文 | 水哥
源 | 知乎
Saying
1. embedding+DNN范式有两个流派,一个更关注DNN,叫逍遥派;一个更关注embedding,叫少林派
2. embedding+DNN这种结构中,embedding一般是模型并行;DNN一般是数据并行
3. 逍遥派能够创造奇迹,但是也很容易走上邪门歪道。一念成北冥神功,一念成化功大法
4. 少林派把汗水都洒在看不到的地方,但是在长期来看,我还是相信功不唐捐
这是【从零单排推荐系统】系列的第16讲。之前的铺垫是有点多了,现在终于进入到激动人心的DNN环节了。正如一个快要讲烂了的故事说的一样,先是CNN在CV上引发了行业的关注,然后NLP领域也有LSTM这样的工作,乃至后面的transformer。基于DNN的推荐系统现在也成为了标准结构。DNN在这几个领域的发展都很相似:
先有数据量,再有深度学习。正如有了ImageNet才能有AlexNet一样,当下恰好是一个内容分发,媒体平台的数据量爆炸的时代。因此DNN在推荐中才可以如此顺利,毕竟CNN是做了复杂度简化的,而MLP却没有。
登堂入室之前都会经历一个观望的阶段。早期CV界刚出AlexNet那几年,大家都负担不起显卡,也没几个实验室摸明白深度学习这一套怎么走下来。再加上传闻CNN不好收敛,对数据需求大(其实最后发现还好,小一点的数据集放开了训也不会怎么样)。所以那时候做法就比较保守,往往是用别人训好的CNN提取特征,再在本地训练类似SVM这样的分类器来做。在推荐这边也是类似,一开始DNN并不直接用来做预测,而是提取一些辅助的信息[1]。
Embedding+DNN的工业操作
在详细聊DNN发展的路径之前,我们还是要把现代工业的标准操作再做一个说明。现在的标准操作是:(1)对于所有特征,通过hash把它转化成一个ID;(2)对于每个ID,都用embedding look-up table把特征映射成一段固定长度的embedding(如果是序列化的可以pooling,或者做其他操作,后几讲会详细讨论);(3)把所有需要用到的特征的embedding拼接起来,作为DNN(一般是MLP)的输入,得到结果。
上面的流程可以大致总结embedding+DNN的主体架构,下面要介绍的工作有自己独特的地方,但都不会改变这个主体结构。细心阅读过一些论文的同学可能会发现上面提到的hash转化是之前没出现过的,和科研场景也有所不同。为什么是这样的形式我们会留到下一讲来说明。
youtube[2]方案
让DNN在推荐中走入大众视野,开始吸引人眼球的比较有名的工作,当属google的这篇Deep Neural Networks for YouTube Recommendations了。在下图中我们展示了其主体结构,除了输入的特征有一些设计(有的特征同时存在一次项,平方项和开根项)之外,还是遵循了拼接后进DNN的方式。
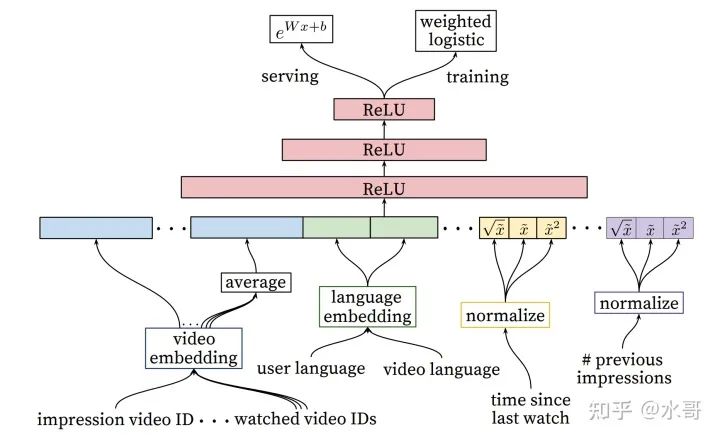
有两点需要特别说明。第一点是这篇文章同时提了召回+精排。召回的最终形式是一个单塔(因为item的embedding没有经过网络生成),而不是DNN直接预估点击。我们现在熟悉的双塔都用在召回上,按照复杂度从高到低应该是精排用DNN,粗排用DNN,召回用双塔。如果算力弱一点会是精排用DNN,粗排+召回用双塔。在这篇文章的设计里没有粗排。
第二点是我们之前提到过粗排学习目标,召回学习目标都是多变的,像这篇文章对召回的建模就是softmax做分类(后面再详细分析),唯独精排的学习目标一直没提。原因是之前两个都是序敏感,而精排(多数情况下)是值敏感。也就是说,召回粗排只需要知道谁先谁后就行了,但精排需要CTR,CVR那个具体的数字。很多地方都需要用这个预估数字,而这些数字是精排提供的。
举个例子,在广告竞价时是按照CTRxCVRxbid来竞价,而竞价体现了广告主愿意出的钱。如果某个广告的CTR高估了,该广告主很容易赢得竞价,也就要出更多的钱,但是实际上点击没有发生那么多,等于就多扣冤枉钱了。所以现在精排还是单点分类那样占主导(也可以在精排得到预估值后,再加其他序敏感的环节,在这里就不展开了)。这篇文章中对正样本做了额外的加权(按照实际观看时间,也就是,看得越长的,权重越大),其实会影响最后pctr的预估,但是看起来文章中涉及的场景也还是序敏感的。
其他方案
和上面方案有所不同的是其他环节的引入,比如Wide&Deep[3]就同时结合了LR和DNN。另外我们在推荐中使用FNN/PNN/ONN/NFM优化特征交叉 中也已经讲过DNN如何和FM结合。这部分的方案都比较简单且直观,就不展开了,下面两个主题是比较重要的。
工程上的特殊性
在2019年,Facebook发布了他们的DLRM框架,与之对应的论文:Deep Learning Recommendation Model for Personalization and Recommendation Systems[4]。原论文的图做的不太清楚,这里我们用网站上的:

图中的sparse feature指的就是我们最常见的各种ID,dense feature是数值型特征,我们之前称作numeric,有时候也叫连续特征(continuous)。各种ID可以用look-up table查找embedding,而连续特征是拼成一块,再经过MLP,就可以和查找后的embedding在形式上等价(都是浮点数向量)。Feature interaction这里是对所有的浮点数向量一视同仁,两两做内积,再把结果拼接作为MLP的输入。
虽然论文里一直在强调这个模型与其他模型的不同,但是读过之前FM那几讲的同学可能会有感觉在算法上没有什么独特的地方。处理连续特征那里确实其他文章没有明确提,但也是属于一个拍拍脑袋能想出差不多方案的实现。可能这篇文章更大的目的还是对PyTorch的宣传:PyTorch能做推荐哦,快来试试吧。u1s1如果能用PyTorch的话确实比较爽,TensorFlow静态图很难受,虽然现在有动态了,大多数公司也不支持。
Embedding+DNN这套体系中,目前为止介绍到的算法都比较初级。但是想要这套体系无往不利,更重要的是工程层面的优化:每一个特征都有一个embedding,百万,千万,甚至上亿的特征存在哪?如果要做一套分布式的训练机制,哪些部分应该存在一起?不同的实例之间应该如何通信?
模型并行与数据并行
在讲明白embedding+DNN的工程实现细节之前,我们先要讲分布式计算里面的两个基本概念:模型并行和数据并行。如下图所示:
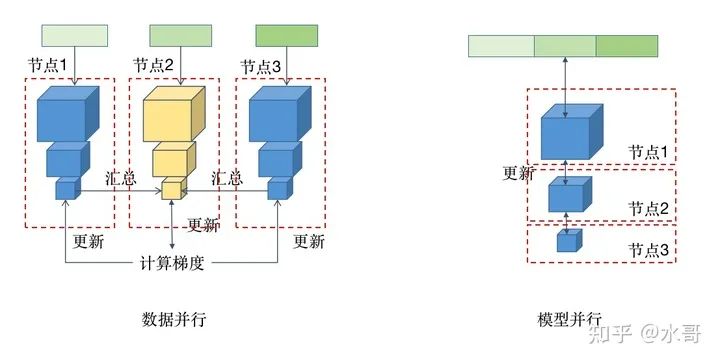
蓝色方块代表模型中的环节,绿色方块表示数据的一部分。节点就是机器,其中黄色的是总节点
数据并行:在每台机器上都有一个完整的模型,把一个大batch的数据分成多份分别给每个模型,对于模型的要求是参数得都保持同步。为了达到这个目的,forward的时候可以各做各的,但是在backward的时候需要互相传递参数和梯度,每个节点要把所有的梯度汇总后回传。通常比较简单的实现是有一个总的节点负责更新梯度,算好以后发送给大家去更新。
模型并行:当模型大到一个机器装不下的时候,把模型拆开,每一部分放在一个节点上。从输入端开始可以灌入全量数据,必须按照次序计算,backward的时候顺序则会倒过来。
我们的embedding+DNN范式是两种并行混着用的情况。embedding按照key-value这样的形式存在存储中,需要用的时候,key就是当前这个特征的ID,而value就是一段我们定义长度的向量。如果特征量很大的话,一台机器肯定是存不下的。实际中用的方式一般都是按照特征分别存在不同的CPU大内存机器中。比如第一台机器存User ID,第二台机器存Item ID这样,因此embedding这部分属于模型并行。下面DNN的部分一般来说单机都是放的下的,就是batch可能比较大,要拆开,因此DNN这部分则是数据并行。用原论文的图来解释一下:

上面是embedding部分,下面是DNN部分。按照上面的描述,这里有1,2,3三种特征,其中1全部放在Device1上,2,3也是同理。下面的DNN有三个实例,分别是蓝绿黄三种颜色。这三种颜色也对应一个batch内的三个小batch。需要用的时候,蓝色的DNN从3个embedding机器中分别取出属于它的数据对应的3种特征的embedding,完成自己的推断。另外两边也以此类推。
像这样的工程架构其实还延伸出很多可以做的事情:从embedding到DNN部分如何更加科学的通信,下面的DNN部分如何用GPU加速,embedding中如何设计特征的摆放更好等等。都是一些有意思的方向,也有很多公司有团队在做这些方面的探索。
在上面的介绍中,我们的主流范式分为两部分:embedding和DNN部分。以现在的眼光来看,DNN如果直接就3层MLP显得太简单了一些,很多新奇的结构都可以试一试,这样想的人,慢慢就形成了以DNN优化为主的“逍遥派”。另一波人认为推荐的关键还是在特征上,各种十年经验“调参仙人”对特征有着独到的理解。随着特征越加越多,DNN的输入也越来越宽,这就是“少林派”。在实际业务中,两个门派各自有得意的祖传技法,但也有各自的苦衷。
逍遥派——内卷的路上,不要忘了初心
秘籍:北冥神功,小无相功
弱点:内力(算力)有限,容易走上邪路
势力:随着深度学习的各种模型发力,势力明显提升
所谓逍遥派,就是要在DNN上尝试各种各样新奇的技术。眼观六路耳听八方,新出的技术一定要及时了解,并且往往都有很酷炫的名字(小无相功,凌波微步)。比如transformer我知道能用在NLP的序列中,那么推荐中也有用户的行为序列,就可以把transformer借助过来(北冥神功);再比如CV领域的自监督学习很火,我们也可以想办法把自监督学习的思想用在推荐领域。所以对于逍遥派弟子来说,只要这个领域还在发展,永远不会陷入没事情可做的境地,而且像transformer这样的技术确实也能在推荐中发挥很大的作用,能拿到很不错的收益。对于高手来说,有的模型变形不大,看起来是蜻蜓点水,然而效果却非常犀利。他们能把深度学习的很多技术和之前的机器学习技术都融会贯通(天山折梅手)。
但是逍遥派有一个弱点是,很多技术原生于CV,NLP等领域,这些技术发展的时候对于实时性没有那么高的要求。当借鉴过来的时候大多数情况都要直接面对时延的增长,即使这一次成功说服了大家部署上线了,后面的迭代也变得越来越慢(内力不足)。毕竟允许的时延总归有个上限,不能一直往上加。所以这一派越做,就越有点挖断后人路那么点味道(逍遥不动了)。
相对少林派来说,逍遥派的门槛其实要更低,这也导致他们是内卷大户。你能看paper,我也能看,你能实现一个新算法,我也能实现。所以经常看到的现象是新出现一篇paper有好几波不同的人都在做。这种赛马很折磨人,但是大家为了出效果完成KPI还是都会去做。如果失去管控,这个门派是最容易走上歪门邪路(星宿派):把不work的东西包装成有效果,把不必要的环节强行加进去等等,甚至吹吹捧捧(丁春秋)。在后面我们会探讨一下健康的迭代路径是怎么样的,但首先要知道,前面这两个都是极不健康的。
逍遥派其实是上限极高的一派,但是本质还是要实事求是+创新。看别的文章实现仅仅是初出茅庐的水平,如果你想在这一派中做到护法或者长老,应该对这个问题有自己的认识,有自己的理解。我希望这个专栏一些有点键盘侠的言论能启发读者对问题有自己的见解,这是成长中很重要的一步。
少林派——不能吹的痛,外人是否能懂?
秘籍:七十二绝技(特征)
弱点:锦衣夜行/怀才不遇
势力:硕果仅存的sql boys
既然逍遥派我们给定义到专注于DNN,那么少林派就定义为关注embedding部分了。关注的形式倒不是embedding本身的操作有什么差异,而是体现在特征的设计上。像我们之前在讲FM的时候,提到过实践中最好是能指出谁和谁交叉才是好的。这个技能一般人没有,但是少林派的高手有,而且有很多。所以其实少林派的门槛还是比较高的,做这些事情需要很深的业务积累(苦练内功)。另一方面,少林派做事情更加自然,更加贴合实际,要设计出好用的新特征其实是要仔细观察分析系统和模型的各种表现的。针对模型目前的弱点加以改进总是一种更实事求是的改进方式。
但是少林派正在遭受巨大的打击,随着行业内卷的加剧,方法的创新性变的非常重要。少林派要在实际业务中吃无数的亏,栽无数的跟头(十八铜人)。到最后功力终于大成了,用最简单普通的招式(罗汉拳)就能打出海量伤害了,还是会被人用“不就是加特征嘛”,“不就是sql boy嘛”给破防。另一边逍遥派可以发paper,搞宣传,给少林派真的是馋哭了。所以大批原本深入特征的少林派弟子纷纷“叛变”,加入逍遥派(neijuan)的怀抱。可以理解他们的委屈,只能说人在江湖,身不由己,打不过那就加入。
想要在少林派中成长到高手,必须耐得住寂寞。算法在学习的同时,也必须端正自己面对问题的态度,到最后会发现,即使是特征设计上,也能有拈花指,千手如来掌招式(这里可以牵强附会举例一下前面Facebook做GBDT那个工作,也是很有影响力的)。但是如果心态不正也会走上别的路子,正如扫地僧说的那样,越高深的武功越需要佛法来化解。
逍遥派的创新能力和少林派深入问题的态度值得所有人学习,对我们普通人来说,最好是同时具备这两派的优点。取百家之长,然后形成自己的风格,一句话概括下:
实事求是,有创新意识,以北冥神功才能驾驭少林七十二绝技。
下期预告
推荐系统精排之锋(11):再论特征与embedding生成
往期回顾
召回 粗排 精排,如何各司其职?
拍不完的脑袋:推荐系统打压保送重排策略
简单复读机LR如何成为推荐系统精排之锋?
召回粗排精排-级联漏斗(上)
召回粗排精排-级联漏斗(下)
推荐系统精排:看阿里妈妈再试线性模型
推荐精排之锋:FM的一小步,泛化的一大步
推荐中使用FNN/PNN/ONN/NFM优化特征交叉
聊聊推荐系统的高阶特征交叉问题
真正的高阶特征交叉:xDeepFM与DCN-V2
GBDT是如何成为推荐系统顶级工具人的?
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!

[1]Deep content-based music recommendation
[2]Deep Neural Networks for YouTube Recommendations,RecSys,2016 https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/45530.pdf
[3]Wide & Deep Learning for Recommender Systems https://arxiv.org/pdf/1606.07792.pdf
[4]Deep Learning Recommendation Model for Personalization and Recommendation Systems https://arxiv.org/pdf/1906.00091.pdf