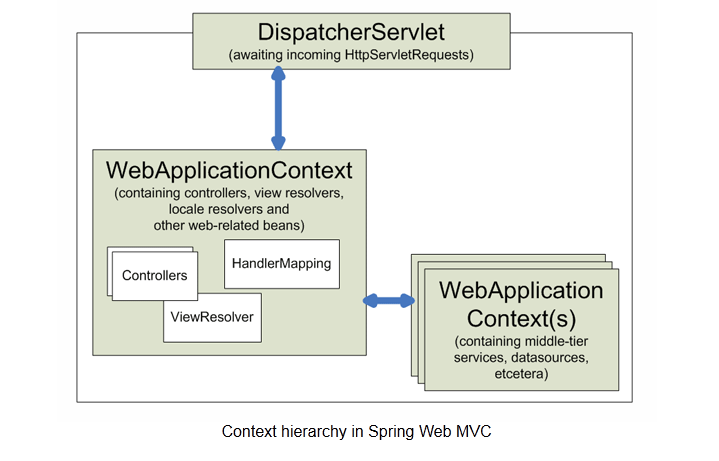
图1描述了MAKG构建的框架,主要包括五个阶段: 1)本体定义、2)APP爬取、3)知识抽取、4)知识对齐、5)知识存储。基于MAKG,网络安全分析师与用户可以获得更好的服务,如: 语义检索、推荐、风险检测等。

图1 MAKG的构建框架
本体定义:为了利用APP应用程序的信息来构建一个语义明确的知识图谱抽象层,我们首先设计了一个关于APP的本体,它主要定义了APP关系与属性层面的内容。在对现实的APP数据进行调研中,我们发现绝大多数针对APP的风险信息(如: APP的功能点、APP的交互模式等)并不能够从网络上直接获得。因此,我们基于现有概念化的技术研究选择了合适的术语,并通过斯坦福大学研发protégé定义MAKG中APP的关联关系与属性。

图2 轻量级本体概览
图2为我们定义的轻量级本体,其中红色边和蓝色边分别表示子类(subclassOf)和实例类型(rdfs: type)两个基本关系。此外,绿色边代表关系,紫色边代表属性。我们在本体中一共定义了26个基本概念、11个关系和45个属性。得益于定义良好的本体,不仅可以在查询过程中为APP在网络安全分析师和用户呈现更全面的属性,还可以在APP之间产生更多共享链接。
APP爬取:借助scrapy框架,我们爬取了华为应用市场、小米应用商店、App Store、Google Play发布的APP描述信息。由于一些应用市场(如: Google Play)并不提供APP的分类,所以我们在爬取的过程中将一些常见的APP当作种子,利用它们的推荐结果来爬取更多的同类APP。考虑到MAKG整体的存储大小,我们并没有下载APP的安装包,而是专注于它们在本体中定义的描述信息。表1列出了来自各应用市场的爬取应用的统计数据,其中,MKAG一共收集了超过34.7万个APP,生成了大约700万个三元组。可以注意到,由于Google Play为APP提供了多语言的描述,因此统计的APP数量相比其应用他商店更多。
表1 移动应用商店爬取的APP统计信息
移动应用商店 | 华为应用市场 | 小米应用商店 | APP Store | Google Play |
APP数量 | 43287 | 27694 | 3137 | 273802 |
APP关系 | 5 | 3 | 3 | 4 |
APP属性 | 14 | 12 | 5 | 15 |
实体数量 | 70954 | 47478 | 5724 | 382358 |
三元组数量 | 1384854 | 384648 | 25088 | 5210417 |
知识抽取:从应用市场爬取APP的描述信息是构建MAKG最直接的方法。然而,应用市场中现有的标签不足以覆盖我们设计本体中的属性,这阻碍了APP之间共享链接(又称实体)的进一步发现。为此,我们试图从百科全书(如: 百度百科、快懂百科)、文本描述以及网站上发布的APP相关新闻中收集相关的网页,以补全这些属性缺失的取值。
我们主要考虑以下策略来解析网页和文本描述,以获得结构化的应用三元组,并丰富其缺乏的价值。
infobox的补全。这是一种最为普遍的属性值补全技巧。我们采用字符串匹配方法(如: “基于编辑距离测度”)计算infobox中标签与设计的本体中属性的相似度,并进一步构造它们的对应关系(如: infobox中的市场与本体中的Platform)。
命名实体识别。对于本体中定义的概念(如: Developer和Company),我们评估了4种主流的命名为实体识别方法,最终选择了NcrfPP 模型来捕获应用程序的相关信息,该方法是一种以CRF推理层为基础,通过不同神经网络层结构快速实现的序列标记模型,并在我们的测试评估中获得最佳性能。
关系抽取技术。对于本体中的部分重要关系(如: 总部)和属性(如: 发布时间),我们分别采用了来自清华大学研发的OpenNRE与浙江大学研发的DeepKE平台中前沿的关系抽取模型进行测试,最终,我们在DeepKE平台中选取一种验证效果最佳的关系抽取模型CNN来抽取部分APP的结构化描述信息。同时,考虑到标注的语料库中存在部分关系仅有少量标注的关系,我们也尝试从清华大学研发的FewRel平台中利用少样本关系抽取技术进行知识的抽取与补充。
最终,我们从百度百科和快懂百科中分别检索到了2493和2503个APP,并在MAKG中添加了69092个结构化的三元组。同时,在命名实体识别和关系抽取的帮助下,我们针对MAKG的文本描述和百科全书中共补全了29651个三元组。
知识对齐:我们注意到大多数应用通常会发布在不同的移动应用商店,但对它们描述标签的具体取值可能是异构的。此外,不同的移动应用商店对APP关系和属性的描述方式也存在差异。因此,找出来自不同应用商店的APP以及相应实体之间的对应关系(又称匹配)至关重要,这样有助于APP信息的共享与重用。为了实现这一目标,我们尝试采用以下方法进行知识对齐。
基于规则挖掘器方法。它是一种半监督学习算法,用于迭代细化的匹配规则(如: EM迭代策略),并基于这些规则发现新的高置信度匹配。
基于知识图谱表示学习的方法。它将知识图的实体和关系编码在连续稠密的向量空间中,基于学习到的向量表示来度量实体的相似性。
基于上述知识对齐模型提及的算法(即, Rule Miner、NMN以及南京大学研发的OpenEA平台中MultiKE、RDGCN),我们最终获得应用市场之间的对齐。同时,手动校验它们对齐结果的正确性。表2列出了不同移动应用商店APP对齐的具体统计数据。由于目前APP Store爬取的APP数量远小于其他应用商店,因此,我们暂时没有列出它相应的结果。
表2 不同移动应用商店中等价实体的统计数据
应用商店 | 华为应用市场对应的 | 小米应用商店对应的 | Google Play对应的 |
华为应用市场 | — | 27397 | 1526 |
小米应用商店 | 27397 | — | 979 |
Google Play | 1526 | 979 | — |
知识存储:基于我们设计的本体,利用爬取的数据实例化关系与属性取值,并利用知识抽取和知识对齐来丰富知识图的结构化三元组。然后,通过Jena将它们转换为具有指定URL的结构化三元组{(h, r, t)}。对于知识存储,我们使用Neo4j来存储转换后的三元组,这是一种能够高效存储RDF三元组的图数据库,并提供配套查询语言Cypher。为了让MAKG与移动应用商店里的数据保持同步,我们定期更新APP的描述性信息,并记录更新到日志中。
4. MAKG的用途
目前,我们为MAKG列出了三种可能的应用场景:
1) MAKG可以实现基于APP的语义检索。比如: 用户查询一个APP,通过MAKG就可以向用户获得呈现该APP全面的信息。此外,我们还可以将实体链接技术应用到APP出现的文本描述中,特别是国家发布的APP整治新闻。受益于以上检索方式,用户可以更加充分了解APP的信息,避免下载一些有负面报道或者存在风险的移动应用。
2) MAKG可以帮助网络安全分析师检测一些敏感APP。相比于普通APP,这些APP拥有更多的条件或者可能性成为网络罪犯温床。借助于MAKG对APP全面综合的关系与属性描述,分析师可以定义一些先验规则或采用前沿的算法来评估APP敏感度并对其进行排序。这样,可以提前降低一些敏感APP所带来的风险,实现提前防控。
当用户和网络安全分析师请求上述服务时,MAKG可以为他们推荐一些类似的APP。利用一些高效的算法进行推荐,同样可以降低潜在风险,维护移动互联网的安全。
5. 结语及致谢
由于MAKG是基于自动化爬取算法从各大应用商店与网站进行获取的,其中难免存在数据爬取、处理上的问题,在此表达歉意。目前MAKG网站 (http://www.makg.com.cn/) 的测试版本已经对外进行开放,欢迎大家进行测试,提供宝贵意见。最后,感谢周恒、张步烨、谭亦鸣提供算法实现上的支持,周恒实现的在线服务平台,漆桂林教授、季秋博士、吴天星博士、高桓博士、李林、李学凯、李志强、许茜、罗安源、黄婉华、申时荣等给予技术上的宝贵建议。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。