EigenFaces 通常也被称为 特征脸,它使用主成分分析(Principal Component Analysis,PCA) 方法将高维的人脸数据处理为低维数据后(降维),再进行数据分析和处理,获取识别结果。
基本原理
在现实世界中,很多信息的表示是有冗余的。例如,表 23-2 所列出的一组圆的参数中就存在冗余信息。
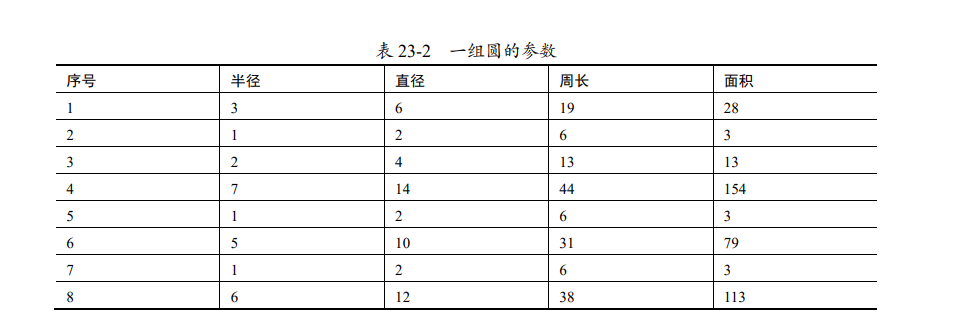
在表 23-2 所示的参数中,各个参数之间存在着非常强的相关性:
- 直径 = 2*半径
- 周长 = 2π半径
- 面积 = π半径半径
可以看到,直径、周长和面积都可以通过半径计算得到。
在进行数据分析时,如果我们希望更直观地看到这些参数的值,就需要获取所有字段的值。
但是,在比较圆的面积大小时,仅使用半径就足够了,此时其他信息对于我们来说就是“冗余”的。
因此,我们可以理解“半径”就是表 23-2 所列数据中的“主成分”,我们将“半径”从上述数据中提取出来供后续分析使用,就实现了“降维”。
当然,上面例子的数据非常简单、易于理解,而在大多数情况下,我们要处理的数据是比较复杂的。很多时候,我们可能无法直接判断哪些数据是关键的“主成分”,所以就要通过 PCA方法将复杂数据内的“主成分”分析出来。
EigenFaces 就是对原始数据使用 PCA 方法进行降维,获取其中的主成分信息,从而实现人脸识别的方法。
函数介绍
OpenCV 通过函数 cv2.face.EigenFaceRecognizer_create()生成特征脸识别器实例模型,然后应用 cv2.face_FaceRecognizer.train()函数完成训练,最后用 cv2.face_FaceRecognizer.predict()函数完成人脸识别。
- 函数cv2.face.EigenFaceRecognizer_create()
函数 cv2.face.EigenFaceRecognizer_create()的语法格式为:
retval = cv2.face.EigenFaceRecognizer_create( [, num_components[,
threshold]] )
式中的两个参数都是可选参数,含义如下:
- num_components:在 PCA 中要保留的分量个数。当然,该参数值通常要根据输入数据
来具体确定,并没有一定之规。一般来说,80 个分量就足够了。 - threshold:进行人脸识别时所采用的阈值。
- 函数cv2.face_FaceRecognizer.train()
函数 cv2.face_FaceRecognizer.train()对每个参考图像进行 EigenFaces 计算,得到一个向量。
每个人脸都是整个向量集中的一个点。该函数的语法格式为:
None = cv2.face_FaceRecognizer.train( src, labels )
式中各个参数的含义为:
- src:训练图像,用来学习的人脸图像。
- labels:人脸图像所对应的标签。
该函数没有返回值。
- 函数cv2.face_FaceRecognizer.predict()
函数 cv2.face_FaceRecognizer.predict()在对一个待测人脸图像进行判断时,会寻找与当前图像距离最近的人脸图像。与哪个人脸图像最接近,就将待测图像识别为其对应的标签。该函数的语法格式为:
label, confidence = cv2.face_FaceRecognizer.predict( src )
式中各个参数及返回值的含义为:
- src:需要识别的人脸图像。
- label:返回的识别结果标签。
- confidence:返回的置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。
0 表示完全匹配。该参数值通常在 0 到 20 000 之间,只要低于 5000,都被认为是相当可靠的识别结果。注意,这个范围与 LBPH 的置信度评分值的范围是不同的。
示例:使用 EigenFaces 模块完成一个简单的人脸识别程序。
import cv2
import numpy as np
images=[]
images.append(cv2.imread("face\\face2.png",cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread("face\\face3.png",cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread("face\\face4.png",cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread("face\\face5.png",cv2.IMREAD_GRAYSCALE))
labels=[0,0,1,1]
#print(labels)
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(images, np.array(labels))
predict_image=cv2.imread("face\\face5.png",cv2.IMREAD_GRAYSCALE)
label,confidence= recognizer.predict(predict_image)
print("label=",label)
print("confidence=",confidence)
运行结果:
报错了

说训练必须所有的图片大小要一致。
新代码:
import cv2
import numpy as np
images=[]
img1= cv2.imread("face\\face2.png",cv2.IMREAD_GRAYSCALE);
img1.resize((240,240))
images.append(img1)img2= cv2.imread("face\\face3.png",cv2.IMREAD_GRAYSCALE);
img2.resize((240,240))
images.append(img2)img3= cv2.imread("face\\face4.png",cv2.IMREAD_GRAYSCALE);
img3.resize((240,240))
images.append(img3)img4= cv2.imread("face\\face5.png",cv2.IMREAD_GRAYSCALE);
img4.resize((240,240))
images.append(img4)labels=[0,0,1,1]
#print(labels)
recognizer = cv2.face.EigenFaceRecognizer_create()
recognizer.train(images, np.array(labels)) # 识别器训练
predict_image=cv2.imread("face\\face6.png",cv2.IMREAD_GRAYSCALE)
predict_image.resize((240,240))
label,confidence= recognizer.predict(predict_image)
print("label=",label)
print("confidence=",confidence)
运行结果:
label= 1
confidence= 11499.110301703204
从结果来看,比 LBPH 人脸识别 对比稍微准点。




![[oneAPI] 基于BERT预训练模型的命名体识别任务](http://pic.xiahunao.cn/[oneAPI] 基于BERT预训练模型的命名体识别任务)



)


![[ubuntu]ubuntu18.04使用自带共享桌面实现vncserver连接](http://pic.xiahunao.cn/[ubuntu]ubuntu18.04使用自带共享桌面实现vncserver连接)

)
)




)