目录
Python基础(八)--迭代,生成器,装饰器与元类
1 迭代
1.1 可迭代对象与迭代器
1.2 自定义迭代类型
1.3 迭代合体
2 生成器
2.1 什么是生成器
2.2 生成器表达式
2.3 生成器函数
3 装饰器
3.1 闭包
3.2 什么是装饰器
3.3 装饰器的使用
3.4 含有参数的装饰器
3.5 保留函数信息
3.6 类装饰器
4 元类
4.1 什么是元类
4.2 自定义元类
Python基础(八)--迭代,生成器,装饰器与元类
1 迭代
1.1 可迭代对象与迭代器
简单的说在for循环中,进行遍历的对象,我们称其为可迭代对象,如序列,字典与集合类型。可迭代对象类型在collections.abc.Iterable类中定义,因此,我们往往可以通过某对象是否为Iterable实例的方式,来判断该对象是否为可迭代对象。
(1)Iterable类
Iterable类是一个抽象基类(父类),用来定义可迭代对象的规范,即可迭代对象应该具有的公共特征。该接口中定义了一个用来表示规范的方法(抽象方法):
def __iter__(self):用来返回一个迭代器,用来依次访问容器中的数据。迭代器其实就是一个数据流对象,可以连续返回流中数据。可以说,可迭代对象能够在for循环中遍历,底层靠的就是迭代器来实现的。
(2)迭代器
对于迭代器类型,是在collections.abc.Iterator中定义。该类型也是一个抽象基类,用来定义迭代器对象的规范,Iterator继承Iterable类型, 两个重要的方法如下:
def __next__(self):返回下一个元素,当没有元素时,产生StopIteration异常。
def __iter__(self):从父类Iterable继承的方法,意义与Iterable类中的__iter__方法相同,即返回一个迭代器。因为当前对象就是迭代器对象,所以在该方法中,只需要简单的返回当前对象即可:return self
正规来说,作为可迭代对象,需要实现__iter__方法(返回一个迭代器,用来遍历容器中的元素)或者__getitem__方法(返回self[key]的结果)。
注意:可迭代对象也可以不实现__iter__方法,而是实现__getitem__方法,与抽象基类Iterable中定义的行为不一致(Iterable中仅定义了__iter__方法)。实际上,这是由于历史原因造成的,保留__getitem__方法是为了做到兼容以前的实现。
# iterable类型的对象为可迭代对象,可迭代对象所属的类是iterable类型的子类
from collections.abc import Iterable
from collections.abc import Iterator
print(issubclass(bytes,Iterable))
print(issubclass(str,Iterable))
print(issubclass(list,Iterable))
print(issubclass(tuple,Iterable))
print(issubclass(dict,Iterable))
print(issubclass(set,Iterable))
# int不是可迭代对象
print(issubclass(int,Iterable))# Iterable与Iterator的区别:Iterable需要实现__iter__方法
# 而Iterator需要实现__iter__与__next__方法,所以所有的迭代器都是可迭代对象
print(issubclass(Iterator,Iterable))# 任何的可迭代对象都具有迭代器,可以通过iter内建函数获取一个可迭代对象的迭代器
li = [1,2,3]
it = iter(li)
# 虽然我们可以直接调用可迭代对象的__iter__方法获取迭代器,但是我们通常不这么做
li2= [4,5,6]
it2 = li.__iter__()
# __next__返回迭代器的下一个元素
print(it2.__next__())
print(it2.__next__())
(2)for循环内部的工作方式
在使用for循环来遍历容器中的元素时,底层会调用iter函数,来返回容器的迭代器。iter函数首先检查类是否实现__iter__方法,如果实现,则调用该方法,返回迭代器。否则,会创建一个迭代器,然后调用__getitem__方法依次获取元素。如果以上两个方法都不存在,则表示当前对象并不是一个可迭代对象,因此也就不能放在for循环中使用(产生错误)。
在遍历容器中的元素时,会调用迭代器的__next__方法,返回下一个元素,如此反复执行。当没有可用的元素时,迭代器会产生StopIteration异常,而这个异常,会由for循环内部进行捕获,无需我们显式处理。
# for循环底层也是通过__iter__方法,获得可迭代对象的迭代器,然后调用迭代器对象的
# __next__方法返回容器(可迭代对象)中的元素。如果迭代器没有元素产生异常,for循环内部
# 会对该错误进程处理,保证不会让错误传播到for循环之外
li = [1,2,3,4]
# it = iter(li)
it = li.__iter__()
while True:try:# item = next(it)item = it.__next__()print(item,end = "\t")except StopIteration:del itbreak
![]()
(3)一次性迭代器
对于迭代器,如果我们只想获得下一个元素而不是遍历,可以调用__next__方法而实现,不过,我们往往不会直接调用Python中的特殊方法,内建函数next可以帮助我们获取迭代器的下一个元素,next在内部会调用迭代器的__next__方法。同时,我们需要注意,迭代器只能迭代一轮,也就是说,如果容器中已经没有可用的元素,则迭代器就不能再次使用了(再次调用next函数获取下一个元素会产生异常),如果想要重新进行迭代,需要再次调用iter函数获取一个新的迭代器对象。
# 迭代器是一次性的,只能通过迭代器对象遍历一次,当迭代器没有元素,迭代器对象就不可用
li = [1,2,3]
# 遍历可迭代对象
for item in li:print(item,end="\t")
print()
for item in li:print(item,end="\t")
print()
# 遍历迭代器
it = iter(li)
for item in it:print(item,end="\t")
# 无法再次循环,因为第一次循环的时候迭代器就已经消耗完了
for item in it:print(item,end="\t")

注意:可迭代对象与迭代器都有__iter__方法,能够返回迭代器。对于可迭代对象,__iter__方法每次都能返回一个新的迭代器能够重新遍历;而对于迭代器,__iter__方法每次返回自身,不能够进行重新遍历
1.2 自定义迭代类型
自定义的迭代类型也可以不继承Iterable或者Iterator,只需要满足抽象基类定义的规范,这样的类型就会成为Iterable或者Iterator的子类型。即:如果自定义可迭代对象类型,需要实现__iter__方法,如果自定义迭代器,除了实现父类中的__iter__方法外,额外实现__next__方法。
# 可迭代对象Iterable或迭代器Iterator是抽象基类,不需要显示去继承,只需要满足抽象基类的规范
# (实现其所规定的方法),就可以自动被issubclass与isinstance所识别
# 成为可迭代对象,需要在类中定义__iter__方法,返回一个迭代器
from collections.abc import Iterable,Iterator
class MyIterable:def __iter__(self):self.li = [1,2,3]return MyIterator(self.li)
# 成为迭代器,需要在类中定义__iter__(返回迭代器,直接返回自身)与__next__方法(返回下一个元素)。
class MyIterator:def __init__(self,arg):self.li = argself.index = 0def __iter__(self):return selfdef __next__(self):if self.index < len(self.li):r = self.li[self.index]self.index += 1return relse:raise StopIterationm = MyIterable()
it = m.__iter__()
print(it.__next__())![]()
1.3 迭代合体
Python在实现序列等类型时,将其设计为可迭代对象,但是却不是迭代器,如果二者可以合体程序就可以不用再定义一个新的迭代器类,直接在可迭代对象的__iter__方法中返回自身(self),然后同时实现__next__方法不就可以了吗?
因为要是这样做的话就没有办法对可迭代对象进行重复性的遍历
# 将MyIterable可迭代对象直接设计为迭代器
class MyIterable:def __init__(self):self.li = [1, 2, 3]self.index = 0def __iter__(self):return selfdef __next__(self):if self.index < len(self.li):r = self.li[self.index]self.index += 1return relse:raise StopIteration
m = MyIterable()
for item in m:print(item,end="\t")
for item in m:print(item)![]()
2 生成器
2.1 什么是生成器
生存器类似于生产数据的工厂。在工作方式上,生成器不会预先准备好所有的数据,而是在需要时,每次仅生成一个数据。这样,在处理大量数据时,也不会占用大量的内容空间。我们可以使用两种方式来创建生成器:①生成器表达式②生成器函数
2.2 生成器表达式
生成器表达式的语法非常简单,只需要将列表推导式的中括号改成小括号就可以了。
# 生成器表达式
li = (i + 1 for i in range(10))
print(type(li))
# 对于列表,可以看到列表中所有元素的值,生成器看不到,因为生成器是
# 一种惰性计算方式,仅当我们请求时才会计算数据,不会一次性计算所有的数据
print(li)
# 通过for循环采集生成器数据
for item in li:print(item,end="\t")# 生成器是一种特殊的迭代器,所有的生成器都是迭代器(生成器是迭代器的子类型)
from collections.abc import Iterator
print(isinstance(li,Iterator))
print(issubclass(type(li),Iterator))
# 生成器因为是迭代器,所以具有迭代器的特征
li2 = (i + 1 for i in range(10))
print(next(li2))
print(li2.__next__())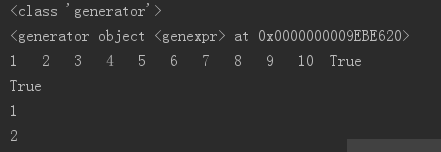
2.3 生成器函数
当数据集计算比较简单时,使用生成器表达式是一个不错的选择。但如果数据集的计算方式较为复杂,我们也可以使用生成器函数来实现。在生成器函数中,使用yield关键字来生成一个值,并将该值返回给生成器的调用端,格式为:
yield [生成的值]
这种语法,我们称为yield表达式。其中,生成的值是可选的。
生成器函数与普通的函数非常相似,从形式上,只是使用yield代替了return而已,如果函数中出现该关键字,则表示该函数为生成器函数。
生成器函数普通的函数的差异:
①对于普通函数,当调用函数时,就会执行函数体。对于生成器函数,当调用函数时,不会执行函数体,而是返回一个生成器对象,当调用生成器对象的__next__等方法时,才会执行函数体。
②对于普通函数,每次调用都会进行初始化。对于生成器函数,当调用__next__等方法时,遇到yield等就会暂停执行,将yield后面的值返回给调用端,暂停执行时,生成器函数内部的状态会保存,当再次调用生成器对象的__next__等方法时,就会从刚才yield暂停的位置继续执行
# 生成器函数
def builder():a = 1for i in range(10):# 生成器函数使用yield来生成一个值给调用端yield aprint("暂停")a = a + i
# 普通函数
def normal():print("普通函数")
b = builder()
# 生成器作为特殊的迭代器,当迭代器无法迭代时,会产生StopIteration异常,生成器也有这个特征
print(b.__next__())
print(b.__next__())
生成器函数的yield表达式:
生成器函数除了可以使用yield产生一个值,同时yield表达式本身还具有一个值。当调用__next__方法时,生成器函数体就会执行,除此之外,当调用生成器对象的send方法时,会执行生成器的函数体。send方法的返回值也是yield产生的值。
__next__与send不同之处在于:send方法除了可以获取生成器对象产生的值,还可以向生成器对象传递值,传递的值作为yield表达式的值。
yield表达式的值取决于客户端调用的反复噶,如果客户端调用的是__next__方法,则yield表达式的值为None,如果客户端调用的是send方法,则yield表达式的值为send方法传递的参数值。
# 生成器函数的yield表达式
def builderYield():for i in range(10):value = yield iprint(value)
b = builderYield()
# 第一个必须发送None 否则TypeError: can't send non-None value to a just-started generator
print(b.send(None))
print(b.send("给生成器传递一个值"))
print(b.send("给生成器传递另一个值"))
# 相当于调用send(None)
print(b.__next__())# 使用生成器获取生成器产生的值,并给生成去发送值,实现客户端和生成器的交互
import time
def builder():a = 0while True:value = yield atime.sleep(1)if value == "增加":a += 1if value == "减少":a -= 1
b = builder()
value = b.send(None)
data = ""
while True:print(value)if value == 0:data = "增加"elif value == 3:data = "减少"value = b.send(data)
3 装饰器
3.1 闭包
(1)什么是闭包
闭包:是指内部函数引用(访问)外围函数中定义的变量,对于内部函数来说就是闭包。所以闭包是发生在函数嵌套的场合中。
从代码实现的角度,通常会定义嵌套函数,然后将内部函数作为外围函数的返回值,返回给函数的调用端,供调用端多次调用执行。
(2)闭包的作用
①当内部函数执行结束时,执行函数所引用的外围函数中定义的变量状态(值)依然可以保留下来,当下一次调用内部函数时,外围函数中的变量依然是内部函数上一次离开时的值
②内部函数的名称处于局部命名空间中,这样就不会对外面的命名空间造成影响。
# 闭包
def outer():num = 0def inner(name):nonlocal numnum += 1print(f"数字为{num},名字为{name}")return inner
o = outer()
o("refuel")
o("refuel")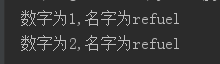
3.2 什么是装饰器
装饰器,用来处理被其所装饰的函数,然后将该函数返回。从实现的角度讲,装饰器本身也是一个函数,其参数用来接收另外一个函数,然后返回一个函数,返回的函数与参数接收的函数可以相同,也可以不同。装饰器本质上是一个函数或类,能够在不修改现有函数代码的情况下,对现有函数的功能实现扩充。
def decorator(函数1):
return 函数2
装饰器使用的,就是闭包的思想。当定义好一个装饰器(函数)后,就可以使用如下的语法来修饰另外一个函数
# decorator为装饰器函数名。
@decorator
def fun():
pass
经过这样修饰后,在任意调用fun函数的位置:fun() 就相当于执行:fun = decorator(fun) 这与我们之前使用闭包的形式是一样的。
装饰器的好处:装饰器的优势在于:我们可以在不修改现有函数的基础上,对其进行的扩展,增加额外的功能。一个装饰器可以用来修饰多个函数,这样,我们就可以避免代码的重复,有利于程序的维护。
3.3 装饰器的使用
(1)装饰器
# 装饰器
import datetime
def outer(fun):def inner(name):print(datetime.datetime.now())fun(name)return inner
# 相当于walk = outer(walk)
@outer
def walk(name):print(f"{name}走路")
# 相当于run = outer(rum)
@outer
def run(name):print(f"{name}跑")
walk("refuel")
run("refuel")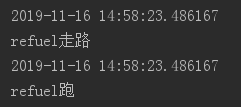
(2)装饰器优化
①装饰器使用参数接收的函数,可能是具有返回值的,因此,我们在内部函数中,不应该仅仅只是调用参数接收的函数,还应该将参数接收函数的返回值作为内部函数的返回值而返回。
②装饰器可能会用来修饰很多函数(对很多函数进行功能扩展)。
# 装饰器优化:
# 1、将装饰器改成万能参数列表 2、对原来的函数(装饰器修饰的函数)返回值进行处理
def outer2(fun):def inner(*args,**kwargs):# fun(*args,**kwargs) 会丢失原函数的返回值return fun(*args,**kwargs)return inner(3)叠加装饰器
在开发项目时,因为需求的不确定性,业务的不断发展,功能的不断扩充等诸多原因,我们很难做到一步到位,因此,我们可能对现有功能不止一次的进行扩展。此时,我们可以对装饰器进行叠加,以便于对功能进行多次扩展。格式如下
@decorator1
@decorator2
def fun():
pass
叠加修饰后,就相当于执行:
fun = decorator2(fun)
fun = decorator1(fun)
# 叠加装饰器
def outer(fun):def inner(*args,**kwargs):print("第一个装饰器")return fun(*args,**kwargs)return inner
def outer2(fun):def inner(*args,**kwargs):r = fun(*args,**kwargs)print("第二个装饰器")return rreturn inner
@outer2
@outer
def walk(name):print(f"{name}走路")
walk("refuel")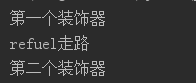
3.4 含有参数的装饰器
我们使用装饰器完美的实现了需求。但是,输出的结果含有微秒,这可能并不是所有人都想要的。因为装饰器的参数是固定的(装饰器所修饰的函数),可以再定义一层函数,用来接收装饰器的参数,然后返回装饰器。这样,返回的装饰器就会停留在我们需要修饰的函数上,继续修饰对应的函数。
# 含有参数的装饰器
# 因为装饰器的参数是固定的(装饰器所修饰的函数),可以在装饰器外层再定义一层函数
# 然后根据函数的参数,返回它的功能的装饰器
import datetime
def outer_arg(format):def outer(fun):def inner(*args, **kwargs):print(datetime.datetime.now().strftime(format))return fun(*args, **kwargs)return inner# 将装饰器作为函数的返回值return outer
@outer_arg("%Y%d%m%H%M")
def walk(name):print(f"{name}走路")
walk("refuel")![]()
3.5 保留函数信息
我们可以使用functools.wraps来解决,wraps接收一个函数,可以将接收函数的元信息复制到其所修饰的函数中。
def outer(fun):def inner(*args, **kwargs):return fun(*args, **kwargs)return inner
@outer
def walk(name):print(f"{name}走路")
walk("refuel")
# 返回函数的名字
print(walk.__name__)
# 返回函数的说明文档
print(walk.__doc__)
# 返回函数的注解
print(walk.__annotations__)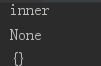
注意:函数经过装饰器修饰之后,返回的函数不在是装饰器之前的函数,因此原函数的元信息(名字,说明文档,注解等)都会丢失
from functools import wraps
def outer(fun):# 保留原函数的元信息# 将wraps参数指定的函数的元信息复制给@wrap所修饰的函数# 这里就是将fun函数的元信息复制给inner函数@wraps(fun)def inner(*args, **kwargs):return fun(*args, **kwargs)return inner
@outer
def walk(name:str)->None:"""函数的说明文档"""print(f"{name}走路")
walk("refuel")
# 返回函数的名字
print(walk.__name__)
# 返回函数的说明文档
print(walk.__doc__)
# 返回函数的注解
print(walk.__annotations__)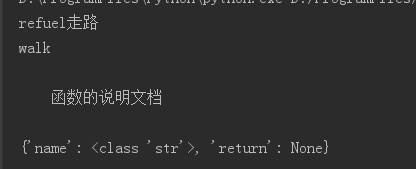
3.6 类装饰器
装饰器不仅可以是函数,只要是可调用的对象,就能够成为装饰器。在Python中,类也是对象(一切皆为对象)。而调用类时,返回的其实就是类所创建的对象。因此,类也可以成为装饰器。
# 类装饰器
class outer:def __init__(self,fun):self.fun = fun# 定义了__call__方法后,创建的对象就可以像函数一样调用def __call__(self, *args, **kwargs):return self.fun(*args, **kwargs)
@outer
def walk(name):print(f"{name}走路")
walk("refuel")![]()
4 元类
4.1 什么是元类
我们使用class关键字来定义一个类,并且可以在类体中来定义类的成员。不过,在Python程序中,一切皆为对象,因此,我们通过class来定义的类,也是对象。既然类本质上也是一个对象,那类就可以应用到对象可以应用的一切场合中。例如:赋值,打印输出,作为参数传递等。
因为类也是一个对象,故对象具有的能力,类也同样具备。我们定义类,可以用来创建对象。或者说,对象是类来创建的,那么,类既然也是一个对象,类是由谁来创建的呢?答案就是——元类。
可以通过type函数来获取一个对象所属的类型,既然类也是一个对象,那我们将类传递到type函数中,就可以得知类这个对象所属的类型,即类是由谁来创建的。作为一个类对象,所属的类都是type。这也就说明,这些类都是由type来创建的。
之前将type当成函数看待,其实,type是一个类,该类除了可以返回一个对象所属的类型外,还可以用来创建一个类型,而type类本身,就是创建类的类,这种类型,我们将其称为元类。所谓的元类,就是可以创建其他类的类,每一个由元类type所创建的类型,都是元类type的一个对象。Python语言规定,type元类依然是由type元类所创建。
我们可以通过如下的方式来创建类:变量名 = type(类名(字符串类型), 所有父类(元组类型), 属性与方法(字典类型))
type创建类型的参数。参数1:类的名字(str类型), 参数2:所有继承的父类(元素为类的元组类型),如果继承object,可以传递一个空元组
参数3:类所关联的属性与方法(字典类型)。
如:Bird = type("Bird", (object,), {"desc": "鸟类"}) 这样,就创建了一个type类型(元类)的对象,即Bird类。这与我们使用如下的class来定义类是等价的(class定义类时,也是创建一个type元类的对象):
class Bird:
desc = "鸟类"
# 元类:创建其他类型(对象)的类
print(type(list()))
print(type(list))
print(type(type))
# 对象是由类创建的,类是由元类创建的,元类还是元类创建的# type的两种用法:
# 1、一个参数:传递一个对象,返回该对象的类型
# 2、三个参数:用来创建一个类型。参数1:类的名字(str类型),
# 参数2:所有继承的父类(元素为类的元组类型),如果继承object,可以传递一个空元组
# 参数3:类所关联的属性与方法(字典类型)
def init(self,name):self.name = name
@classmethod
def copy(cls,student):return cls(student.name)
# 使用type创建类
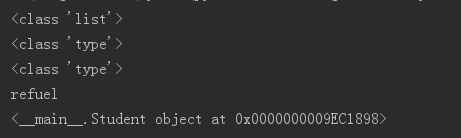
Student = type("Student",(),{"desc":"学生","__init__":init,"copy":copy})
s = Student("refuel")
print(s.name)
s2 = Student.copy(s)
print(s2)
4.2 自定义元类
type是Python中内建的元类,除此之外,我们也可以定义自己的元类,用来在创建类时定义类的创建细节,执行一些特殊的操作。例如:验证类的属性,增加线程安全,跟踪对象的创建等。我们可以继承元类type,来创建自定义的元类。然后在定义类时,使用metaclass关键字参数来显示指定要创建该类型的元类型。例如:
class MyClass(object, metaclass=Meta)
这样,该类(MyClass)就会使用我们指定的元类(Meta)来创建,如果没有指定元类,将会从该类的父类型中进行查找,以先找到的元类为准。如果一直没有找到元类,则使用内建的元类type来创建当前的类型。
# 自定义元类。通常是影响,干涉类的创建过程
# 自定义元;诶,继承type。当创建对象的时候,会调用类的__new__方法
# 类是有元类创建的,类就是元类的对象,因此创建类的时候会调用元类的__new__方法
class MyMeta(type):# 创建类调用元素的__new__方法,会传递三个参数:# 1:类的名称,2:元组(所有父类),3:类的所有关联的名称,属性,方法(字典类型)def __new__(cls, name, bases,attr):attr["desc"]="自定义元类"return super().__new__(cls, name, bases,attr)
# 定义一个类,首先从当前类中查找元素,如果没有找到,则查找父类,一致到object,如果一直没有找到使用type元;类
# 显示指定元类
class Student(metaclass=MyMeta):pass
print(Student.desc)
# 当前类没有显示指定,查找父类
class Pupil(Student):pass
print(Student.desc)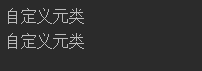

--异常)


--文件相关)


)
--正则表达式)


)





)

