

实战是学习的最好途径,效率最高,本文不是很长,通过小小的练习,让大家综合运用基础知识,加深印象巩固记忆。
一、读入数据,了解数据
本数据随机生成的假数据,读者可以自己造,也可以通过下方链接下载,或者后台回复“超市营业额”获取:
链接:https://pan.baidu.com/s/1OIOwBdBZydgRf5U72Gh_vg
提取码:vedz
读入数据
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 生成营业额400-4000,生成400个随机数
# np.random.randint(400,4000,400)
df=pd.read_excel("超市营业额数据.xlsx")
df.head(10)了解数据
通过.info() 和 .describe()方法分别查看数据大概是什么样的
df.info()
---------------------------------------------------------------------
out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 256 entries, 0 to 255
Data columns (total 6 columns):
工号 256 non-null int64
姓名 256 non-null object
日期 256 non-null datetime64[ns]
时段 256 non-null object
交易额 242 non-null float64
柜台 256 non-null object
dtypes: datetime64[ns](1), float64(1), int64(1), object(3)
memory usage: 12.1+ KB数据总共256个观测,6个变量/特征,工号是整型,日期是日期型,交易额是浮点型,其他是字符型数据。“交易额”有缺失数据。
#将工号的数据类型由原来是整型调整为字符型df['工号']=df["工号"].apply(lambda x:str(x))
df.info()
---------------------------------------------------------------------
out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 256 entries, 0 to 255
Data columns (total 6 columns):
工号 256 non-null object
姓名 256 non-null object
日期 256 non-null datetime64[ns]
时段 256 non-null object
交易额 242 non-null float64
柜台 256 non-null object
dtypes: datetime64[ns](1), float64(1), object(4)
memory usage: 12.1+ KB从统计量角度,可以看到数值型的变量(交易额)的最大值、最小值、均值、四分位值,标准差的五值分布。均值是2123.88,最大为3988,最小是404,中位数是2239.5。
df.describe()
---------------------------------------------------------------------
out:交易额
count 242.000000
mean 2123.884298
std 1033.596041
min 404.000000
25% 1211.500000
50% 2239.500000
75% 3023.250000
max 3988.000000题目1:
删除重复数据,把缺失的交易额使用每个员工自己所有交易额的中值进行填充,把小于500的交易额统一改为500,大于3000的交易额改为3000,修改后的数据保存为文件“数据调整结果.xlsx”,文件结构与“超市营业额数据.xlsx”相同。
# 查看重复数据
df[df.duplicated()]
# 删除重复数据
df.drop_duplicates()重复的数据如下:
for i in df[df["交易额"].isnull()].index:#循环遍历交易额有缺失值的索引#取到交易额有缺失值的索引,根据索引找到人名,用这些人对应的交易额中位数填充df.loc[i,"交易额"]=round(df.loc[df.姓名==df.loc[i,"姓名"],"交易额"].median())
---------------------------------------------------------------------
df.loc[df["交易额"]<500,"交易额"]=500
df.loc[df["交易额"]>3000,"交易额"]=3000解析:
df.loc[df.姓名==df.loc[i,"姓名"],"交易额"]:取有营业额缺失的索引对应的人的营业额
所有营业额的缺失值已经被填补
df.info()
---------------------------------------------------------------------
out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 256 entries, 0 to 255
Data columns (total 6 columns):
工号 256 non-null object
姓名 256 non-null object
日期 256 non-null datetime64[ns]
时段 256 non-null object
交易额 256 non-null float64
柜台 256 non-null object
dtypes: datetime64[ns](1), float64(1), object(4)
memory usage: 12.1+ KB验证:
df[df["交易额"].isnull()].index
---------------------------------------------------------------------
out:
Int64Index([6, 29, 80, 113, 127, 149, 152, 175, 187, 194, 202, 228, 232, 254], dtype='int64')索引6对应的人为“钱八”,他的所有营业额的中位数是:
round(df.loc[df.姓名=="钱八","交易额"].median())
---------------------------------------------------------------------
out:
1536处理后的数据如下:
保存数据:
df.to_excel("数据调整结果.xlsx",index=False)题目2:
查看单日交易总额最小的3天的交易数据,并查看这三天是周几,程序运行后直接输出这些结果。
df2=df.groupby(by="日期",as_index=False).agg({"交易额":"sum"}).nsmallest(3,["日期",'交易额'])
df2
---------------------------------------------------------------------
out:日期 交易额
0 2019-03-01 13809.0
1 2019-03-02 19364.0
2 2019-03-03 16821.0
pd.to_datetime(df2["日期"]).dt.weekday_name
-----------------------------------------------------------------------
out:
0 Friday
1 Saturday
2 Sunday
Name: 日期, dtype: object解析:
df.groupby(by="日期",as_index=False).agg({"交易额":"sum"}):根据日期分类汇总,按交易额求和汇总
nsmallest:传入保留最小的前几位n和保留的列名。
题目3:
把所有员工的工号前面增加一位数字,增加的数字和原工号最后一位相同,把修改后的数据写入新文件“超市营业额2_修改工号.xlsx”。例如,工号1001变为11001,1003变为31003
from copy import deepcopy #深拷贝
df3=deepcopy(df)
fx=lambda x:str(x)[-1]+str(x)
df3['gh2']=df[['工号']].applymap(fx)
df3
---------------------------------------------------------------------
out:解析:
1、lambda x:str(x)[-1]+str(x):定义lambda表达式,用于参数x(x转化为字符串后切片取末位,然后再拼接一个转为字符串的x)
2、df[['工号']].applymap(fx):applymap()函数作用对象为DataFrame,调用定义的lambda表达书,逐个作用在df[['工号']]的工号上。 当然还可以用apply()函数和map()函数,变换作用对象即可:
map()和apply()作用对象为Series。
df3['gh1']=df['工号'].map(fx)
df3['gh3']=df['工号'].apply(fx)
---------------------------------------------------------------------
out:
保存数据到超市营业额2_修改工号.xlsxdf3.to_excel("超市营业额2_修改工号.xlsx",index=False)额外补充:
1、深拷贝和浅拷贝通俗理解
a是自定义的列表,b是copy(a),c是deepcopy(a),改变列表a中的值,b会随之改变,c还是原来的a。
2、==和is的区别:
python对象三要素:id(身份标识)、type(数据类型)、value(值)
==是比较操作,用来判断两个对象的value(值)是否相等
is是同一性运算符,判断比较两个对象的唯一身份id
题目4:
把每个员工的交易数据写入文件“各员工数据.xlsx”,每个员工的数据占一个worksheet,结构和“超市营业额2.xlsx”一样,并以员工姓名作为worksheet的标题。
writer=pd.ExcelWriter("各员工数据.xlsx")
names=set(df['姓名'])
names
---------------------------------------------------------------------
out:
{'周七', '张三', '李四', '王五', '赵六', '钱八'}for name in names:dff=df[df['姓名']==name]dff.to_excel(writer,sheet_name=name,index=False)
writer.save()
---------------------------------------------------------------------
out:最终结果如下(前面所有生成的文件和本题产出的excel文件):
题目5:
查看日期尾数为6的数据前12行,输出这些结果
df[df['日期'].map(lambda x:x.strftime("%Y-%m-%d").endswith("6"))][:12]
---------------------------------------------------------------------
out:工号 姓名 日期 时段 交易额 柜台
44 1002 李四 2019-03-06 9:00-14:00 799.0 化妆品
45 1005 周七 2019-03-06 14:00-21:00 2726.0 化妆品
46 1002 李四 2019-03-06 9:00-14:00 1519.0 食品
47 1003 王五 2019-03-06 14:00-21:00 3000.0 食品
48 1003 王五 2019-03-06 9:00-14:00 2343.0 日用品
49 1005 周七 2019-03-06 14:00-21:00 3000.0 日用品
50 1003 王五 2019-03-06 9:00-14:00 2293.0 蔬菜水果
51 1004 赵六 2019-03-06 14:00-21:00 1970.0 蔬菜水果
126 1002 李四 2019-03-16 9:00-14:00 3000.0 化妆品
127 1003 王五 2019-03-16 14:00-21:00 2428.0 化妆品
128 1003 王五 2019-03-16 9:00-14:00 2732.0 食品
129 1001 张三 2019-03-16 14:00-21:00 1650.0 食品方法二:用datetime模块
from datetime import datetime
df[df['日期'].map(lambda x:str(datetime.date(x)).endswith('16'))][:12]
---------------------------------------------------------------------
out:工号 姓名 日期 时段 交易额 柜台
126 1002 李四 2019-03-16 9:00-14:00 3000.0 化妆品
127 1003 王五 2019-03-16 14:00-21:00 2428.0 化妆品
128 1003 王五 2019-03-16 9:00-14:00 2732.0 食品
129 1001 张三 2019-03-16 14:00-21:00 1650.0 食品
130 1002 李四 2019-03-16 9:00-14:00 2823.0 日用品
131 1003 王五 2019-03-16 14:00-21:00 2857.0 日用品
132 1004 赵六 2019-03-16 9:00-14:00 511.0 蔬菜水果
133 1005 周七 2019-03-16 14:00-21:00 2658.0 蔬菜水果解析:
思路都是一样的,首先定义lambda表达式(也可以自定义函数),对其字符化处理后调用字符处理函数endswith()函数判断以什么结尾,方法一直接用格式化时间,方法二调用datetime模块datetime.date,将日期时间类型转化为日期型后,在转化为字符串。
题目6:
计算张三每天交易总额的增幅,也就是每天交易总额减去前一天的交易总额,程序运行后输出前5天的结果
df[df['姓名']=="张三"].groupby(by='日期').交易额.sum() #张三每天总的交易额
---------------------------------------------------------------------
out:
日期
2019-03-01 1664.0
2019-03-02 680.0
2019-03-04 1823.0
2019-03-07 2352.0
2019-03-09 2522.0
2019-03-11 3000.0
2019-03-12 592.0
2019-03-14 2676.0
2019-03-16 1650.0
2019-03-18 1266.0
2019-03-19 1414.0
2019-03-21 3000.0
2019-03-22 3000.0
2019-03-24 1942.0
2019-03-26 1725.0
2019-03-28 518.0
2019-03-29 2651.0
2019-03-31 3000.0
Name: 交易额, dtype: float64增幅利用diff()函数,简单粗暴:
df[df['姓名']=="张三"].groupby(by='日期').交易额.sum().diff()[:5]
---------------------------------------------------------------------
out:
日期
2019-03-01 NaN
2019-03-02 -984.0
2019-03-04 1143.0
2019-03-07 529.0
2019-03-09 170.0
Name: 交易额, dtype: float64题目7:
绘制折线图展示一个月内各柜台营业额每天变化趋势,保存为“1.png”,设置dpi为200
## 设置字符集,防止中文乱码
import matplotlib as mpl
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=Falsedf7=df.loc[:,['日期','柜台','交易额']].groupby(by=['日期','柜台'],as_index=False).sum()
df7.pivot(index='日期',columns='柜台',values='交易额').plot()
plt.title("每天各柜台营业额的变化")
plt.legend(loc='best')
plt.xticks(rotation=5)
plt.savefig("1.jpg",dpi=200)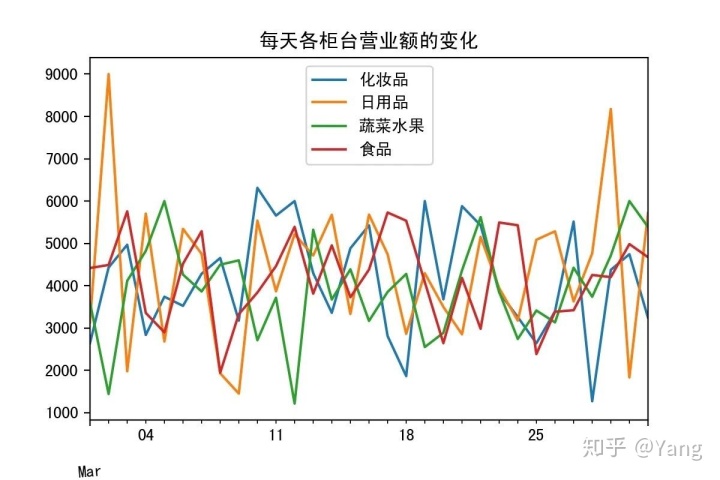
题目8:
绘制饼状图展示该月各柜台营业额在交易总额中的占比,保存为“2.png”,设置dpi为200
df8.plot(x='柜台',y='交易额',kind='pie',labels=df8['柜台'].values)
plt.legend(loc=(1,0.5))
plt.title("各柜台营业额占比图")
plt.savefig("2.png",dpi=200)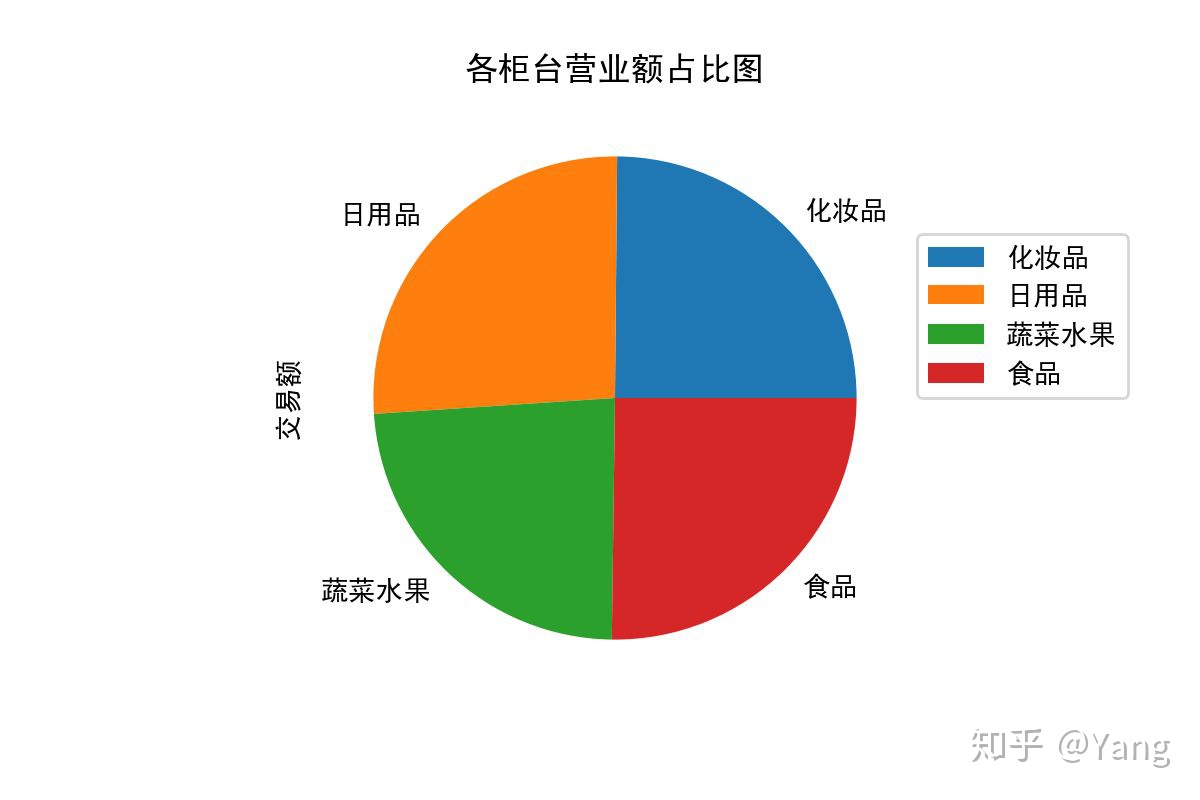
题目9:
把销售总额低于5万的员工工号和姓名写入“业绩差的员工.txt”文件,每行一个员工信息,工号,姓名和交易额之间使用英文逗号分隔
df9=df.groupby(by=["姓名","工号"],as_index=False).sum()
df99=df9[df9['交易额']<=50000]
df99
---------------------------------------------------------------------
out:姓名 工号 交易额
1 张三 1001 35475.0
5 钱八 1006 37115.0with open("业绩差的员工.txt","w+",encoding="utf-8") as fp:for name in df99['姓名'].values:gh=df99[df99['姓名']==name].工号.values[0]jye=df99[df99['姓名']==name].交易额.values[0]fp.write(str(gh)+','+name+','+str(jye)+'n')输出结果如下图:
题目10:
绘制柱状图展示每个员工在不同柜台上的交易总额,结果类似于下图,保存为“3.png”,设置dpi为200
方法一:DataFrame.pivot_table()
df10=df.pivot_table(index='姓名',columns='柜台',values='交易额',aggfunc="sum").apply(round)
df10
方法二:Pandas.crosstab()
df10=pd.crosstab(df.姓名,df.柜台,df.交易额,aggfunc="sum").apply(round)
df10
df10.plot(kind="bar")
plt.xlabel("员工业绩分布")
plt.legend(loc="upper right")
plt.savefig("3.jpg",dpi=200)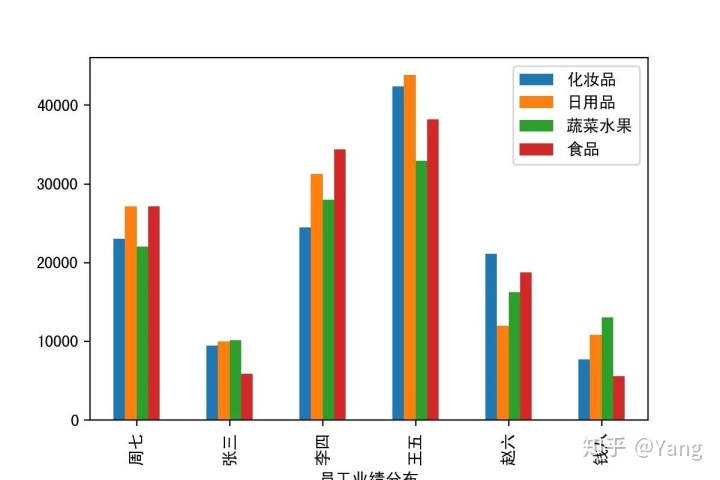
本题重点:
☆☆☆☆☆☆☆DataFrame透视表功能 VS Pandas的交叉表功能☆☆☆☆☆☆☆
1、df.pivot_table(index='姓名',columns='柜台',values='交易额',aggfunc="sum")
pivot_table()透视表功能,作用对象是DataFrame,参数index、columns、values,aggfunc。
可以通过help(pivot_table)查看。
2、pd.crosstab()交叉表功能,有同样的效果,作用对象是Pandas
参数margins=False表示不分类汇总,True表示分类汇总
help(df.pivot_table)
pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
help(pd.crosstab):
crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False)题目11:
使用透视表查看每个员工在不同柜台上班的次数:
df.pivot_table(index="姓名",columns="柜台",values="交易额",aggfunc="count",margins=True)
---------------------------------------------------------------------
out: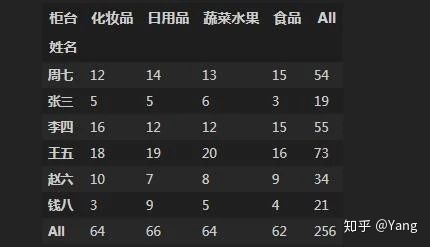
本文涉及数据处理,数据分析,统计展示,输入输出。
lambda表达式,apply()系列函数,pivot,pivot_table()函数,crosstab()函数,上下文管理器,分组聚合,数据筛选,字符处理,数据透视。文章不长,但是涉及内容精简实用,可以做实际应用中体会。
知乎排版太难看,请参考原文
Pandas综合案例:超市营业额数据实战分析mp.weixin.qq.com
公众号“python数据科学修炼之路”







:选择最佳的数据类型...)


)



![[luoguP2760] 科技庄园(背包DP)](http://pic.xiahunao.cn/[luoguP2760] 科技庄园(背包DP))




