
1 CASIA-B数据集
本例使用的是预处理后的CASIA-B数据集, 数据集下载网址如下。
http://www.cbsr.ia.ac.cn/china/Gait%20Databases%20cH.asp
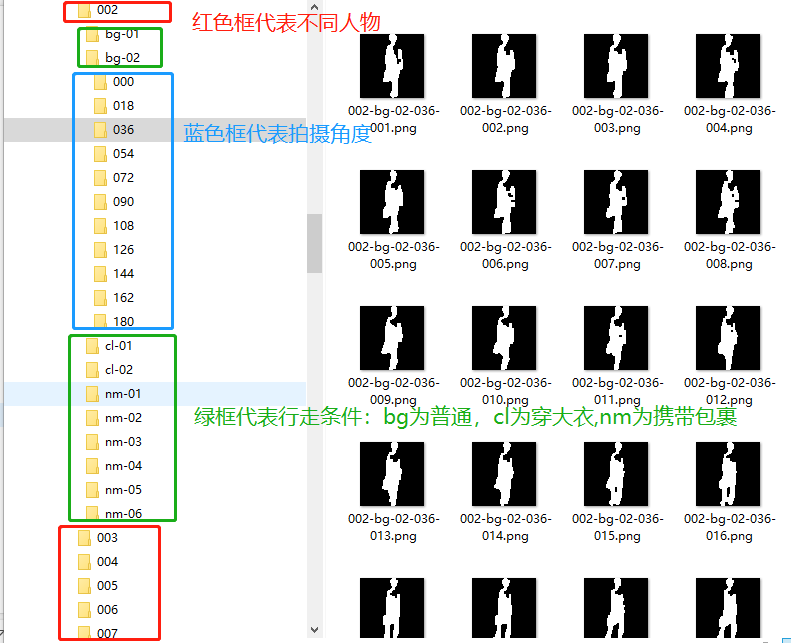
该数据集是一个大规模的、多视角的步态库。其中包括124个人,每个人有11个视角(0,18,36,...,180),在3种行走条件(普通、穿大衣、携带包裹)下采集。
1.1 CASIA-B数据集的两种形式
CASIA-B数据集有视频和轮廓两种形式。
1.1.1 案例讲解
本例直接使用轮廓数据集进行训练, 如图2-13(a)所示。
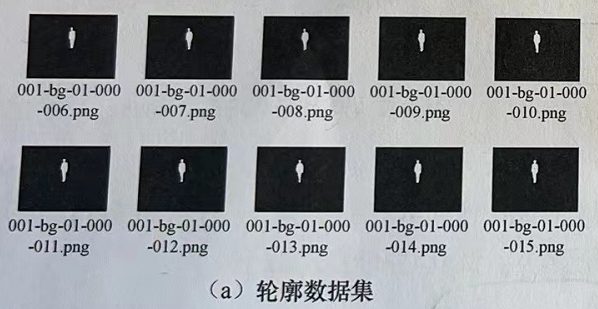
在本例中, 对CASIA-B的轮廓数据集做二次处理, 将图片中人物的顶端和底部背景去掉,方便模型的训练预处理后的数据集如图2-13(b)所示。

1.2 数据集的目录结构
2 代码实战 GitSet模型进行步态与身份识别(CASIA-B数据集)
代码总览![]() https://blog.csdn.net/qq_39237205/article/details/124199534
https://blog.csdn.net/qq_39237205/article/details/124199534
2.1 代码实战:定义函数,加载文件夹的文件名称---GaitSet_DataLoader.py(第一部分)
import numpy as np # 引入基础库
import os
import torch.utils.data as tordata
from PIL import Image
from tqdm import tqdm
import random# 1.1定义函数,加载文件夹的文件名称# load_data函数, 分为3个步骤:#
def load_data(dataset_path,imgresize,label_train_num,label_shuffle): # 完成了整体数据集的封装# 主要分为三个步骤# ①以人物作为标签,将完整的数据集分为两部分,分别用于训练和测试。# ②分别根据训练集和测试集中的人物标签遍历文件夹,获得对应的图片文件名称。# ③用torch.utils.data接口将图片文件名称转化为数据集, 使其能够将图片载入并返回。label_str = sorted(os.listdir(dataset_path)) # 以人物为标签# 将不完整的样本忽略,只载入完整样本removelist = ['005','026','037','079','109','088','068','048'] # 对数据集中样本不完整的人物标签进行过滤,留下可用样本。代码中不完整的人物标签可以通过调用load_dir函数来查找。for removename in removelist:if removename in label_str:label_str.remove(removename)print("label_str",label_str)
# -start--------根据乱序标志来处理样本标签顺序,并将其分为训练集和测试集----label_index = np.arange(len(label_str)) # 序列数组if label_shuffle:np.random.seed(0)# 打乱数组顺序label_shuffle_index = np.random.permutation( len(label_str) )train_list = label_shuffle_index[0:label_train_num]test_list = label_shuffle_index[label_train_num:]else:train_list = label_index[0:label_train_num]test_list = label_index[label_train_num:]
# -end--------根据乱序标志来处理样本标签顺序,并将其分为训练集和测试集----print("train_list",test_list)# 加载人物列表中的图片文件名称data_seq_dir,data_label,meta_data = load_dir(dataset_path,train_list,label_str) # 代码调用load_dir函数,将标签列表所对应的图片文件名称载入。①test_data_seq_dir, test_data_label, test_meta_data = load_dir(dataset_path, test_list, label_str) # 代码调用load_dir函数,将标签列表所对应的图片文件名称载入。②# 将图片文件名称转化为数据集train_source = DataSet(data_seq_dir, data_label, meta_data, imgresize,True) # 调用自定义类DataSet, 返回PyTorch支持的数据集对象,且只对训练集进行缓存处理,测试集不做缓存处理。①# test数据不缓存test_source = DataSet(test_data_seq_dir, test_data_label, test_meta_data, imgresize, False) # 调用自定义类DataSet, 返回PyTorch支持的数据集对象,且只对训练集进行缓存处理,测试集不做缓存处理。②return train_source,test_source2.2 代码实战:实现load_dir函数加载图片文件名称---GaitSet_DataLoader.py(第二部分)
# 1.2 实现load_dir函数加载图片文件名称,
def load_dir(dataset_path,label_index,label_str):# 在load_dir函数中, 通过文件夹的逐级遍历, 将标签列表中每个人物的图片文件名称载入。# 该函数返回3个列表对象:图片文件名称、图片文件名称对应的标签索引、图片文件名称对应的元数据(人物、行走条件、拍摄角度)data_seq_dir,data_label,meta_data = [],[],[]for i_label in label_index: # 获取样本个体label_path = os.path.join(dataset_path, label_str[i_label]) # 拼接目录for _seq_type in sorted(os.listdir(label_path)): # 获取样本类型,普通条件、穿大衣、携带物品seq_type_path = os.path.join(label_path, _seq_type) # 拼接目录for _view in sorted(os.listdir(seq_type_path)): # 获取拍摄角度_seq_dir = os.path.join(seq_type_path, _view) # 拼接图片目录if len(os.listdir(_seq_dir)) > 0: # 有图片data_seq_dir.append(_seq_dir) # 图片目录data_label.append(i_label) # 图片目录对应的标签meta_data.append((label_str[i_label], _seq_type, _view))else:print("No files:", _seq_dir) # 输出数据集中样本不完整的标签。# 当发现某个标签文件夹中没有图片时会将该标签输出。在使用时,可以先用load_dir函数将整个数据集遍历一遍, 并根据输出样本不完整的标签,回填到第18行代码。return data_seq_dir, data_label, meta_data # 返回结果2.3 实现定义数据类DataSet---GaitSet_DataLoader.py(第三部分)
# 1.3 实现定义数据类DataSet
# PyTorch提供了一个torch.utils.data接口,可以用来对数据集进行封装。
# 在实现时,只需要继承torch.utils.data.Dataset类,并重载其__getitem__方法。
# 在使用时,框架会向getitem方法传入索引index。在__getitem__方法内部,根据指定index加载数据。
class DataSet(tordata.DataLoader):def __init__(self,data_seq_dir,data_label,meta_data,imgresize,cache=True): # 初始化self.data_seq_dir = data_seq_dir # 存储图片文件名称self.data = [None] * len(self.data_seq_dir) # 存放图片self.cache = cache # 缓存标志self.meta_data = meta_data # 数据的元信息self.data_label = np.asarray(data_label) # 存放标签self.imgresize = int(imgresize) # 载入的图片大小self.cut_padding = int(float(imgresize)/64*10) # 指定图片裁剪的大小def load_all_data(self): # 加载所有数据for i in tqdm(range(len(self.data_seq_dir))):self.__getitem__(i)def __loader__(self,path): # 读取图片并裁剪frame_imgs = self.img2xarray(path)/255.0# 将图片横轴方向的前10列与后10列去掉frame_imgs = frame_imgs[:,:,self.cut_padding:-self.cut_padding]return frame_imgsdef __getitem__(self, index): # 加载指定索引数据if self.data[index] is None: # 第一次加载data = self.__loader__(self.data_seq_dir[index])else:data = self.data[index]if self.cache : # 保存到缓存里self.data[index] = datareturn data,self.meta_data[index],self.data_label[index]def img2xarray(self,file_path): # 读取指定路径的数据frame_list = [] # 存放图片数据imgs = sorted(list(os.listdir(file_path)))for _img in imgs : # 读取图片,放到数组里_img_path = os.path.join(file_path, _img)if os.path.isfile(_img_path):img = np.asarray(Image.open(_img_path).resize((self.imgresize, self.imgresize)))if len(img.shape) == 3: # 加载预处理后的图片frame_list.append(img[..., 0])else:frame_list.append(img)return np.asarray(frame_list, dtype=np.float) # [帧数,高,宽]def __len__(self): # 计算数据集长度return len(self.data_seq_dir)2.4 代码实战:测试数据集---train.py(第一部分)
# 1.4 测试数据集
# 在完成数据集的制作之后,对其进行测试。
# 将样本文件夹perdata放到当前目录下,并编写代码生成数据集对象。
# 从数据集对象中取出一条数据,并显示该数据的详细内容。
from GaitSet_DataLoader import load_data # 加载项目模块# 输出当前CPU-GPU
print("torch V",torch.__version__,"cuda V",torch.version.cuda)
pathstr = './data/perdata/perdata'
label_train_num = 10 # 训练集的个数。剩下是测试集
batch_size = (3, 6)
frame_num = 8
hidden_dim = 64
# label_train_num = 70 # 训练数据集的个数,剩下的是测试数据库dataconf = { # 方便导入参数'dataset_path':pathstr,'imgresize':'64','label_train_num':label_train_num,'label_shuffle':True,
}
print("加载训练数据...")
train_source,test_cource = load_data(**dataconf) # 一次全载入,经过load_data()分别生成训练和测试数据集对象。
print("训练数据集长度",len(train_source)) # label_num * type10* view11
# 显示数据集里面的标签
train_label_set = set(train_source.data_label)
print("数据集里面的标签:",train_label_set)dataimg,matedata,lebelimg = train_source.__getitem__(4) # 从数据集中获取一条数据,并显示其详细信息。print("图片样本数据形状:", dataimg.shape," 数据的元信息:", matedata," 数据标签索引:",lebelimg)plt.imshow(dataimg[0]) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()def imshow(img):print("图片形状",np.shape(img))npimg = img.numpy()plt.axis('off')plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()imshow(torchvision.utils.make_grid(torch.from_numpy(dataimg[-10:]).unsqueeze(1),nrow=10)) # 显示十张图片2.5 代码实战:实现自定义采集器---GaitSet_DataLoader.py(第四部分)
# 1.5 实现自定义采集器
# 步态识别模型需要通过三元损失进行训练。三元损失可以辅助模型特征提取的取向,使相同标签的特征距离更近,不同标签的特征距离更远。
# 由于三元损失需要输入的批次数据中,要包含不同标签(这样才可以使用矩阵方式进行正/负样本的采样),需要额外对数据集进行处理。
# 这里使用自定义采样器完成含有不同标签数据的采样功能。# torch.utils.data.sampler类需要配合torch.utils.data.Data Loader模块一起使用。# torch.utils.data.DataLoader是PyTorch中的数据集处理接口。# 根据torch.utils.data.sampler类的采样索引,在数据源中取出指定的数据,并放到collate_fn中进行二次处理,最终返回所需要的批次数据。# 实现自定义采样器TripletSampler类,来从数据集中选取不同标签的索引,并将其返回。# 再将两个collate_fn函数collate_fn_for_train、collate_fn_for_test分别用于对训练数据和测试数据的二次处理。class TripletSample(tordata.sampler.Sampler): # 继承torch.utils.data.sampler类,实现自定义采样器。# TripletSampler类的实现,在该类的初始化函数中,支持两个参数传入:数集与批次参数。其中批次参数包含两个维度的批次大小,分别是标签个数与样本个数。def __init__(self,dataset,batch_size):self.dataset = dataset # 获得数据集self.batch_size = batch_size # 获得批次参数,形状为(标签个数,样本个数)self.label_set = list(set(dataset.data_label)) # 标签集合def __iter__(self): # 实现采样器的取值过程:从数据集中随机抽取指定个数的标签,并在每个标签中抽取指定个数的样本,最终以生成器的形式返回。while(True):sample_indices = []# 随机抽取指定个数的标签label_list = random.sample(self.label_set,self.batch_size[0])# 在每个标签中抽取指定个数的样本for _label in label_list: # 按照标签个数循环data_index = np.where(self.dataset.data_label == _label)[0]index = np.random.choice(data_index,self.batch_size[1],replace=False)sample_indices += index.tolist()yield np.asarray(sample_indices) # 以生成器的形式返回def __len__(self):return len(self.dataset) # 计算长度# 用于训练数据的采样器处理函数
def collate_fn_train(batch,frame_num):# collate_fn_train函数会对采样器传入的批次数据进行重组,并对每条数据按照指定帧数frame_num进行抽取。# 同时也要保证每条数据的帖数都大于等于帧数frame_num。如果帧数小于frame_num,则为其添加重复帧。batch_data, batch_label,batch_meta = [],[],[]batch_size = len(batch) #获得数据条数for i in range(batch_size) : # 依次对每条数据进行处理batch_label.append(batch[i][2]) # 添加数据的标签batch_meta.append(batch[i][1]) # 添加数据的元信息data = batch[i][0] # 获取该数据的样本信息if data.shape[0] < frame_num: # 如果帧数较少,则随机加入几个# 复制帧,用于帧数很少的情况multy = (frame_num - data.shape[0])//data.shape[0] + 1# 额外随机加入的帧的个数choicenum = (frame_num - data.shape[0])%data.shape[0]choice_index = np.random(data.shape[0],choicenum,replace = False)choice_index = list(range(0,data.shape[9])) * multy + choice_index.tolist()else: # 随机抽取指定个数的帧choice_index = np.random.choice(data.shape[0],frame_num,replace = False)batch_data.append(data[choice_index]) # 增加指定个数的帧数据# 重新组合合成用于训练的样本数据batch = [np.asarray(batch_data),batch_meta,batch_label]return batchdef collate_fn_for_test(batch,frame_num): # 用于测试数据的采样器处理函数# collate_fn_for_test函数会对采样器传入的批次数据进行重组,并按照批次数据中最大帧数进行补0对齐。# 同时也要保证母条数据的帧数都大于等于帧数frame_num。如果帧数小于frame_num,则为其添加重复帧。batch_size = len(batch) # 获得数据的条数batch_frames = np.zeros(batch_size,np.int)batch_data,batch_label,batch_meta = [],[],[]for i in range(batch_size): # 依次对每条数据进行处理batch_label.append(batch[i][2]) # 添加数据的标签batch_meta.append(batch[i][1]) # 添加数据的元信息data = batch[i][0] # 获取该数据的帧样本信息if data.shape[0] < frame_num: # 如果帧数较少,随机加入几个print(batch_meta, data.shape[0])multy = (frame_num - data.shape[0]) // data.shape[0] + 1choicenum = (frame_num - data.shape[0]) % data.shape[0]choice_index = np.random.choice(data.shape[0], choicenum, replace=False)choice_index = list(range(0, data.shape[0])) * multy + choice_index.tolist()data = np.asarray(data[choice_index])batch_frames[i] = data.shape[0] # 保证所有的都大于等于frame_numbatch_data.append(data)max_frame = np.max(batch_frames) # 获得最大的帧数# 对其他帧进行补0填充batch_data = np.asarray([np.pad(batch_data[i], ((0, max_frame - batch_data[i].shape[0]), (0, 0), (0, 0)),'constant', constant_values=0)for i in range(batch_size)])# 重新组合成用于训练的样本数据batch = [batch_data, batch_meta, batch_label]return batch2.6 测试采样器---train.py(第二部分)
# 1.6 测试采样器
from GaitSet_DataLoader import TripletSample,collate_fn_trainbatch_size = (4,8) # 定义批次(4个标签,每个标签8个数据)
frame_num = 32 # 定义帧数
num_workers = torch.cuda.device_count() # 设置采样器的线程数# 在设置数据加载器额外启动进程的数量时,最好要与GPU数量匹配,即一个进程服务于一个GPU。如果额外启动进程的数量远远大于GPU数量,则性能瓶颈主要会卡在GPU运行的地方,起不到提升效率的作用。
print("当前GPU数量:",num_workers)
if num_workers <= 1 : # 如果只有一块GPU,或者没有GPU,则使用主线程处理num_workers = 0
print("数据加载器额外启动进程的数量",num_workers)# 实例化采样器:得到对象triplet_sampler。
triplet_sampler = TripletSample(train_source,batch_size)
# 初始化采样器的处理函数:用偏函数的方法对采样器的处理函数进行初始化。
collate_train = partial(collate_fn_train,frame_num=frame_num)# 定义数据加载器:每次迭代,按照采样器的索引在train_source中取出数据
# 将对象triplet_sampler和采样器的处理函数collate_train传入tordata.DataLoader,得到一个可用于训练的数据加载器对象train_loader。
# 同时对数据加载器额外启动进程的数量进行了设置,如果额外启动进程的数量num_workers是0,则在加载数据时不额外启动其他进程。
train_loader = tordata.DataLoader(dataset=train_source,batch_sampler=triplet_sampler, collate_fn=collate_train,num_workers=num_workers)# 从数据加载器中取出一条数据
batch_data,batch_meta,batch_label = next(iter(train_loader))
print("该批次数据的总长度:",len(batch_data)) # 输出该数据的详细信息
print("每条数据的形状为",batch_data.shape)
print(batch_label) # 输出该数据的标签2.7 代码实战:定义基础卷积类---GaitSet.py(第一部分)
import torch
import torch.nn as nn
import torch.autograd as autograd
import torch.nn.functional as F# 搭建GaitSet模型: 分为两部分:基础卷积(BasicConv2d) 类和GaitSetNet类。# 1.7 定义基础卷积类:对原始卷积函数进行封装。在卷积结束后,用Mish激活函数和批量正则化处理对特征进行二次处理。
class BasicConv2d(nn.Module):def __init__(self,in_channels,out_channels,kernel_size,**kwargs):super(BasicConv2d,self).__init__()self.conv = nn.Conv2d(in_channels,out_channels,kernel_size,bias=False,**kwargs) # 卷积操作self.BatchNorm = nn.BatchNorm2d(out_channels) # BN操作def forward(self,x): # 自定义前向传播方法x = self.conv(x)x = x * ( torch.tanh(F.softplus(x))) # 实现Mish激活函数:PyTorch没有现成的Mish激活函数,手动实现Mish激活函数,并对其进行调用。return self.BatchNorm(x) # 返回卷积结果2.8 代码实战:定义GaitSetNet类---GaitSet.py(第二部分)
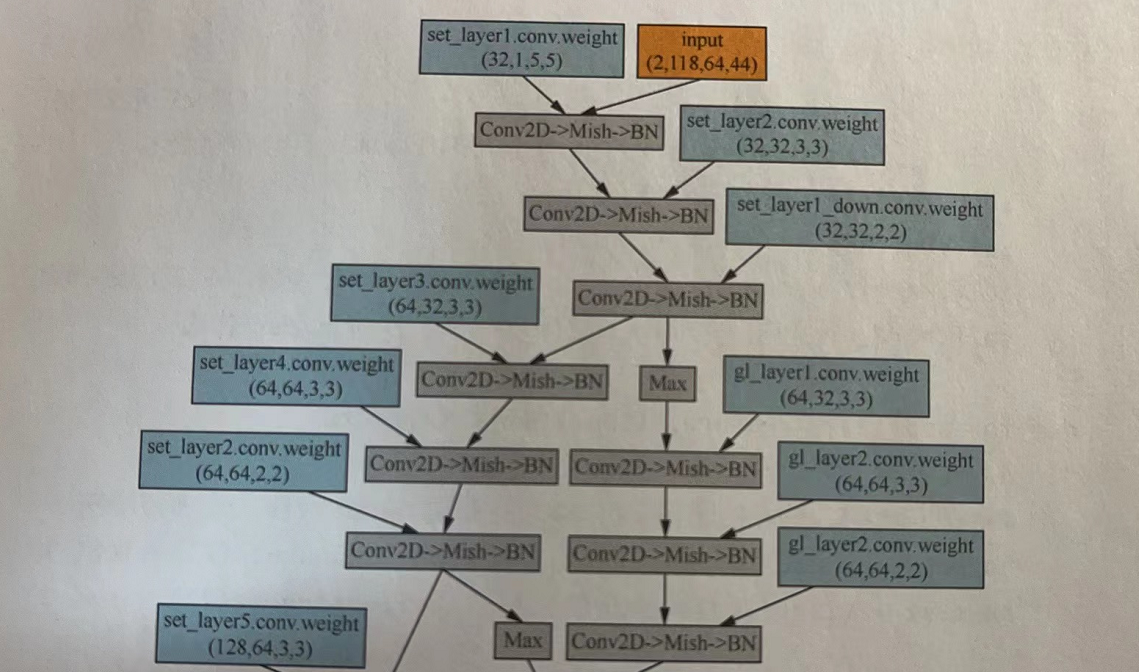
# 1.8 定义GaitSetNet类:
# ①实现3个MGP。
# ②对MGP的结果进行HPM处理。每层MGP的结构是由两个卷积层加一次下采样组成的。在主分支下采样之后,与辅助分支所提取的帧级特征加和,传入下一个MGP中。
class GaitSetNet(nn.Module):def __init__(self, hidden_dim, frame_num):super(GaitSetNet, self).__init__()self.hidden_dim = hidden_dim # 输出的特征维度# 定义MGP部分cnls = [1, 32, 64, 128] # 定义卷积层通道数量self.set_layer1 = BasicConv2d(cnls[0], cnls[1], 5, padding=2)self.set_layer2 = BasicConv2d(cnls[1], cnls[1], 3, padding=1)self.set_layer1_down = BasicConv2d(cnls[1], cnls[1], 2, stride=2) # 下采样操作,通过步长为2的2x2卷积实现。self.set_layer3 = BasicConv2d(cnls[1], cnls[2], 3, padding=1)self.set_layer4 = BasicConv2d(cnls[2], cnls[2], 3, padding=1)self.set_layer2_down = BasicConv2d(cnls[2], cnls[2], 2, stride=2)# 下采样操作,通过步长为2的2x2卷积实现。self.gl_layer2_down = BasicConv2d(cnls[2], cnls[2], 2, stride=2)# 下采样操作,通过步长为2的2x2卷积实现。self.set_layer5 = BasicConv2d(cnls[2], cnls[3], 3, padding=1)self.set_layer6 = BasicConv2d(cnls[3], cnls[3], 3, padding=1)self.gl_layer1 = BasicConv2d(cnls[1], cnls[2], 3, padding=1)self.gl_layer2 = BasicConv2d(cnls[2], cnls[2], 3, padding=1)self.gl_layer3 = BasicConv2d(cnls[2], cnls[3], 3, padding=1)self.gl_layer4 = BasicConv2d(cnls[3], cnls[3], 3, padding=1)self.bin_num = [1, 2, 4, 8, 16] # 定义MGP部分self.fc_bin = nn.ParameterList([nn.Parameter(nn.init.xavier_uniform_(torch.zeros(sum(self.bin_num) * 2, 128, hidden_dim)))])def frame_max(self, x, n): # 用最大特征方法提取帧级特征:# 调用torch.max函数,实现从形状[批次个数,帧数,通道数,高度,宽度]的特征中,沿着帧维度,提取最大值,得到形状[批次个数,通道数,高度,宽度]的特征提取帧级特征的过程。return torch.max(x.view(n, -1, x.shape[1], x.shape[2], x.shape[3]), 1)[0] # 取max后的值def forward(self, xinput): # 定义前向处理方法n = xinput.size()[0] # 形状为[批次个数,帧数,高,宽]x = xinput.reshape(-1, 1, xinput.shape[-2], xinput.shape[-1])del xinput # 删除不用的变量# MGP 第一层x = self.set_layer1(x)x = self.set_layer2(x)x = self.set_layer1_down(x)gl = self.gl_layer1(self.frame_max(x, n)) # 将每一层的帧取最大值# MGP 第二层gl = self.gl_layer2(gl)gl = self.gl_layer2_down(gl)x = self.set_layer3(x)x = self.set_layer4(x)x = self.set_layer2_down(x)# MGP 第三层gl = self.gl_layer3(gl + self.frame_max(x, n))gl = self.gl_layer4(gl)x = self.set_layer5(x)x = self.set_layer6(x)x = self.frame_max(x, n)gl = gl + x# srart-------HPM处理:按照定义的特征尺度self.bin_num,将输入特征分成不同尺度,并对每个尺度的特征进行均值和最大化计算,从而组合成新的特征,放到列表feature中。feature = list() # 用于存放HPM特征n, c, h, w = gl.size()for num_bin in self.bin_num:z = x.view(n, c, num_bin, -1)z = z.mean(3) + z.max(3)[0]feature.append(z)z = gl.view(n, c, num_bin, -1)z = z.mean(3) + z.max(3)[0]feature.append(z)# end-------HPM处理:按照定义的特征尺度self.bin_num,将输入特征分成不同尺度,并对每个尺度的特征进行均值和最大化计算,从而组合成新的特征,放到列表feature中。# 对HPM特征中的特征维度进行转化# srart-------将每个特征维度由128转化为指定的输出的特征维度hidden_dim。因为输入数据是三维的,无法直接使用全连接API,所以使用矩阵相乘的方式实现三维数据按照最后一个维度进行全连接的效果。feature = torch.cat(feature, 2).permute(2, 0, 1).contiguous() # 62 n cfeature = feature.matmul(self.fc_bin[0])feature = feature.permute(1, 0, 2).contiguous()# end-------将每个特征维度由128转化为指定的输出的特征维度hidden_dim。因为输入数据是三维的,无法直接使用全连接API,所以使用矩阵相乘的方式实现三维数据按照最后一个维度进行全连接的效果。return feature # 返回结果2.8.1 提取帧级特征的过程

2.9 自定义三元损失类---GaitSet.py(第三部分)
# 1.9 实现 自定义三元损失类
# 定义三元损失(TripletLoss)类, 实现三元损失的计算。具体步骤:
# ①对输入样本中的标签进行每两个一组自由组合,生成标签矩阵,从标签矩阵中得到正/负样本对的掩码
# ②对输入样本中的特征进行每两个一组自由组合,生成特征矩阵,计算出特征矩阵的欧氏距离。
# ③按照正/负样本对的掩码,对带有距离的特征矩阵进行提取,得到正/负两种标签的距离。
# ④将正/负两种标签的距离相减,再减去间隔值,得到三元损失。
class TripletLoss(nn.Module): # 定义三元损失类def __init__(self,batch_size,hard_or_full,margin): # 初始化super(TripletLoss, self).__init__()self.batch_size = batch_sizeself.margin =margin # 正/负样本的三元损失间隔self.hard_or_full = hard_or_full # 三元损失方式def forward(self,feature,label): # 定义前向传播方法:# 接收的参数feature为模型根据输入样本所计算出来的特征。该参数的形状为[n.m.d],n:HPM处理时的尺度个数62。m:样本个数32。d:维度256。# 在计算过程中,将三元损失看作n份,用矩阵的方式对每份m个样本、d维度特征做三元损失计算,最后将这n份平均。n,m,d = feature.size() # 形状为[n,m,d]# 生成标签矩阵,并从中找出正/负样本对的编码,输出形状[n,m,m]并且展开hp_mask = (label.unsqueeze(1) == label.unsqueeze(2)).view(-1)hn_mask = (label.unsqueeze(1) != label.unsqueeze(2)).view(-1)dist = self.batch_dist(feature) # 计算出特征矩阵的距离mean_dist = dist.mean(1).mean(1) # 计算所有的平均距离dist = dist.view(-1)# start-----计算三元损失的hard模式hard_hp_dist = torch.max(torch.masked_select(dist, hp_mask).view(n, m, -1), 2)[0]hard_hn_dist = torch.min(torch.masked_select(dist, hn_mask).view(n, m, -1), 2)[0]hard_loss_metric = F.relu(self.margin + hard_hp_dist - hard_hn_dist).view(n, -1) # 要让间隔最小化,到0为止# 对三元损失取均值,得到最终的hard模式loss[n]hard_loss_metric_mean = torch.mean(hard_loss_metric,1)# end-----计算三元损失的hard模式# start-----计算三元损失的full模式# 计算三元损失的full模型full_hp_dist = torch.masked_select(dist, hp_mask).view(n, m, -1, 1) # 按照编码得到所有正向样本距离[n,m,正样本个数,1] [62, 32, 8, 1]full_hn_dist = torch.masked_select(dist, hn_mask).view(n, m, 1, -1) # 照编码得到所有负向样本距离[n,m,1,负样本个数] [62, 32, 1, 24]full_loss_metric = F.relu(self.margin + full_hp_dist - full_hn_dist).view(n, -1) # 让正/负间隔最小化,到0为止 [62,32*8*24]# 计算[n]中每个三元损失的和full_loss_metric_sum = full_loss_metric.sum(1) # 计算[62]中每个loss的和# 计算[n]中每个三元损失的个数(去掉矩阵对角线以及符合条件的三元损失)full_loss_num = (full_loss_metric != 0).sum(1).float() # 计算[62]中每个loss的个数# 计算均值full_loss_metric_mean = full_loss_metric_sum / full_loss_num # 计算平均值full_loss_metric_mean[full_loss_num == 0] = 0 # 将无效值设为0# end-----计算三元损失的full模式return full_loss_metric_mean, hard_loss_metric_mean, mean_dist, full_loss_num # ,lossdef batch_dist(self, x): # 计算特征矩阵的距离x2 = torch.sum(x ** 2, 2) # 平方和 [62, 32]# dist [62, 32, 32]dist = x2.unsqueeze(2) + x2.unsqueeze(2).transpose(1, 2) - 2 * torch.matmul(x, x.transpose(1, 2)) # 计算特征矩阵的距离dist = torch.sqrt(F.relu(dist)) # 对结果进行开平方return distdef ts2var(x):return autograd.Variable(x).cuda()def np2var(x):return ts2var(torch.from_numpy(x))2.10 代码实战:训练模型并保存权重文件---train.py(第三部分)
# 1.10 训练模型并保存权重文件:实例化模型类,并遍历数据加载器,进行训练。
from GaitSet import GaitSetNet, TripletLoss, np2varhidden_dim = 256 # 定义样本的输出维度
encoder = GaitSetNet(hidden_dim, frame_num).float()
encoder = nn.DataParallel(encoder) # 使用多卡并行训练
encoder.cuda() # 将模型转储到GPU
encoder.train() # 设置模型为训练模型optimizer = Ranger(encoder.parameters(), lr=0.004) # 定义Ranger优化器TripletLossmode = 'full' # 设置三元损失的模式
triplet_loss = TripletLoss(int(np.prod(batch_size)), TripletLossmode, margin=0.2) # 实例化三元损失
triplet_loss = nn.DataParallel(triplet_loss) # 使用多卡并行训练
triplet_loss.cuda() # 将模型转储到GPUckp = 'checkpoint' # 设置模型名称
os.makedirs(ckp, exist_ok=True)
save_name = '_'.join(map(str, [hidden_dim, int(np.prod(batch_size)),frame_num, 'full']))ckpfiles = sorted(os.listdir(ckp)) # 载入预训练模型
if len(ckpfiles) > 1:modecpk = os.path.join(ckp, ckpfiles[-2])optcpk = os.path.join(ckp, ckpfiles[-1])encoder.module.load_state_dict(torch.load(modecpk)) # 加载模型文件optimizer.load_state_dict(torch.load(optcpk))print("load cpk !!! ", modecpk)
# 定义训练参数
hard_loss_metric = []
full_loss_metric = []
full_loss_num = []
dist_list = []
mean_dist = 0.01
restore_iter = 0
total_iter = 1000 # 迭代次数
lastloss = 65535 # 初始的损失值
trainloss = []_time1 = datetime.now() # 计算迭代时间
for batch_data, batch_meta, batch_label in train_loader:restore_iter += 1optimizer.zero_grad() # 梯度清零batch_data = np2var(batch_data).float() # torch.cuda.DoubleTensor变为torch.cuda.FloatTensorfeature = encoder(batch_data) # 将标签转为张量# 将标签转化为张量target_label = np2var(np.array(batch_label)).long() # len=32triplet_feature = feature.permute(1, 0, 2).contiguous() # 对特征结果进行变形,形状变为[62, 32, 256]triplet_label = target_label.unsqueeze(0).repeat(triplet_feature.size(0), 1) # 复制12份标签,[62, 32]# 计算三元损失(full_loss_metric_, hard_loss_metric_, mean_dist_, full_loss_num_) = triplet_loss(triplet_feature, triplet_label)if triplet_loss.module.hard_or_full == 'full': #提取损失值loss = full_loss_metric_.mean()else:loss = hard_loss_metric_.mean()trainloss.append(loss.data.cpu().numpy()) # 保存损失值hard_loss_metric.append(hard_loss_metric_.mean().data.cpu().numpy())full_loss_metric.append(full_loss_metric_.mean().data.cpu().numpy())full_loss_num.append(full_loss_num_.mean().data.cpu().numpy())dist_list.append(mean_dist_.mean().data.cpu().numpy())if loss > 1e-9: # 若损失值过小,则不参加反向传播loss.backward()optimizer.step()else:print("损失值过小:", loss)if restore_iter % 1000 == 0:print("restore_iter 1000 time:", datetime.now() - _time1)_time1 = datetime.now()if restore_iter % 100 == 0: # 输出训练结果print('iter {}:'.format(restore_iter), end='')print(', hard_loss_metric={0:.8f}'.format(np.mean(hard_loss_metric)), end='')print(', full_loss_metric={0:.8f}'.format(np.mean(full_loss_metric)), end='')print(', full_loss_num={0:.8f}'.format(np.mean(full_loss_num)), end='')print(', mean_dist={0:.8f}'.format(np.mean(dist_list)), end='')print(', lr=%f' % optimizer.param_groups[0]['lr'], end='')print(', hard or full=%r' % TripletLossmode)if lastloss > np.mean(trainloss): # 保存模型print("lastloss:", lastloss, " loss:", np.mean(trainloss), "need save!")lastloss = np.mean(trainloss)modecpk = os.path.join(ckp,'{}-{:0>5}-encoder.pt'.format(save_name, restore_iter))optcpk = os.path.join(ckp,'{}-{:0>5}-optimizer.pt'.format(save_name, restore_iter))torch.save(encoder.module.state_dict(), modecpk) # 一定要用encoder对象的module中的参数进行保存。否则模型数的名字中会含有“module”字符串,使其不能被非并行的模型载入。torch.save(optimizer.state_dict(), optcpk)else:print("lastloss:", lastloss, " loss:", np.mean(trainloss), "don't save")print("__________________")sys.stdout.flush()hard_loss_metric.clear()full_loss_metric.clear()full_loss_num.clear()dist_list.clear()trainloss.clear()if restore_iter == total_iter: # 如果满足迭代次数,则训练结束break2.11 代码实战:测试模型---GaitSet_test.py(全)
import os
import numpy as np
from datetime import datetime
from functools import partial
from tqdm import tqdm
import torch.nn as nn
import torch.nn.functional as F
import torch
import torch.utils.data as tordata
from GaitSet_DataLoader import load_data,collate_fn_for_test
from GaitSet import GaitSetNet,np2var
# 为了测试模型识别步态的效果不依赖于拍摄角度和行走条件,可以多角度识别人物步分别取3组行走条件(普通、穿大衣、携带包裹)的样本输入模型,查看该模型所计算出的生征与其他行走条件的匹配程度。
# 1.11 测试模型
print("torch v:",torch.__version__,"cuda v:",torch.version.cuda)pathstr = './data/perdata/perdata'
label_train_num = 70 # 训练数据集的个数,剩下是测试数据集
batch_size = (8,16)
frame_num = 30
hidden_dim = 256# 设置处理流程
num_workers = torch.cuda.device_count()
print("cuda.device_count",num_workers)
if num_workers <= 1: # 仅有一块GPU或没有GPU,则使用CPUnum_workers = 0
print("num_workers",num_workers)dataconf = { # 初始化数据集参数'dataset_path':pathstr,'imgresize':'64','label_train_num':label_train_num, # 训练数据集的个数,剩下的是测试数据集'label_shuffle':True,
}
train_source,test_source = load_data(**dataconf)sampler_batch_size = 4 # 定义采样批次
# 初始化采样数据的二次处理函数
collate_train = partial(collate_fn_for_test,frame_num=frame_num)
# 定义数据加载器:每次迭代,按照采样器的索引在test_source中取出数据
test_loader = tordata.DataLoader(dataset=test_source,batch_size=sampler_batch_size,sampler=tordata.sampler.SequentialSampler(test_source),collate_fn=collate_train,num_workers=num_workers)# 实例化模型
encoder = GaitSetNet(hidden_dim,frame_num).float()
encoder = nn.DataParallel(encoder)
encoder.cuda()
encoder.eval()ckp = './checkpoint' # 设置模型文件路径
save_name = '_'.join(map(str,[hidden_dim,int(np.prod( batch_size )),frame_num,'full']))
ckpfiles = sorted(os.listdir(ckp)) # 加载模型
print("ckpfiles::::",ckpfiles)
if len(ckpfiles) > 1:# modecpk = ckp + '/'+ckpfiles[-1]modecpk = os.path.join(ckp,ckpfiles[-1])encoder.module.load_state_dict(torch.load(modecpk), False) # 加载模型文件print("load cpk !!! ", modecpk)
else:print("No cpk!!!")def cuda_dist(x,y): # 计算距离x = torch.from_numpy(x).cuda()y = torch.from_numpy(y).cuda()dist = torch.sum(x ** 2, 1).unsqueeze(1) + torch.sum(y ** 2, 1).unsqueeze(1).transpose(0, 1) - 2 * torch.matmul(x, y.transpose(0, 1))dist = torch.sqrt(F.relu(dist))return distdef de_diag(acc,each_angle=False): # 计算多角度准确率,计算与其他拍摄角度相关的准确率result = np.sum(acc - np.diag(np.diag(acc)), 1) / 10.0if not each_angle:result = np.mean(result)return resultdef evaluation(data): # 评估模型函数feature, meta, label = dataview, seq_type = [], []for i in meta:view.append(i[2])seq_type.append(i[1])label = np.array(label)view_list = list(set(view))view_list.sort()view_num = len(view_list)probe_seq = [['nm-05', 'nm-06'], ['bg-01', 'bg-02'], ['cl-01', 'cl-02']] # 定义采集数据的行走条件gallery_seq = [['nm-01', 'nm-02', 'nm-03', 'nm-04']] # 定义比较数据的行走条件num_rank = 5 # 取前5个距离最近的数据acc = np.zeros([len(probe_seq), view_num, view_num, num_rank])for (p, probe_s) in enumerate(probe_seq): # 依次将采集的数据与比较数据相比for gallery_s in gallery_seq:# Start---获取指定条件的样本特征后,按照采集数据特征与比较数据特之间的距离大小匹配对应的标签,并计算其准确率。# 步骤如下:# ①计算采集数据特征与比较数据特征之间的距离。# ②对距离进行排序,返回最小的前5个排序索引。# ③按照索引从比较数据中取出前5个标签,并与采集数据中的标签做比较。# ④将比较结果的正确数量累加起来,使每个样本对应5个记录,分别代表前5个果中的识别正确个数。如[True,True,True,False,False],# 累加后结果为[1,2,3,3,3],表明离采集数据最近的前3个样本特征中识别出来3个正确结果,前5个样本特征中识别出来3个正确结果。# ⑤将累加结果与0比较,并判断每个排名中大于0的个数。# ⑥将排名1-5的识别正确个数分别除以采集样本个数,再乘以100,便得到每个排名的准确率for (v1, probe_view) in enumerate(view_list):for (v2, gallery_view) in enumerate(view_list): # 遍历所有视角gseq_mask = np.isin(seq_type, gallery_s) & np.isin(view, [gallery_view])gallery_x = feature[gseq_mask, :] # 取出样本特征gallery_y = label[gseq_mask] # 取出标签pseq_mask = np.isin(seq_type, probe_s) & np.isin(view, [probe_view])probe_x = feature[pseq_mask, :] # 取出样本特征probe_y = label[pseq_mask] # 取出标签if len(probe_x) > 0 and len(gallery_x) > 0:dist = cuda_dist(probe_x, gallery_x) # 计算特征之间的距离idx = dist.sort(1)[1].cpu().numpy() # 对距离按照由小到大排序,返回排序后的索引(【0】是排序后的值)# 分别计算前五个结果的精确率:步骤③~⑥rank_data = np.round(np.sum(np.cumsum(np.reshape(probe_y,[-1,1]) == gallery_y[idx[:,0:num_rank]],1)>0,0)*100/dist.shape[0],2)# End---获取指定条件的样本特征后,按照采集数据特征与比较数据特之间的距离大小匹配对应的标签,并计算其准确率。acc[p, v1, v2, 0:len(rank_data)] = rank_datareturn accprint('test_loader', len(test_loader))
time = datetime.now()
print('开始评估模型...')
feature_list = list()
view_list = list()
seq_type_list = list()
label_list = list()
batch_meta_list = []# 在遍历数据集前加入了withtorch.nograd()语句。该语句可以使模型在运行时,不额外创建梯度相关的内存。
# 在显存不足的情况下,使用withtorch.nogradO语句非常重要,它可以节省系统资源。
# 虽然在实例化模型时,使用了模型的eval方法来设置模型的使用方式,但这仅注意是修改模型中具有状态分支的处理流程(如dropout或BN等),并不会省去创建显存存放梯度的开销。
with torch.no_grad():for i, x in tqdm(enumerate(test_loader)): # 遍历数据集batch_data, batch_meta, batch_label = xbatch_data = np2var(batch_data).float() # [2, 212, 64, 44]feature = encoder(batch_data) # 将数据载入模型 [4, 62, 64]feature_list.append(feature.view(feature.shape[0], -1).data.cpu().numpy()) # 保存特征结果,共sampler_batch_size 个特征batch_meta_list += batch_metalabel_list += batch_label # 保存样本标签# 将样本特征、标签以及对应的元信息组合起来
test = (np.concatenate(feature_list, 0), batch_meta_list, label_list)
acc = evaluation(test) # 对组合数据进行评估
print('评估完成. 耗时:', datetime.now() - time)for i in range(1): # 计算第一个的精确率print('===Rank-%d 准确率===' % (i + 1))print('携带包裹: %.3f,\t普通: %.3f,\t穿大衣: %.3f' % (np.mean(acc[0, :, :, i]),np.mean(acc[1, :, :, i]),np.mean(acc[2, :, :, i])))for i in range(1): # 计算第一个的精确率(除去自身的行走条件)print('===Rank-%d 准确率(除去自身的行走条件)===' % (i + 1))print('携带包裹: %.3f,\t普通: %.3f,\t穿大衣: %.3f' % (de_diag(acc[0, :, :, i]),de_diag(acc[1, :, :, i]),de_diag(acc[2, :, :, i])))np.set_printoptions(precision=2, floatmode='fixed') # 设置输出精度
for i in range(1): # 显示多拍摄角度的详细结果print('===Rank-%d 的每个角度准确率 (除去自身的行走条件)===' % (i + 1))print('携带包裹:', de_diag(acc[0, :, :, i], True))print('普通:', de_diag(acc[1, :, :, i], True))print('穿大衣:', de_diag(acc[2, :, :, i], True))
...)


)

 on Variable that requires grad. Use var.detach().numpy())











 must match the size of tensor b (3) at non-singletonThe size of)
