项目官网地址
新手可以参考这篇 8、Getting Started With Titanic,教你如何操作、提交等
自己简要再记录一下:
- Join the competition
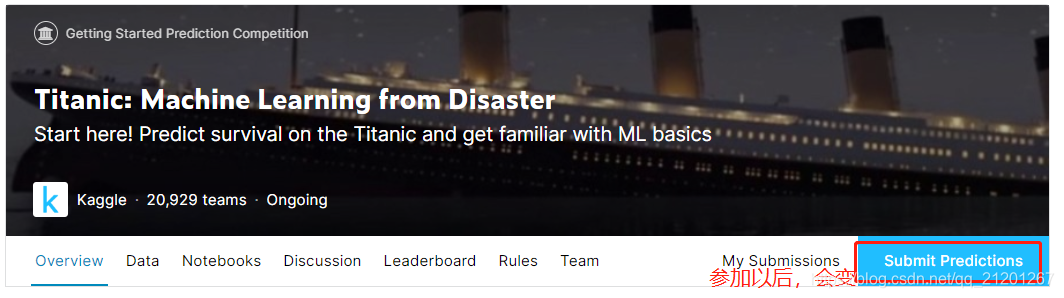
各个 tab 下可以查看数据Data、代码编写Notebooks、讨论、排名、比赛规则、队伍 - 点击 Notebooks,新建文件
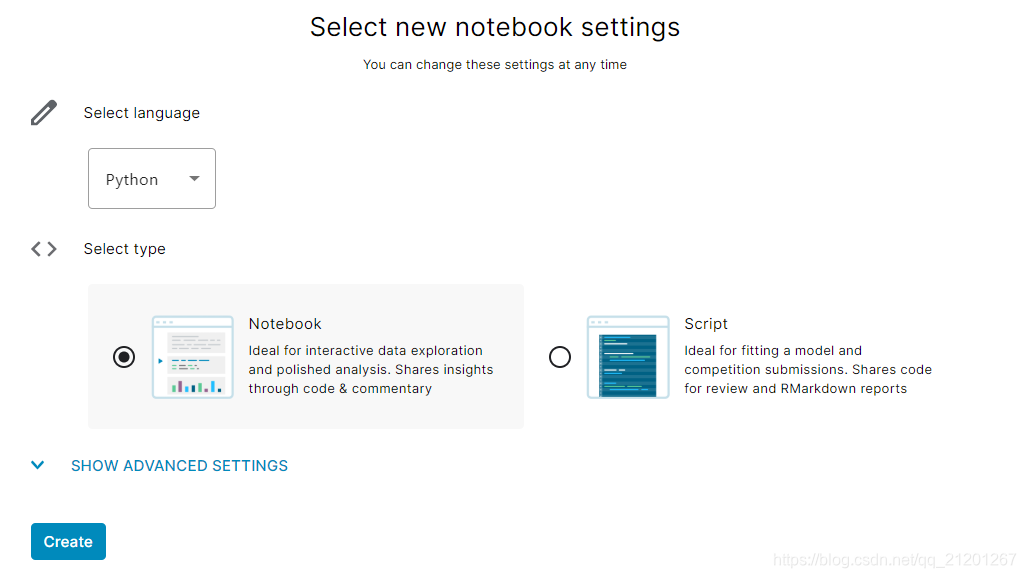
- 添加比赛数据集
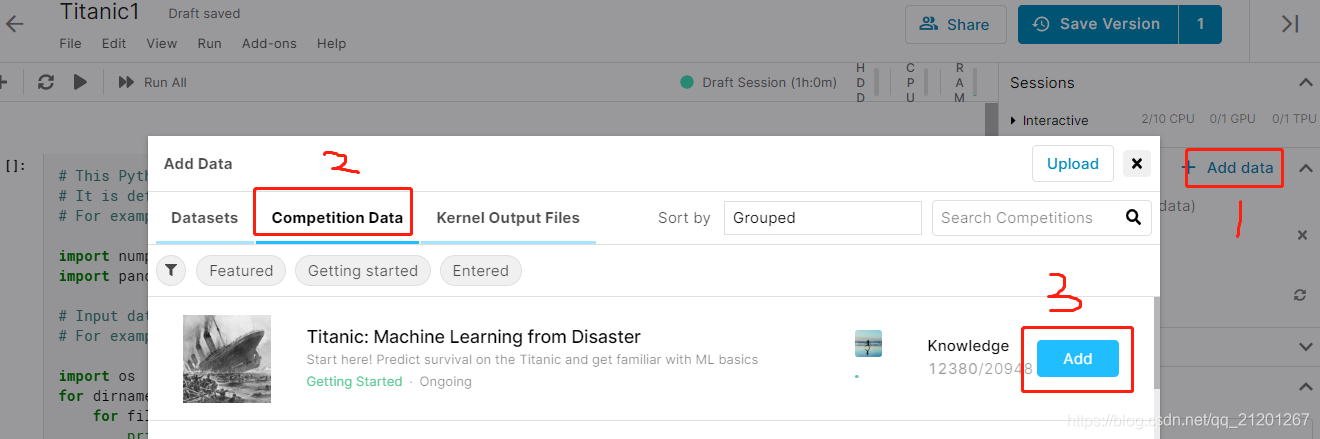
- 编写代码
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk('/kaggle/input'):for filename in filenames:print(os.path.join(dirname, filename))
# 读取数据
test_data = pd.read_csv("../input/titanic/test.csv")
test_data.head()
train_data = pd.read_csv("../input/titanic/train.csv")
train_data.head()# 简要的数据查看,分析男女生存状况
women = train_data.loc[train_data.Sex == 'female']["Survived"]
rate_women = sum(women)/len(women)
print("% of women who survived:", rate_women)men = train_data.loc[train_data.Sex == 'male']["Survived"]
rate_men = sum(men)/len(men)
print("% of men who survived:", rate_men)# 随机森林模型,选取4个特征
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])# get_dummies编码处理
X_test = pd.get_dummies(test_data[features])# 设置模型参数
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)#训练
predictions = model.predict(X_test)#预测# 输出预测文件
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
# 写入csv文件
output.to_csv('my_submission.csv', index=False)
print("Your submission was successfully saved!")
- 保存、运行
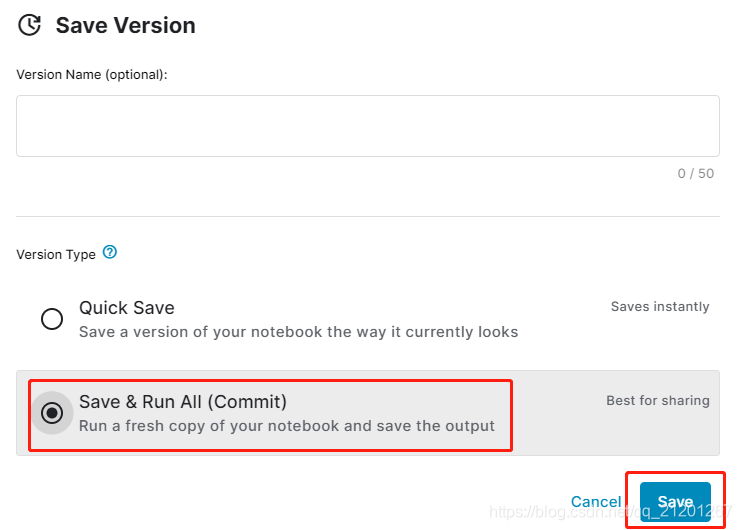

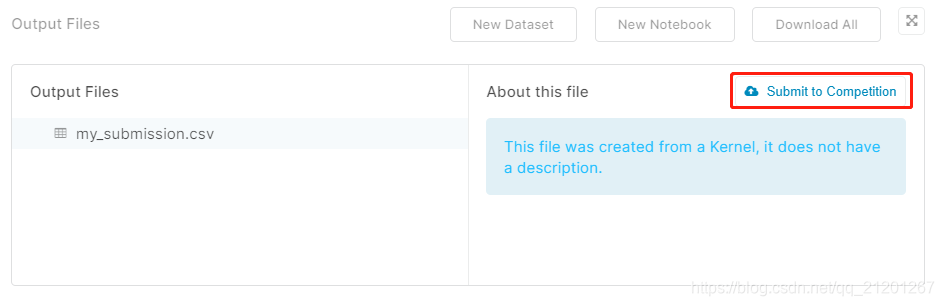
往下找到 output files
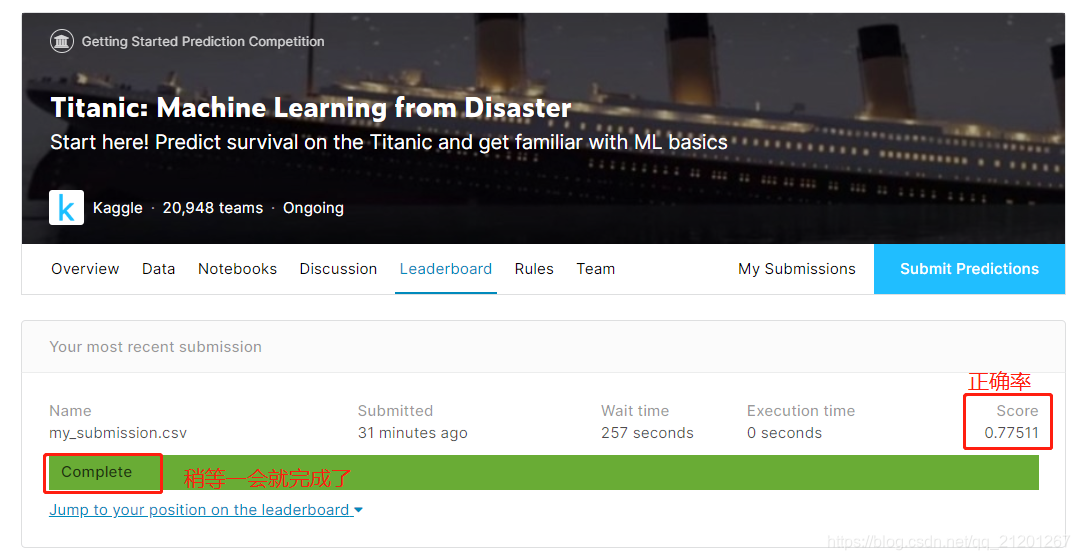
完成课程 Intro to Machine Learning,发了一张证书,哈哈,加油!




)


)

)


)
)


)



)