YOLOX-PAI:一种改进的YOLOX,比YOLOv6更强更快
原文:https://arxiv.org/pdf/2208.13040.pdf
代码:https://github.com/alibaba/EasyCV
0.Abstract
We develop an all-in-one computer vision toolbox named EasyCV to facilitate the use of various SOTA computer vision methods. Recently, we add YOLOX-PAI, an improved version of YOLOX, into EasyCV. We conduct ablation studies to investigate the in fluence of some detection methods on YOLOX. We also provide an easy use for PAI-Blade which is used to accelerate the inference process based on BladeDISC and TensorRT. Finally, we receive 42.8 mAP on COCO dateset within 1.0 ms on a single NVIDIA V100 GPU, which is a bit faster than YOLOv6. A simple but efficient predictor api is also designed in EasyCV to conduct end2end object detection.
我们开发了一个名为 EasyCV 的一体化计算机视觉工具箱,以方便使用各种 SOTA 计算机视觉方法。最近,我们将 YOLOX 的改进版 YOLOX-PAI 添加到 EasyCV 中。我们进行消融研究以调查某些检测方法对 YOLOX 的影响。我们还为 PAI-Blade 提供了一个简单的用法,用于加速基于 BladeDISC 和 TensorRT 的推理过程。最后,我们在单个 NVIDIA V100 GPU 上在 1.0 毫秒内收到 COCO 数据集上的 42.8 mAP,这比 YOLOv6 快一点。 EasyCV 中还设计了一个简单但高效的预测器 api 来进行端到端对象检测。
1 Introduction
YOLOX (Ge et al., 2021) is one of the most famous one-stage object detection methods, and has been widely used in a various field, such as automatic driving, defect inspection, etc. It introduces the decoupled head and the anchor-free manner into the YOLO series, and receives state-of-the-art results among 40 mAP to 50 mAP.
YOLOX是最著名的单阶段目标检测方法之一,已广泛应用于自动驾驶、缺陷检测等各个领域。它将the decoupled head和anchor-free 方式进入 YOLO 系列,并在 40 mAP 到 50 mAP 之间获得最先进的结果。
Considering its flexibility and efficiency, we intend to integrate YOLOX into our EasyCV, an allin-one computer vision methods that helps even a beginner easily use a computer vision algorithm.In addition, we investigate the improvement upon YOLOX by using different enhancement of the detection backbone, neck, and head. Users can simply set different configs to obtain a suitable object detection model according to their own requirements.Also, based on PAI-Blade (an inference optimization framework by PAI), we further speed up the inference process and provide an easy api to use PAI-Blade in our EasyCV. Finally, we design an efficient predictor api to use our YOLOX-PAI in an end2end manner, which accelerate the original YOLOX by a large margin. The comparisons between YOLOX-PAI and the state-of-the-art object detection methods have been shown in Fig. 1.
考虑到它的灵活性和效率,我们打算将 YOLOX 集成到我们的 EasyCV 中,这是一种一体式计算机视觉方法,即使是初学者也可以轻松使用计算机视觉算法。此外,我们通过使用不同的检测增强来研究对 YOLOX 的改进脊椎、颈部和头部。用户可以根据自己的需求简单地设置不同的配置来获得合适的目标检测模型。另外,基于PAI-Blade(PAI的推理优化框架),我们进一步加快了推理过程,并提供了一个简单易用的api我们 EasyCV 中的 PAI-Blade。最后,我们设计了一个高效的预测器 api,以端到端的方式使用我们的 YOLOX-PAI,大大加速了原始 YOLOX。 YOLOX-PAI 与最先进的目标检测方法之间的比较如图 1 所示。
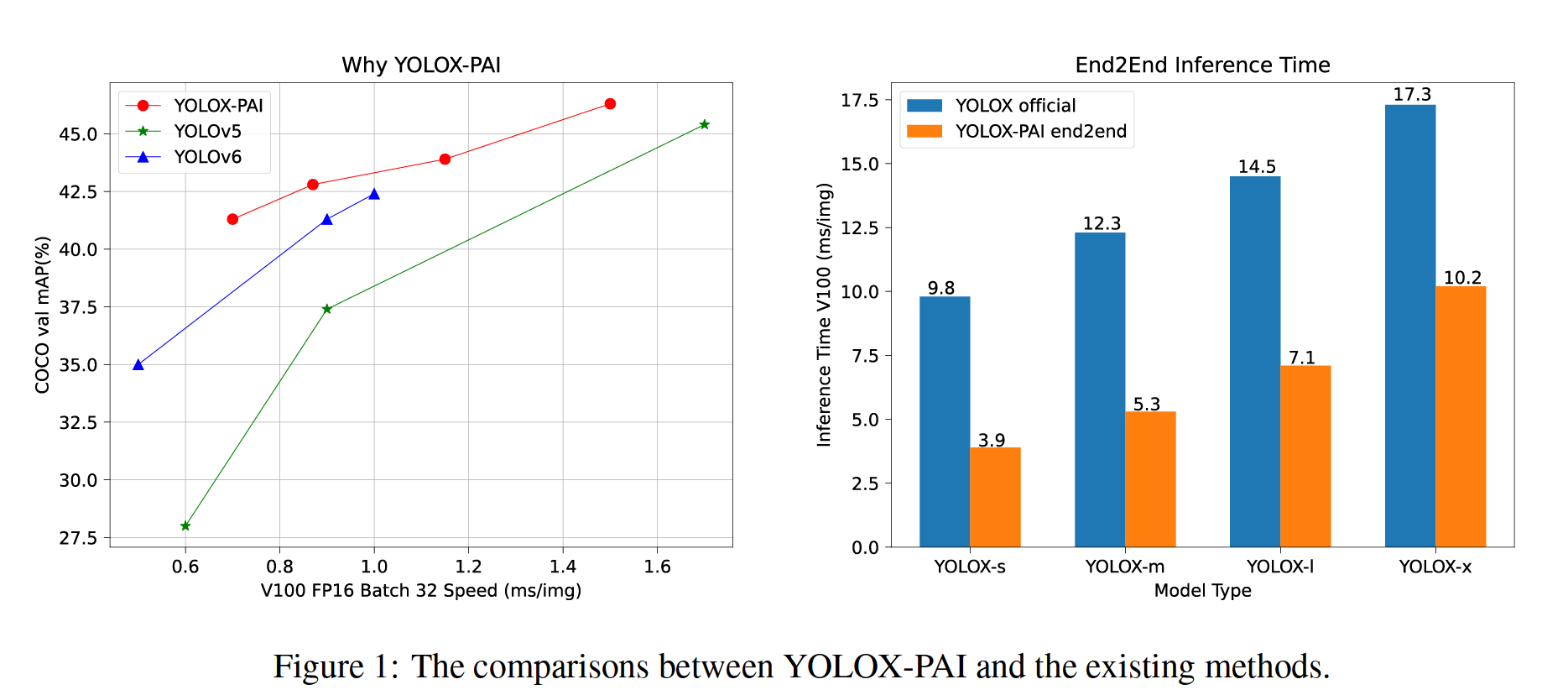
Figure 1: The comparisons between YOLOX-PAI and the existing methods.
图 1:YOLOX-PAI 与现有方法的比较。
In brief, our main contributions are as follows:
简而言之,我们的主要贡献如下:
• We release YOLOX-PAI in EasyCV as a simple yet efficient object detection tool (containing the docker image, the process of model training, model evaluation and model deployment). We hope that even a beginner can use our YOLOX-PAI to accomplish his object detection tasks.
我们在 EasyCV 中发布 YOLOX-PAI 作为一个简单而高效的对象检测工具(包含 docker 图像、模型训练、模型评估和模型部署的过程)。我们希望即使是初学者也可以使用我们的 YOLOX-PAI 来完成他的目标检测任务。
• We conduct ablation studies of existing object detection methods based on YOLOX, where only a config file is used to construct selfdesigned YOLOX model. With the improvement of the architecture and the efficiency of PAI-Blade, we obtain state-of-the-art object detection results among 40 mAP and 50 mAP within 1ms for model inference on a single NVIDIA Tesla V100 GPU.
**我们对现有的基于 YOLOX 的目标检测方法进行了消融研究,其中仅使用一个配置文件来构建自行设计的 YOLOX 模型。**随着架构的改进和 PAI-Blade 的效率,我们在单个 NVIDIA Tesla V100 GPU 上在 1ms 内获得了 40 mAP 和 50 mAP 中最先进的目标检测结果,用于模型推理。
• We provide a flexible predictor api in EasyCV that accelerates both the preprocess, inference and postprocess procedure, respectively. In this way, user can better use YOLOX-PAI for end2end objection detection task.
我们在 EasyCV 中提供了一个灵活的预测器 api,它分别加速了预处理、推理和后处理过程。这样,用户可以更好地使用 YOLOX-PAI 进行端到端的异物检测任务。
2 Methods
In this section, we will take a brief review of the used methods in YOLOX-PAI. We conduct several improvements on both the detection backbone, neck, head. We also use PAI-Blade to accelerate the inference process.
2.1 Backbone
Recently, YOLOv6 and PP-YOLOE (Xu et al., 2022) have replaced the backbone of CSPNet(Wang et al., 2020) to RepVGG (Ding et al., 2021).
最近,YOLOv6 和 PP-YOLOE (Xu et al., 2022) 已经将 CSPNet (Wang et al., 2020) 的主干替换为 RepVGG (Ding et al., 2021)。
In RepVGG, a 3x3 convolution block is used to replace a multi-branch structure during the inference process, which is beneficial to both save the inference time and improve the object detection results.Following YOLOv6,we also use a RepVGG-based backbone as a choice in YOLOX-PAI.
在 RepVGG 中,
2.2 Neck
We use two methods to improve the performance of YOLOX in the neck of YOLOX-PAI, that is 1) Adaptively Spatial Feature Fusion (ASFF) (Liu et al., 2019) and its variance (denoted as ASFF_Sim) for feature augmentation 2) GSConv (Li et al., 2022), a lightweight convolution block to reduce the compute cost.
我们使用两种方法来提高 YOLOX 在 YOLOX-PAI 颈部的性能,即
1)自适应空间特征融合(ASFF)(Liu 等人,2019)及其方差(表示为 ASFF_Sim)用于特征增强
2) GSConv (Li et al., 2022),一种用于降低计算成本的轻量级卷积块。
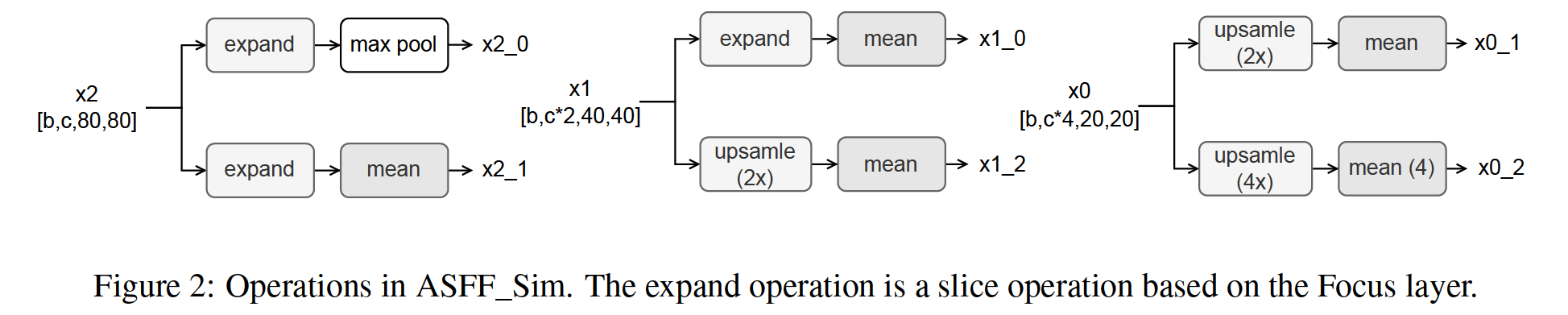
The original ASFF method uses several vanilla convolution blocks to first unify the dimension of different feature maps. Inspired by the Focus layer in YOLOv5, we replace the convolution blocks by using the non-parameter slice operation and mean operation to obtain the unified feature maps (denoted as ASFF_Sim). To be specific, the operation for each feature map of the output of YOLOX is defined in Fig. 2.
原始的 ASFF 方法使用几个 vanilla 卷积块来首先统一不同特征图的维度。受 YOLOv5 中 Focus 层的启发,我们通过使用非参数切片操作和均值操作来替换卷积块以获得统一的特征图(表示为 ASFF_Sim)。具体来说,YOLOX 输出的每个特征图的操作在图 2 中定义。
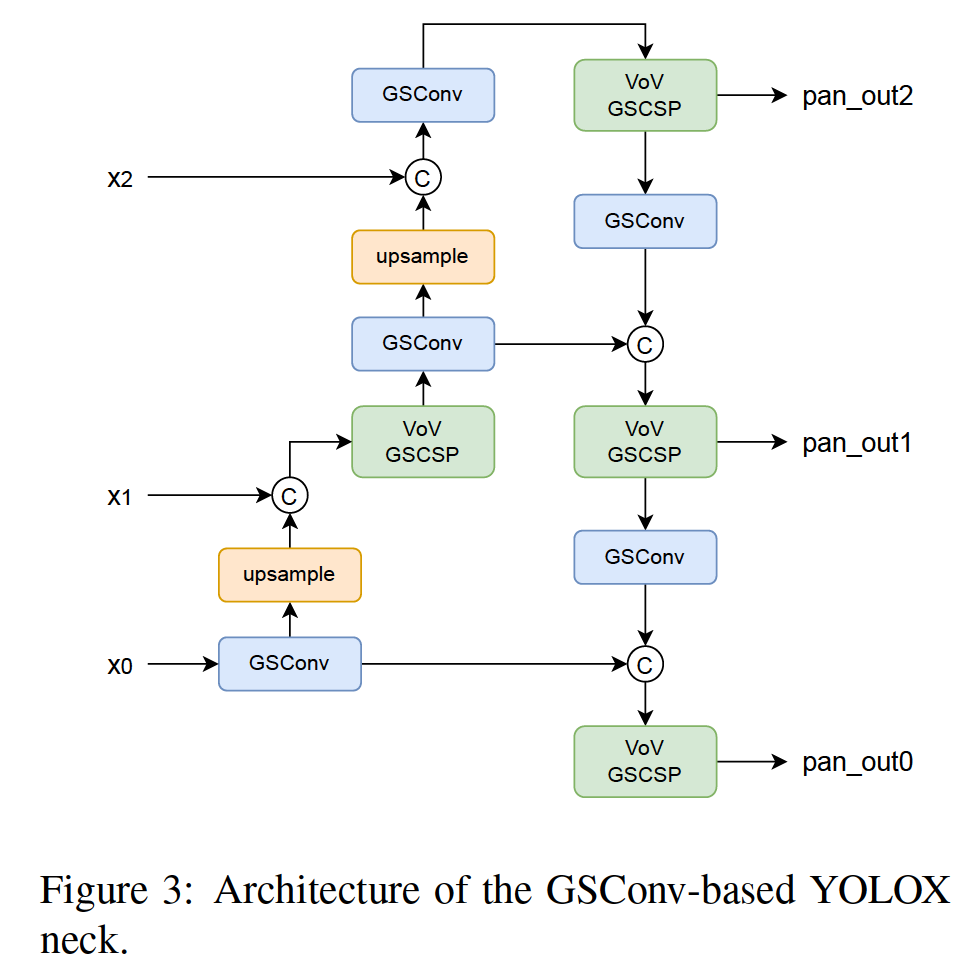
We also use two kinds of GSConv-based neck to optimize YOLOX. The used neck architectures are shown in Fig 3 and Fig 4. The differences of the two architectures are whether to replace all the blocks with GSConv. As proved by the authors, GSconv is specially designed for the neck where the channel reaches the maximum and the the size reaches the minimum.
我们还使用两种基于 GSConv 的颈部来优化 YOLOX。使用的neck架构如图3和图4所示。**两种架构的区别在于是否将所有块替换为GSConv。**正如作者所证明的那样,GSconv 是专门为通道达到最大和尺寸达到最小的颈部设计的。
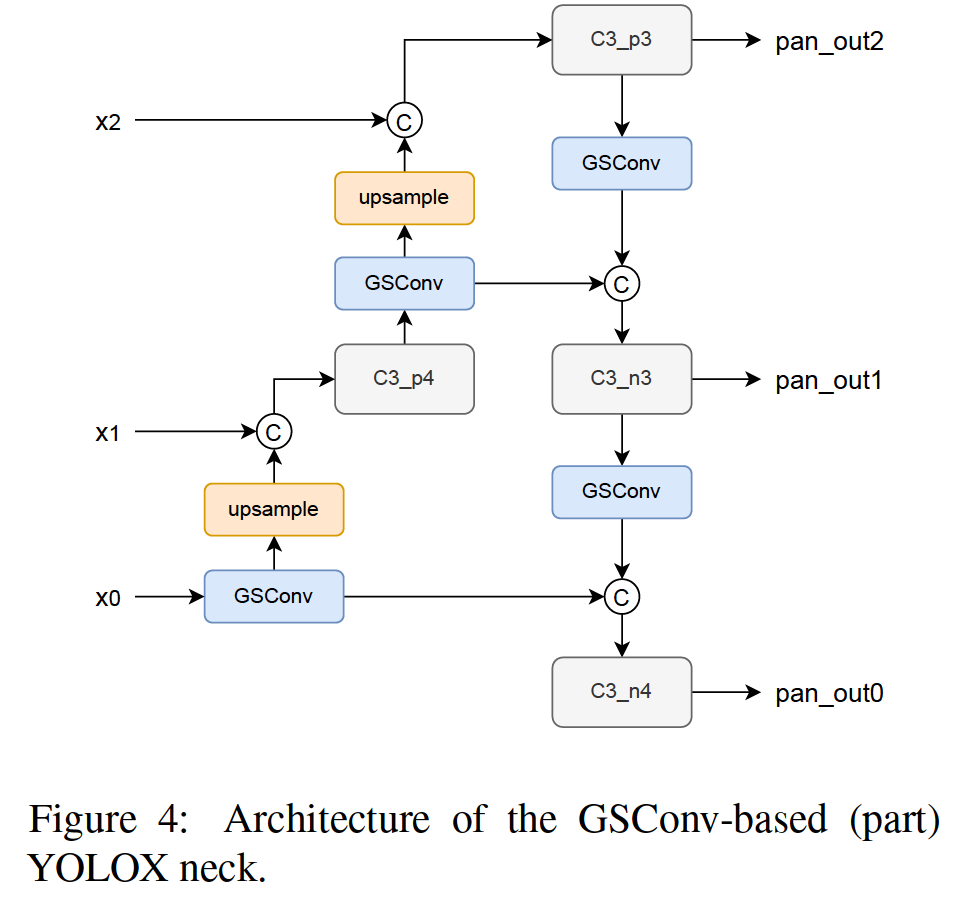
2.3 Head
We enhance the YOLOX-Head with the attention mechanism as (Feng et al., 2021) to align the task of object detection and classification (denoted as TOOD-Head). The architecture is shown in Fig. 5.
我们使用 (Feng et al., 2021) 的注意机制增强了 YOLOX-Head,以协调对象检测和分类的任务(表示为 TOOD-Head)架构如图 5 所示。
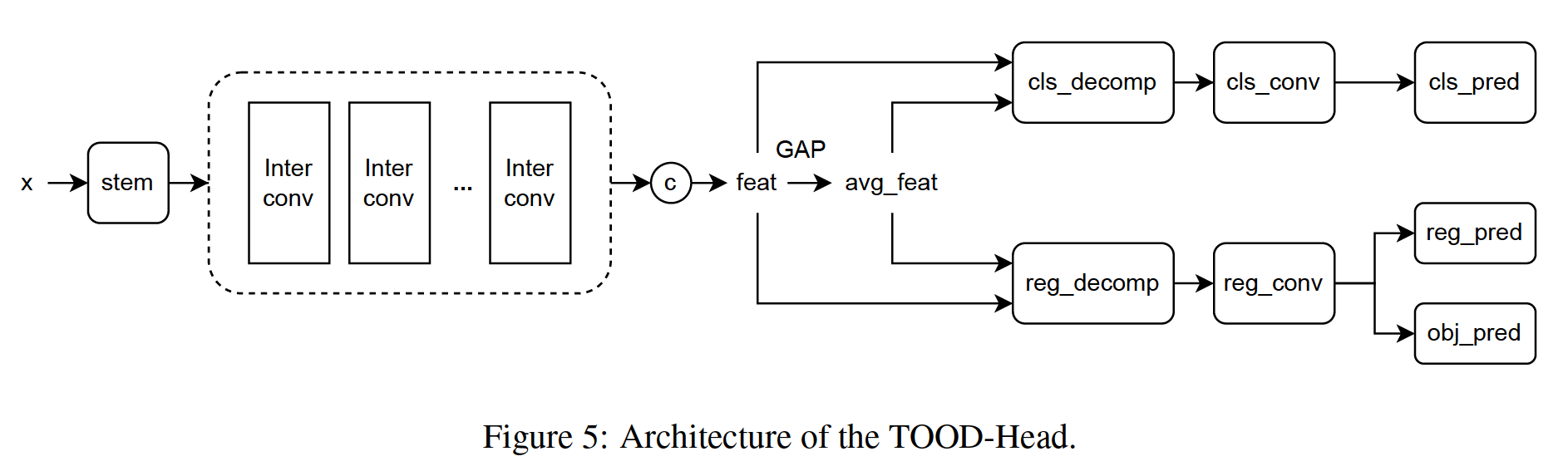
A stem layer is first used to reduce the channel, following by a group of inter convolution layers to obtain the inter feature maps. Finally, the adaptive weight is computed according to different tasks.We test the result of using the vanilla convolution or the repvgg-based convolution in the TOOD-Head, respectively.
首先使用一个stem层来减少通道,然后是一组间卷积层以获得间特征图。最后,根据不同的任务计算自适应权重。我们分别在 TOOD-Head 中测试了使用 vanilla 卷积或基于 repvgg 的卷积的结果。
2.4 PAI-Blade
PAI-Blade is an easy and robust inference optimization framework for model acceleration. It is based on many optimization techniques, such as Blade Graph Optimizer, TensorRT, PAI-TAO (Tensor Accelerator and Optimizer), and so on. PAI-Blade will automatically search for the best method to optimize the input model. Therefore, people without the professional knowledge of model deployment can also use PAI-Blade to optimize the inference process. We integrate the use of PAI-Blade in EasyCV so that users are allowed to obtain an efficient model by simply change the export config.
PAI-Blade 是一个用于模型加速的简单且强大的推理优化框架。它基于许多优化技术,如 Blade Graph Optimizer、TensorRT、PAI-TAO(Tensor Accelerator and Optimizer)等。 **PAI-Blade 将自动搜索优化输入模型的最佳方法。**因此,没有模型部署专业知识的人也可以使用 PAI-Blade 来优化推理过程。我们在 EasyCV 中集成了 PAI-Blade 的使用,让用户只需更改导出配置即可获得高效的模型。
2.5 EasyCV Predictor
Along with the model inference, the preprocess function and the postprocess function are also important in an end2end object detection task, which are often ignored by the existing object detection toolbox. In EasyCV, we allow user to choose whether to export the model with the preprocess/postprocess procedure flexibly. Then, a predictor api is provided to conduct efficient end2end object detection task with only a few lines.
除了模型推断,预处理功能和后处理功能在端到端目标检测任务中也很重要,而现有的目标检测工具箱往往会忽略这些功能。在 EasyCV 中,我们允许用户灵活选择是否使用预处理/后处理程序导出模型。然后,提供了一个预测器 api 来执行高效的端到端对象检测任务,只需几行代码。
3 Experiments
In this section, we report the ablation study results of the above methods on the COCO dataset (Lin et al., 2014) and the comparisons between YOLOXPAI and the SOTA object detection methods.
在本节中,我们报告了上述方法在 COCO 数据集(Lin et al., 2014)上的消融研究结果,以及 YOLOXPAI 和 SOTA 对象检测方法之间的比较。
3.1 Comparisons with the SOTA methods
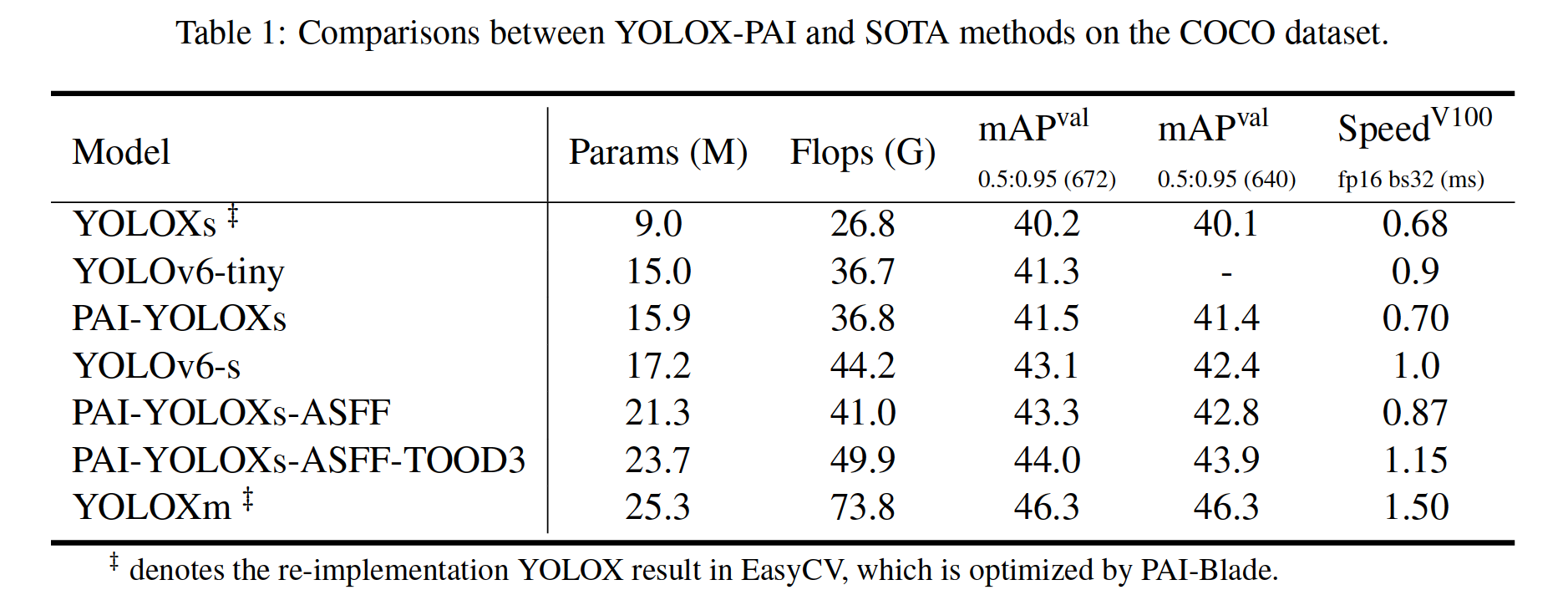
We select the useful improvements in YOLOX-PAI and compare it with the SOTA YOLOv6 method in Table 1. It can be seen that YOLOX-PAI is much faster compared to the corresponding version of YOLOv6 with a better mAP (i.e., obtain +0.2 mAP and 22% speed up, +0.2 mAP and 13% speed up of the YOLOv6-tiny, and the YOLOv6-s model, respectively).
我们选择 YOLOX-PAI 中有用的改进,并将其与表 1 中的 SOTA YOLOv6 方法进行比较。可以看出,与 YOLOv6 的相应版本相比,YOLOX-PAI 速度要快得多,具有更好的 mAP(即获得 +0.2 mAP YOLOv6-tiny 和 YOLOv6-s 模型分别加速 22%、+0.2 mAP 和 13%)。
3.2 Ablation studies
Influence of Backbone.
As shown in Table 1,YOLOX with a RepVGG-based backbone achieve better mAP with only a little sacrifice of speed. It indeed adds more parameters and flops that may need more computation resource, but does not require much inference time. Considering its effi-ciency, we make it as a flexible config setting in EasyCV.
如表 1 所示,具有基于 RepVGG 的骨干网的 YOLOX 实现了更好的 mAP,而只牺牲了一点速度。它确实增加了更多的参数和触发器,可能需要更多的计算资源,但不需要太多的推理时间。考虑到它的效率,我们将其作为 EasyCV 中的灵活配置设置。
Influence of Neck.
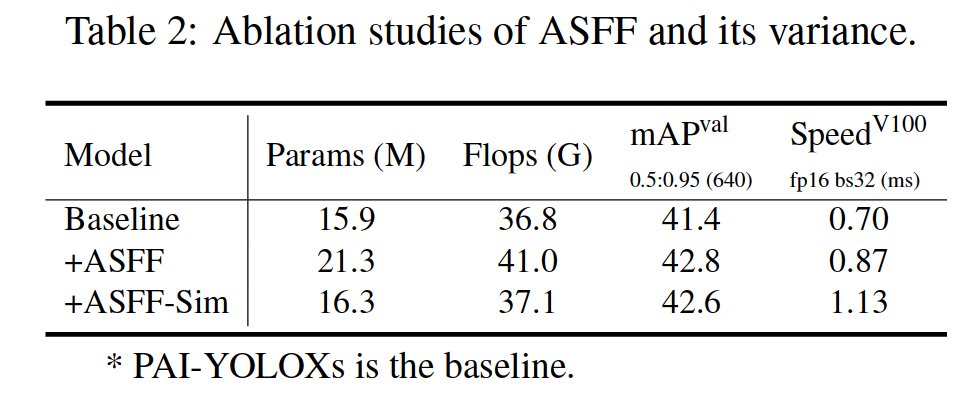
The influence of ASFF and ASFF_Sim are shown in Table 2. It shows that, compared with ASFF, ASFF_Sim is also benefical to improve the detection result with only a little gain of parameters and flops. However, the time cost is much larger and we will implement the CustomOP to optimize it in the future.
ASFF 和 ASFF_Sim 的影响如表 2 所示。这表明,**与 ASFF 相比,ASFF_Sim 也有利于提高检测结果,而参数和触发器的增益很小。**但是,时间成本要大得多,我们将在未来实施 CustomOP 对其进行优化。
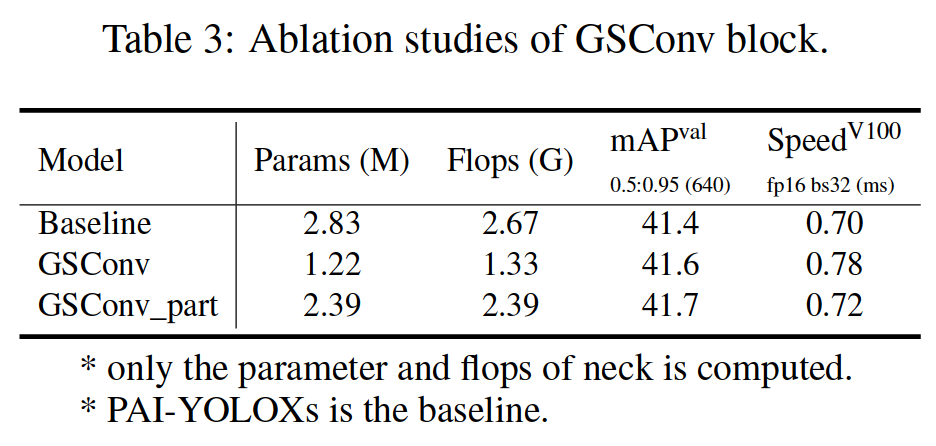
The influence of GSConv is shown in Table 3. The result is that GSConv will bring 0.3 mAP and reduce 3% of speed on a single NVIDIA V100 GPU.
GSConv 的影响如表 3 所示。结果是 GSConv 在单个 NVIDIA V100 GPU 上会带来 0.3 mAP 并降低 3% 的速度。
Influence of Head.
The influence of the TOODHead is shown in Table 4. We investigate the influence of different number of inter convolution layers. We show that when adding additional inter convolution layers, the detection results can be better. It is a trade-off between the speed and accuracy to choose a suitable hyperparameter. We also show that when replacing the vanilla convolution with the repconv-based convolution in the inter convolution layers, the result become worse.
TOODHead 的影响如表 4 所示。我们研究了不同数量的互卷积层的影响。我们表明,当添加额外的卷积层时,检测结果会更好。选择合适的超参数是速度和准确性之间的权衡。我们还表明,当在卷积层间用基于 repconv 的卷积替换 vanilla 卷积时,结果会变得更糟。
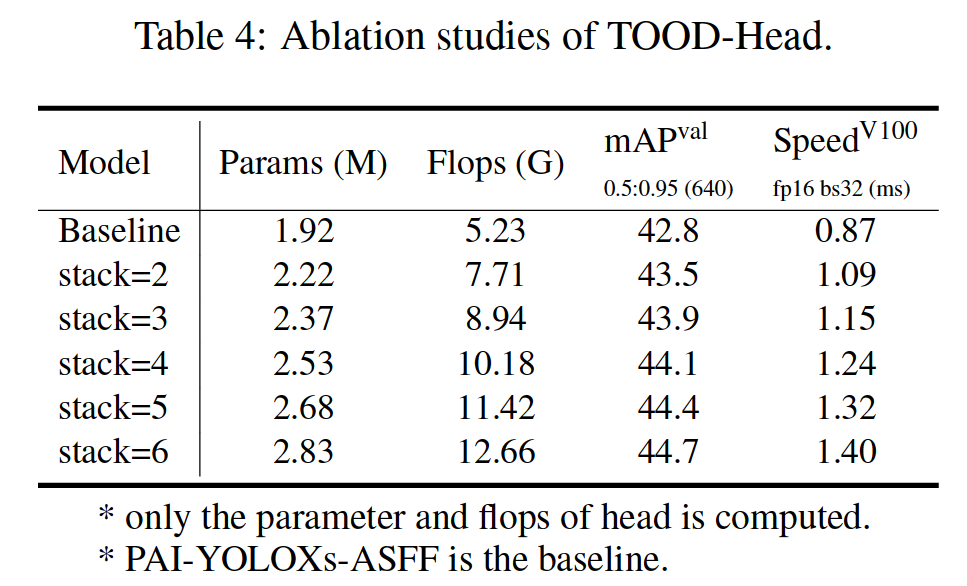
It will slightly improve the result when using repconvbased cls_conv/reg_conv layer (in Fig. 5) when the stack number is small (i.e., 2, 3).
当堆栈数较小(即 2、3)时,使用基于 repconv 的 cls_conv/reg_conv 层(图 5)会略微改善结果。

3.3 End2end results
Table 5 shows the end2end prediction results of YOLOXs model with different export configs. The keywords in the table are the same as in our EasyCV config file. It is evident that the blade optimization is useful to optimize the inference process. Also, the preprocess process can be greatly speed up by the exported jit model.
表 5 显示了 YOLOXs 模型在不同导出配置下的端到端预测结果。表中的关键字与我们的 EasyCV 配置文件中的关键字相同。很明显,blade优化对于优化推理过程很有用。此外,导出的 jit 模型可以大大加快预处理过程。
As for the postprocess, we are still work on it to realize a better CustomOP that can be optimized by PAI-Blade for a better performance. In the right part of Fig 1, we show that with the optimization of PAI-Blade and EasyCV predictor, we can receive a satisfactory end2end inference time on YOLOX.
至于后处理,我们仍在努力实现更好的 CustomOP,可以通过 PAI-Blade 进行优化以获得更好的性能。在图 1 的右侧,我们展示了通过 PAI-Blade 和 EasyCV 预测器的优化,我们可以在 YOLOX 上获得令人满意的端到端推理时间。
4 Conclusion
In this paper, we introduced YOLOX-PAI, an improved version of YOLOX based on EasyCV. It receives SOTA object detection results among 40 mAP and 50 mAP with the improvement of the model architecture and PAI-Blade. We also provide an easy and efficient predictor api to conduct end2end object detection in a flexible way. EasyCV is an all-in-one toolkit box that focuses on SOTA computer vision methods, especially in the field of self-supervised learning and vision transformer.We hope that users can conduct computer vision tasks immediately and enjoy CV by using EasyCV!
在本文中,我们介绍了 YOLOX-PAI,它是基于 EasyCV 的 YOLOX 的改进版本。随着模型架构和 PAI-Blade 的改进,它在 40 mAP 和 50 mAP 之间接收 SOTA 目标检测结果。我们还提供了一个简单高效的预测器 api,以灵活的方式进行端到端对象检测。 **EasyCV 是一款专注于 SOTA 计算机视觉方法的一体化工具箱,特别是在自监督学习和视觉转换器领域。**我们希望用户可以立即进行计算机视觉任务,并通过使用 EasyCV 享受 CV!








 C. Sonya and Queries —— 二进制压缩)


)
 to copy the tensor to host memory)



![[笔记] FireDAC DataSet 导入及导出 JSON](http://pic.xiahunao.cn/[笔记] FireDAC DataSet 导入及导出 JSON)


